

Android程序员面试会遇到的算法系列:
隔了三个月,终于下定决心继续更新了,还是想把 关于算法这部分写完整,这次我会开始介绍一些数据结构的用法,本来想说更新一个关于并查集的问题的。但是思前想后,还是字典树的实际用例更多一些,例子也容易让人理解。所以这次我要详细的讲一下Trie-> AKA 字典树这个数据结构的用法和一些实际的例子。
首先Trie这个单词是一个新的词汇,中文的翻译一般说是字典树,或者叫前缀树(因为用这个树结构可以通过前缀搜索数据),中文的翻译就比较容易让人理解。但是有趣的是这个单词的英文发音却很有争议,如果你在Google上搜索Trie Pronunciation,你会发现大家都在纠结于到底是发Tree的音还是Try的音。

当然,这些都不是重点,随便哪个我觉得大家都能理解,反正千万别到时候因为某些同学和你认知的发音不一样就去鄙视人家。。。

华丽丽的分割线
1. 字典树的原理
那么说会重点,通俗的来讲,字典树是一种可以方便人们通过前缀查找单词的一种数据结构,它把具有相同前缀的单词合并到一起,节省了存储空间(和直接用HashMap存相比),同时也可以做前缀查找或者自动补全。
举个例子,我就搬来维基百科的例子
假设我们要收录一下几个单词Tea, Ted, Ten,Inn。那么我们会以以下的方式把这些单词逐一录入树种:
- 创建初始节点Root, 当前插入节点为根节点
- 先准备录入Tea,分解Tea的字母T, E, A,先把第一个字母T放入根节点下面。并且把当前插入节点改为T
- 在T也就是当前插入节点下面放入E,当前插入节点改为E
- 在E也就是当前插入节点下面放入A,当前插入节点改为A,但是单词所有字母都输入结束了,因此在A上面打个tag,标记该节点是某个单词的结束字母。
第一个单词录入完毕
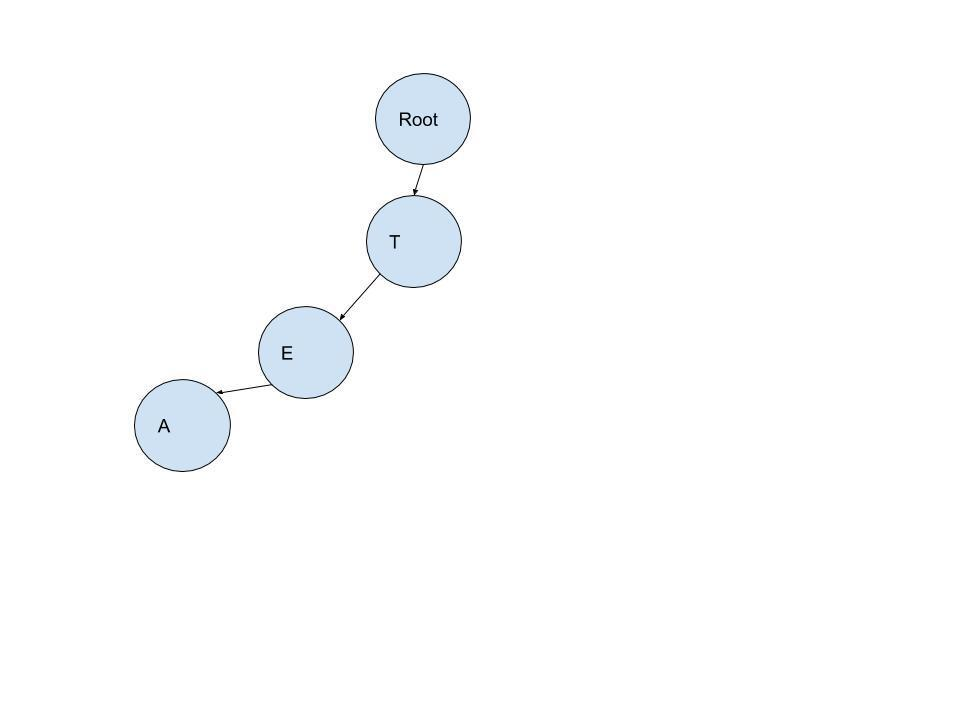
- 准备录入Ted,当前插入节点为根节点。分解单词Ted为T,E,D.准备插入第一个字母T
- 先检查根节点下面有没有T这个字母。答案是有,那么不需要再插入一个T了,直接将插入节点改为T。
- 第二个输入字母为E,同样的,T下面也有一个E,也不需要再插入E了,直接将插入节点改为E.
- 第三个输入字母为D,这次当前的插入节点E下面没有D,那么我们插入D,当前插入节点也改为D
- 因为TED输入完毕,所以在D上面打一个tag,标记标记该节点是某个单词的结束字母。
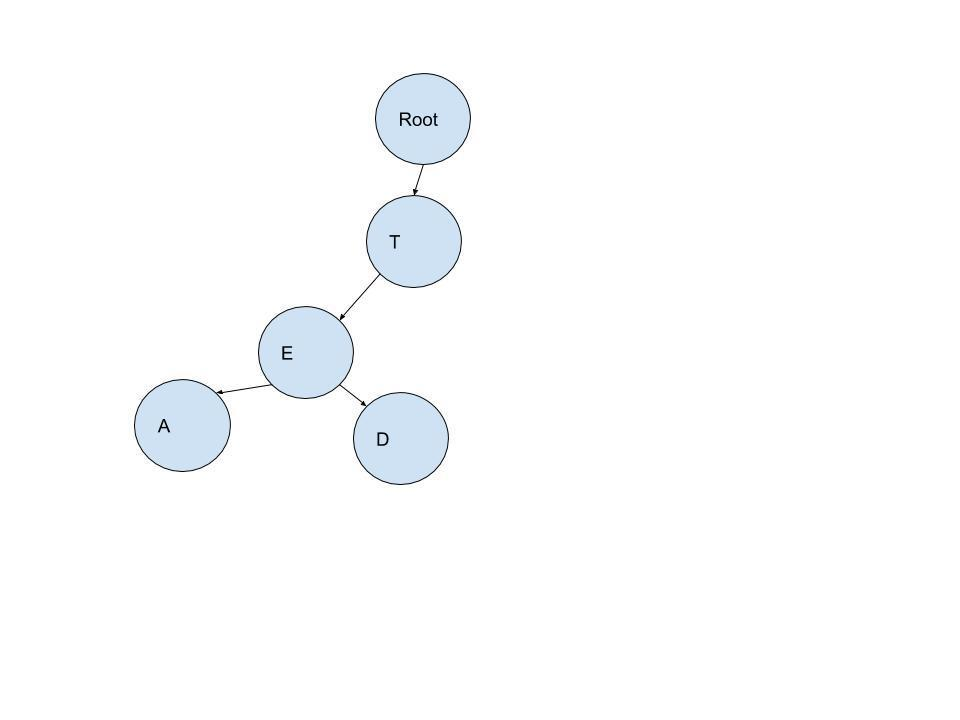
剩下的字母同理可得
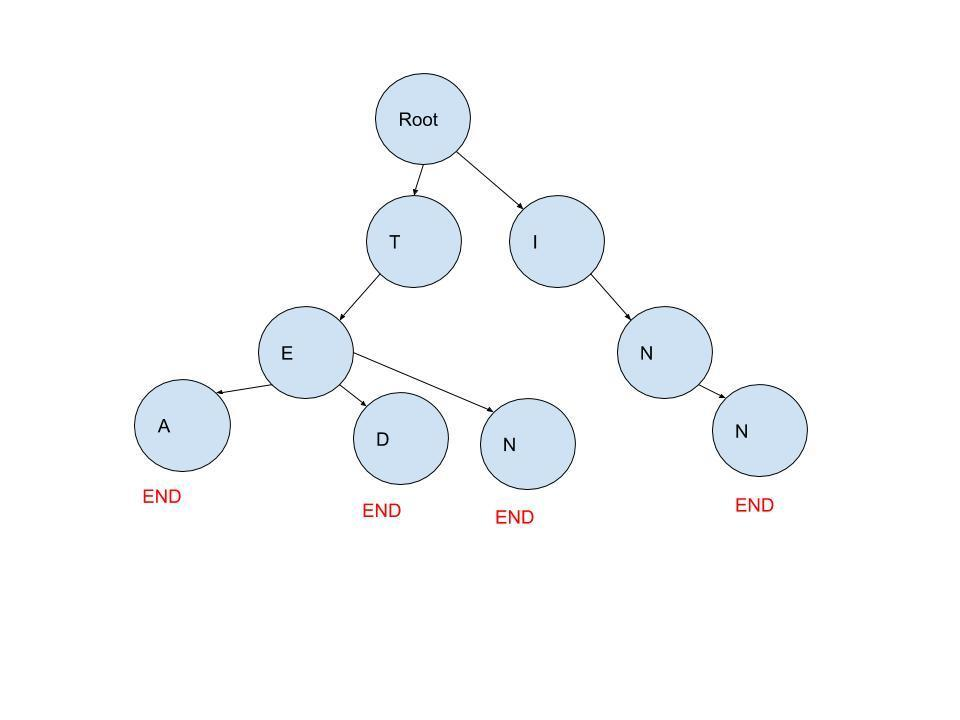
在讨论代码的实现之前,我们先看看字典树的实际应用:
2.字典树的应用。
2.1自动补全
字典树的最经典的应用肯定就是自动补全了,比如你在Google或者百度进行搜索的时候
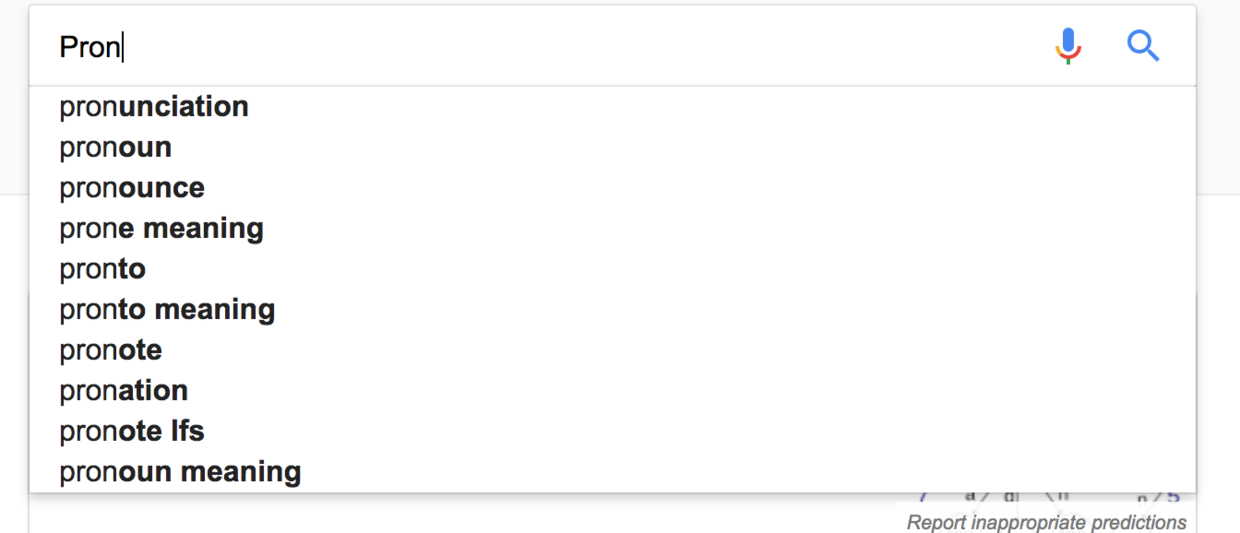
谷歌将很多热门的搜索单词用字典树的方式存储在后端,当Web网页搜索单词的前缀的时候,后端查找到该前缀最后一个节点的位置,将下面的子节点全部排列出来返回给前端。
比如用以上的例子,当用户搜索TE的时候,定位到最后一个节点E,将E节点下面的节点返回并且拼凑出一个完整的字符串,TED和TEA。
2.2 搜索文件
还有比如说当我们在Android Studio按下:alt+control+o,并且搜索文件的时候:
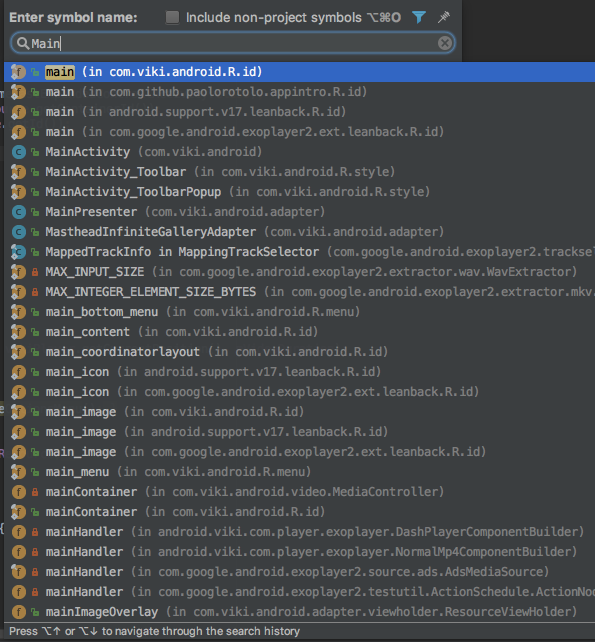
当我们搜索Main的时候,显示以Main开头的文件。
这个功能也可以用字典树实现(当然这是可以,不一定就是用字典树实现,事先声明免得误人子弟,因为做索引还可以用B树来做,类似数据库,这里不展开,感兴趣的可以看阮一峰大神的关于数据库原理的文章)
2.3 通讯录
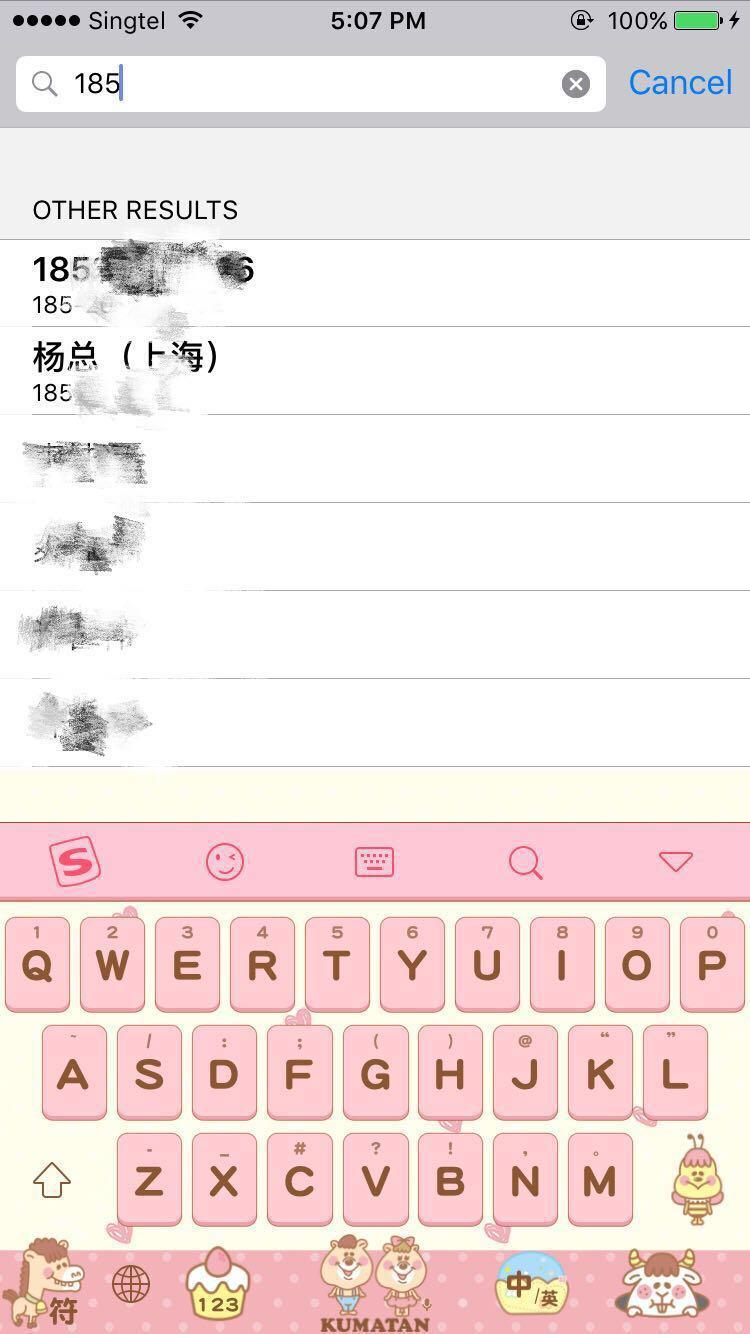
请自动忽略我粉红色的键盘。。。。

比如说我们在通讯录搜索185,app会自动返回以185开头的号码的联系人,这个道理也是一样的,只不过树的内容不再是单词,而是数字罢了。
有同学问,貌似通讯录app不只可以搜索号码吧,应该照理来说搜索名字也是可以,比如根据姓来搜索。
这个答案很简单,再根据名字做另外一个字典树不就行了。
3.字典树的代码。
这里我用一个Leetcode的题目作为参考,代码是我自己实现的。
Leetcode 字典树
/**
*
* 实现字典树,诀窍就是用什么数据结构保存children,个人偏向用hashmap,因为用数组写起来也麻烦而且会浪费多余的空间。26个字符不一定全都用得到。
*
*/
class TrieNode {
// Initialize your data structure here.
