

0.前言
在上一篇文章里,已经对v2版本的koa中间件原理做了逐行分析,讲清楚了它的流程控制和异步方案。
但是,仍然有大量的基于koa的项目、框架、库在基于v1版本的koa在工作,而它的中间件是Generator函数,其运行机制与v2版本的koa中间件有比较大的不同。
因此,有必要解释清楚v1版本的koa中间件原理,作为对上一篇文章的补充,希望能对那些仍然在项目中使用v1版本koa的同行同学有所帮助。
PS:本文基于v1.6.2的koa源码,结构图如下:

1.响应机制
本段内容与上一篇文章大致相同,已经看过该文章的话,可以跳过这一节
与上一篇文章一样,先从一个简单的Demo开始,来看Koa的使用方式。
const Koa = require('koa');
const app = new Koa();
Koa变量指向是什么呢?我们知道:
require在查找第三方模块时,会查找该模块下package.json文件的main字段。
查看koa仓库目录下下package.json文件,可以看到模块暴露的出口是lib目录下的application.js文件
{
"main": "lib/application.js",
}
在lib/application文件中,可以看到其模块出口如下:
var app = Application.prototype;
module.exports = Application;
function Application(){}
好,现在来给我们的Demo添加中间件
const Koa = require('koa');
const app = new Koa();
const one = function* (next){
console.log('1-Start');
const t = yield next;
console.log('1-End');
}
const final = function* (next) {
console.log('final-Start');
this.body = { text: 'Hello World' };
console.log('final-End');
}
app.use(one);
app.use(final);
app.listen(3005);
以上这段代码中,ctx.body 如何实现并不是本文的重点,只要知道它的作用是设置响应体的数据,就可以了。
但是要弄清楚的关键有亮点
- app.use 的作用是挂载中间件,它做了什么?
- app.listen 的作用是监听端口,它做了哪些工作?
先来看use函数
app.use = function(fn){
// 省略与中间件机制无关的代码
this.middleware.push(fn);
return this;
};
根据上文提到的var app = Application.prototype;语句,可以知道use方法挂载到了Application.prototype上,因此每个实例都可以调用use。
use方法做的事情也很简单,把传入的函数,存入到实例的middleware数组当中。
再来看listen方法:
app.listen = function(){
// 省略无关代码
var server = http.createServer(this.callback());
return server.listen.apply(server, arguments);
};
如果曾使用过Node的[http]模块创建过简单的服务器应用的话,就会知道http.createServer的参数一个函数,函数的参数分别是请求对象request和相应对象response,即形如以下结构:
(req, res) => {
// Do Sth.
res.end('Hello World')
}
因此this.callback函数执行所返回的结果,也一定是这样一个结构,我们来看这个callback函数
app.callback = function(){
// 省略一些校验代码
var fn = this.experimental
? compose_es7(this.middleware)
: co.wrap(compose(this.middleware));
var self = this;
// 省略一些错误处理代码,与中间件机制没关系
return function handleRequest(req, res){
var ctx = self.createContext(req, res);
self.handleRequest(ctx, fn);
}
};
看到返回的handleRequest函数的结构了吗?它会被传递给http.createServer,因此在每次接收到请求时,都会执行该函数。
那好,再来看self.handleRequest函数。
app.handleRequest = function(ctx, fnMiddleware){
ctx.res.statusCode = 404;
onFinished(ctx.res, ctx.onerror);
fnMiddleware.call(ctx).then(function handleResponse() {
