

HBase and MapR-DB: Designed for Distribution, Scale, and Speed-HBASE数据模型
Apache HBase is a database that runs on a Hadoop cluster. HBase is not a traditional RDBMS, as it relaxes the ACID (Atomicity, Consistency, Isolation, and Durability) properties of traditional RDBMS systems in order to achieve much greater scalability. Data stored in HBase also does not need to fit into a rigid schema like with an RDBMS, making it ideal for storing unstructured or semi-structured data.
The MapR Converged Data Platform supports HBase, but also supports MapR-DB, a high performance, enterprise-grade NoSQL DBMS that includes the HBase API to run HBase applications. For this blog, I’ll specifically refer to HBase, but understand that many of the advantages of using HBase in your data architecture apply to MapR-DB. MapR built MapR-DB to take HBase applications to the next level, so if the thought of higher powered, more reliable HBase deployments sound appealing to you, take a look at some of the MapR-DB content here.
HBase allows you to build big data applications for scaling, but with this comes some different ways of implementing applications compared to developing with traditional relational databases. In this blog post, I will provide an overview of HBase, touch on the limitations of relational databases, and dive into the specifics of the HBase data model.
Relational Databases vs. HBase – Data Storage Model
Why do we need NoSQL/HBase? First, let’s look at the pros of relational databases before we discuss its limitations:
- Relational databases have provided a standard persistence model
- SQL has become a de-facto standard model of data manipulation (SQL)
- Relational databases manage concurrency for transactions
- Relational database have lots of tools
Relational databases were the standard for years, so what changed? With more and more data came the need to scale. One way to scale is vertically with a bigger server, but this can get expensive, and there are limits as your size increases.
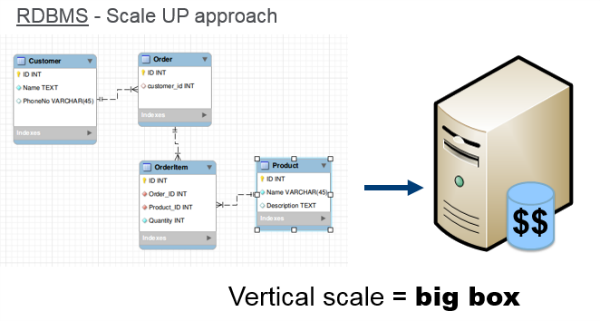
Relational Databases vs. HBase - Scaling
What changed to bring on NoSQL?
An alternative to vertical scaling is to scale horizontally with a cluster of machines, which can use commodity hardware. This can be cheaper and more reliable. To horizontally partition or shard a RDBMS, data is distributed on the basis of rows, with some rows residing on a single machine and the other rows residing on other machines, However, it’s complicated to partition or shard a relational database, and it was not designed to do this automatically. In addition, you lose the querying, transactions, and consistency controls across shards. Relational databases were designed for a single node; they were not designed to be run on clusters.
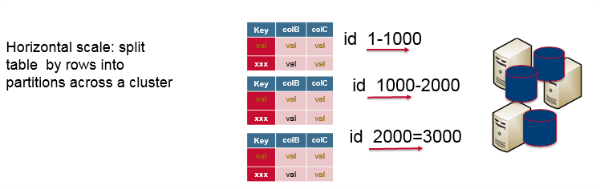
Limitations of a Relational Model
Database normalization eliminates redundant data, which makes storage efficient. However, a normalized schema causes joins for queries, in order to bring the data back together again. While HBase does not support relationships and joins, data that is accessed together is stored together so it avoids the limitations associated with a relational model. See the difference in data storage models in the chart below:
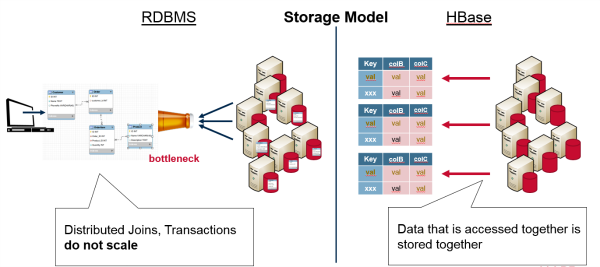
Relational databases vs. HBase - data storage model
HBase Designed for Distribution, Scale, and Speed
HBase was designed to scale due to the fact that data that is accessed together is stored together. Grouping the data by key is central to running on a cluster. In horizontal partitioning or sharding, the key range is used for sharding, which distributes different data across multiple servers. Each server is the source for a subset of data. Distributed data is accessed together, which makes it faster for scaling. HBase is actually an implementation of the BigTable storage architecture, which is a distributed storage system developed by Google that’s used to manage structured data that is designed to scale to a very large size.
HBase is referred to as a column family-oriented data store. It’s also row-oriented: each row is indexed by a key that you can use for lookup (for example, lookup a customer with the ID of 1234). Each column family groups like data (customer address, order) within rows. Think of a row as the join of all values in all column families.
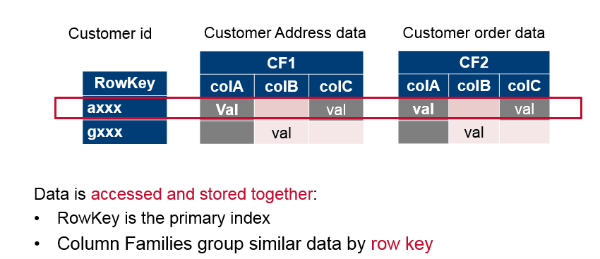
HBase is a column family-oriented database
HBase is also considered a distributed database. Grouping the data by key is central to running on a cluster and sharding. The key acts as the atomic unit for updates. Sharding distributes different data across multiple servers, and each server is the source for a subset of data.
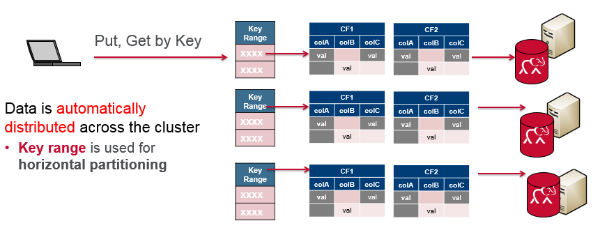
HBase is a distributed database
HBase Data Model
Data stored in HBase is located by its “rowkey.” This is like a primary key from a relational database. Records in HBase are stored in sorted order, according to rowkey. This is a fundamental tenet of HBase and is also a critical semantic used in HBase schema design.
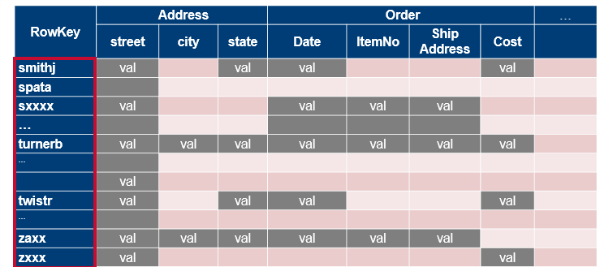
HBase data model – row keys
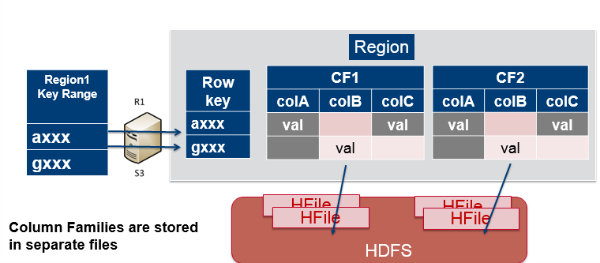
Tables are divided into sequences of rows, by key range, called regions. These regions are then assigned to the data nodes in the cluster called “RegionServers.” This scales read and write capacity by spreading regions across the cluster. This is done automatically and is how HBase was designed for horizontal sharding.