char c;
HashMap<Character, TrieNode> children = new HashMap<Character, TrieNode>();
boolean hasWord;
public TrieNode() {
}
public TrieNode(char c) {
this.c = c;
}
}
public class Trie {
private TrieNode root;
public Trie() {
root = new TrieNode();
}
// Inserts a word into the trie.
public void insert(String word) {
TrieNode cur = root;
//curChildren 对应我们讲的当前插入节点,所有要插入的节点都要放在当前插入节点的子节点里面
HashMap<Character, TrieNode> curChildren = root.children;
char[] wordArray = word.toCharArray();
//循环遍历这次要插入的单词,从第一个字母开始
for (int i = 0; i < wordArray.length; i++) {
char wc = wordArray[i];
//如果当前插入节点有这个字符对应的子节点的话,直接把该子节点变成当前插入节点
if (curChildren.containsKey(wc)) {
cur = curChildren.get(wc);
} else {
//如果没有的话,创建一个。
TrieNode newNode = new TrieNode(wc);
curChildren.put(wc, newNode);
cur = newNode;
}
curChildren = cur.children;
//如果该节点是插入单词的最后一个字符,打一个tag,表面这是一个单词的结尾、
if (i == wordArray.length - 1) {
cur.hasWord = true;
}
}
}
// Returns if the word is in the trie.
//有时候虽然该单词作为前缀,存在于字典树中,但是却没有这个单词。比如我搜索
//TE。这个前缀存在,但是并没有这个单词,E字母对应的节点没有tag
public boolean search(String word) {
if (searchWordNodePos(word) == null) {
return false;
} else if (searchWordNodePos(word).hasWord)
return true;
else
return false;
}
// Returns if there is any word in the trie
// that starts with the given prefix.
public boolean startsWith(String prefix) {
if (searchWordNodePos(prefix) == null) {
return false;
} else
return true;
}
//搜索制定单词在字典树中的最后一个字符对应的节点。这个方法是搜索的关键
public TrieNode searchWordNodePos(String s) {
TrieNode cur = root;
char[] sArray = s.toCharArray();
for (int i = 0; i < sArray.length; i++) {
char c = sArray[i];
if (cur.children.containsKey(c)) {
cur = cur.children.get(c);
} else {
return null;
}
}
return cur;
}
}
这部分是简单的搜索和生成字典树,但是并没有实现如何返回字符串。其实返回字符串就是暴力搜索的一个过程,把最后一个节点一下的所有子节点组合起来。这里可以使用我们之前讲到的深度优先的方法(其实就相当于找一个树的所有path的过程,参考Leetcode 257. Binary Tree Paths))。
感兴趣的同学可以先自己实现一下。
这里最后贴上我的实现
public ArrayList<String> getAutoCompletionStrings(String preflix){
TrieNode lastNode = searchWordNodePos(preflix);
if( lastNode == null ){
return new ArrayList<String>();
}
else{
ArrayList<String> list = new ArrayList<String>();
trieHelper(list,"",lastNode);
return list;
}
}
private void trieHelper(ArrayList<String> result, String current, TrieNode node) {
if (node != null && node.hasWord) {
result.add(current);
} else if(node != null){
Set<Entry<Character,TrieNode>> set = node.children.entrySet();
for( Entry<Character,TrieNode> entry : set ){
trieHelper(result, current+entry.getValue().c , entry.getValue());
}
}
return;
}
