

You only get one shot, do not miss your chance to blow.
你只有一发子弹,不要错过引爆全场的机会。
日志
2019年3月24日 trie实战(一)统计字符串中指定字符出现的次数
2019年3月25日 trie实战 (二)基于AC自动机的敏感词过滤系统
引言
学习不能只局限于实现,更重要的是学会自己思考,举一反三。学的是思想,如何转化成自己的东西。
trie树又称“字典树”。关键词提示功能在日常生活中非常常用,通常只需要输出前缀,它就会给出相应的提示。呢具体是怎么实现的呢?本文主要分享了基于trie树的一个简易的搜索提示以及trie树常用的应用场景。所有源码均已上传至github:链接
ps:Trie 树的本质,就是利用字符串之间的公共前缀,将重复的前缀合并在一起。
模拟搜索关键词提示功能
本次实现其实也可以改造一下,将用户习惯(输入内容)存成一颗trie树
以how,hi,her,hello,so,see为例
声明一个tire类
这里偷了个小懒,整了一个内部类。
public class TrieNode {
/**
* 字符
*/
public char data;
/**
* 子节点
*/
TrieNode[] children;
/**
* 标识
*/
boolean isEndingChar;
TrieNode(char data) {
children = new TrieNode[26];
isEndingChar = false;
this.data = data;
}
}初始化
通常根节点是不存储任何信息的,起一个占位符的作用
/**
* 根节点
*/
private TrieNode root;
/**
* 预制单词数量
*/
private int count;
/**
* 提示词列表
*/
private List<String> list;
/**
* 输入值
*/
private String pattern;
/**
* 存储一个无意义的字符
*/
private TrieTree() {
root = new TrieNode('/');
count = 0;
list = new ArrayList<>();
}插入
这里存储的是ASCII码,相对而言要省内存一些。
private void insert(char[] txt) {
TrieNode p = root;
for (char c : txt) {
//当前字符的ASCII码 - 'a'的 ASCII码
int index = c - 'a';
if (null == p.children[index]) {
TrieNode node = new TrieNode(c);
p.children[index] = node;
}
p = p.children[index];
}
++count;
p.isEndingChar = true;
}查询
private boolean contains(String pattern) {
char[] patChars = pattern.toCharArray();
TrieNode p = root;
for (char patChar : patChars) {
int index = patChar - 'a';
if (null == p.children[index])
return false;
p = p.children[index];
}
return p.isEndingChar;
}模糊提示匹配
private void match() {
char[] patChars = pattern.toCharArray();
TrieNode p = root;
for (char patChar : patChars) {
int index = patChar - 'a';
if (null == p.children[index])
return;
p = p.children[index];
}
//开始遍历 p,将所有匹配的字符加入strs
traversal(p, "");
}递归遍历节点
private void traversal(TrieNode trieNode, String str) {
if (null != trieNode) {
str += trieNode.data;
if (trieNode.isEndingChar) {
String curStr = pattern.length() == 1 ?
str : pattern + str.substring(pattern.length() - 1);
if (!list.contains(curStr))
list.add(curStr);
return;
}
for (int i = 0; i < trieNode.children.length; i++) {
traversal(trieNode.children[i], str);
}
}
}测试代码
人为构造一个tire树
ps:这里的存储会导致树很高,比如 l l o,其实可以合成llo,也就是缩点优化。这里暂时不实现了。
private void initTries() {
// how,hi,her,hello,so,see
// /
// h s
// e i o o e
// l w e
// l
// o
char[] how = "how".toCharArray();
insert(how);
char[] hi = "hi".toCharArray();
insert(hi);
char[] her = "her".toCharArray();
insert(her);
char[] hello = "hello".toCharArray();
insert(hello);
char[] so = "so".toCharArray();
insert(so);
char[] see = "see".toCharArray();
insert(see);
}测试代码
public static void main(String[] args) {
TrieTree trieTree = new TrieTree();
trieTree.initTries();
String str = "hello";
boolean res = trieTree.contains(str);
