

上一篇文章中介绍了几种常见链表的含义,今天介绍下如何写出正确的链表代码。
如何表示链表
我们一般设计的链表有两个类。Node 类用来表示节点,LinkedList 类提供了一些辅助方法,比如说结点的增删改查,以及显示列表元素等方法。
接下来看看如何用 js 代码表示一个链表。
代码演示:
{
var Node = function(data) {
this.data = data;
this.next = null;
};
var node1 = new Node(1);
var node2 = new Node(2);
var node3 = new Node(3);
node1.next = node2;
node2.next = node3;
console.log(node1.data);
console.log(node1.next.data);
console.log(node1.next.next.data);
}
Node 类包含两个属性:data 用来保存节点上的数据,next 用来保存指向下一个节点的链接。
{
var LList = function() {
this.head = new Node('head');
this.find = find;
this.insert = insert;
this.remove = remove;
this.display = display;
}
}
LList 类提供了对链表进行操作的方法。该类中使用一个 Node 类来保存链表中的头结点。当有新元素插入时,next 就会指向新的元素。
怎么样,简单吧,你已经学会链表了

但,这只是基本的链表表示法,水还很深。
注意事项

把上一篇文章中的单链表图搬过来,方便参考
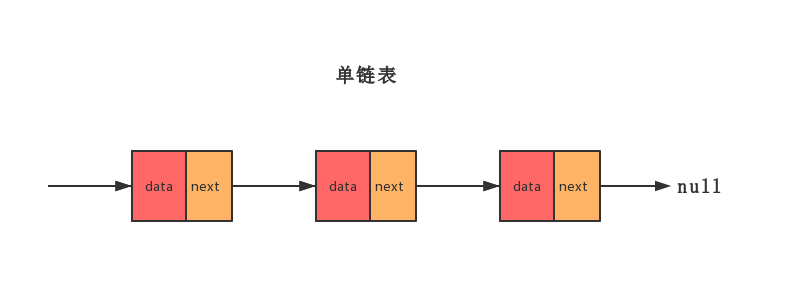
重点一:理解指针或引用的含义
这里的指针或者引用,他们的意思都是一样的,都是存储所指对象的内存地址。
将某个变量赋值给指针,实际上就是将某个变量的地址赋值给指针,或者反过来说,指针中存储了这个变量的内存地址,指向了这个变量,通过指针就能找到这个变量。
看下面的伪代码表示什么意思:
p -> next = q;
这行代码就是说 p 结点中的 next 指针存储了 q 结点的内存地址。
再看下面的代码表示什么:
p -> next = p -> next -> next;
这行代码表示,p 结点的 next 指针存储了 p 结点的下下一个结点的内存地址。
现在应该能有所体会指针或者引用的概念了吧。