respond.call(ctx);
}).catch(ctx.onerror);
};
这个函数接受一个上下文ctx对象作为第一个参数,这里只要记住它是一个对象就可以,后面会被传递给每个中间件。它的第二个参数,是一个名为fnMiddleware的函数,它是什么呢?回过头去看app.handleRequest被执行的地方。
self.handleRequest(ctx, fn);
这里的fn又是什么?再去找fn的定义,发现
var fn = this.experimental
? compose_es7(this.middleware)
: co.wrap(compose(this.middleware));
原来fn是this.middleware经过一些处理后得到的函数,这些工作具体做了什么,后文会说。这里只要先记住fn是一个组合后的函数,执行了它,那么一系列中间件就会依次执行。
现在fn清楚了,也就是self.handleRequest函数的第二个参数就清楚了,接着刚刚没有说完的话题,看看这个self.handleRequest做了什么事。
function(ctx, fnMiddleware){
// 忽略其他非关键代码
fnMiddleware.call(ctx).then(function handleResponse() {
respond.call(ctx);
}).catch(ctx.onerror);
};
也很简单,以上下文ctx对象作为this,去调用fnMiddleware函数其返回的结果是一个Promise,并且使用了该Promise的then/catch方法,添加了两个流程:
- 请求相应:
respond.call(ctx) - 错误处理:
.catch(ctx.onerror)
所以,总结一下:
- use方法将中间件函数添加到自身的middleware数组上
- listen方法设置响应请求的函数,该函数中会执行中间件。当每次请求发起时,所执行的流程就是:请求 -> handleRequest函数 -> self.handleRequest函数 -> fnMiddleware函数。
好,v1版本的响应机制已经介绍完毕,各位也差不多能知道中间件是在什么时候执行的了。如果有不明白的地方,可以先看完上一篇讲v2版本Koa原理的文章(传送门)。
2.前置知识-Generator
与之前基于v2版本的koa相比,v1版本的koa,在中间件原理上有个重大的不同之处,即
v1版本的koa的执行工作,是交给Co库完成的,而v2则是自己完成的。
这话什么意思???这与Koa使用Generator函数作为中间件函数有关。
所以,在正式开始介绍v1版本koa的中间件原理之前,有一些前置知识要先解释清楚。
(已经熟悉Generator和Co库原理的各位,可以直接跳过介绍这两章)
2.1 Generator
Generator 是一种特殊的函数,它的执行结果是一个Iterator,即可迭代对象。
那Iterator又是什么呢? 可以这么说,任何一个对象,只要符合迭代器协议,就可以被认为是一个Iterator。通俗一点说,该协议所约定的对象,有两个关键点:
- 有next方法,连续执行next方法可以依次得到多个值
- 执行next方法,返回值的格式为 { value: xxx, done: Boolean },value为任意类型,done的值为Boolean,true表示迭代完成,false表示迭代未完成。
示例如下,下面的it对象,因为符合迭代器协议,就是一个Iterator(尽管它不是由Generator返回的)
var it = makeIterator(['a', 'b']);
it.next() // { value: "a", done: false }
it.next() // { value: "b", done: false }
it.next() // { value: undefined, done: true }
function makeIterator(array) {
var nextIndex = 0;
return {
next: function() {
return nextIndex < array.length ?
{value: array[nextIndex++], done: false} :
{value: undefined, done: true};
}
};
}
那么Iterator有什么用呢?它原本的作用,是用于自定义对象的迭代行为。
而为什么又要定义对象的迭代行为呢?按照阮一峰老师在Iterator和for...of循环里的说法
遍历器(Iterator)就是这样一种机制。它是一种接口,为各种不同的数据结构提供统一的访问机制。任何数据结构只要部署 Iterator 接口,就可以完成遍历操作(即依次处理该数据结构的所有成员)。
对此我的理解是,“定义对象的迭代行为”的意义,在于“为各种不同的数据结构提供统一的访问机制”,即把对于迭代的描述工作交给了数据结构自身,开发者只需调用单个API即可(即for...of...),这将会节约开发者记忆API的成本。正所谓“对象千万种,规范第一条;迭代不规范,开发泪两行”...
