

接着上篇文章 深入浅出学习决策树(一) 继续介绍决策树相关内容。
回归问题中的决策树
在预测数值变量时,构造树的想法保持不变,但质量标准会发生变化。
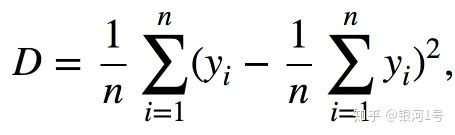
其中n是叶子中的样本数,Yi是目标变量的值。简单地说,通过最小化均值周围的方差,我们寻找以这样的方式划分训练集的特征,即每个叶子中的目标特征的值大致相等。
例
让我们生成一些由函数分配并带有一些噪音的数据。
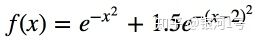
然后我们将在其上训练一棵树并显示它所做的预测。
n_train = 150
n_test = 1000
noise = 0.1
def f(x):
x = x.ravel()
return np.exp(-x ** 2) + 1.5 * np.exp(-(x - 2) ** 2)
def generate(n_samples, noise):
X = np.random.rand(n_samples) * 10 - 5
X = np.sort(X).ravel()
y = np.exp(-X ** 2) + 1.5 * np.exp(-(X - 2) ** 2) + \
np.random.normal(0.0, noise, n_samples)
X = X.reshape((n_samples, 1))
return X, y
X_train, y_train = generate(n_samples=n_train, noise=noise)
X_test, y_test = generate(n_samples=n_test, noise=noise)
from sklearn.tree import DecisionTreeRegressor
reg_tree = DecisionTreeRegressor(max_depth=5, random_state=17)
reg_tree.fit(X_train, y_train)
reg_tree_pred = reg_tree.predict(X_test)
plt.figure(figsize=(10, 6))
plt.plot(X_test, f(X_test), "b")
plt.scatter(X_train, y_train, c="b", s=20)
plt.plot(X_test, reg_tree_pred, "g", lw=2)
plt.xlim([-5, 5])
plt.title("Decision tree regressor, MSE = %.2f" % np.sum((y_test - reg_tree_pred) ** 2))
plt.show()
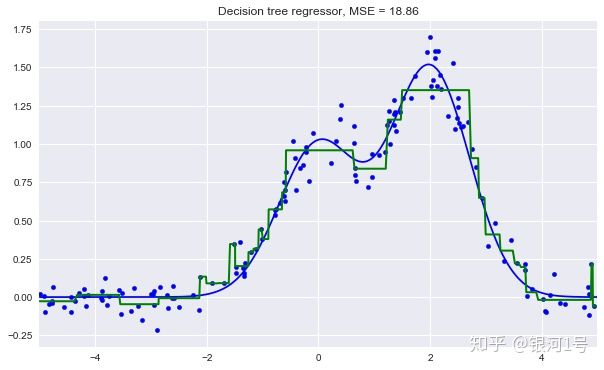
我们看到决策树用分段常数函数逼近数据。
3.最近邻法
最近邻方法(k-Nearest Neighbors,或k-NN)是另一种非常流行的分类方法,有时也用于回归问题。与决策树一样,这是最易于理解的分类方法之一。潜在的直觉是你看起来像你的邻居。更正式地,该方法遵循紧凑性假设:如果足够好地测量示例之间的距离,则类似示例更可能属于同一类。
根据最近邻法,绿球将被分类为“蓝色”而不是“红色”。

再举一个例子,如果您不知道如何在在线列表上标记蓝牙耳机,您可以找到5个类似的耳机,如果其中4个被标记为“配件”,只有1个被标记为“技术”,那么你还会在“配件”下标注它。
要对测试集中的每个样本进行分类,需要按顺序执行以下操作:
- 计算训练集中每个样本的距离。
- 从训练集中选择k个样本,距离最小。
- 测试样本的类别将是那些k个最近邻居中最常见的类别。
该方法非常容易适应回归问题:在步骤3中,它不返回类,而是返回数字 - 邻居之间目标变量的平均值(或中值)。
这种方法的一个显着特点是它的懒惰 - 计算只在预测阶段进行,当需要对测试样本进行分类时。预先没有从训练样例构建模型。相反,回想一下,对于本文前半部分的决策树,树是基于训练集构建的,并且测试用例的分类通过遍历树而相对快速地发生。
最近邻是一种经过深入研究的方法。存在许多重要的定理,声称在“无穷无尽”的数据集上,它是最佳的分类方法。经典着作“统计学习要素”的作者认为k-NN是理论上理想的算法,其使用仅受计算能力和维数灾难的限制。