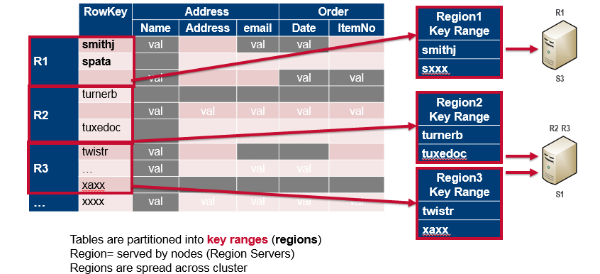
Tables are split into regions = contiguous keys
The image below shows how column families are mapped to storage files. Column families are stored in separate files, which can be accessed separately.
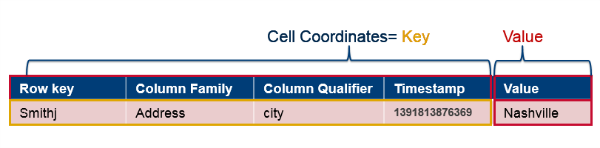
The data is stored in HBase table cells. The entire cell, with the added structural information, is called Key Value. The entire cell, the row key, column family name, column name, timestamp, and value are stored for every cell for which you have set a value. The key consists of the row key, column family name, column name, and timestamp.
Logically, cells are stored in a table format, but physically, rows are stored as linear sets of cells containing all the key value information inside them.
In the image below, the top left shows the logical layout of the data, while the lower right section shows the physical storage in files. Column families are stored in separate files. The entire cell, the row key, column family name, column name, timestamp, and value are stored for every cell for which you have set a value.
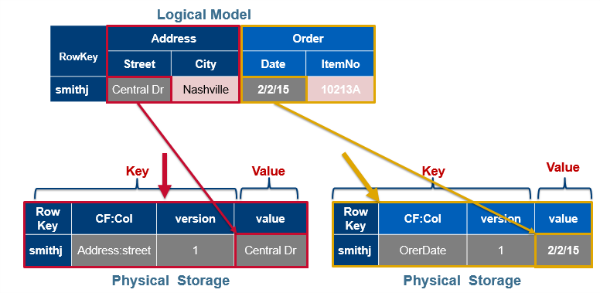
Logical data model vs. physical data storage
As mentioned before, the complete coordinates to a cell's value are: Table:Row:Family:Column:Timestamp ➔ Value. HBase tables are sparsely populated. If data doesn’t exist at a column, it’s not stored. Table cells are versioned uninterpreted arrays of bytes. You can use the timestamp or set up your own versioning system. For every coordinate row family:column, there can be multiple versions of the value.
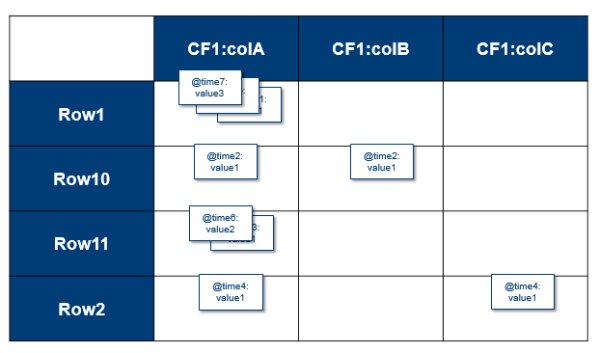
Sparse data with cell versions
Versioning is built in. A put is both an insert (create) and an update, and each one gets its own version. Delete gets a tombstone marker. The tombstone marker prevents the data being returned in queries. Get requests return specific version(s) based on parameters. If you do not specify any parameters, the most recent version is returned. You can configure how many versions you want to keep and this is done per column family. The default is to keep up to three versions. When the max number of versions is exceeded, extra records will be eventually removed.
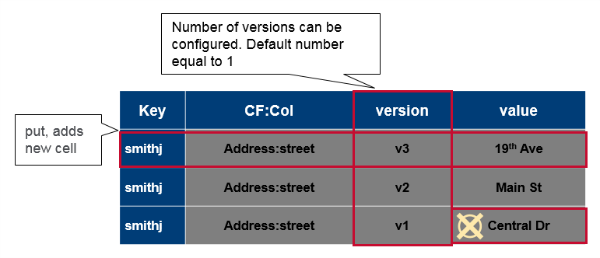
Versioned data
In this blog post, you got an overview of HBase (and implicitly MapR-DB) and learned about the HBase/MapR-DB data model. Stay tuned for the next blog post, where I’ll take a deep dive into the details of the HBase architecture. In the third and final blog post in this series, we’ll take a look at schema design guidelines.
Want to learn more?
- Installing HBase on MapR
- Getting Started with HBase on MapR
- Release notes for HBase on MapR
- Apache HBase docs
- shop.oreilly.com/product/063…)
深度分析HBase架构
HBase的架构
物理上看, HBase系统有3种类型的后台服务程序, 分别是Region server, Master server 和 zookeeper.
Region server负责实际数据的读写. 当访问数据时, 客户端与HBase的Region server直接通信.
Master server管理Region的位置, DDL(新增和删除表结构)
Zookeeper负责维护和记录整个HBase集群的状态.
所有的HBase数据都存储在HDFS中. 每个 Region server都把自己的数据存储在HDFS中. 如果一个服务器既是Region server又是HDFS的Datanode. 那么这个Region server的数据会在把其中一个副本存储在本地的HDFS中, 加速访问速度.
但是, 如果是一个新迁移来的Region server, 这个region server的数据并没有本地副本. 直到HBase运行compaction, 才会把一个副本迁移到本地的Datanode上面.
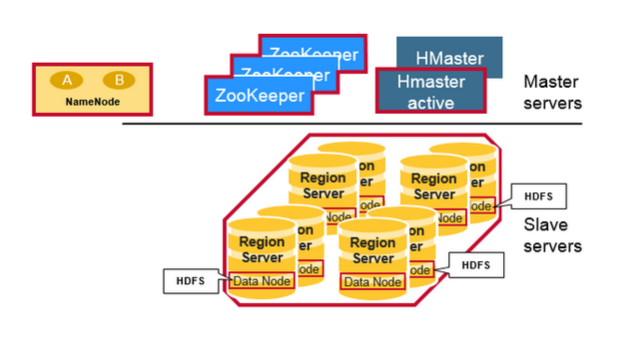
HBase Region server
HBase的表根据Row Key的区域分成多个Region, 一个Region包含这这个区域内所有数据. 而Region server负责管理多个Region, 负责在这个Region server上的所有region的读写操作. 一个Region server最多可以管理1000个region.
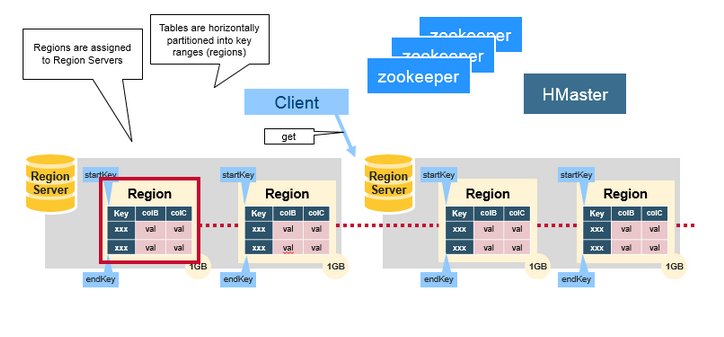
HBase Master server
HBase Maste主要负责分配region和操作DDL(如新建和删除表)等,
HBase Master的功能:
- 协调Region server
- 在集群处于数据恢复或者动态调整负载时,分配Region到某一个Region Server中
- 管控集群, 监控所有RegionServer的状态
- 提供DDL相关的API, 新建(create),删除(delete)和更新(update)表结构.
