

通过使用 LruCache, 查看 LinkedHashMap 源码, 分析 LRU 算法的具体实现细节.
LRU 算法描述
当序列达到设置的内存上限时, 丢弃序列中最近最少使用的元素.
LruCache
Android SDK 提供的使用了(Least Recently Used)最近最少使用算法的缓存类.
编写一个 LruCache, 用于缓存 Integer.
public class IntegerCache extends LruCache<String, Integer> {
public IntegerCache(int maxSize) {
super(maxSize);
}
@Override
protected int sizeOf(String key, Integer value) {
return Integer.SIZE;
}
}
// 最大容量为 4 个 Integer
IntegerCache ca = new IntegerCache(4 * Integer.SIZE)
ca.put("1", 1);
ca.put("2", 2);
ca.put("3", 3);
ca.put("4", 4);
ca.get("4");
ca.put("5", 5);
ca.put("4", 4);
ca.put("6", 6);
缓存中内容:
{1=1} // put 1
{1=1, 2=2} // put 2
{1=1, 2=2, 3=3} // put 3
{1=1, 2=2, 3=3, 4=4} // put 4
---
{1=1, 2=2, 3=3, 4=4} // get 4
{2=2, 3=3, 4=4, 5=5} // put 5
{2=2, 3=3, 5=5, 4=4} // put 4
{3=3, 5=5, 4=4, 6=6} // put 6
可见, 每次的 get 和 put 操作, 都会造成序列中的重排序, 最近使用的元素在末尾, 最近最少使用的元素在头部, 当容量超过限制时会移出最近最少使用的元素.
LruCache 的构造
public class LruCache<K, V> {
// 构造时就初始化的一个 LinkedHashMap
private final LinkedHashMap<K, V> map;
private int size; /* 记录当前缓存占用的内存大小 */
private int maxSize; /* 最多能缓存的内存大小 */
private int putCount; /* 记录 put 调用的次数 */
private int createCount; /* 记录 create 调用的次数 */
private int evictionCount; /* 记录被丢弃的对象个数 */
private int hitCount; /* 记录调用 get 时,缓存命中的次数 */
private int missCount; /* 记录调用 get 时,缓存未命中的次数 */
public LruCache(int maxSize) {
if (maxSize <= 0) {
throw new IllegalArgumentException("maxSize <= 0");
}
this.maxSize = maxSize;
// 初始容量为0, 扩容系数为 0.75, 排序模式: true 表示按访问排序, false 表示按插入排序, SDK 实现里固定为 ture
this.map = new LinkedHashMap<K, V>(0, 0.75f, true);
}
LruCache 插入元素
public final V put(K key, V value) {
V previous;
synchronized (this) {
putCount++;
// 内存占用记录增加
size += safeSizeOf(key, value);
// 存入新的值, 并获取 key 对应的旧值
previous = map.put(key, value);
if (previous != null) {
// 如果旧值存在, 就减去对应内存
size -= safeSizeOf(key, previous);
}
}
// 如果 size > maxSize, 就执行丢弃元素, 裁剪内存操作
trimToSize(maxSize);
return previous;
}
LurCache 获取缓存
public final V get(K key) {
V mapValue;
synchronized (this) {
// 从缓存中获取 key 对应的 value, 如果存在就直接返回
mapValue = map.get(key);
if (mapValue != null) {
hitCount++;
return mapValue;
}
missCount++;
}
// 如果缓存中没有, 就尝试创建一个对应对象, 该方法由子类实现, 可以返回 null
V createdValue = create(key);
if (createdValue == null) {
return null;
}
// 如果子类 create 返回了非 null 对象, 就把这个对象返回, 并插入到缓存中
synchronized (this) {
createCount++;
mapValue = map.put(key, createdValue);
// 上面 get 时得到了 null 才会走到这, 怎么在插入时旧值又跑出来了 ?
if (mapValue != null) {
// 这里应该是避免多线程访问时, 在 get 获取为 null 之后, 其他线程插入了对应的值, 所以这里把其他线程插入的值还原回去
map.put(key, mapValue);
} else {
// 如果没有其他插入, 就把新创建的内存占用记账
size += safeSizeOf(key, createdValue);
}
}
...
}
以上就是 LruCache 里主要的方法了, 看完也没发现与 LRU 算法有关的东西, 那 LRU 的具体实现肯定就在 LinkedHashMap 里了.