而如果要定义对象的迭代行为,就要在它的[Symbol.iterator]属性上,定义一个函数,并且返回一个符合迭代器协议的对象(即Iterator)。(参考:可迭代协议)。
比如,我们把上面的代码改一改,就可以使用for...of...来执行迭代了。
const arr = ['a', 'b'];
arr[Symbol.iterator] = function () {
let i = 0;
return {
next: function () {
const done = i >= arr.length;
if (!done) {
console.log('Not Done!')
return { value: arr[i++], done };
} else {
return { done };
}
}
}
}
for(let i of arr){}; // 输出两次Not Done
但是从上面的代码可以看到,何时完成迭代(控制done的值),每次迭代返回value值是什么,都交给了next函数来维护,需要写的维护代码较多。
这时候我们可以回到Generator函数了,因为Generator函数就是为此而生的。它为这种维护工作,提供了简化的写法,只要通过yield命令给出返回值就可以了,最后yield全部结束的时候。
arr[Symbol.iterator] = function* () {
for(let i = 0; i < arr.length; i++){
console.log(`输出文本:yield arr[${i}]`)
yield arr[i]
}
return ;
}
for(let i of arr){};
// 输出文本:yield arr[0]
// 输出文本:yield arr[1]
所以,个人认为,Generator函数是一种语法糖,它描述的是若干个代码块的分段执行顺序。
2.2 Generator与异步
既然Generator有分段执行的功能,就可以处理异步问题了。
不过,值得注意的是,yield并不是真正的异步逻辑,它只是把yield后面的值,在执行next方法的时候返回出去而已。比如当yield 后面的表达式返回的是一个Promise的时候:
function* gen1(){
yield 1;
yield new Promise(resolve => setTimeout(() => resolve(1), 1000));
yield 2;
}
const iterator = gen1();
开始跑iterator的next方法
iterator.next(); // {value: 1, done: false};
iterator.next(); // {value: Promise, done: false};
iterator.next(); // {value: 2, done: false};
看到了吗?第二句next方法只是返回了Promise对象而已,根本没有等着它的then回调执行。
所以,要想用Generator来做异步操作,其基本思路只能是如下:执行第一次next -> 等待promise 完成 -> 执行第二次next...举个例子:
var fetch = require('node-fetch');
function* gen(){
var url = 'https://api.github.com/users/github';
var result = yield fetch(url);
console.log(result.bio);
}
var g = gen();
var result = g.next();
// value是个Promise,下一次g.next执行要交给promise的then回调
result.value.then(function(data){
return data.json();
}).then(function(data){
g.next(data);
});
但是,这显然有问题:gen函数返回的Iterator,必须手动执行才能进行到下一个yield,不会自动执行。如果异步方案仅仅是如此,那开发者还不如自己写Promise链呢。
这就是co的作用了!它会:
- 把yield 变成“真正的异步等待语句”
- 自动执行next
3.前置知识-Co
3.1 基本使用方式
通常来说,我们使用co库,会像是现在这样
const co = require('co');
const mockTimeoutPromise = (data, timeout = 1000) => new Promise(resolve => {
setTimeout(() => {
console.log(data);
resolve(data)
}, timeout);
});
co(function* () {
yield mockTimeoutPromise(1);
const result = yield { name: 'co' };
return result;
})
.then(value => {
console.log(value);
})
接下来我们就用这份源代码,来分析co库到底是怎么做的
3.2 执行分析
可以看到,co函数接受了一个Generator函数作为参数。
function co(gen) {
var ctx = this;
var args = slice.call(arguments, 1)
return new Promise(function(resolve, reject) {
});
}
可以看到,co函数的返回值是一个Promise,它对应的是当次co函数内包裹的整个流程,一旦该Promise被resolved,就意味着co函数所接受的入参函数,其内部流程已经完全执行完毕。
好,接下来来Promise构造函数内部的内容。
首先是一段执行传入的Generator函数的代码,获得Iterator
// 在某些情况下,传入的gen参数本身就是一个Iterator对象,不是Generator函数,因此会做类型检查