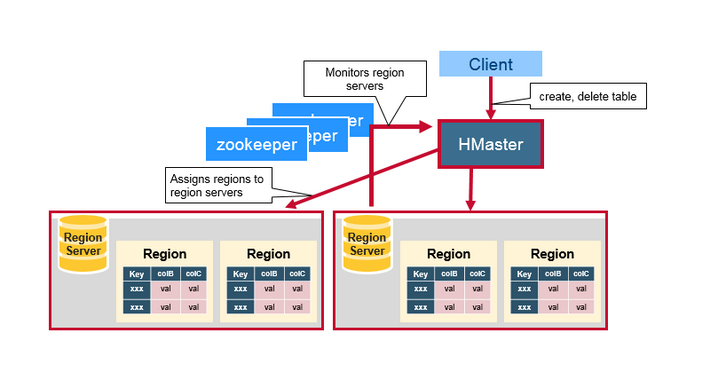
ZooKeeper: 集群"物业"管理员
Zookeepper是一个分布式的无中心的元数据存储服务. zookeeper探测和记录HBase集群中服务器的状态信息. 如果zookeeper发现服务器宕机, 它会通知Hbase的master节点. 在生产环境部署zookeeper至少需要3台服务器, 用来满足zookeeper的核心算法Paxos的最低要求.
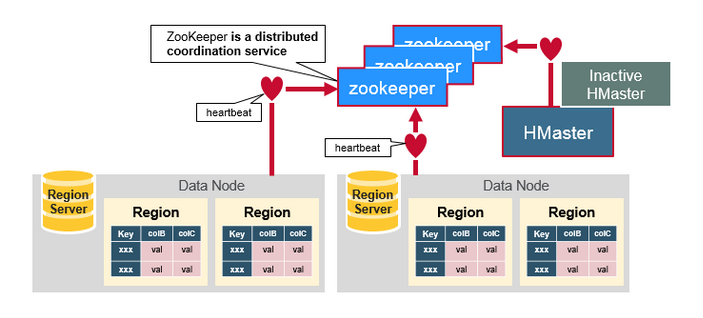
ZooKeeper, Master和 Region server协同工作
Zookeepr负责维护集群的memberlist, 哪台服务器在线,哪台服务器宕机都由zookeeper探测和管理. Region server, 主备Master节点主动连接Zookeeper, 维护一个Session连接,
这个session要求定时发送heartbeat, 向zookeeper说明自己在线, 并没有宕机.
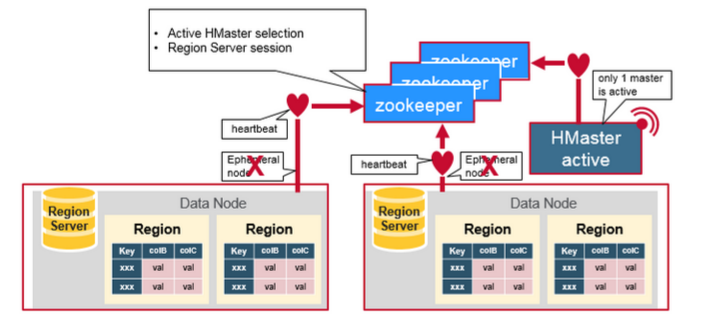
ZooKeeper有一个Ephemeral Node(临时节点)的概念, session连接在zookeeper中建立一个临时节点(Ephemeral Node), 如果这个session断开, 临时节点被自动删除.
所有Region server都尝试连接Zookeeper, 并在这个session中建立一个临时节点(Ephemeral node). HBase的master节点监控这些临时节点的是否存在, 可以发现新加入region server和判断已经存在的region server宕机.
为了高可用需求, HBase的master也有多个, 这些master节点也同时向Zookeeper注册临时节点(Ephemeral Node). Zookeeper把第一个成功注册的master节点设置成active状态, 而其他master node处于inactive状态.
如果zookeeper规定时间内, 没有收到active的master节点的heartbeat, 连接session超时, 对应的临时节也自动删除. 之前处于Inactive的master节点得到通知, 马上变成active状态, 立即提供服务.
同样, 如果zookeeper没有及时收到region server的heartbeat, session过期, 临时节点删除. HBase master得知region server宕机, 启动数据恢复方案.
HBase的第一次读写流程
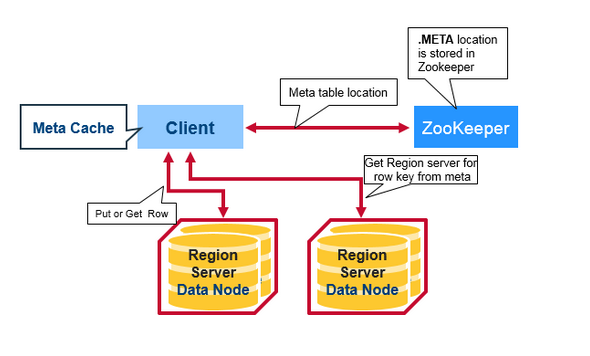
HBase把各个region的位置信息存储在一个特殊的表中, 这个表叫做Meta table.
Zookeeper里面存储了这个Meta table的位置信息.
HBase的访问流程:
- 客户端访问Zookeep, 得到了具体Meta table的位置
- 客户端再访问真正的Meta table, 从Meta table里面得到row key所在的region server
- 访问rowkey所在的region server, 得到需要的真正数据.
客户端缓存meta table的位置和row key的位置信息, 这样就不用每次访问都读zookeeper.
如果region server由于宕机等原因迁移到其他服务器. Hbase客户端访问失败, 客户端缓存过期, 再重新访问zookeeper, 得到最新的meta table位置, 更新缓存.