重点二:警惕指针丢失和内存泄露
在写链表代码的时候,尤其是我们的指针,会不断的改变,指来指去的。所以在写的时候,一定注意不要弄丢了指针。
如下图中单链表的插入操作
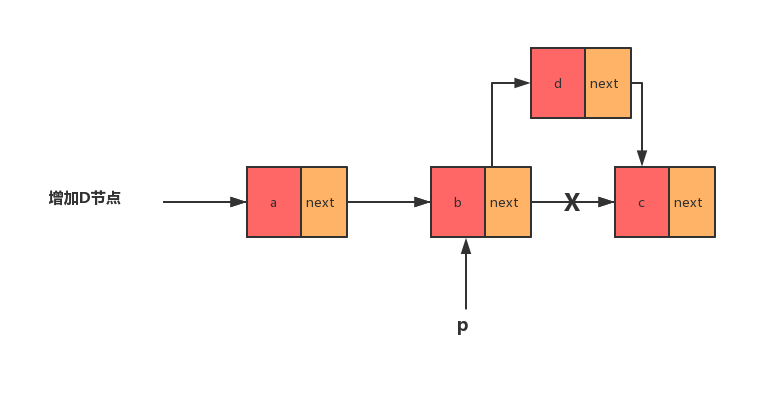
我们希望在结点 B 和相邻的结点 C 之间插入 D 结点。假设当前指针 p 指向 B 结点。如果你将代码实现成下面这个样子,就会发生指针丢失和内存泄露。
// 伪代码
p -> next = d; // 将 p 的 next 指针指向 D 结点;
d -> next = p -> next // 将 D 的结点的 next 指针指向 C? 结点。
我们来分析下:p -> next 指针在完成第一步操作后,已经不再指向结点 C 了,而是指向新增加的结点 D。第二行的代码相当于将 D 赋值给 d->next,自己指向自己。因此,整个链表也就被截断了。
所以我们添加结点时,一定要注意操作的顺序,要先将结点 D 的 next 指针指向结点 C,再把结点 B 的指针指向 D,这样才不会丢失指针。对于刚才的那段代码,你知道怎么修改才是正确的了吧。
重点三:重点留意边界条件处理
首先来回顾下刚才所说的单链表的插入操作。如果在 p 结点后面增加一个新的结点,只需要关注以下两步即可。
new_node -> next = p -> next;
p -> next = new_node;
但是,当我们向一个空链表中插入第一个结点时,就需要特殊处理了。当链表为空时,也就是链表的head为空,那直接赋值即可,如下:
if(head == null) {
head = new_node;
}
看一段完整的添加节点代码:
// 添加一个新结点 tail:表示尾结点
append(data) {
const node = new Node(data);
if (!this.head) {
this.head = node;
this.tail = this.head;
} else {
this.tail.next = node;
this.tail = node;
}
}
如果头结点不存在的话,头结点等于尾结点。如果头结点存在的话,利用尾结点来扩充链表的数据,别忘了再移动 tail 成为尾结点。
再来看单链表结点的删除操作。如果在p结点后删除一个结点,只需要关注一步即可:
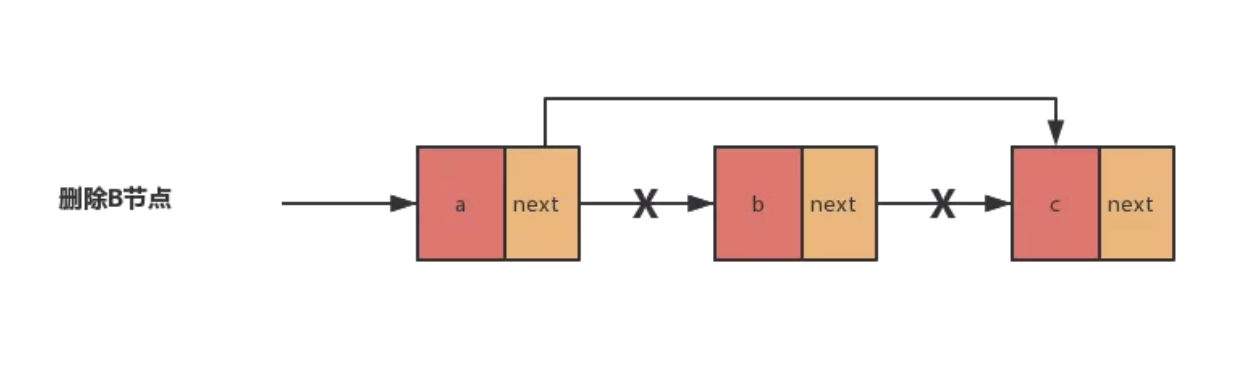
p -> next = p -> next -> next;
但是,当链表中只剩一个结点head时,也需要特殊处理才可以,如下:
if(head -> next == null){
head = null;
}
删除的代码逻辑请查看 github-链表-remove
我提供的方法比较繁琐,当阅读了《数据结构与算法JavaScript描述》的时候,发现书上写的方法特别简洁。在此分享一下。
以下是此书中的删除结点代码:
{
/*
首先根据要删除的元素,检查每一个结点的下一个结点中是否存储着要删除的数据。
如果找到,则返回该结点,即前一个结点。
*/
function findPvevious(item) {
var currNode = this.head;
while(!(currNode.next == null) && (currNode.next.element != item)) {
currNode = currNode.next;
}
return currNode;
}
// 然后找到前一个结点后,利用上文提到的单链表删除操作进行删除。
function remove(item) {
var prevNode = this.findPvevious(item);
if(!(prevNode.next == null)) {
prevNode.next = prevNode.next.next;
}
}
}
所以写链表代码时,要经常注意边界条件是否考虑到了:
- 如果链表为空时,代码是否能正常工作?
- 如果链表只有一个结点时,代码是否能正常工作?
- 如果在处理头结点和尾结点时,代码是否能正常工作?
重点四:要学会画图辅助思考
比如一些单链表的增删改查等,指针总是不断的改变。这个时候如果大脑思考不过来的话,可以简单的画个示意图辅助一下。比如说单链表的增加结点操作,可以画出增加前后的链表变化。
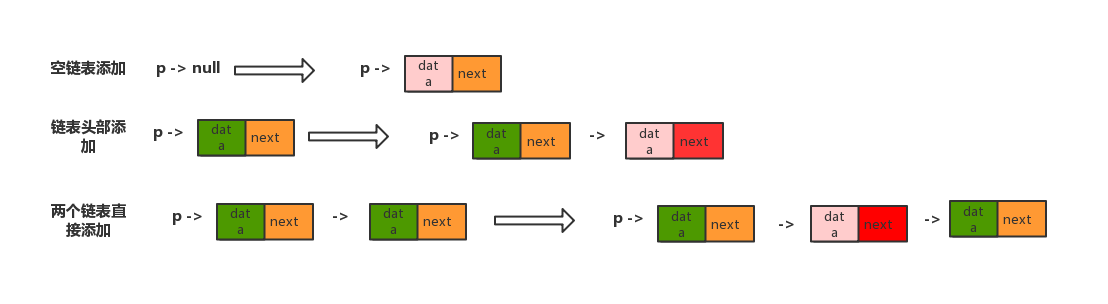
代码演示
请前往 github 查看 链表常见的方法
参考书籍
《数据结构与算法JavaScript描述》
有你才完美
链表这种数据结构,确实比较容易懂,但是想写出好相关的操作代码,确实不易,指针或者引用也是我的薄弱环节,指来指去便记不清该怎么指啦!动物的关节对于动物来讲非常的重要,指针感觉就是链表的关节,链表像一辆火车,每个车厢的连接全靠车厢间的连接轴。