真实应用中最近邻方法
- 在某些情况下,k-NN可以作为一个良好的起点(基线);
- 在Kaggle比赛中,k-NN通常用于构建元特征(即k-NN预测作为其他模型的输入)或用于堆叠/混合;
- 最近邻居方法扩展到推荐系统等其他任务。最初的决定可能是在我们想要提出建议的人的最近邻居中受欢迎的产品(或服务)的推荐;
- 实际上,在大型数据集上,近似搜索方法通常用于最近邻居。有许多开源库可以实现这样的算法; 看看Spotify的图书馆Annoy。
使用k-NN进行分类/回归的质量取决于几个参数:
- 邻居的数量k。
- 样本之间的距离度量(常见的包括汉明,欧几里得,余弦和闵可夫斯基距离)。请注意,大多数这些指标都需要缩放数据。简单来说,我们不希望“薪水”功能(大约数千)影响距离超过“年龄”,通常小于100。
- 邻居的权重(每个邻居可以贡献不同的权重;例如,样本越远,权重越低)。
类KNeighborsClassifier在Scikit学习
该类的主要参数sklearn.neighbors.KNeighborsClassifier是:
- 权重:(
uniform所有权重相等),distance(权重与测试样本的距离成反比),或任何其他用户定义的函数; - 算法(可选):
brute,ball_tree,KD_tree或auto。在第一种情况下,通过训练集上的网格搜索来计算每个测试用例的最近邻居。在第二和第三种情况下,示例之间的距离存储在树中以加速找到最近邻居。如果将此参数设置为auto,则将根据训练集自动选择查找邻居的正确方法。 - leaf_size(可选):如果查找邻居的算法是BallTree或KDTree,则切换到网格搜索的阈值;
- 指标:
minkowski,manhattan,euclidean,chebyshev,或其他。
4.选择模型参数和交叉验证
学习算法的主要任务是能够探索到看不见的数据。由于我们无法立即检查新的传入数据的模型性能(因为我们还不知道目标变量的真实值),因此有必要牺牲一小部分数据来检查模型的质量。
这通常以两种方式之一完成:
- 留出数据集的一部分(保留/保持集)。我们保留训练集的一小部分(通常从20%到40%),在剩余数据上训练模型(原始集合的60-80%),并计算模型的性能指标(例如准确度) - 套装。
- 交叉验证。这里最常见的情况是k折交叉验证。
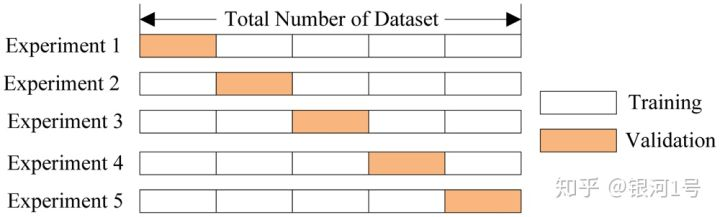
在k倍交叉验证中,模型在原始数据集的不同(K-1)子集上训练K次(白色)并检查剩余子集(每次都是不同的子集,如上所示以橙色表示)。我们获得K模型质量评估,通常是平均值,以给出分类/回归的总体平均质量。
与保持集方法相比,交叉验证可以更好地评估新数据的模型质量。但是,当您拥有大量数据时,交叉验证在计算上非常昂贵。
交叉验证是机器学习中非常重要的技术,也可以应用于统计和计量经济学。它有助于超参数调整,模型比较,特征评估等。更多细节可以在这里找到(Sebastian Raschka的博客文章)或任何关于机器(统计)学习的经典教科书。
5.应用实例和复杂案例
客户流失预测任务中的决策树和最近邻法
让我们将数据读入DataFrame并预处理它。暂时将状态存储在单独的Series对象中,并将其从数据框中删除。我们将训练没有State功能的第一个模型,然后我们将看看它是否有帮助。
df = pd.read_csv('../../data/telecom_churn.csv')
df['International plan'] = pd.factorize(df['International plan'])[0]
df['Voice mail plan'] = pd.factorize(df['Voice mail plan'])[0]
df['Churn'] = df['Churn'].astype('int')
states = df['State']
y = df['Churn']
df.drop(['State', 'Churn'], axis=1, inplace=True)

让我们为训练(X_train,y_train)分配70%的集合,为保留集合(X_holdout,y_holdout)分配30%。保持装置不会参与调整模型的参数。我们将在调整结束后使用它来评估最终模型的质量。让我们训练2个模型:决策树和k-NN。我们不知道哪些参数是好的,所以我们假设一些随机的参数:树深度为5,最近邻居的数量等于10。