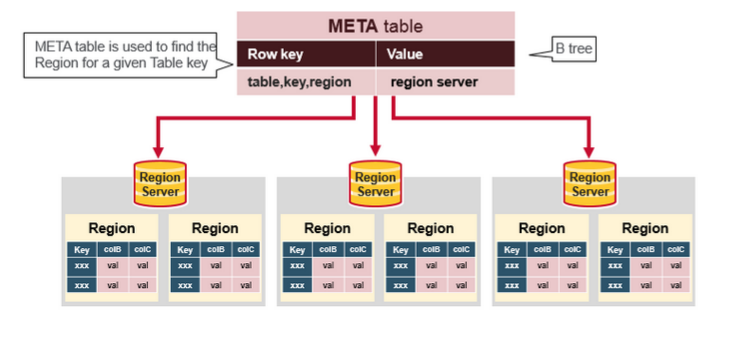
HBase Meta Table
Meta table存储所有region的列表
Meta table用类似于Btree的方式存储
Meta table的结构如下:
- Key: region的开始row key, region id
- Values: Region server
译注: 在google的bigtable论文中, bigtable采用了多级meta table, Hbase的Meta table只有2级
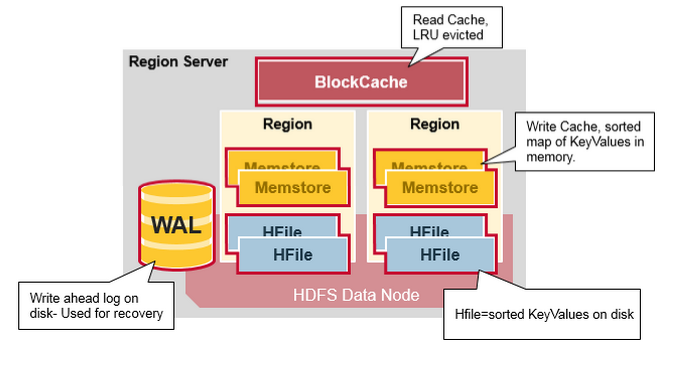
Region Server的结构
Region Server运行在HDFS的data node上面, 它有下面4个部分组成:
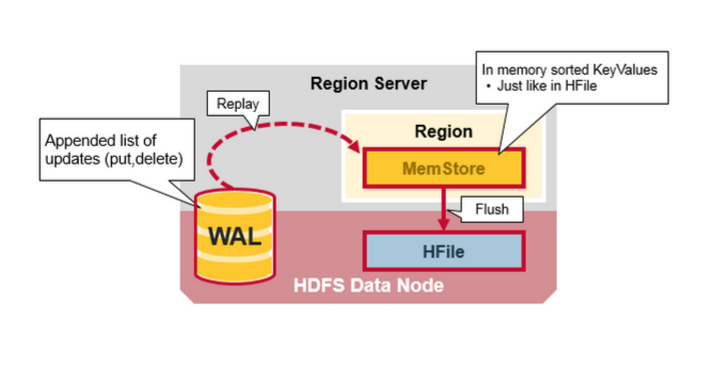
- WAL: 预写日志(Write Ahead Log)是一HDFS上的一个文件, 如果region server崩溃后, 日志文件用来恢复新写入的的, 但是还没有存储在硬盘上的数据.
- BlockCache: 读取缓存, 在内存里缓存频繁读取的数据, 如果BlockCache满了, 会根据LRU算法(Least Recently Used)选出最不活跃的数据, 然后释放掉
- MemStore: 写入缓存, 在数据真正被写入硬盘前, Memstore在内存中缓存新写入的数据. 每个region的每个列簇(column family)都有一个memstore. memstore的数据在写入硬盘前, 会先根据key排序, 然后写入硬盘.
- HFiles: HDFS上的数据文件, 里面存储KeyValue对.
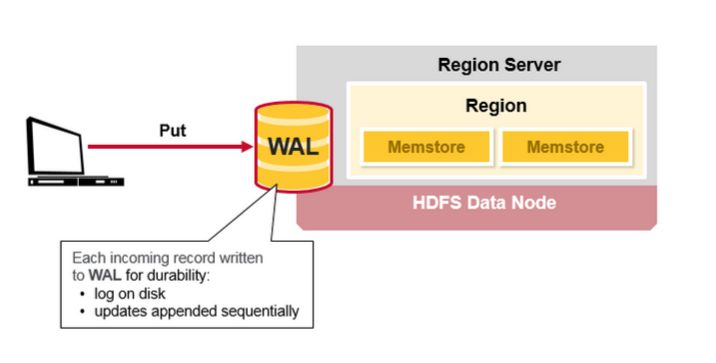
HBase的写入流程(1)
当hbase客户端发起Put请求, 第一步是将数据写入预写日志(WAL):
- 将修改的操作记录在预写日志(WAL)的末尾
- 预写日志(WAL)被用来在region server崩溃时, 恢复memstore中的数据
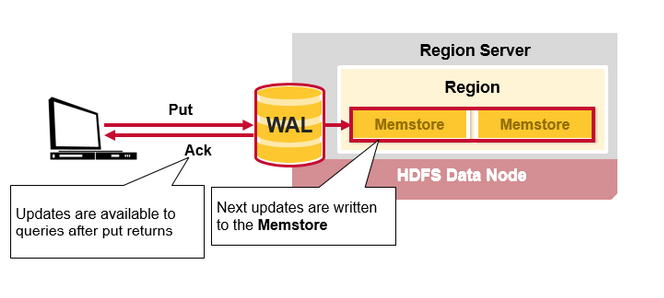
Hbase的写入流程(2)
数据写入预写日志(WAL), 并存储在memstore之后, 向用户返回写成功.
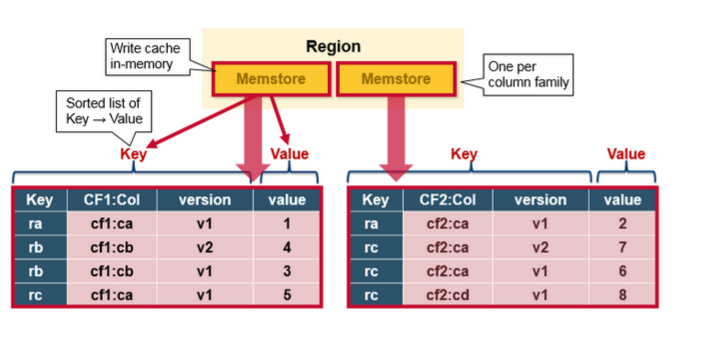
HBase MemStore
MemStore在内存按照Key的顺序, 存储Key-Value对, 一个Memstore对应一个列簇(column family). 同样在HFile里面, 所有的Key-Value对也是根据Key有序存储.
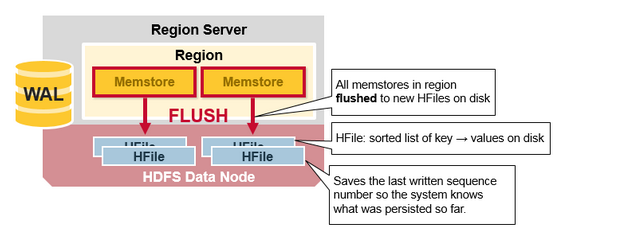
HBase Region Flush
译注: 原文里面Flush的意识是, 把缓冲的数据从内存 转存 到硬盘里, 这就类似与冲厕所(Flush the toilet) , 把数据比作是水, 一下把积攒的水冲到下水道, 想当于把缓存的数据写入硬盘. 和Flush非常类似的英文还有un-plug, 比如有一浴缸的水, 只要un-plug浴缸里面的塞子, 浴缸的水就开始流进下水道, 也类比把缓存数据写入硬盘
当Memstore累计了足够多的数据, Region server将Memstore中的数据写入HDFS, 存储为一个HFile. 每个列簇(column family)对于多个HFile, 每个HFile里面就是实际存储的数据.
这些HFile都是当Memstore满了以后, Flush到HDFS中的文件. 注意到HBase限制了列簇(column family)的个数. 因为每个列簇(column family)都对应一个Memstore. [译注: 太多的memstore占用过多的内存].
当Memstore的数据Flush到硬盘时, 系统额外保存了最后写入操作的序列号(last written squence number), 所以HBase知道有多少数据已经成功写入硬盘. 每个HFile都记录这个序号, 表明这个HFile记录了多少数据和从哪里继续写入数据.
在region server启动后, 读取所有HFile中最高的序列号, 新的写入序列号从这个最高序列号继续向上累加.