if (typeof gen === 'function') gen = gen.apply(ctx, args);
// 确保获得的结果,是一个Iterator
if (!gen || typeof gen.next !== 'function') return resolve(gen);
接着就是开始执行onFulfilled函数。
onFulfilled();
function onFulfilled(res) {
var ret;
try {
ret = gen.next(res);
} catch (e) {
return reject(e);
}
next(ret);
return null;
}
在初次执行时,入参res的值为空,以刚刚提供的Demo来看,执行gen.next(res)得到的ret值,应该是这样的结构:
{
done: false, value: Promise
}
也就是说,其value值,是Demo代码中mockTimeoutPromise函数的执行结果。
接着,就把ret值传入next函数
function next(ret) {
if (ret.done) return resolve(ret.value);
var value = toPromise.call(ctx, ret.value);
if (value && isPromise(value)) return value.then(onFulfilled, onRejected);
return onRejected(new TypeError('You may only yield a function, promise, generator, array, or object, '
+ 'but the following object was passed: "' + String(ret.value) + '"'));
}
分析这段代码,其执行逻辑为:
- 检查传入的Iterator所对应的迭代流程是否已经结束,若结束,说明resolve函数结束整个流程。
- 用
toPromise函数将当前的迭代值,变成Promise类型 - 判断处理后的值是否存在 且 为Promise,则添加一个then回调,继续执行onFulfilled和用onRejected处理错误。
- 若co所执行的流程内,yield关键字后跟着的不是yieldable类型的,则抛出错误。
在初次流程中,由于是第一句yield,所以ret.done为false,开始执行toPromise逻辑,接着来看toPromise函数
function toPromise(obj) {
if (!obj) return obj;
if (isPromise(obj)) return obj;
if (isGeneratorFunction(obj) || isGenerator(obj)) return co.call(this, obj);
if ('function' == typeof obj) return thunkToPromise.call(this, obj);
if (Array.isArray(obj)) return arrayToPromise.call(this, obj);
if (isObject(obj)) return objectToPromise.call(this, obj);
return obj;
}
这段代码的主要功能是将各种类型的值,包裹成了Promise值,其中各个转换函数的逻辑在这里不是重点,因此不加详细阐述。
因此,如果我们写出这样的代码
yield 2;
yield 3;
toPromise就会直接返回这些被yield的常量值,而不转化为promise类型。这时候我们再回到toPromise被执行的位置,即next函数内部,就会发现无法通过value && isPromise(value)校验,就会走onRejected报错。
这也是为什么,我们有时候会看见这样的错误
You may only yield a function, promise, generator, array, or object, but the following object was passed: "2"
就是因为我们yield了一个非yieldables的值。
回到toPromise函数,其中有两个转换逻辑非常值得一提:
一是对于Generator的识别:如果识别为是Generator函数或者Generator函数所返回的Iterator,就会再次用co包裹一层,返回一个Promise。
if (isGeneratorFunction(obj) || isGenerator(obj)) return co.call(this, obj);
其中:
isGeneratorFunction函数识别参数是否为Generator函数isGenerator函数识别参数是否被Generator函数返回的Iterator
私人吐槽时间:isGenerator函数也许改名为isIteratorOfGenerator也许更标准一点。
二则是objectToPromise,通常我们在使用yield的时候,会看见这样的逻辑:
const { result1, result2 } = yield {
result1: Promise1,
result2: Promise2
}
这是怎么做到的呢?其实是依靠objectToPromise函数,它的代码逻辑如下:
function objectToPromise(obj){
var results = new obj.constructor();
var keys = Object.keys(obj);
var promises = [];
for (var i = 0; i < keys.length; i++) {
var key = keys[i];
var promise = toPromise.call(this, obj[key]);
if (promise && isPromise(promise)) defer(promise, key);