from sklearn.model_selection import train_test_split, StratifiedKFold
from sklearn.neighbors import KNeighborsClassifier
X_train, X_holdout, y_train, y_holdout = train_test_split(df.values, y,
test_size=0.3, random_state=17)
tree = DecisionTreeClassifier(max_depth=5, random_state=17)
knn = KNeighborsClassifier(n_neighbors=10)
tree.fit(X_train, y_train)
knn.fit(X_train, y_train)
让我们用一个简单的指标评估保留集的预测质量 - 正确答案的比例(准确度)。决策树做得更好 - 正确答案的百分比约为94%(决策树)与88%(k-NN)。请注意,此性能是通过使用随机参数实现的。
from sklearn.metrics import accuracy_score
tree_pred = tree.predict(X_holdout)
print(accuracy_score(y_holdout, tree_pred)) # 0.94
knn_pred = knn.predict(X_holdout)
print(accuracy_score(y_holdout, knn_pred)) # 0.88
现在,让我们使用交叉验证来识别树的参数。我们将调整每个分割时使用的最大深度和最大特征数。以下是GridSearchCV如何工作的本质:对于每个唯一的值对,max_depth并max_features使用5倍交叉验证计算模型性能,然后选择最佳的参数组合。
from sklearn.model_selection import GridSearchCV, cross_val_score
tree_params = {'max_depth': range(1,11),
'max_features': range(4,19)}
tree_grid = GridSearchCV(tree, tree_params,
cv=5, n_jobs=-1,
verbose=True)
tree_grid.fit(X_train, y_train)
让我们列出交叉验证的最佳参数和相应的平均精度。
print(tree_grid.best_params_) # {'max_depth': 6, 'max_features': 17}
print(tree_grid.best_score_) # 0.942
print(accuracy_score(y_holdout, tree_grid.predict(X_holdout))) # 0.946
让我们画出结果树。由于它不完全是玩具示例(其最大深度为6),因此图片并不小,但如果您在本地打开从课程仓库下载的相应图片,则可以仔细浏览树的全貌。
dot_data = StringIO()
export_graphviz(tree_grid.best_estimator_, feature_names=df.columns,
out_file=dot_data, filled=True)
graph = pydotplus.graph_from_dot_data(dot_data.getvalue())
Image(value=graph.create_png())

现在,让我们调整k-NN 的邻居k的数量:
from sklearn.pipeline import Pipeline
from sklearn.preprocessing import StandardScaler
knn_pipe = Pipeline([('scaler', StandardScaler()),
('knn', KNeighborsClassifier(n_jobs=-1))])
knn_params = {'knn__n_neighbors': range(1, 10)}
knn_grid = GridSearchCV(knn_pipe, knn_params,