System.out.println("trie树是否包含" + str + "返回结果:" + res);
trieTree.pattern = "h";
trieTree.match();
System.out.println("单字符模糊匹配 " + trieTree.pattern + ":");
trieTree.printAll();
trieTree.list.clear();
trieTree.pattern = "he";
trieTree.match();
System.out.println("多字符模糊匹配 " + trieTree.pattern + ":");
trieTree.printAll();
}测试结果
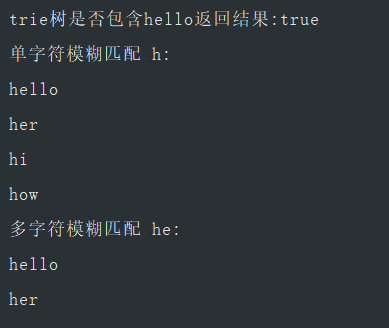
统计字符串中指定字符出现的次数
还是以26个字母为大前提.字典树正是因为它搜索快捷的特性,才会深受搜索引擎的喜爱。只要有空间(确实很耗内存),就能为所欲为(快)。
思考
这里主要是分享这样的一种思想,如何利用现有代码,根据需求,将其进行改造成满足的需求的代码。有时候不需要重复造轮子,但是关键时刻需要会用轮子。
改造TireNode类
这里加了一个frequency属性,为了统计高频词汇。并且将children由数组改成map,更便于存储,相当而言,更节省空间。
private class TrieNode {
/**
* 字符
*/
public char data;
/**
* 出现频率
*/
int frequency;
boolean isEndingChar;
/**
* 子节点
*/
Map<Character, TrieNode> children;
TrieNode(char data) {
this.data = data;
children = new HashMap<>();
isEndingChar = false;
}
}初始化
/**
* 根节点
*/
private TrieNode root;
/**
* 计数
*/
private int count;
/**
* 无参构造方法
*/
private TrieTreeAlgo() {
root = new TrieNode('/');
count = 0;
}改造插入方法
- frequency用来计数,计算该字符的频率
- isEndingChar和之前一样,用来判断是否是该单词的结尾
private void insert(String txt) {
TrieNode p = root;
char[] txtChar = txt.toCharArray();
for (Character c : txtChar) {
if (!p.children.containsKey(c)) {
TrieNode trieNode = new TrieNode(c);
p.children.put(c, trieNode);
}
p = p.children.get(c);
++p.frequency;
}
++count;
p.isEndingChar = true;
}统计方法
增加一个统计方法,计算某一单词的出现频率,当isEndingChar==true,说明已经匹配到该单词了,并且到末尾,然后该字符频率数量减去子节点的个数即可
private int frequency(String pattern) {
char[] patChars = pattern.toCharArray();
TrieNode p = root;
for (char patChar : patChars) {
if (p.children.containsKey(patChar)) {
p = p.children.get(patChar);
}
}
if (p.isEndingChar) return p.frequency - p.children.size();
return -1;
}测试代码
初始化要插入字典树的单词(这里其实可以扩展一下下,插入一篇文章,插入用户常输入词汇等等。)
private void initTries() {
String txt = "he her hello home so see say just so so hello world";
String[] strs = txt.split(" ");
for (String str : strs) {
insert(str);
}
}测试代码
- so 一个高频词汇
- he 一个普通单词,并且里面的单词还有含有它的,比如her,hello
- hel一个不存在的单词
public static void main(String[] args) {
TrieTreeAlgo trieTreeAlgo = new TrieTreeAlgo();
trieTreeAlgo.initTries();
System.out.println("共计" + trieTreeAlgo.count + "个单词。");
String so = "so";
int soCount = trieTreeAlgo.frequency(so);
System.out.println(so + "出现的次数为:" + (soCount > 0 ? soCount : 0));
String he = "he";
int heCount = trieTreeAlgo.frequency(he);
System.out.println(he + "出现的次数为:" + (heCount > 0 ? heCount : 0));
String hel = "hel";
int helCount = trieTreeAlgo.frequency(hel);
System.out.println(hel + "出现的次数为:" + (helCount > 0 ? helCount : 0));
}测试结果
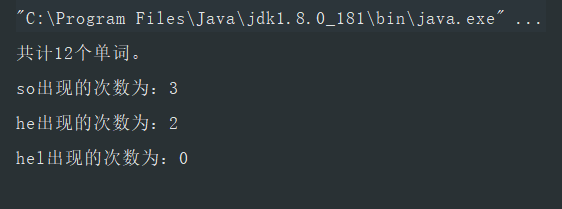
基于AC自动机的敏感词过滤系统
既然有了关键词匹配提示,那么相对应的,自然也应该有敏感词过滤,随着互联网的日益发达,用户的素质参差不齐,动不动就骂人,如果这在一个网站上显示,肯定是不好的,所以对此现象,基于AC自动机的敏感词过滤系统就诞生了。
ps:偷偷告诉你个秘密:这是一个阉割压缩版的敏感词过滤系统
思考
