

共享预期修改
一个线程能够共享它的预期修改来替代拷贝和修改内存中的整个数据结构.一个线程需要进行如下几个操作来实现对一个共享数据的预期修改:
- 检查是否有其他线程已经提交一个预期修改到数据结构了
- 如果其他线程还没有提交一个预期修改,那就创建一个预期修改(通常是一个对象)并提交它到数据结构(通过一个cas操作).
- 对共享数据结构执行预期修改.
- 移除预期修改的引用来发送信号给其他线程通知它们预期修改已经被执行了.
如你所见,第二个操作提交一个预期修改会阻塞其他线程.因为第二个操作实际上等同于作用在共享数据结构上的锁.如果一个线程成功提交一个预期修改,那么其他线程将无法提交预期修改,直到上一个提交的预期修改被执行为止.
如果一个线程提交一个预期修改后因为执行其他任务而发生阻塞,那么共享数据结构等同于锁死.共享数据结构并不会直接阻塞其他线程来使用它.其他线程能够检测到无法提交预期修改然后再决定做些什么.很明显,我们需要解决这种情况.
可完善的预期修改
为了解决提交一个预期修改会锁住共享数据结构的问题,一个提交的预期修改对象需要包含足够的信息以让其他线程可以继续完成这些修改.这样,当线程提交一个预期修改后无法完成它时,其他线程可以通过它自己的方式来完成这次修改,同时让共享数据结构能继续被其他线程使用.
下图描述了上文给出的非阻塞算法设想:
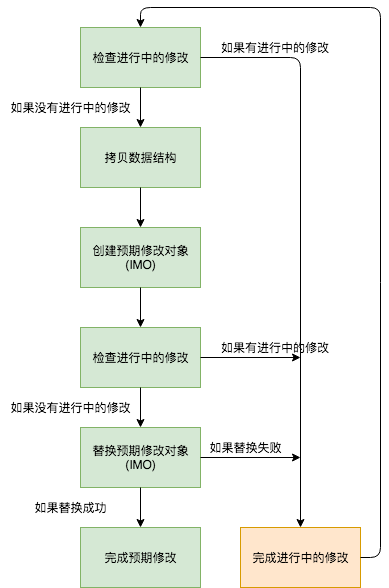
修改必须通过一到多次cas操作来进行.因此,如果有两个线程同时尝试完成预期修改,只会有一个线程能够成功完成.
ABA问题
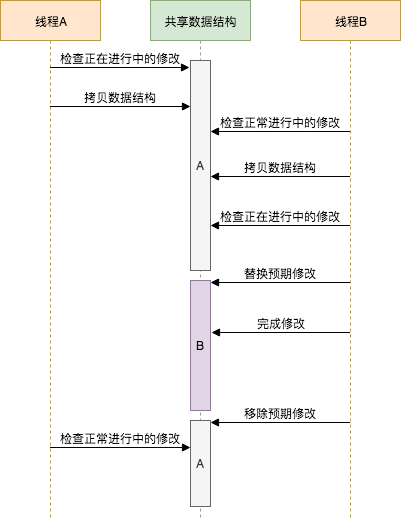
上文描述的算法中会遇到ABA问题.ABA问题是指一个变量从A更改到B,再从B被更改到A的时候,其他线程无法检测到变量实际上已经被修改过了.
如果一个线程A先检查是否有正在进行的更改,然后拷贝数据再然后就被线程调度器挂起了,此时线程B在同一时间访问共享数据结构.此时如果线程B对共享数据执行了一个完整的修改,然后移除预期修改对象的引用,那么对于线程A来说,它会误以为自从拷贝数据结构后预期修改并没有被替换过.然而,预期修改的的确确已经被替换过了.当线程A基于过期的数据结构副本进行修改时,实际上内存中的数据结构已经被线程B的修改替换了.
下图描述了上文讨论的ABA问题的场景:
ABA解决方案
一个通用的解决方案,不单单只是替换掉预期修改对象的指针,同时需要更新一个计数器,且替换预期修改对象指针和更新计数器需要在一个cas操作中完成.这在C和C++的指针中是可行的.因此,即使当前预期修改对象的指针被设置为"没有进行中的预期修改"的状态,仍然会有一个计数器来记录预期修改被更新的次数,以保障更新对其他线程可见.
在Java中不能合并一个引用和计数器到一个变量中.但Java中提供了一个AtomicStampedReference对象用于完成在一个cas操作中同时替换引用和一个标记.
一个非阻塞算法的模版
下面提供了一个代码模版,这个模版提供了一个实现非阻塞算法的思路.这个模版基于上文给出的思路实现.