LinkedHashMap 的实现
- 内部数据结构: 双向链表
// LinkedHashMap 的节点数据结构, 继承自 HashMap.Node
static class LinkedHashMapEntry<K,V> extends HashMap.Node<K,V> {
LinkedHashMapEntry<K,V> before, after;
LinkedHashMapEntry(int hash, K key, V value, Node<K,V> next) {
super(hash, key, value, next);
}
}
构造
public LinkedHashMap(int initialCapacity,
float loadFactor,
boolean accessOrder) {
super(initialCapacity, loadFactor);
// accessOrder 决定内部的排序顺序
this.accessOrder = accessOrder;
}
获取操作
public V get(Object key) {
Node<K,V> e;
// 调用父类 HashMap 的方法
if ((e = getNode(hash(key), key)) == null)
return null;
// 如果按访问顺序排序为 ture, 则进行重排序
if (accessOrder)
// 将 e 移动到最后
afterNodeAccess(e);
return e.value;
}
可以看到, 重点就是 afterNodeAccess 这个方法.
访问 node 之后的排序操作
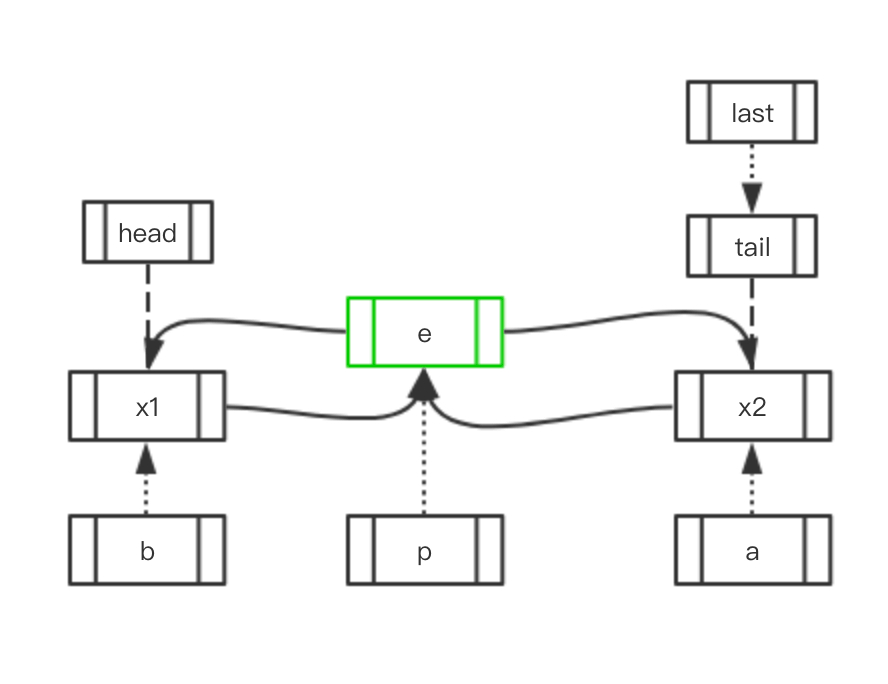
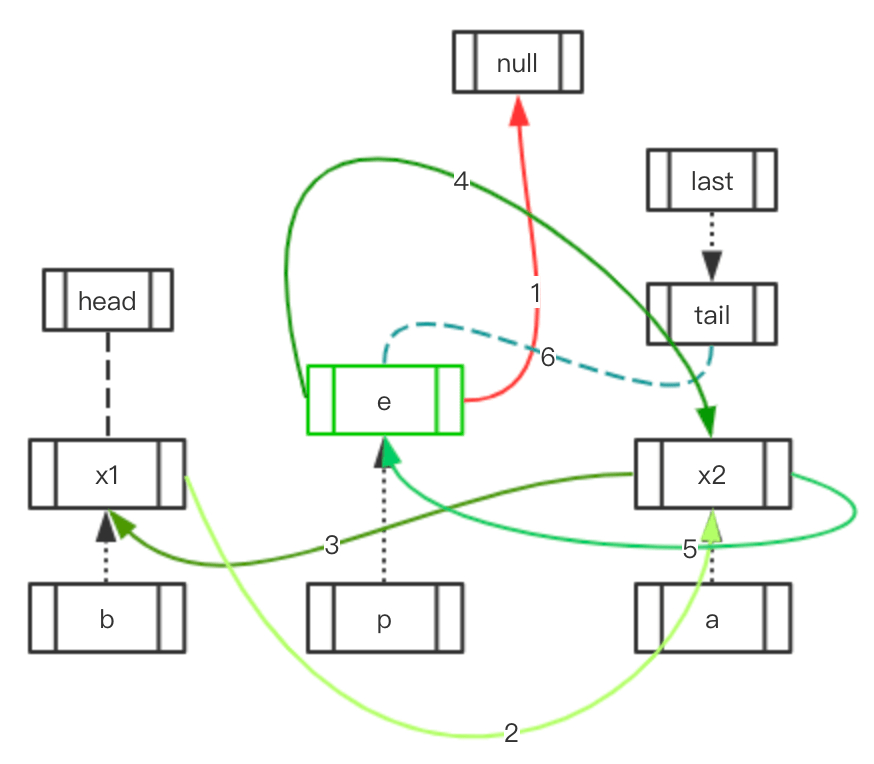
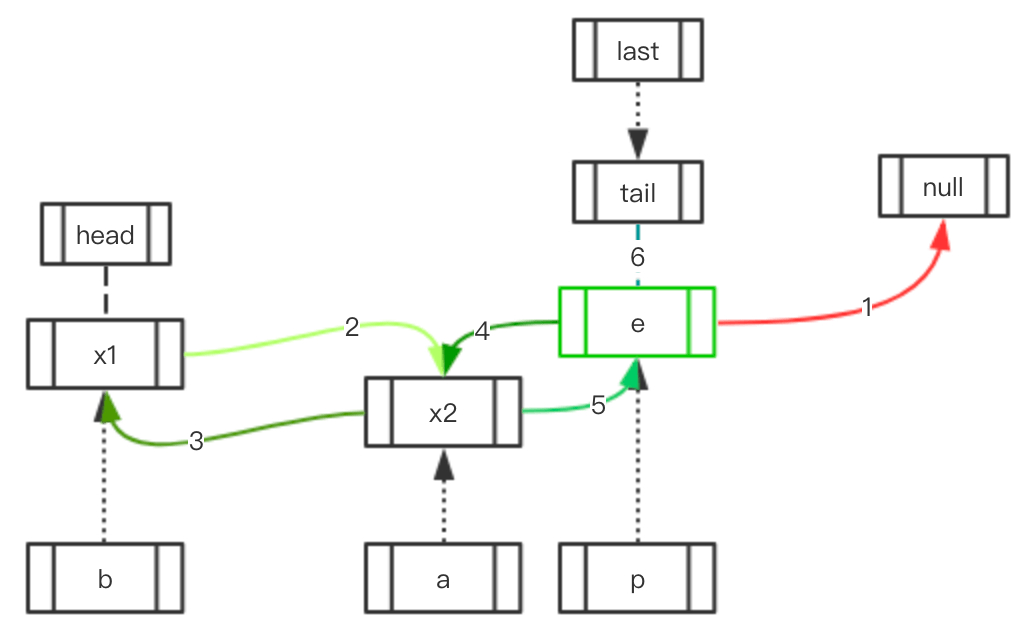
void afterNodeAccess(Node<K,V> e) { // move node to last
LinkedHashMapEntry<K,V> last;
if (accessOrder && (last = tail) != e) {
LinkedHashMapEntry<K,V> p = (LinkedHashMapEntry<K,V>)e, /* p 指向当前节点 e */
b = p.before, /* b 指向前一个节点 */
a = p.after; /* a 指向后一个节点 */
p.after = null; /* 当前节点 after 置 null */
if (b == null)
head = a;
else
b.after = a;
if (a != null)
a.before = b;
else
last = b;
if (last == null)
head = p;
else {
p.before = last;
last.after = p;