AC 自动机实际上就是在 Trie 树之上,加了类似 KMP 的 next 数组(只不过这里的next数组是构建在Trie树上)。还是要改造的,在trie树的基础上加了一个fail的指针,当匹配不上的时候,尽可能的在树上滑动,说人话就是大大减少了遍历的次数,提升了匹配效率。
ps 这是一种后缀字符串匹配算法
改造
在原有基础上,加了一个fail的指针,并且AC自动机的跳转是通过fail指针来实现的。
private class AcNode {
/**
* 字符
*/
public char data;
/**
* 子节点
*/
Map<Character, AcNode> children;
/**
* 结束标识
*/
boolean isEndingChar;
/**
* 失败指针
*/
AcNode fail;
AcNode(char data) {
this.data = data;
children = new HashMap<>();
isEndingChar = false;
}
}初始化
/**
* 根节点
*/
private AcNode root;
private AhoCorasick() {
root = new AcNode('/');
}插入
private void insert(String txt) {
AcNode p = root;
char[] txtChar = txt.toCharArray();
for (Character c : txtChar) {
if (!p.children.containsKey(c)) {
AcNode trieNode = new AcNode(c);
p.children.put(c, trieNode);
}
p = p.children.get(c);
}
p.isEndingChar = true;
}构建失败指针
这个方法是关键。
private void buildFailurePointer() {
Queue<AcNode> queue = new LinkedList<>();
root.fail = null;
queue.offer(root);
while (!queue.isEmpty()) {
AcNode p = queue.poll();
for (char c : p.children.keySet()) {
AcNode pChild = p.children.get(c);
if (null == pChild) continue;
if (root == p) {
pChild.fail = root;
} else {
AcNode q = p.fail;
while (null != q) {
AcNode qChild = q.children.get(p.data);
if (null != qChild) {
pChild.fail = qChild;
break;
}
q = q.fail;
}
if (null == q) {
pChild.fail = root;
}
}
queue.offer(pChild);
}
}
}匹配
private boolean match(String txt) {
char[] txtChars = txt.toCharArray();
AcNode p = root;
for (char c : txtChars) {
while (p != root && null == p.children.get(c)) {
p = p.fail;
}
p = p.children.get(c);
//如果没有匹配,从root重新开始
if (null == p) p = root;
AcNode temp = p;
while (temp != root) {
if (temp.isEndingChar) {
return true;
}
temp = temp.fail;
}
}
return false;
}构建敏感词Trie树
private void generate() {
String[] strs = new String[]{"so", "hel", "oh", "llo"};
for (int i = 0; i < strs.length; i++) {
insert(strs[i]);
}
}测试代码
这里加了一个Map,用来做缓存,如果已经匹配上了,直接替换就可以了,提升效率。mapCache的value就是key出现的次数,起一个计数的作用。
public static void main(String[] args) {
AhoCorasick ac = new AhoCorasick();
ac.generate();
ac.buildFailurePointer();
String txt = "he her hello home so see say just so so hello world";
System.out.println("主串");
System.out.println("[" + txt + "]");
System.out.println("敏感词:");
System.out.println("so,hel,oh,llo");
String[] strs = txt.split(" ");
Map<String, Integer> mapCache = new HashMap<>();
for (int i = 0; i < strs.length; i++) {
if (mapCache.containsKey(strs[i])) {
int index = mapCache.get(strs[i]);
mapCache.put(strs[i], ++index);
strs[i] = "****";
} else {
boolean res = ac.match(strs[i]);
//如果匹配到,将其替换成****
if (res) {
mapCache.put(strs[i], 1);
strs[i] = "****";
}
}
}
System.out.println("经过敏感词系统过滤后...");
System.out.println(Arrays.toString(strs));
for (String str:mapCache.keySet()){
System.out.println(str + "出现的次数为" + mapCache.get(str));
}
}测试结果
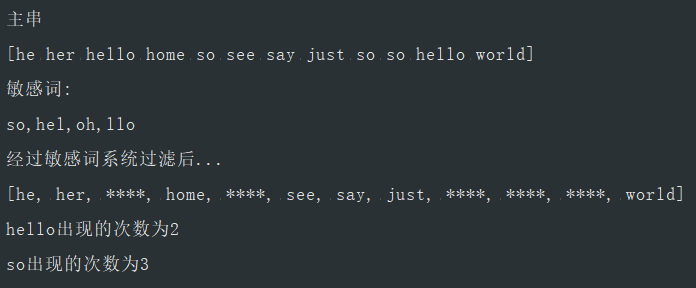
end

您的点赞和关注是对我最大的支持,谢谢!