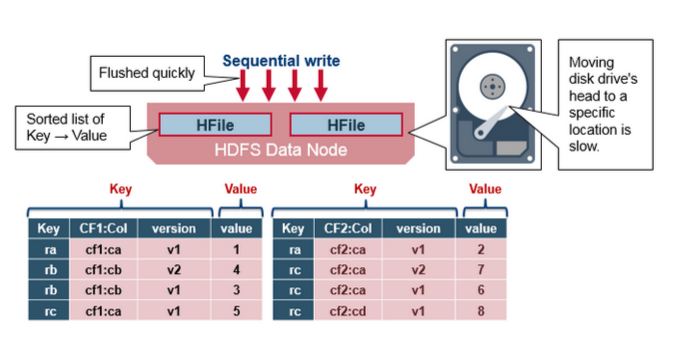
HBase HFile
HFile中存储有序的Key-Value对. 当Memstore满了之后, Memstore中的所有数据写入HDFS中,形成一个新的HFile. 这种大文件写入是顺序写, 因为避免了机械硬盘的磁头移动, 所以写入速度非常快.
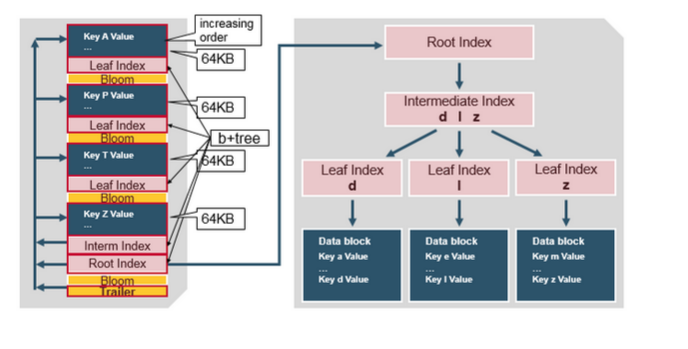
HBase HFile Structure
HFile存储了一个多级索引(multi-layered index), 查询请求不需要遍历整个HFile查询数据, 通过多级索引就可以快速得到数据(工作机制类似于b+tree)
- Key-Value按照升序排列
- Key-Value存储在以64KB为单位的Block里
- 每个Block有一个叶索引(leaf-index), 记录Block的位置
- 每个Block的最后一个Key(译注: 最后一个key也是最大的key), 放入中间索引(intermediate index)
- 根索引(root index)指向中间索引
尾部指针(trailer pointer)在HFile的最末尾, 它指向元数据块区(meta block), 布隆过滤器区域和时间范围区域. 查询布隆过滤器可以很快得确定row key是否在HFile内, 时间范围区域也可以帮助查询跳过不在时间区域的读请求.
译注: 布隆过滤器在搜索和文件存储中有广泛用途, 具体算法请参考https://china.googleblog.com/2007/07/bloom-filter_7469.html
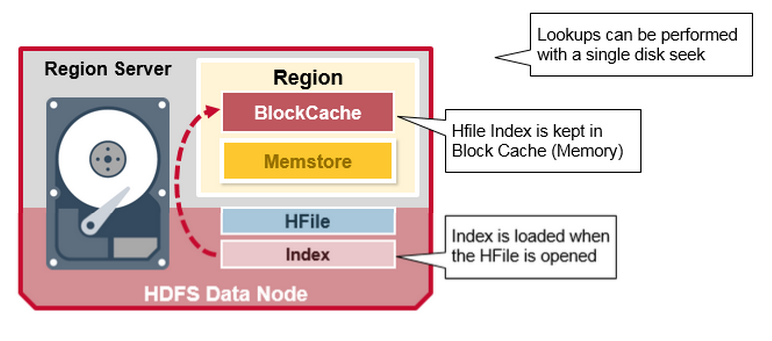
HFile索引
当打开HFile后, 系统自动缓存HFile的索引在Block Cache里, 这样后续查找操作只需要一次硬盘的寻道.
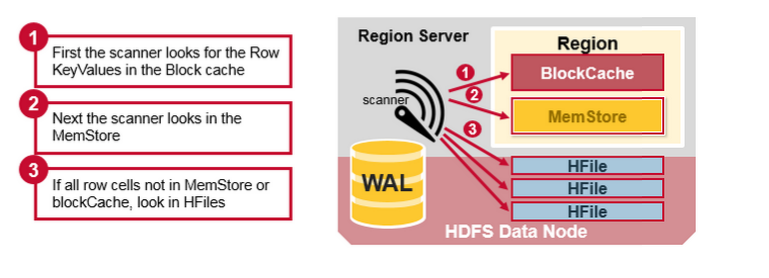
HBase的混合读(Read Merge)
我们发现HBase中的一个row里面的数据, 分配在多个地方. 已经持久化存储的Cell在HFile, 最近写入的Cell在Memstore里, 最近读取的Cell在Block cache里. 所以当你读HBase的一行时, 混合了Block cache, memstore和Hfiles的读操作
- 首先, 在Block cache(读cache)里面查找cell, 因为最近的读取操作都会缓存在这里. 如果找到就返回, 没有找到就执行下一步
- 其次, 在memstore(写cache)里查找cell, memstore里面存储里最近的新写入, 如果找到就返回, 没有找到就执行下一步
- 最后, 在读写cache中都查找失败的情况下, HBase查询Block cache里面的Hfile索引和布隆过滤器, 查询有可能存在这个cell的HFile, 最后在HFile中找到数据.
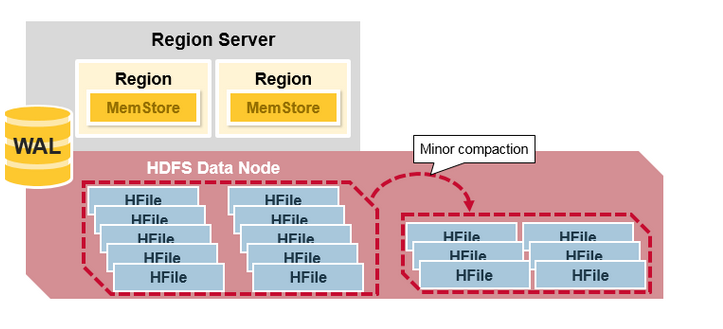
HBase Minor Compaction
HBase自动选择较小的HFile, 将它们合并成更大的HFile. 这个过程叫做minor compaction. Minor compaction通过合并小HFile, 减少HFile的数量.
HFile的合并采用归并排序的算法.
译注: 较少的HFile可以提高HBase的读性能
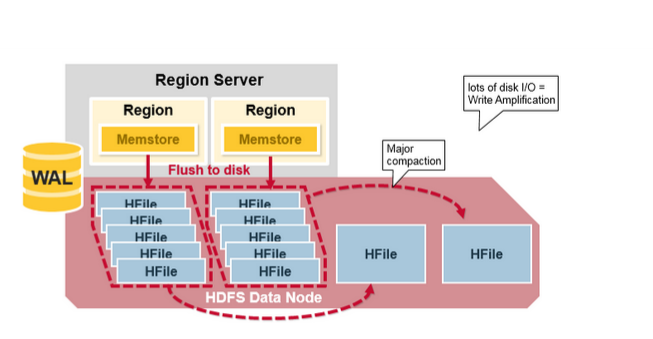
HBase Major Compaction
Major compaction指一个region下的所有HFile做归并排序, 最后形成一个大的HFile. 这可以提高读性能. 但是, major compaction重写所有的Hfile, 占用大量硬盘IO和网络带宽. 这也被称为写放大现象(write amplification)
Major compaction可以被调度成自动运行的模式, 但是由于写放大的问题(write amplification), major compaction通常在一周执行一次或者只在凌晨运行. 此外, major compaction的过程中, 如果发现region server负责的数据不在本地的HDFS datanode上, major compaction除了合并文件外, 还会把其中一份数据转存到本地的data node上.