需要注意的是: 这份模版的作者并不是一个专业非阻塞算法工程师,模版中可能会有几处错误.所以告诫我们千万不要基于这个模版去实现自己的非阻塞算法.这个模版只是示例了非阻塞算法的实现代码的思路.如果你需要实现一个非阻塞算法,那么你需要研读其他更专业的书籍.需要了解一个非阻塞算法是如何实现和工作的,以及如何在实践中编码实现它.(如作者所说,他只是提供了一个思路,笔者在学习完这篇博文后总觉得作者提供非阻塞算法思路并不完整,所以当作入门资料是可以,但要真正掌握非阻塞算法还有很长的路要走.)
import java.util.concurrent.atomic.AtomicBoolean;
import java.util.concurrent.atomic.AtomicStampedReference;
public class NonblockingTemplate {
public static class IntendedModification {
public AtomicBoolean completed =
new AtomicBoolean(false);
}
private AtomicStampedReference<IntendedModification> ongoingMod = new AtomicStampedReference<IntendedModification>(null, 0);
//declare the state of the data structure here.
public void modify() {
while(!attemptModifyASR());
}
public boolean attemptModifyASR(){
boolean modified = false;
IntendedModification currentlyOngoingMod = ongoingMod.getReference();
int stamp = ongoingMod.getStamp();
if(currentlyOngoingMod == null){
//copy data structure state - for use
//in intended modification
//prepare intended modification
IntendedModification newMod = new IntendedModification();
boolean modSubmitted = ongoingMod.compareAndSet(null, newMod, stamp, stamp + 1);
if(modSubmitted){
//complete modification via a series of compare-and-swap operations.
//note: other threads may assist in completing the compare-and-swap
// operations, so some CAS may fail
modified = true;
}
} else {
//attempt to complete ongoing modification, so the data structure is freed up
//to allow access from this thread.
modified = false;
}
return modified;
}
}
非阻塞算法非常难实现
非阻塞算法很难被正确的设计和实现.在尝试实现你自己的非阻塞算法前,不妨查看一下有没有人已经实现过了.
Java中已经实现了一小部分非阻塞算法(例如ConcurrentLinkedQueue)且在未来会有更多的非阻塞算法实现加入到Java版本中.
除了Java中内建的一些非阻塞算法实现外,还有一些开源的数据结构可选.例如,LMAX Disrupter(一个类似队列的数据结构)和由Cliff Click实现的非阻塞版本的HashMap.
非阻塞算法带来的好处
对比阻塞算法,非阻塞算法能够给我们带来诸多好处.以下列出详细的说明:
可选的
非阻塞算法带来的第一个好处是: 线程的请求操作被拒绝时可以选择做些什么而不是直接被阻塞掉.有时候线程的请求操作被拒绝后确实不知道应该做什么.这个时候可以选择阻塞或是挂起来让出CPU运行时间片去做其他任务.但这至少给予了请求线程一次选择的机会.
在单CPU的系统上,当线程的请求操作无法被执行时将会被挂起以腾出CPU运行时间片来做其他事情.但是,即使在单CPU的系统上,阻塞算法仍然会带来死锁,饥饿和其他并发问题.
没有死锁
第二个好处是: 一个线程的挂起不会导致其他线程的挂起.这意味着不会有死锁发生.两个线程不会互相等待对方释放自己所需要的锁.线程的请求操作不能被执行时不会发生阻塞,因此它们不需要阻塞以相互等待对方执行完成.非阻塞算法虽然不会发生死锁,但会发生活锁,两个线程都在尝试执行操作,但一直被告知这些操作不能执行(因为其他线程正在操作的过程中, 理论上是有可能发生的).
没有线程被挂起
挂起和恢复一个线程的性能消耗是十分昂贵的.即使在操作系统和线程工具已经非常高效的情况下,挂起和恢复线程对性能的消耗已经很小了.但是我们仍然需要记住挂起和恢复一个线程是一笔不小的性能消耗(能避免则避免).
当一个线程被阻塞挂起时,需要消耗而外的性能来恢复它们.而在非阻塞算法中,线程不会挂起,这些性能消耗就不会发生.这意味着CPU有更多的运行时间片来执行真正的业务逻辑而不是线程的上下文切换.
在多线程系统中,阻塞算法会对程序的执行效率产生严重的影响.在CPU A上运行的线程可能会被阻塞以等待CPU B上运行的线程.这会降低应用程序的并发性.即使让CPU A切换另外一个线程来执行,线程间的上下文切换仍然是十分昂贵的.越少线程被挂起越好.
降低线程的延迟
延迟在这里是指一个线程发起请求操作到真正被执行的所经过的时间.线程在非阻塞算法中不会被挂起,因此它们没有昂贵的恢复成本.这意味着当一个线程的请求操作能够被执行时,线程可以快速响应从而最大程度的减少它们的响应延迟.
非阻塞算法通常可以在请求操作真正能够被执行时通过繁忙等待的方式来取得最小的响应延迟.当然,如果一个线程在非阻塞数据结构上的竞争情况比较激烈的话,那么CPU会花费大量的运行时间片在繁忙等待上.所以我们需要谨记,多个线程在数据结构上竞争情况比较激烈的情况下,非阻塞算法就显得不是那么合适了.然而,比较常见的做法是重构我们的应用,让线程尽量少的争夺内存中的数据结构.
该系列博文为笔者复习基础所著译文或理解后的产物,复习原文来自Jakob Jenkov所著Java Concurrency and Multithreading Tutorial