cv=5, n_jobs=-1, verbose=True)
knn_grid.fit(X_train, y_train)
print(knn_grid.best_params_, knn_grid.best_score_)
# ({'knn__n_neighbors': 7}, 0.886)
这里,树被证明比最近邻算法更好:交叉验证和保持的准确率分别为94.2%/ 94.6%。决策树表现得非常好,甚至随机森林(现在让我们把它想象成一堆一起工作得更好的树木)在这个例子中,尽管训练时间更长,却无法达到更好的性能(95.1%/ 95.3%)。
from sklearn.ensemble import RandomForestClassifier
forest = RandomForestClassifier(n_estimators=100, n_jobs=-1,
random_state=17)
print(np.mean(cross_val_score(forest, X_train, y_train, cv=5))) # 0.949
forest_params = {'max_depth': range(1, 11), 'max_features': range(4, 19)}
forest_grid = GridSearchCV(forest, forest_params,
cv=5, n_jobs=-1, verbose=True)
forest_grid.fit(X_train, y_train)
print(forest_grid.best_params_, forest_grid.best_score_)
# ({'max_depth': 9, 'max_features': 6}, 0.951)
决策树的复杂案例
为了继续讨论相关方法的优缺点,让我们考虑一个简单的分类任务,其中一棵树表现良好但是以“过于复杂”的方式进行。让我们在一个平面上创建一组点(2个特征),每个点将是两个类中的一个(红色为+1,黄色为-1)。如果将其视为分类问题,则看起来非常简单:类由一行分隔。
def form_linearly_separable_data(n=500, x1_min=0, x1_max=30,
x2_min=0, x2_max=30):
data, target = [], []
for i in range(n):
x1 = np.random.randint(x1_min, x1_max)
x2 = np.random.randint(x2_min, x2_max)
if np.abs(x1 - x2) > 0.5:
data.append([x1, x2])
target.append(np.sign(x1 - x2))
return np.array(data), np.array(target)
X, y = form_linearly_separable_data()
plt.scatter(X[:, 0], X[:, 1], c=y, cmap='autumn', edgecolors='black');
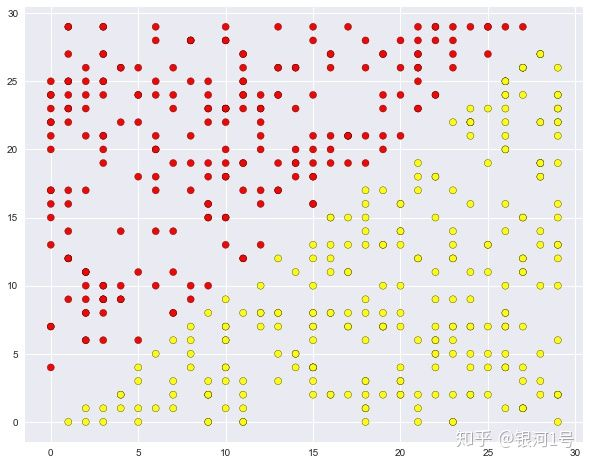
但是,决策树构建的边界过于复杂; 加上树本身很深。另外,想象一下,树会对训练集的30 x 30方格以外的空间进行推广有多么糟糕。
tree = DecisionTreeClassifier(random_state=17).fit(X, y)
xx, yy = get_grid(X)
predicted = tree.predict(np.c_[xx.ravel(), yy.ravel()]).reshape(xx.shape)
plt.pcolormesh(xx, yy, predicted, cmap='autumn')
plt.scatter(X[:, 0], X[:, 1], c=y, s=100,
cmap='autumn', edgecolors='black', linewidth=1.5)
plt.title('Easy task. Decision tree complexifies everything');
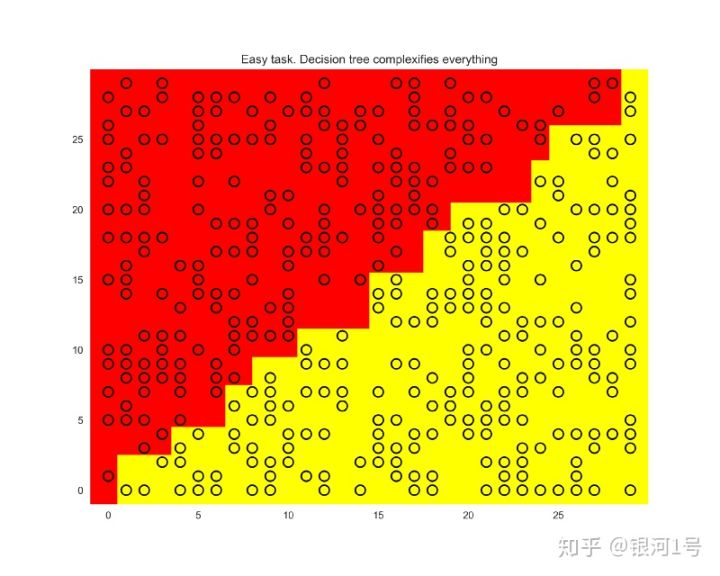
虽然解决方案只是一条直线x1 = x2,但我们得到了这种过于复杂的结构。