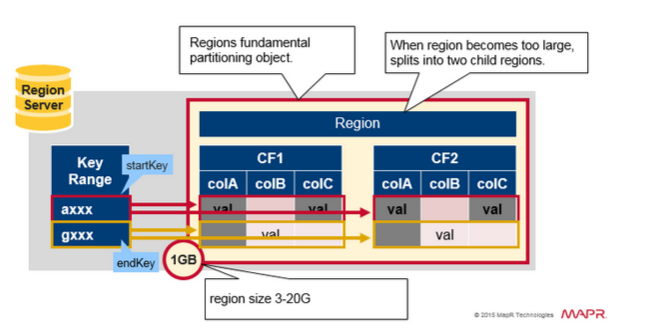
Region = 一组连续key
快速的复习region的概念:
- 一张表垂直分割成一个或多个region, 一个region包括一组连续并且有序的row key, 每一个row key对应一行的数据.
- 每个region最大1GB(默认)
- region由region server管理
- 一个region server可以管理多个region, 最多大约1000个region(这些region可以属于相同的表,也可以属于不同的表)
Region的拆分
最初, 每张表只有一个region, 当一个region变得太大时, 它就分裂成2个子region. 2个子region, 各占原始region的一半数据, 仍然被相同的region server管理. Region server向HBase master节点汇报拆分完成.
如果集群内还有其他region server, master节点倾向于做负载均衡, 所以master节点有可能调度新的region到其他region server, 由其他region管理新的分裂出的region.
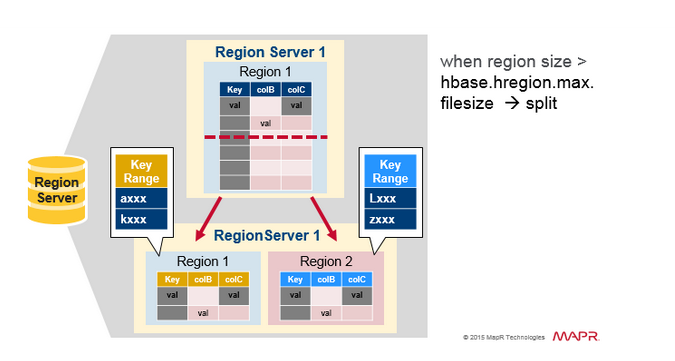
负载均衡
最初, 一个Region server上的region一分为二, 但是考虑到负载均衡, master node会把新region调度到其他服务器上. 然而, 新region所在的region server在本地data node上没有数据, 所有操作都是操作远程HDFS上面的数据. 直到这个Region server运行了major compaction之后, 才有一份副本落在本地datanode中.
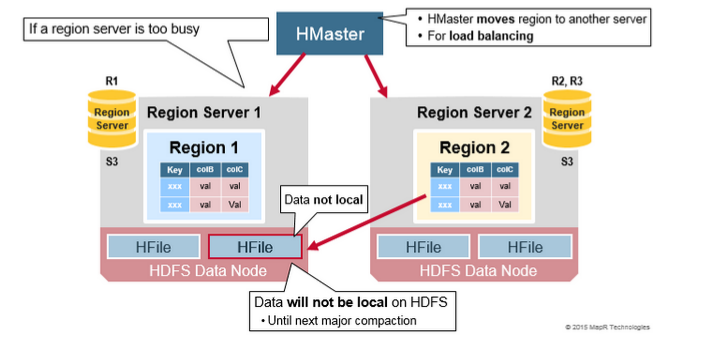
译注: HFile和WAL都是存储在HDFS中, 这里说的把副本存储在本地是指: 由于HDFS是一种聪明的FS, 如果他发现要求写入文件的客户端恰好也是HDFS的data node, 那么在分配哪三台服务器存储副本时, 会优先在发请求的客户端存储数据, 这样就可以让Region server管理的数据虽然是3份, 但是其中一份就在本地服务器上, 优化了访问路径.
具体可以参考这篇文章http://www.larsgeorge.com/2010/05/hbase-file-locality-in-hdfs.html, 里面详述了HDFS如何实现这种本地化的存储. 换句话说, 如果region server没有和HDFS的data node部署在同一台服务器, 就无法实现上面说的本地存储
HDFS的数据复制(1)
所有读写都是操作primary node. HDFS自动复制所有WAL和HFile的数据块到其他节点. HBase依赖HDFS保证数据安全. 当在HDFS里面写入一个文件时, 一份存储在本地节点, 另两份存储到其他节点
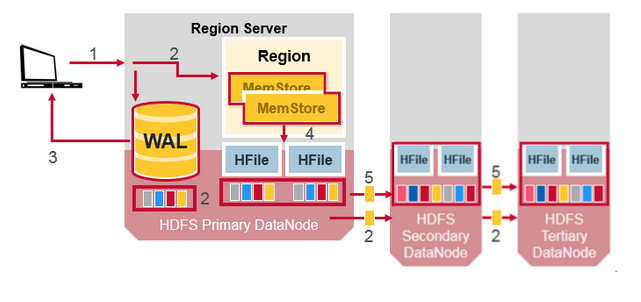
HDFS的数据复制(2)
预写日志(WAL) 和 HFile都存在HDFS里面, 可以保证数据的可靠性, 但是HBase memstore里的数据都在内存中, 如果系统崩溃后重启, Hbase如何恢复Memstore里面的数据?
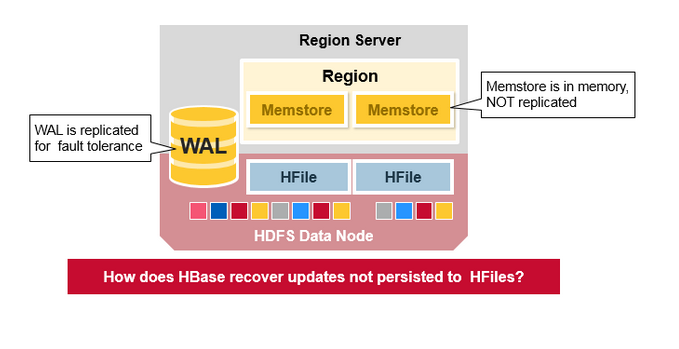
译注: 从上图看memstore的数据在内存中, 也没有多副本
HBase的灾难恢复
当region server宕机, 崩溃的region server管理的region不能再提供服务, HBase监测到异常后, 启动恢复程序, 恢复region.
Zookeeper发现region server的heartbeat停止, 判断region server宕机并通知master节点. Hbase master节点得知该region server停机后, 将崩溃的region server管理的region分配给其他region server. HBase从预写文件(WAL)里恢复memstore里的数据.
HBase master知道老的region被重新分配到哪些新的region server. Master把已经crash的Region server的预写日志(WAL)拆分成多个. 参与故障恢复的每个region server重放的预写日志(WAL), 重新构建出丢失Memstore.
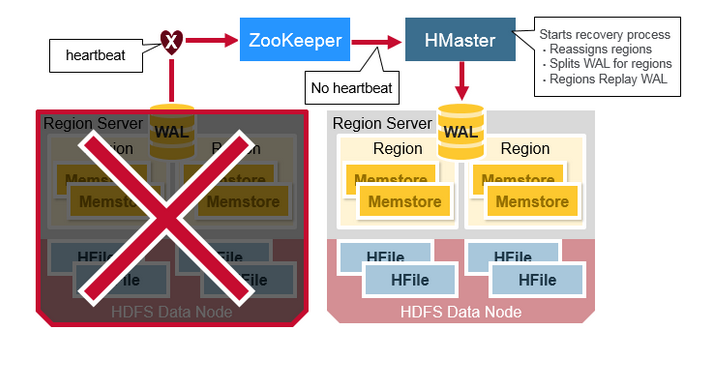
数据恢复
预写日志(WAL)记录了HBase的每个操作, 每个操作代表一个Put或者删除Delete动作. 所有的操作按照时间顺序在预写日志(WAL)排列, 文件头记录最老的操作, 最新的操作处于文件末尾.