else results[key] = obj[key];
}
return Promise.all(promises).then(function () {
return results;
});
function defer(promise, key) {
// predefine the key in the result
results[key] = undefined;
promises.push(promise.then(function (res) {
results[key] = res;
}));
}
}
它主要是做了这么几件事:
- 基于同一个constructor构建一个空对象result,保证类型一致。
var results = new obj.constructor();
var keys = Object.keys(obj);
- 新建一个promises数组,标记当前对象中「有哪些key对应的值需要“等待”」
var promises = [];
- 遍历当前对象的key,把key对象的value执行toPromise函数
for (var i = 0; i < keys.length; i++) {
var key = keys[i];
var promise = toPromise.call(this, obj[key]);
}
- 如果成功转换为Promise,执行defer函数,构建一个新Promise表示“等待原Promise完成后,再把获得的结果值赋值到result对象上”,推到promises数组当中,表明当前key对应的值需要“等待”之后,才可以获得值。
if (promise && isPromise(promise)) defer(promise, key);
function defer(promise, key) {
// predefine the key in the result
results[key] = undefined;
promises.push(promise.then(function (res) {
results[key] = res;
}));
}
- 如果是非yieldable值不能被转成Promise类型,直接把该value值赋值到新的result对象上(这些值不需要等待就可以获得结果,所以不需要把它们包装之后推入到promises数组中)
else results[key] = obj[key];
- 等待所有被推入promises数组中的Promise被resolve,即所有要等待的值,都等到了结果。
return Promise.all(promises).then(function () {
return results;
});
好,回到刚刚的toPromise函数,由于Demo代码里的第一句是
yield mockTimeoutPromise(1);
所以toPromise函数会执行第二句
if (isPromise(obj)) return obj;
因此可以通过next函数的isPromise校验
if (value && isPromise(value)) return value.then(onFulfilled, onRejected);
好,第一轮循环至此结束,再也没有其他代码要执行了。
接下来,因为mockTimeoutPromise函数默认的超时值timeout为1000,所以1秒之后,上面的value(是一个Promise)被resolve,开始继续执行onFulfilled函数
function onFulfilled(res) {
var ret;
try {
ret = gen.next(res);
} catch (e) {
return reject(e);
}
next(ret);
return null;
}
此时,ret的返回结构为
{
done: false,
value: { name: 'co' };
}
因此会继续执行 next函数 -> toPromise函数 -> objectToPromise函数。因此,toPromise函数会得到这样一个结果
Promise
[[PromiseStatus]]: "resolved"
[[PromiseValue]]: Object
因此也可以通过next函数的isPromise校验,至此第二轮yield结束。
接下来
ret = gen.next(res);
得到的ret.done值为true,所以第三次执行next函数,就会走
if (ret.done) return resolve(ret.value);
至此,整个流程结束。
3.3 小结
好,Co的工作流程已经大致理清楚,在此做个小结:
-> 包裹一层Promise,用以判断当前整个异步流程终结
-> 执行传入的Generator函数,获得Iterator
-> 执行Iterator对象的next方法,获得当前值value/done
-> 若done为false,包装value值为Promise,在该Promise的then/catch回调中,执行下一次next
-> 若done为true,整个流程已终结,将外层Promise给resolved。
4.中间件执行
如果暂时没有理解前置知识相关章节的代码,可以直接看下面的几点总结(看懂的可以跳过)
Generator函数:
- 用于描述对象的迭代行为
- 返回的值,是一个具有next方法的对象,即所谓的Iterator对象
co函数库
- 会帮助Generator函数进行自动执行next方法以进行迭代
- 把yield方法变成了真正的异步逻辑。
好了,有了这些基础知识,我们可以开始看中间件的执行了。
在第一节的“请求响应机制”部分提到,fnMiddlewawre是一个把所有中间件组合后得到的函数,它会在每次收到请求的时候执行,来看它的组合代码
var fn = this.experimental
? compose_es7(this.middleware)
: co.wrap(compose(this.middleware));