dot_data = StringIO()
export_graphviz(tree, feature_names=['x1', 'x2'],
out_file=dot_data, filled=True)
graph = pydotplus.graph_from_dot_data(dot_data.getvalue())
Image(value=graph.create_png())
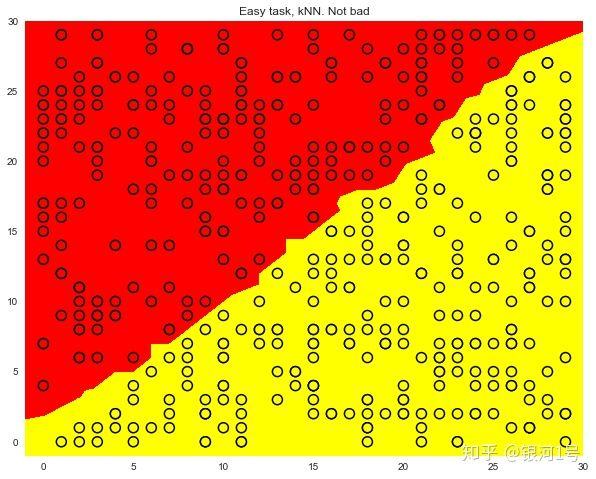
一个最近邻居的方法比树更好,但仍然不如线性分类器(我们的下一个主题)。
knn = KNeighborsClassifier(n_neighbors=1).fit(X, y)
xx, yy = get_grid(X)
predicted = knn.predict(np.c_[xx.ravel(), yy.ravel()]).reshape(xx.shape)
plt.pcolormesh(xx, yy, predicted, cmap='autumn')
plt.scatter(X[:, 0], X[:, 1], c=y, s=100,
cmap='autumn', edgecolors='black', linewidth=1.5);
plt.title('Easy task, kNN. Not bad');
MNIST手写数字识别任务中的决策树和k-NN
现在让我们看看这两种算法如何在现实世界中执行任务。我们将sklearn在手写数字上使用内置数据集。这个任务就是k-NN工作得非常好的例子。
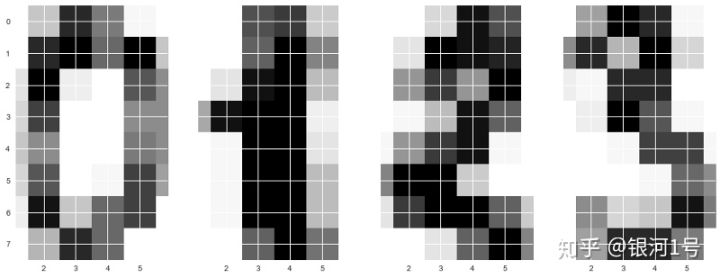
这里的图片是8x8矩阵(每个像素的白色强度)。然后将每个这样的矩阵“展开”到长度为64的向量中,并且我们获得对象的特征描述。
我们画一些手写的数字。我们看到它们是可区分的。
from sklearn.datasets import load_digits
data = load_digits()
X, y = data.data, data.target
f, axes = plt.subplots(1, 4, sharey=True, figsize=(16, 6))
for i in range(4):
axes[i].imshow(X[i,:].reshape([8,8]), cmap='Greys');
接下来,让我们进行与上一个任务相同的实验,但是,这一次,让我们更改可调参数的范围。
让我们选择70%的数据集用于训练(X_train,y_train)和30%用于训练(X_holdout,y_holdout)。保持集不参与模型参数调整; 我们将在最后使用它来检查结果模型的质量。
X_train, X_holdout, y_train, y_holdout = train_test_split(X, y, test_size=0.3,
random_state=17)
让我们用随机参数训练决策树和k-NN,并对我们的保持集进行预测。我们可以看到k-NN做得更好,但请注意这是随机参数。
tree = DecisionTreeClassifier(max_depth=5, random_state=17)
knn = KNeighborsClassifier(n_neighbors=10)
tree.fit(X_train, y_train)
knn.fit(X_train, y_train)
tree_pred = tree.predict(X_holdout)
knn_pred = knn.predict(X_holdout)
print(accuracy_score(y_holdout, knn_pred),
accuracy_score(y_holdout, tree_pred))
# (0.97, 0.666)
现在让我们像以前一样使用交叉验证来调整我们的模型参数,但是现在我们将考虑到我们拥有比上一个任务更多的功能:64。
tree_params = {'max_depth': [1, 2, 3, 5, 10, 20, 25, 30, 40, 50, 64],
'max_features': [1, 2, 3, 5, 10, 20 ,30, 50, 64]}
tree_grid = GridSearchCV(tree, tree_params, cv=5, n_jobs=-1,