如何恢复在memstore里, 但还没有写到HFile的数据? 重新执行预写日志(WAL)就可以. 从前到后依次执行预写日志(WAL)里的操作, 重建memstore数据. 最后, Flush memstore数据到的HFile, 完成恢复.
Apache Hbase架构优点
强一致模型
- 当写返回时, 确保所有读操作读到相同的值
自动扩展
- 数据增长过大时, 自动分裂region
- 利用HFDS分散数据和备份数据
内建自动回复
- 预写日志(WAL)
集成Hadoop生态
- 在HBase上运行map reduce
Apache HBase存在的问题...
- Business continuity reliability:
- 重放预写日志慢
- 故障恢复既慢又复杂
- Major compaction容易引起IO风暴(写放大)
Guidelines for HBase Schema Design
In this blog post, I’ll discuss how HBase schema is different from traditional relational schema modeling, and I’ll also provide you with some guidelines for proper HBase schema design.
Relational vs. HBase Schemas
There is no one-to-one mapping from relational databases to HBase. In relational design, the focus and effort is around describing the entity and its interaction with other entities; the queries and indexes are designed later.
With HBase, you have a “query-first” schema design; all possible queries should be identified first, and the schema model designed accordingly. You should design your HBase schema to take advantage of the strengths of HBase. Think about your access patterns, and design your schema so that the data that is read together is stored together. Remember that HBase is designed for clustering.
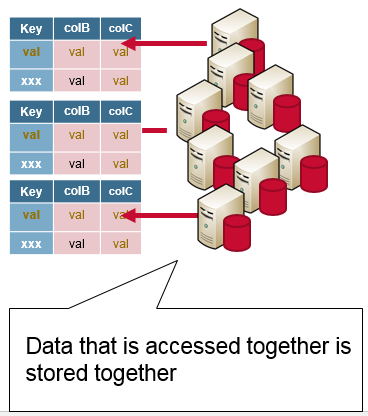
- Distributed data is stored and accessed together
- It is query-centric, so focus on how the data is read
- Design for the questions
Normalization
In a relational database, you normalize the schema to eliminate redundancy by putting repeating information into a table of its own. This has the following benefits:
- You don’t have to update multiple copies when an update happens, which makes writes faster.
- You reduce the storage size by having a single copy instead of multiple copies.
However, this causes joins. Since data has to be retrieved from more tables, queries can take more time to complete.
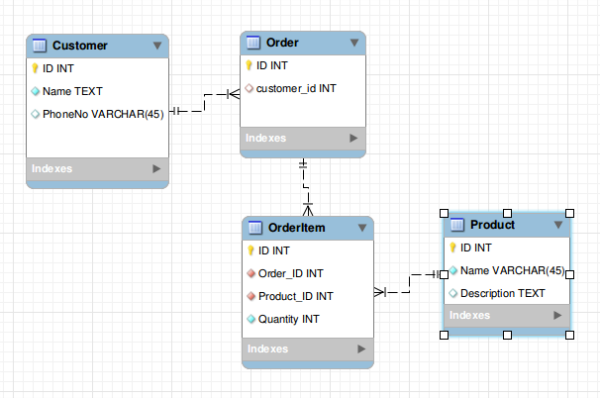
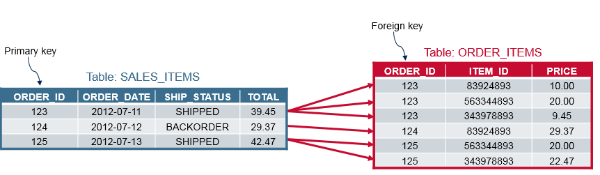
In this example below, we have an order table which has one-to-many relationship with an order items table. The order items table has a foreign key with the id of the corresponding order.
De-normalization
In a de-normalized datastore, you store in one table what would be multiple indexes in a relational world. De-normalization can be thought of as a replacement for joins. Often with HBase, you de-normalize or duplicate data so that data is accessed and stored together.
Parent-Child Relationship–Nested Entity
Here is an example of denormalization in HBase, if your tables exist in a one-to-many relationship, it’s possible to model it in HBase as a single row. In the example below, the order and related line items are stored together and can be read together with a get on the row key. This makes the reads a lot faster than joining tables together.
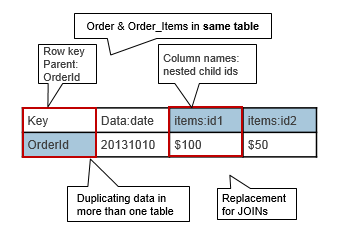
The rowkey corresponds to the parent entity id, the OrderId. There is one column family for the order data, and one column family for the order items. The Order Items are nested, the Order Item IDs are put into the column names and any non-identifying attributes are put into the value.
This kind of schema design is appropriate when the only way you get at the child entities is via the parent entity.
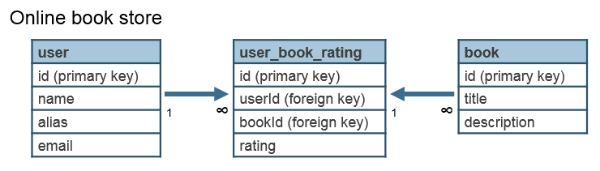
Many-to-Many Relationship in an RDBMS
Here is an example of a many-to-many relationship in a relational database. These are the query requirements:
- Get name for user x
- Get title for book x
- Get books and corresponding ratings for userID x
- Get all userIDs and corresponding ratings for book y
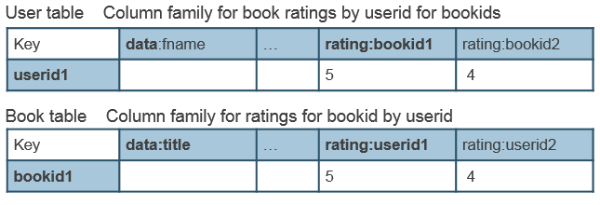
Many-to-Many Relationship in HBase
The queries that we are interested in are:
- Get books and corresponding ratings for userID x
- Get all userIDs and corresponding ratings for book y
For an entity table, it is pretty common to have one column family storing all the entity attributes, and column families to store the links to other entities.
The entity tables are as shown below:
Generic Data, Event Data, and Entity-Attribute-Value
Generic data that is schemaless is often expressed as name value or entity attribute value. In a relational database, this is complicated to represent. A conventional relational table consists of attribute columns that are relevant for every row in the table, because every row represents an instance of a similar object. A different set of attributes represents a different type of object, and thus belongs in a different table. The advantage of HBase is that you can define columns on the fly, put attribute names in column qualifiers, and group data by column families.
Here is an example of clinical patient event data. The Row Key is the patient ID plus a time stamp. The variable event type is put in the column qualifier, and the event measurement is put in the column value. OpenTSDB is an example of variable system monitoring data.

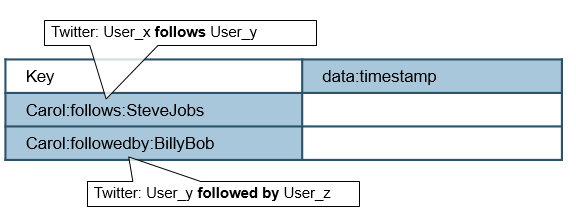
Self-Join Relationship – HBase
A self-join is a relationship in which both match fields are defined in the same table.