查遍koa v1.6.2的源码,发现experimental属性并没有赋值语句,所以我们可以认为,只要你不写这样的代码
const app = new Koa();
app.experimental = true;
那么,experimental始终会是undefined,也就是一个falsy的值。它一定会走的是
co.wrap(compose(this.middleware));
于是,我们就有两件事情要说清楚:
- co.wrap做了什么
- compose做了什么
4.1 co-wrap
先说co-wrap,因为它非常简单
co.wrap = function (fn) {
createPromise.__generatorFunction__ = fn;
return createPromise;
function createPromise() {
return co.call(this, fn.apply(this, arguments));
}
};
它接受一个函数fn,返回另一个函数createPromise。
从上面的代码可以知道,返回的createPromise,就是fnMiddleware函数,而fnMiddleware的执行语句是这样的:
fnMiddleware.call(ctx)
所以createPromise在得到执行时,内部的this,就是上下文ctx对象。
而这createPromise函数的职责也很简单,就是把传入的fn参数,用co库来执行了一遍。
所以,我们来看compose函数做了什么。
4.2 koa-compose
查找顶部引入模块的语句,可以看到
var compose = require('koa-compose');
好,我们来看koa-compose的模块,到底是什么功能
PS:koa-compose基于2.5.1;
module.exports = compose;
// 空函数
function *noop(){}
function compose(middleware){
// 这个被返回的函数,就是传给co-wrap的fn参数
return function *(next){
if (!next) next = noop();
var i = middleware.length;
while (i--) {
next = middleware[i].call(this, next);
}
return yield *next;
}
}
我们还是用一个Demo来看:
const Koa = require('koa');
const app = new Koa();
const one = function* (next){
console.log('1-Start');
const r = yield Promise.resolve(1);
const t = yield next;
console.log('1-End');
}
const final = function* (next) {
console.log('final-Start');
this.body = { text: 'Hello World' };
console.log('final-End');
}
app.use(one);
app.use(final);
app.listen(3005);
因此,middleware得到的结果是[one, final],它们都是Generator函数,因此,执行下列语句的时候
// 由于fnMiddleware.call(ctx)语句,未传入第二个参数,因此初次调用时候next为空,变成noop函数
if (!next) next = noop();
var i = middleware.length;
// 第一次 i 为 2
var i = middleware.length;
// i--返回值为2,i--之后i变为1
while (i--) {
next = middleware[i].call(this, next);
}
第一次执行时,middleware[i]即是middleware[1],即final函数。此时,入参next为noop函数,返回的next,指向final中间件执行后所返回的Iterator对象。
而下一次循环发生时
// i--返回值为1,i--之后i变为0
while (i--) {
next = middleware[i].call(this, next);
}
此时middleware[i].call(this, next);,入参next,是final中间件返回的Iterator对象,即one中间件函数中的next参数
// 这个next参数是final中间件的Iterator噢
const one = function* (next){
console.log('1-Start');
const r = yield Promise.resolve(1);
const t = yield next;
console.log('1-End');
}
而返回的next则是one中间件函数执行所返回的Iterator。
再下一次循环发生时,此时循环不会发生
// i--返回值为0,i--之后i变为-1,不执行循环。
while (i--) {
next = middleware[i].call(this, next);
}
// 开始走return逻辑
return yield *next;
此时next即为one中间件函数执行所返回的Iterator。
所以,koa-compose完成的工作,主要在于通过函数的组合,实现了next参数,即迭代器对象Iterator的传递。
4.3 关于yield *next
根据yield*关键字,yield *next相当于yield one中间件的代码
yield (
console.log('1-Start');
const r = yield Promise.resolve(1);
const t = yield next;
console.log('1-End');
)
但为什么这里要写yield *next,直接yield next不好吗?