verbose=True)
tree_grid.fit(X_train, y_train)
让我们看看最佳参数组合以及交叉验证的相应准确度:
print(tree_grid.best_params_, tree_grid.best_score_)
# ({'max_depth': 20, 'max_features': 64}, 0.844)
这已经超过了66%但不是97%。k-NN在此数据集上的效果更好。在一个最近邻居的情况下,我们能够在交叉验证上达到99%的猜测。
print(np.mean(cross_val_score(KNeighborsClassifier(n_neighbors=1),
X_train, y_train, cv=5))) # 0.987
让我们在同一个数据集上训练一个随机森林,它在大多数数据集上比k-NN更好。但我们这里有一个例外。
print(np.mean(cross_val_score(RandomForestClassifier(random_state=17),
X_train, y_train, cv=5))) # 0.935
你指出我们RandomForestClassifier在这里没有调整任何参数是正确的。即使进行调整,训练精度也不会像一个最近邻居那样达到98%。
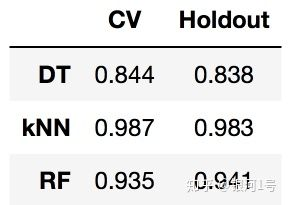
这个实验的结论(以及一般建议):首先检查数据上的简单模型:决策树和最近邻居(下次我们还将逻辑回归添加到此列表中)。情况可能就是这些方法已经足够好了。
最近邻法的复杂案例
让我们考虑另一个简单的例子。在分类问题中,其中一个特征将与响应矢量成比例,但这对最近邻方法没有帮助。
def form_noisy_data(n_obj=1000, n_feat=100, random_seed=17):
np.seed = random_seed
y = np.random.choice([-1, 1], size=n_obj)
# first feature is proportional to target
x1 = 0.3 * y
# other features are noise
x_other = np.random.random(size=[n_obj, n_feat - 1])
return np.hstack([x1.reshape([n_obj, 1]), x_other]), y
X, y = form_noisy_data()
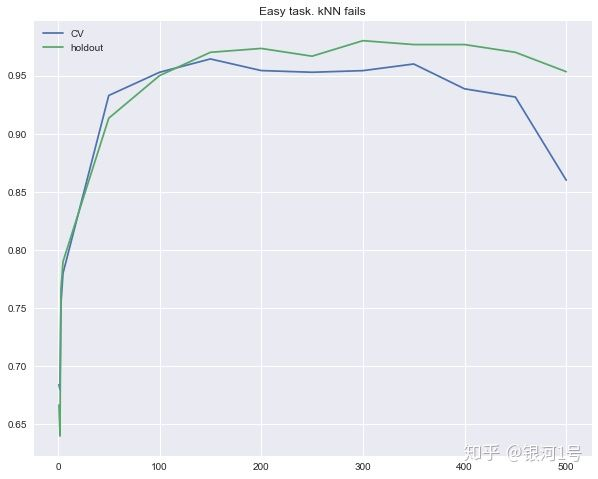
与往常一样,我们将研究交叉验证和保持集的准确性。让我们构造反映这些量对n_neighbors最近邻方法中参数的依赖性的曲线。这些曲线称为验证曲线。
可以看出,即使你在很大范围内改变最近邻居的数量,具有欧几里德距离的k-NN也不能很好地解决问题。
X_train, X_holdout, y_train, y_holdout = train_test_split(X, y, test_size=0.3,
random_state=17)
from sklearn.model_selection import cross_val_score
cv_scores, holdout_scores = [], []
n_neighb = [1, 2, 3, 5] + list(range(50, 550, 50))
for k in n_neighb:
knn = KNeighborsClassifier(n_neighbors=k)
cv_scores.append(np.mean(cross_val_score(knn, X_train, y_train, cv=5)))
knn.fit(X_train, y_train)
holdout_scores.append(accuracy_score(y_holdout, knn.predict(X_holdout)))
plt.plot(n_neighb, cv_scores, label='CV')
plt.plot(n_neighb, holdout_scores, label='holdout')
plt.title('Easy task. kNN fails')
plt.legend();
相反,尽管对最大深度有限制,但决策树很容易“检测”数据中的隐藏依赖性。
tree = DecisionTreeClassifier(random_state=17, max_depth=1)
tree_cv_score = np.mean(cross_val_score(tree, X_train, y_train, cv=5))
tree.fit(X_train, y_train)
tree_holdout_score = accuracy_score(y_holdout, tree.predict(X_holdout))
print(‘Decision tree. CV: {}, holdout: {}’.format(tree_cv_score,
tree_holdout_score))
# Decision tree. CV: 1.0, holdout: 1.0
在第二个例子中,树完全解决了问题,而k-NN遇到了困难。然而,这比使用欧几里德距离更不利于该方法。它不允许我们揭示一个特征比其他特征好得多。
6.决策树的优缺点和最近邻法
决策树的利弊
优点:
- 生成明确的人类可理解的分类规则,例如“如果年龄<25且对摩托车感兴趣,则拒绝贷款”。此属性称为模型的可解释性。
- 决策树可以很容易地可视化,即模型本身(树)和某个测试对象(树中的路径)的预测都可以“被解释”。
- 快速培训和预测。
- 少量模型参数。
- 支持数字和分类功能。
缺点:
- 树对输入数据中的噪声非常敏感; 如果稍微修改训练集,整个模型可能会改变(例如删除一个特征,添加一些对象)。这损害了模型的可解释性。
- 由决策树构建的分离边界有其局限性 - 它由垂直于其中一个坐标轴的超平面组成,在实践中其质量低于其他一些方法。
- 我们需要通过调整来避免过度拟合,在每个叶子中设置最小数量的样本,或者为树定义最大深度。请注意,过度拟合是所有机器学习方法的问题。
- 不稳定。对数据的微小更改可以显着改变决策树。决策树集合解决了这个问题(下次讨论)。
- 最优决策树搜索问题是NP完全的。在实践中使用了一些启发式算法,例如贪婪搜索具有最大信息增益的特征,但是它不能保证找到全局最优树。
- 难以支持数据中的缺失值。弗里德曼估计,大约50%的代码用于支持CART中的数据差距(该算法的改进版本已实现
sklearn)。 - 该模型只能插值但不能外推(随机森林和树提升也是如此)。也就是说,决策树对位于特征空间中的训练集所设置的边界框之外的对象进行恒定预测。在我们使用黄色和蓝色球的示例中,这意味着模型为位置> 19或<0的所有球提供相同的预测。
最近邻法的利弊
优点:
- 简单的实施。
- 容易学习。
- 通常,该方法不仅是分类或回归的良好第一解决方案,而且是推荐。
- 它可以通过选择正确的度量或内核来适应某个问题(简而言之,内核可以为复杂对象(如图形)设置相似性操作,同时保持k-NN方法相同)。顺便说一句,Alexander Dyakonov,前任前1名kaggler,喜欢最简单的k-NN,但却拥有调整对象的相似度量。
- 良好的可解释性。也有例外:如果邻居数量很大,可解释性就会恶化(“我们没有给他贷款,因为他与350个客户类似,其中70个是坏客户,比平均水平高12%对于数据集“)。
缺点:
- 与算法的组合相比,被认为是快速的方法,但是在现实生活中用于分类的邻居的数量通常很大(100-150),在这种情况下算法将不像决策树那样快速地运行。
- 如果数据集具有许多变量,则很难找到正确的权重并确定哪些特征对于分类/回归不重要。
- 依赖于对象之间的选定距离度量。默认选择欧几里德距离通常是没有根据的。您可以通过网格搜索参数找到一个好的解决方案,但这对于大型数据集来说变得非常耗时。
- 没有理论上的方法可以选择邻居的数量 - 只有网格搜索(尽管对于所有模型的所有超参数都是如此)。在少数邻居的情况下,该方法对异常值敏感,即倾向于过度拟合。
- 通常,由于“维数的诅咒”而存在许多功能时,它不能很好地工作。ML社区的知名成员Pedro Domingos教授在他的热门论文“机器学习中几个有用的事情”中谈到了这一点 ; 在本章的深度学习书中也描述了“维度的诅咒” 。
这是很多信息,但是,希望这篇文章很长一段时间对你很有帮助:)
公众号:银河系1号
联系邮箱:public@space-explore.com
(未经同意,请勿转载)

微信扫一扫关注该公众号