Consider a schema for twitter relationships, where the queries are: which users does userX follow, and which users follow userX? Here’s a possible solution: The userids are put in a composite row key with the relationship type as a separator. For example, Carol follows Steve Jobs and Carol is followed by BillyBob. This allows for row key scans for everyone carol:follows or carol:followedby
Below is the example Twitter table:
Tree, Graph Data
Here is an example of an adjacency list or graph, using a separate column for each parent and child:
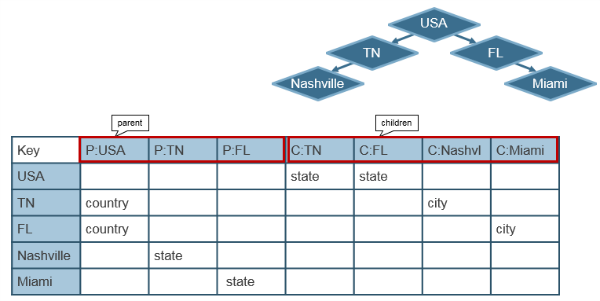
Each row shows a node, and the row key is equal to the node id. There is a column family for parent p, and a column family children c. The column qualifiers are equal to the parent or child node ids, and the value is equal to the type to node. This allows to quickly find the parent or children nodes from the row key.
You can see there are multiple ways to represent trees, the best way depends on your queries.
Inheritance Mapping
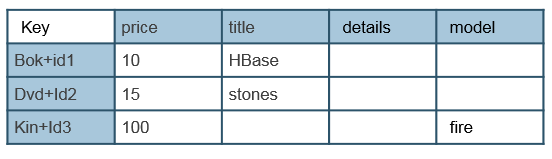
In this online store example, the type of product is a prefix in the row key. Some of the columns are different, and may be empty depending on the type of product. This allows to model different product types in the same table and to scan easily by product type.
Data Access Patterns
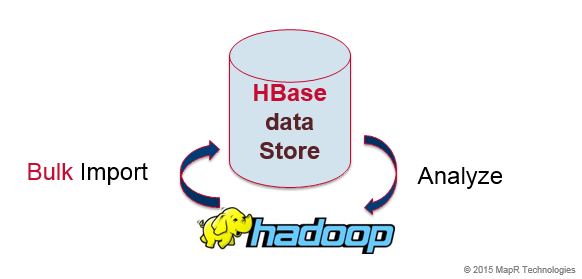
Use Cases: Large-scale offline ETL analytics and generating derived data
In analytics, data is written multiple orders of magnitude more frequently than it is read. Offline analysis can also be used to provide a snapshot for online viewing. Offline systems don’t have a low-latency requirement; that is, a response isn’t expected immediately. Offline HBase ETL data access patterns, such as Map Reduce or Hive, are characterized by high latency reads and high throughput writes.
Data Access Patterns
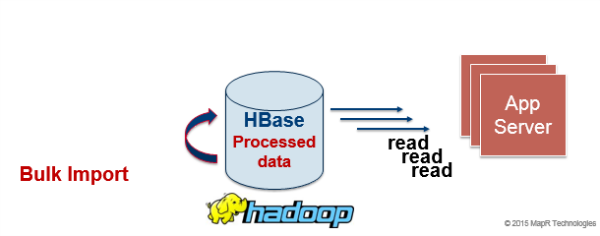
Use Cases: Materialized view, pre-calculated summaries
To provide fast reads for online web sites, or an online view of data from data analysis, MapReduce jobs can reorganize the data into different groups for different readers or materialized views. Batch offline analysis could also be used to provide a snapshot for online views. This is going to be high throughput for batch offline writes and high latency for read (when online).
Examples include:
• Generating derived data, duplicating data for reads in HBase schemas, and delayed secondary indexes
Schema Design Exploration:
- Raw data from HDFS or HBase
- MapReduce for data transformation and ETL from raw data.
- Use bulk import from MapReduce to HBase
- Serve data for online reads from HBase
Designing for reads means aggressively de-normalizing data so that the data that is read together is stored together.
Data Access Patterns
Lambda Architecture
The Lambda architecture solves the problem of computing arbitrary functions on arbitrary data in real time by decomposing the problem into three layers: the batch layer, the serving layer, and the speed layer.
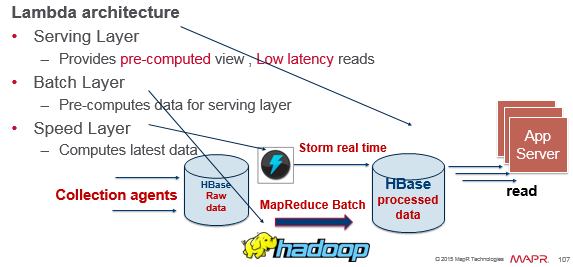
MapReduce jobs are used to create artifacts useful to consumers at scale. Incremental updates are handled in real time by processing updates to HBase in a Storm cluster, and are applied to the artifacts produced by MapReduce jobs.
The batch layer precomputes the batch views. In the batch view, you read the results from a precomputed view. The precomputed view is indexed so that it can be accessed quickly with random reads.
The serving layer indexes the batch view and loads it up so it can be efficiently queried to get particular values out of the view. A serving layer database only requires batch updates and random reads. The serving layer updates whenever the batch layer finishes precomputing a batch view.
You can do stream-based processing with Storm and batch processing with Hadoop. The speed layer only produces views on recent data, and is for functions computed on data in the few hours not covered by the batch. In order to achieve the fastest latencies possible, the speed layer doesn’t look at all the new data at once. Instead, it updates the real time view as it receives new data, instead of re-computing them like the batch layer does. In the speed layer, HBase provides the ability for Storm to continuously increment the real-time views.
How does Storm know to process new data in HBase? A needs work flag is set. Processing components scan for notifications and process them as they enter the system.
MapReduce Execution and Data Flow
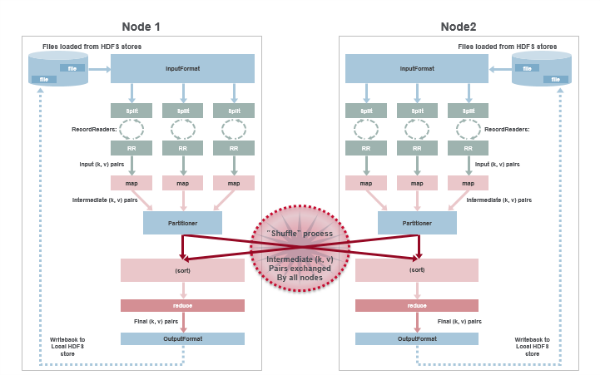
The flow of data in a MapReduce execution is as follows:
- Data is being loaded from the Hadoop file system
- Next, the job defines the input format of the data
- Data is then split between different map() methods running on all the nodes
- Then record readers parse out the data into key-value pairs that serve as input into the map() methods
- The map() method produces key-value pairs that are sent to the partitioner
- When there are multiple reducers, the mapper creates one partition for each reduce task
- The key-value pairs are sorted by key in each partition
- The reduce() method takes the intermediate key-value pairs and reduces them to a final list of key-value pairs
- The job defines the output format of the data
- Data is written to the Hadoop file system
In this blog post, you learned how HBase schema is different from traditional relational schema modeling, and you also got some guidelines for proper HBase schema design. If you have any questions about this blog post, please ask them in the comments section below.
Want to learn more? Take a look at these resources that I used to prepare this blog post:
Here are some additional resources for helping you get started with HBase:
