

其他更多java基础文章:
java基础学习(目录)
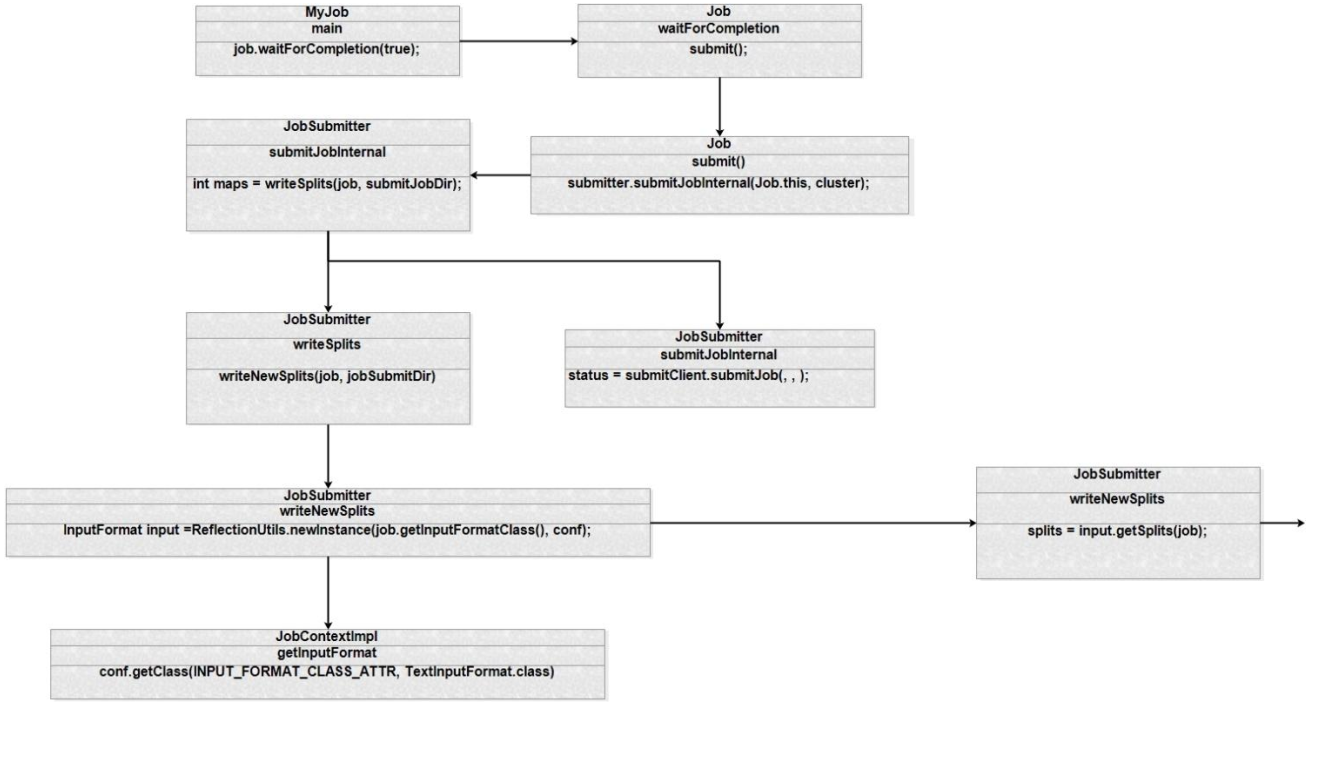
我们从client端的入口job.waitForCompletion(true)开始看:
public static void main(String[] args) throws Exception{
Configuration configuration = new Configuration();
configuration.set("hbase.zookeeper.quorum",Hconfiguration.hbase_zookeeper_quorum);
configuration.set("hbase.zookeeper.clientPort","2181");
configuration.set(TableOutputFormat.OUTPUT_TABLE,Hconfiguration.tableName);
configuration.set("dfs.socket.timeout","1800000");
MRDriver myDriver = MRDriver.getInstance();
/*try{
myDriver.creatTable(Hconfiguration.tableName, Hconfiguration.colFamily);
}catch (Exception e){
e.printStackTrace();
}*/
Job job = new Job(configuration,"Map+ReduceImport");
job.setMapperClass(HMapper.class);
job.setReducerClass(HReducer.class);
job.setMapOutputKeyClass(LongWritable.class);
job.setMapOutputValueClass(Text.class);
job.setInputFormatClass(TextInputFormat.class);
job.setOutputFormatClass(TableOutputFormat.class);
FileInputFormat.setInputPaths(job, Hconfiguration.mapreduce_inputPath);
job.waitForCompletion(true);
}
public boolean waitForCompletion(boolean verbose) throws IOException, InterruptedException,ClassNotFoundException {
if (state == JobState.DEFINE) {
//重点是提交的过程
submit();
}
if (verbose) {
//监控并打印执行过程
monitorAndPrintJob();
} else {
……
}
return isSuccessful();
}
我们跟进去看,继续submit()方法,submit()调用 submitJobInternal()方法把作业提交到集群
public void submit()throws IOException, InterruptedException,ClassNotFoundException {
ensureState(JobState.DEFINE);
//判断使用的是 hadoop 1.x 还是 2.x 的 jar 包
setUseNewAPI();
//连接集群
connect();
final JobSubmitter submitter = getJobSubmitter(cluster.getFileSystem(), cluster.getClient());
status = ugi.doAs(new PrivilegedExceptionAction<JobStatus>() {public JobStatus run() throws IOException,
InterruptedException, ClassNotFoundException {
//把作业提交到集群
return submitter.submitJobInternal(Job.this, cluster);
}
});
……
}
submitJobInternal()方法详解:
JobStatus submitJobInternal(Job job, Cluster cluster)
throws ClassNotFoundException, InterruptedException, IOException {
//validate the jobs output specs
//Checking the input and output specifications of the job. 检查输入输出路径
checkSpecs(job);
Configuration conf = job.getConfiguration();
addMRFrameworkToDistributedCache(conf);
Path jobStagingArea = JobSubmissionFiles.getStagingDir(cluster, conf);
//configure the command line options correctly on the submitting dfs
InetAddress ip = InetAddress.getLocalHost();
if (ip != null) {
//封装提交的信息
submitHostAddress = ip.getHostAddress();
submitHostName = ip.getHostName();
conf.set(MRJobConfig.JOB_SUBMITHOST,submitHostName);
conf.set(MRJobConfig.JOB_SUBMITHOSTADDR,
submitHostAddress);
}
JobID jobId = submitClient.getNewJobID();
job.setJobID(jobId);
//获得提交的目录
Path submitJobDir = new Path(jobStagingArea, jobId.toString());
JobStatus status = null;
……
//copy 配置文件
copyAndConfigureFiles(job, submitJobDir);
Path submitJobFile =
JobSubmissionFiles.getJobConfPath(submitJobDir);// Create the splits for the job 创建切片
LOG.debug("Creating splits at " + jtFs.makeQualified(submitJobDir));
//创建切片的方法
int maps = writeSplits(job, submitJobDir);
conf.setInt(MRJobConfig.NUM_MAPS, maps);
LOG.info("number of splits:" + maps);
……
// Write job file to submit dirwriteConf(conf, submitJobFile);
// Now, actually submit the job (using the submit name)
printTokens(jobId, job.getCredentials());
//之前都是提交前的准备, 最终提交作业
status = submitClient.submitJob(
jobId, submitJobDir.toString(), job.getCredentials());
……
}
writeSplits()调用 writeNewSplits()
private int writeSplits(org.apache.hadoop.mapreduce.JobContext job, Path jobSubmitDir)
throws IOException, InterruptedException, ClassNotFoundException {
JobConf jConf = (JobConf)job.getConfiguration();
int maps;
//根据前面的信息选择使用 1.x 或者 2.x 的配置
if (jConf.getUseNewMapper()) {
maps = writeNewSplits(job, jobSubmitDir);
} else {
maps = writeOldSplits(jConf, jobSubmitDir);
}
return maps;
}
我们继续跟进看writeNewSplits(job, jobSubmitDir)方法
private <T extends InputSplit> int writeNewSplits(JobContext job, Path jobSubmitDir) throws
IOException,InterruptedException, ClassNotFoundException {
Configuration conf = job.getConfiguration();
//通过反射得到 InputFormatClass
InputFormat<?, ?> input = ReflectionUtils.newInstance(job.getInputFormatClass(), conf);
List<InputSplit> splits = input.getSplits(job);
……
}
这里有两个方法重点跟进一下,一个是getInputFormatClass(),另一个是getSplits(job)。我们先看一下getInputFormatClass()方法
public Class<? extends InputFormat<?,?>> getInputFormatClass() throws ClassNotFoundException {
return (Class<? extends InputFormat<?,?>>)
//如果用户设置过 InputFormat,
//job.setInputFormatClass(cls);
//就使用用户设置的
//否则使用默认的 Textconf.getClass(INPUT_FORMAT_CLASS_ATTR,TextInputFormat.class);
}
然后我们继续看getSplits(job)方法。这个方法非常重要
public List<InputSplit> getSplits(JobContext job) throws IOException {
Stopwatch sw = new Stopwatch().start();
//在用户没有干预的情况下, 值为 1
long minSize = Math.max(getFormatMinSplitSize(),getMinSplitSize(job));
/*
protected long getFormatMinSplitSize() {
return 1;
}
public static long getMinSplitSize(JobContext job) {
如果用户设置了,用用户设置的值,否则使用1
//FileInputFormat.setMinInputSplitSize(job, size);
return job.getConfiguration().getLong(SPLIT_MINSIZE, 1L);
}
*/
long maxSize = getMaxSplitSize(job);
/*
如果用户设置了, 去用户的值, 否则去一个无限大的值
public static long getMaxSplitSize(JobContext context) {
return context.getConfiguration().getLong(SPLIT_MAXSIZE,Long.MAX_VALUE);
}
*/
// generate splits
List<InputSplit> splits = new ArrayList<InputSplit>();
List<FileStatus> files = listStatus(job);
//迭代用户给的目录下的所有文件,得到每个文件的
//BlockLocations
for (FileStatus file: files) {
Path path = file.getPath();
long length = file.getLen();
if (length != 0) {
BlockLocation[] blkLocations;
if (file instanceof LocatedFileStatus) {
blkLocations = ((LocatedFileStatus)file).getBlockLocations();
} else {
FileSystem fs = path.getFileSystem(job.getConfiguration());
blkLocations = fs.getFileBlockLocations(file, 0, length);
}
if (isSplitable(job, path)) {
long blockSize = file.getBlockSize();
long splitSize = computeSplitSize(blockSize, minSize, maxSize);
/*
在用户没有干预的情况下
取 maxSize 和 blockSize 的最小值, 默认情况下为 blockSize
取 blockSize 和 minSize 的最大值, 最后结果为 blockSize
protected long computeSplitSize(long blockSize, long minSize,long maxSize) {
return Math.max(minSize, Math.min(maxSize, blockSize));
}
*/
long bytesRemaining = length;
while (((double) bytesRemaining)/splitSize > SPLIT_SLOP) {
//计算切片属于哪个 block
int blkIndex = getBlockIndex(blkLocations, lengthbytesRemaining);
/*
protected int getBlockIndex(BlockLocation[] blkLocations,long offset) {
判断 offset 在 block 块的偏移量的哪个范围
for (int i = 0 ; i < blkLocations.length; i++) {
// is the offset inside this block?
if ((blkLocations[i].getOffset() <= offset) && (offset < blkLocations[i].getOffset() + blkLocations[i].getLength())){
return i;
}
}
BlockLocation last =blkLocations[blkLocations.length -1];
long fileLength = last.getOffset() + last.getLength() -1;
throw new IllegalArgumentException("Offset " + offset +" is outside of file (0.." + fileLength + ")");
}
*/
splits.add(makeSplit(path,
length-bytesRemaining, splitSize,
blkLocations[blkIndex].getHosts(),
blkLocations[blkIndex].getCachedHosts()));
bytesRemaining -= splitSize;
}
if (bytesRemaining != 0) {
int blkIndex = getBlockIndex(blkLocations, lengthbytesRemaining);
//创建切片
//切片信息包括文件名,偏移量,大小,位置信息
splits.add(makeSplit(path, length-bytesRemaining, bytesRemaining,
blkLocations[blkIndex].getHosts(),
blkLocations[blkIndex].getCachedHosts()));
}
} else { // not splitable
……
}
} else {
//Create empty hosts array for zero length files
……
}
}
……
return splits;
}
总的来说, 客户端做了以下几件事:
- 配置完善
- 检查路径
- 计算 split: maps
- 资源提交到 HDFS
- 提交任务
然后, AppMaster 根据 split 列表信息向 ResourceManager 申请资源, RS 创建 container,然 后 AppMaster 启动 container, 把 MapReducer 任务放进去。
总结图
public static final String MAP_MEMORY_MB = "mapreduce.map.memory.mb";
public static final int DEFAULT_MAP_MEMORY_MB = 1024;
Reduce 内存默认 1G,这个默认数值太小,应该调整
public static final String REDUCE_MEMORY_MB ="mapreduce.reduce.memory.mb";
public static final int DEFAULT_REDUCE_MEMORY_MB = 1024;