}
tail = p;
++modCount;
}
}
Case 1: 访问元素的前后存在元素
| 初始状态 | 移动指向 | 最终结果 |
|---|---|---|
 |
 |
 |
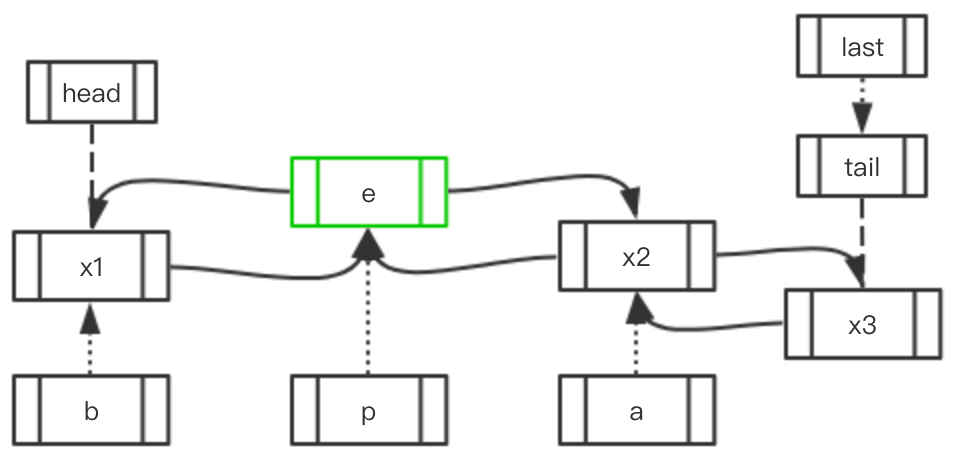
Case 1.2: 访问元素的前后存在多个元素
| 初始状态 | 移动指向 | 最终结果 |
|---|---|---|
 |
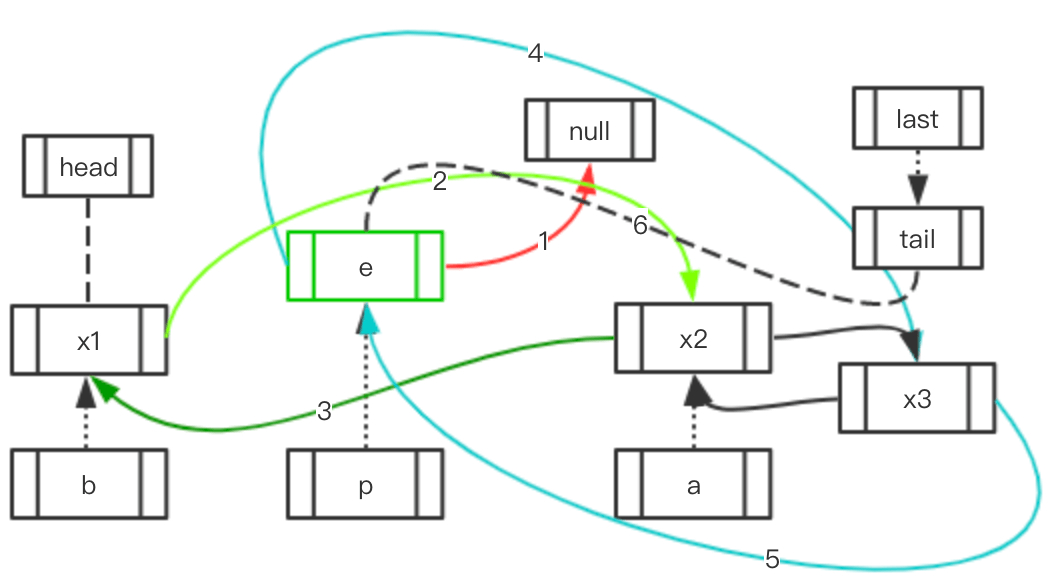 |
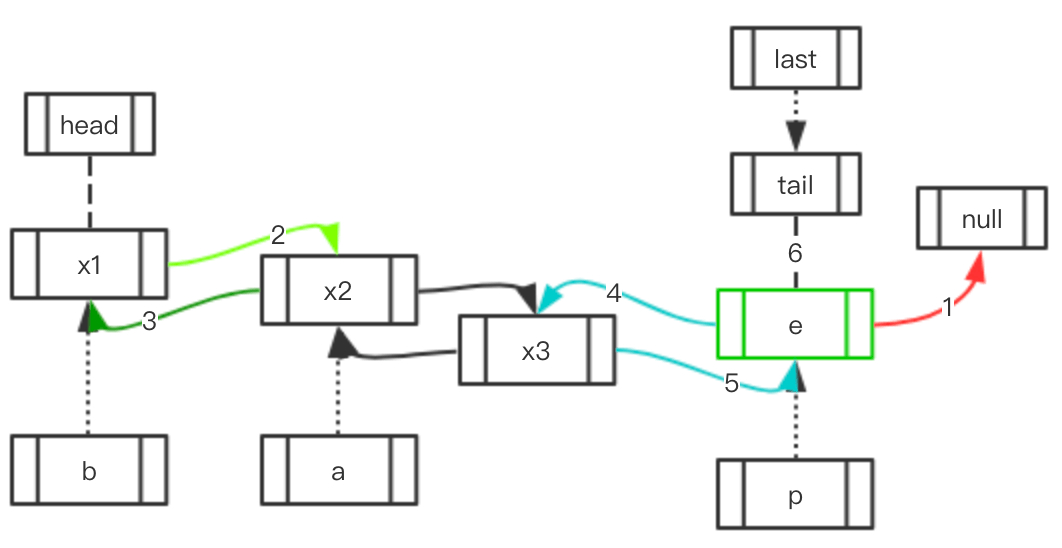 |
Case 2: 访问元素的后面存在元素, 前面不存在
| 初始状态 | 移动指向 | 最终结果 |
|---|---|---|
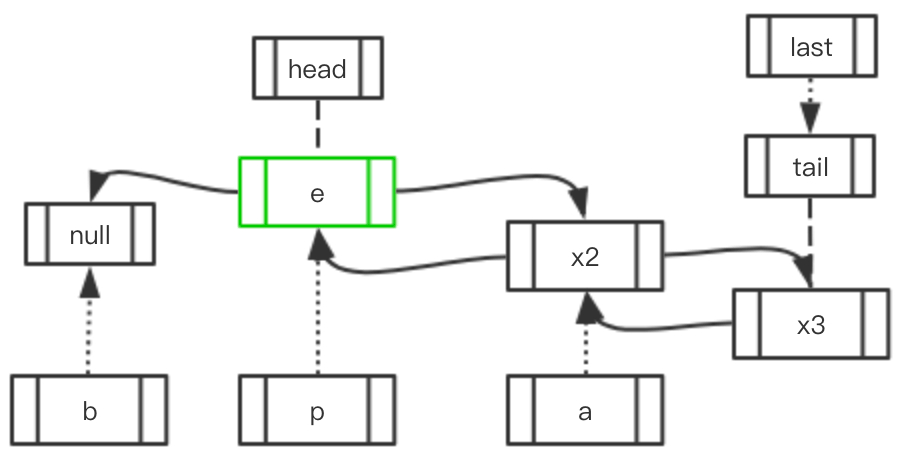 |
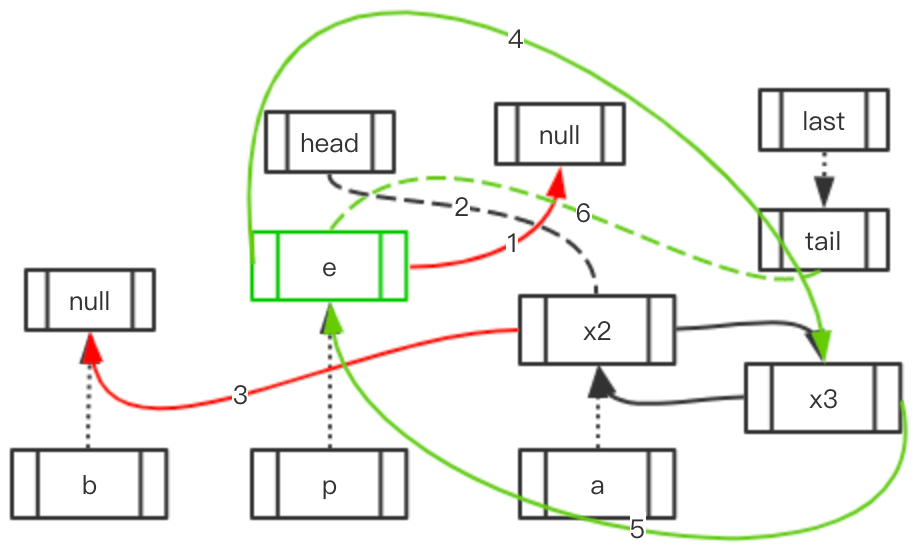 |
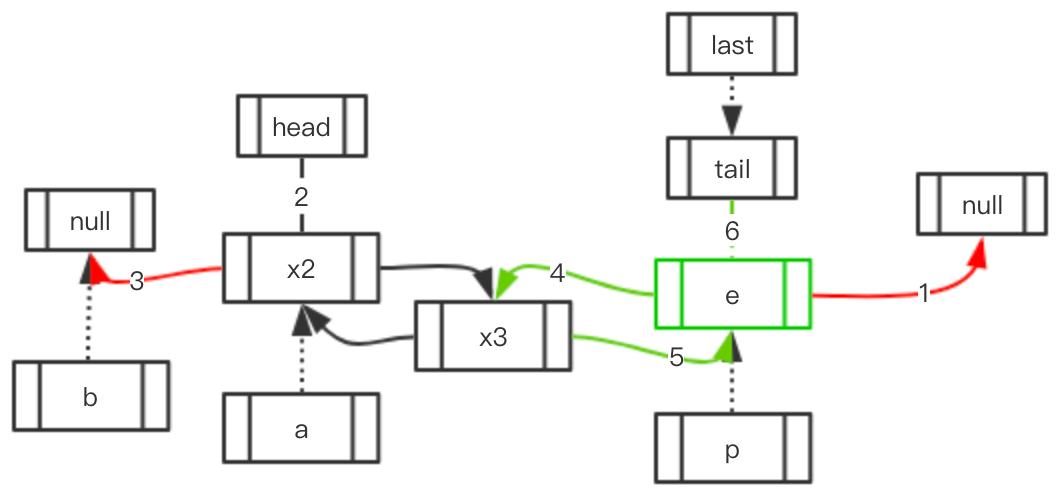 |
Case 3: 访问元素的前面存在元素, 后面不存在
这种 case 不会做排序操作, 因为元素已经位于链表尾部了.
在访问元素之后, 通过 afterNodeAccess 排序之后, 被访问的元素就移动到了链表的尾部.
插入操作
