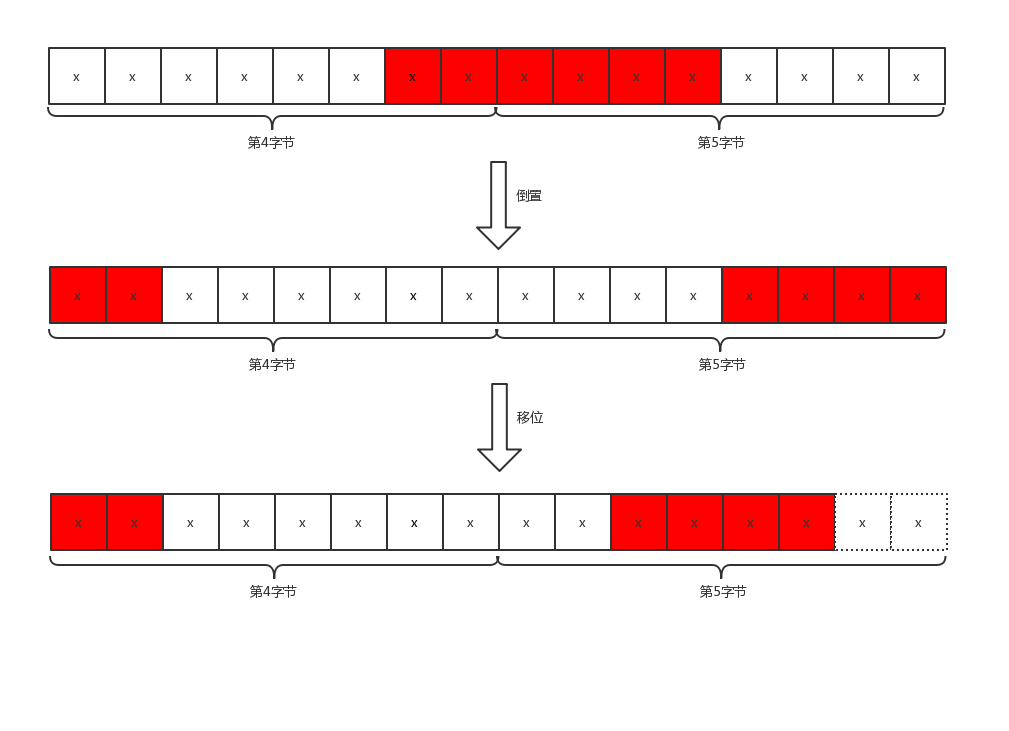
#define HLL_BITS 6 /* Enough to count up to 63 leading zeroes. */#define HLL_REGISTER_MAX ((1<<HLL_BITS)-1)/* Store the value of the register at position 'regnum' into variable 'target'.
* 'p' is an array of unsigned bytes. */#define HLL_DENSE_GET_REGISTER(target,p,regnum) do { \
uint8_t *_p = (uint8_t*) p; \
unsigned long _byte = regnum*HLL_BITS/8; \
unsigned long _fb = regnum*HLL_BITS&7; \
unsigned long _fb8 = 8 - _fb; \
unsigned long b0 = _p[_byte]; \
unsigned long b1 = _p[_byte+1]; \
target = ((b0 >> _fb) | (b1 << _fb8)) & HLL_REGISTER_MAX; \
} while(0)/* Set the value of the register at position 'regnum' to 'val'.
* 'p' is an array of unsigned bytes. */#define HLL_DENSE_SET_REGISTER(p,regnum,val) do { \
uint8_t *_p = (uint8_t*) p; \
unsigned long _byte = regnum*HLL_BITS/8; \
unsigned long _fb = regnum*HLL_BITS&7; \
unsigned long _fb8 = 8 - _fb; \
unsigned long _v = val; \
_p[_byte] &= ~(HLL_REGISTER_MAX << _fb); \
_p[_byte] |= _v << _fb; \
_p[_byte+1] &= ~(HLL_REGISTER_MAX >> _fb8); \
_p[_byte+1] |= _v >> _fb8; \
} while(0)
structhllhdr {char magic[4]; /* "HYLL" */uint8_t encoding; /* HLL_DENSE or HLL_SPARSE. */uint8_t notused[3]; /* Reserved for future use, must be zero. */uint8_t card[8]; /* Cached cardinality, little endian. */uint8_t registers[]; /* Data bytes. */
};
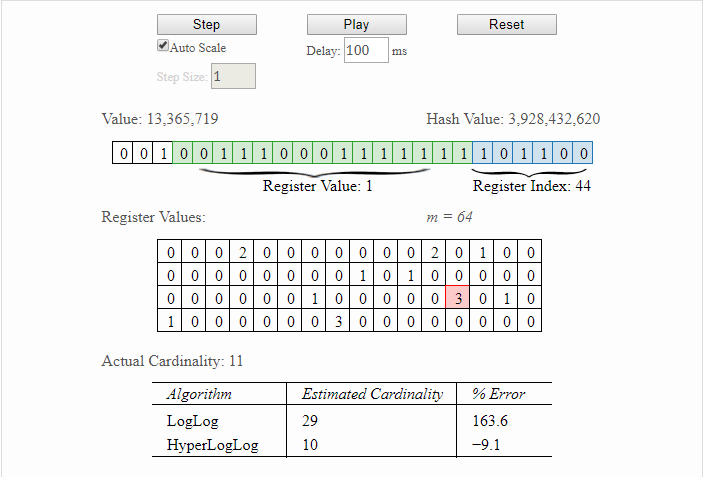
创建HyperLogLog对象
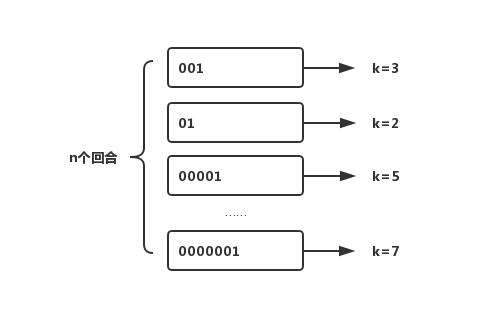
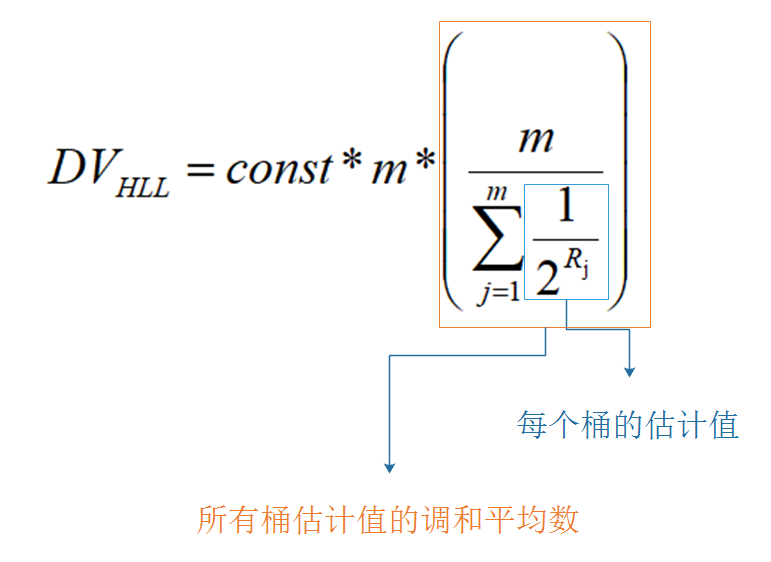
#define HLL_P 14 /* The greater is P, the smaller the error. */#define HLL_REGISTERS (1<<HLL_P) /* With P=14, 16384 registers. */#define HLL_SPARSE_XZERO_MAX_LEN 16384#define HLL_SPARSE_XZERO_SET(p,len) do { \
int _l = (len)-1; \
*(p) = (_l>>8) | HLL_SPARSE_XZERO_BIT; \
*((p)+1) = (_l&0xff); \
} while(0)/* Create an HLL object. We always create the HLL using sparse encoding.