个人认为,由于co函数会识别yield关键字后面的值的类型并转化为Promise,即依次执行 toPromise函数 -> if (isGeneratorFunction(obj) || isGenerator(obj)) return co.call(this, obj);,因此使用yield*和yield,在执行流程上没有本质的区别。
但是,为什么用yield_呢?我的理解是,由于最外层的next几乎可以确定是一个Iterator,所以直接使用yield _,可以减少一层co函数的调用。
4.4 中间件的执行
由之前的分析可以知道,fnMiddleware,实际上相当于这样的结构
co(function*(next){
if (!next) next = noop();
var i = middleware.length;
while (i--) {
next = middleware[i].call(this, next);
}
return yield *next;
})
所以,第一步,yield *next会帮助我们去等待next迭代器完成迭代,而这个next,就是one中间件的迭代器。而在one中间件里,可以看到第一步是
console.log('1-Start');
const r = yield Promise.resolve(1);
在co的自动执行流程中,会等着这个Promise完成,才会进行下一个yield。
而下一步,在one中间件中,则是
const t = yield next;
前面提到,one中间件函数的入参next,是final中间件返回的Iterator
而co会识别到这个next是一个Iterator,进而在toPromise函数中走包装Iterator为Promise的逻辑
if (isGeneratorFunction(obj) || isGenerator(obj)) return co.call(this, obj);
因此,在one中间件中执行yield next时,会等到final中间件完全执行完毕后,再回过头来执行下一个yield语句。当然,one中间件已经没有下一个yield语句了,因此它自身对应的next对象,也就执行完毕了。
用一段伪代码来描述,就是这样的:
yield (
console.log('1-Start');
const r = yield Promise.resolve(1);
const t = yield (
console.log('final-Start');
this.body = { text: 'Hello World' };
console.log('final-End');
)
console.log('1-End');
)
可以看到,这就是Koa所说的洋葱圈模型:
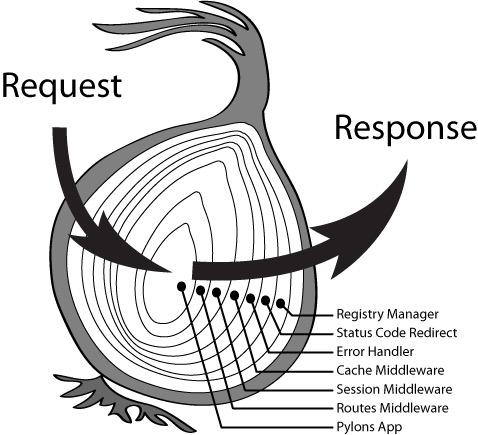
如果我们把one中间件的代码改改
const one = function* (next) {
console.log('one-Start');
this.body = { text: 'Hello World' };
console.log('one-End');
}
相当于在one中间件里,并没有通过yield next语句,来等待下一个中间件,也就是final中间件的执行完毕。因此可以说,next参数就是one中间件对于下一个中间件“是否执行”的控制权。
5 小结
至此,v1版本koa的中间件执行机制已经全部介绍完毕。
与Koa v2相比,Koa v1的流程控制方案是一致的,都是把下一个中间件的执行权,通过传参数的方式,交给了当前中间件。
但不同的是,Koa v2传递的是包装后的中间件函数本身,所以「下一个中间件的执行工作」,是当前中间件函数自己完成的。而Koa v1,则只是传递了迭代器对象Iterator,中间件函数只是描述了执行流程,具体的执行工作是交给Co工具库来完成的。
而Koa v1的异步逻辑,也是交给Co库完成。它通过判断迭代器执行next方法所返回的值的类型,并通过toPromise函数转化成Promise类型的指,待该Promise被resolve时,再来下一次next方法执行的时机,进而实现了异步逻辑。
关于我们
我们是蚂蚁保险体验技术团队,来自蚂蚁金服保险事业群(杭州/上海)。我们是一个年轻的团队(没有历史技术栈包袱),目前平均年龄92年(去除一个最高分8x年-团队leader,去除一个最低分97年-实习小老弟)。我们支持了阿里集团几乎所有的保险业务。18年我们产出的相互宝轰动保险界,19年我们更有多个重量级项目筹备动员中。现伴随着事业群的高速发展,团队也在迅速扩张,欢迎各位前端高手加入我们~
我们希望你是:技术上基础扎实、某领域深入(Node/互动营销/数据可视化等);学习上善于沉淀、持续学习;性格上乐观开朗、活泼外向。
如有兴趣加入我们,欢迎发送简历至邮箱:shuzhe.wsz@alipay.com
本文作者:蚂蚁保险-体验技术组-渐臻
掘金地址:DC大锤