LinkedHashMap 的 put 操作是直接调用父类 HashMap 的, HashMap 的 put 操作之后, 被插入的元素将会位于链表的尾部, 然后会调用 afterNodeInsertion, 该方法在 LinkedHashMap 中的实现:
void afterNodeInsertion(boolean evict) { // possibly remove eldest
LinkedHashMapEntry<K,V> first;
// 如果 removeEldestEntry 为 true, 则移出头部的元素
// LinkedHashMap 中 removeEldestEntry 默认返回 false
if (evict && (first = head) != null && removeEldestEntry(first)) {
K key = first.key;
removeNode(hash(key), key, null, false, true);
}
}
由于 LinkedHashMap 中 removeEldestEntry 默认返回 false, 所以 LinkedHashMap 的插入操作, 默认不会移出元素, 移出元素的操作实际在 LruCache 中的 trimToSize 实现.
在获取和插入之后, LinkedHashMap 中的元素排列就会是: 最近最多使用的位于尾部, 最近最少使用的位于头部.
LruCache 的 trimToSize
trimToSize 目的在于当缓存大于设置的最大内存时, 会移出最近最少使用到的元素(在 LinkedHashMap 中就是头部的元素):
public void trimToSize(int maxSize) {
while (true) {
K key;
V value;
synchronized (this) {
if (size <= maxSize) {
break;
}
// 该方法会返回 LinkedHashMap 的头节点
Map.Entry<K, V> toEvict = map.eldest();
if (toEvict == null) {
break;
}
key = toEvict.getKey();
value = toEvict.getValue();
// 移出这个节点
map.remove(key);
size -= safeSizeOf(key, value);
evictionCount++;
}
entryRemoved(true, key, value, null);
}
}
总结
-
Android 提供的
LruCache基于LinkedHashMap实现, 利用LinkedHashMap会在每次访问元素之后, 将元素移动到序列末尾的特点, 保证了最近最多使用的元素位于尾部, 最近最少使用的元素位于头部. 当缓存占用达到设置的上限时,LruCache就会移出LinkedHashMap中的头节点. -
LinkedHashMap扩展HashMap, 实现了一套双向链表机制, 保证了在元素的移动上和元素的查找上的时间复杂度都为.