* This will be upgraded to the dense representation as needed. */robj *createHLLObject(void){
robj *o;
structhllhdr *hdr;
sds s;
uint8_t *p;
int sparselen = HLL_HDR_SIZE +
(((HLL_REGISTERS+(HLL_SPARSE_XZERO_MAX_LEN-1)) /
HLL_SPARSE_XZERO_MAX_LEN)*2);
int aux;
/* Populate the sparse representation with as many XZERO opcodes as
* needed to represent all the registers. */
aux = HLL_REGISTERS;
s = sdsnewlen(NULL,sparselen);
p = (uint8_t*)s + HLL_HDR_SIZE;
while(aux) {
int xzero = HLL_SPARSE_XZERO_MAX_LEN;
if (xzero > aux) xzero = aux;
HLL_SPARSE_XZERO_SET(p,xzero);
p += 2;
aux -= xzero;
}
serverAssert((p-(uint8_t*)s) == sparselen);
/* Create the actual object. */
o = createObject(OBJ_STRING,s);
hdr = o->ptr;
memcpy(hdr->magic,"HYLL",4);
hdr->encoding = HLL_SPARSE;
return o;
}
/* PFADD var ele ele ele ... ele => :0 or :1 */voidpfaddCommand(client *c){
robj *o = lookupKeyWrite(c->db,c->argv[1]);
structhllhdr *hdr;int updated = 0, j;
if (o == NULL) {
/* Create the key with a string value of the exact length to
* hold our HLL data structure. sdsnewlen() when NULL is passed
* is guaranteed to return bytes initialized to zero. */
o = createHLLObject();
dbAdd(c->db,c->argv[1],o);
updated++;
} else {
if (isHLLObjectOrReply(c,o) != C_OK) return;
o = dbUnshareStringValue(c->db,c->argv[1],o);
}
/* Perform the low level ADD operation for every element. */for (j = 2; j < c->argc; j++) {
int retval = hllAdd(o, (unsignedchar*)c->argv[j]->ptr,
sdslen(c->argv[j]->ptr));
switch(retval) {
case1:
updated++;
break;
case-1:
addReplySds(c,sdsnew(invalid_hll_err));
return;
}
}
hdr = o->ptr;
if (updated) {
signalModifiedKey(c->db,c->argv[1]);
notifyKeyspaceEvent(NOTIFY_STRING,"pfadd",c->argv[1],c->db->id);
server.dirty++;
HLL_INVALIDATE_CACHE(hdr);
}
addReply(c, updated ? shared.cone : shared.czero);
}
/* PFCOUNT var -> approximated cardinality of set. */voidpfcountCommand(client *c){
robj *o;
structhllhdr *hdr;uint64_t card;
/* Case 1: multi-key keys, cardinality of the union.
*
* When multiple keys are specified, PFCOUNT actually computes
* the cardinality of the merge of the N HLLs specified. */if (c->argc > 2) {
uint8_t max[HLL_HDR_SIZE+HLL_REGISTERS], *registers;
int j;
/* Compute an HLL with M[i] = MAX(M[i]_j). */memset(max,0,sizeof(max));
hdr = (struct hllhdr*) max;
hdr->encoding = HLL_RAW; /* Special internal-only encoding. */
registers = max + HLL_HDR_SIZE;
for (j = 1; j < c->argc; j++) {
/* Check type and size. */
robj *o = lookupKeyRead(c->db,c->argv[j]);
if (o == NULL) continue; /* Assume empty HLL for non existing var.*/if (isHLLObjectOrReply(c,o) != C_OK) return;
/* Merge with this HLL with our 'max' HHL by setting max[i]
* to MAX(max[i],hll[i]). */if (hllMerge(registers,o) == C_ERR) {
addReplySds(c,sdsnew(invalid_hll_err));
return;
}
}
/* Compute cardinality of the resulting set. */
addReplyLongLong(c,hllCount(hdr,NULL));
return;
}
/* Case 2: cardinality of the single HLL.
*
* The user specified a single key. Either return the cached value
* or compute one and update the cache. */
o = lookupKeyWrite(c->db,c->argv[1]);
if (o == NULL) {
/* No key? Cardinality is zero since no element was added, otherwise
* we would have a key as HLLADD creates it as a side effect. */
addReply(c,shared.czero);
} else {
if (isHLLObjectOrReply(c,o) != C_OK) return;
o = dbUnshareStringValue(c->db,c->argv[1],o);
/* Check if the cached cardinality is valid. */
hdr = o->ptr;
if (HLL_VALID_CACHE(hdr)) {
/* Just return the cached value. */
card = (uint64_t)hdr->card[0];
card |= (uint64_t)hdr->card[1] << 8;
card |= (uint64_t)hdr->card[2] << 16;
card |= (uint64_t)hdr->card[3] << 24;
card |= (uint64_t)hdr->card[4] << 32;
card |= (uint64_t)hdr->card[5] << 40;
card |= (uint64_t)hdr->card[6] << 48;
card |= (uint64_t)hdr->card[7] << 56;
} else {
int invalid = 0;
/* Recompute it and update the cached value. */
card = hllCount(hdr,&invalid);
if (invalid) {
addReplySds(c,sdsnew(invalid_hll_err));
return;
}
hdr->card[0] = card & 0xff;
hdr->card[1] = (card >> 8) & 0xff;
hdr->card[2] = (card >> 16) & 0xff;
hdr->card[3] = (card >> 24) & 0xff;
hdr->card[4] = (card >> 32) & 0xff;
hdr->card[5] = (card >> 40) & 0xff;
hdr->card[6] = (card >> 48) & 0xff;
hdr->card[7] = (card >> 56) & 0xff;
/* This is not considered a read-only command even if the
* data structure is not modified, since the cached value
* may be modified and given that the HLL is a Redis string
* we need to propagate the change. */
signalModifiedKey(c->db,c->argv[1]);
server.dirty++;
}
addReplyLongLong(c,card);
}
}