

一旦使用 MySQL 的复制功能,就很大可能会碰到主备切换的情况。也许是为了迭代升级服务器,或者是主库出现问题时,将一台备库转换成主库,或者只是希望重新分配容量。不过出于什么原因,都需要将新主库的信息告诉其它备库。
对于主备切换,如果是计划内的操作,较为容易(至少比紧急情况下容易)。只需在备库简单的使用 CHANGE MASTER TO 命令,并指定合适的值即可。而且大多数的值是可选的,只要指定需要改变的配置项接口。
备库将抛弃之前的配置和中继日志,并从新的主库开始复制。同时,新的参数会被更新到 master.info 文件中,这样就算重启,备库配置信息也不会丢失。
整个过程中最难的是获取新主库上合适的二进制日志位置。这样备库才可以从老主库相同的逻辑位置开始复制。
把备库提升为主库要较为麻烦,我们把备库提升主库分为计划内切换和计划外切换两种场景。
1 计划内切换
备库提升为主库,简单来说,有以下步骤:
- 停止向老主库写入。
- 让备库追赶上主库(可选,可以简化后续的步骤)。
- 将一台备库配置为新主库。
- 将备库和写操作指向新主库,然后开启主库写入。
但上面的过程中还因此着很多细节。一些场景可能依赖于复制的拓扑结构。更深入一点,下面是大多数配置需要的步骤:
- 停止当前主库上的所有写操作。如果可以,最好能将所有的客户端程序关闭(除了复制连接)。
- 通过 FLUSH TABLE WITH READ LOCK 命令在主库上停止所有活跃的写入。也可以在主库上设置 read_only 选项。意味着从这一刻起,禁止向老主库做任何写入操作。因为一旦切换的新主库,老主库的写入就意味着数据丢失。要注意的是,即使设置了 read_only 也不会阻止当前已存在的事务继续提交。因此,可以 kill 所有打开的事务,真正的结束所有写入。
- 选择一个备库作为新的主库,并确保它已经完全跟上主库(例如,让它执行完所有从主库获得的中继日志)。
- 确保新主库和老主库数据一致。
- 在新主库上执行 STOP SLAVE。
- 在新主库上执行 CHANGE MASTER TO MASTER_HOST='',然后再执行 RESET SLAVE,使其断开与老主库的连接,并丢弃 master.info 里记录的信息(如果连接信息记录在 my.cnf 里,会无法正常工作,因此我们建议不要把复制连接信息写到配置文件里)。
- 执行 SHOW MASTER STATUS 记录新主库的二进制日志坐标。
- 确保其它备库已经追赶上老主库。
- 关闭老主库。
- 将客户端连接到新主库。
- 在每台备库上执行 CHANGE MASTER TO 语句,使用之前获得的二进制日志坐标,指向新的主库。
2 计划外切换
当主库崩溃时,需要将一台备库提升为主库。这个过程就比较麻烦。如果只有一台备库,可以直接使用这台备库。但如果有超过一台的备库,就需要做一些额外的工作。
另外,还有潜在的丢失复制事件的问题。可能有主库上已发生的修改还没有更新到它任何一台备库上的情况。甚至可能一条语句在主库上执行了回滚,但在备库上没有回滚,这样备库可能就超过主库的逻辑复制位置。如果能在某一点恢复主库的数据,也许就可以取得丢失语句,并手动执行他们。
在以下描述中,需要确保在服务器中使用 Master_Log_File 和 Read_Master_Log_Pos 的值。
2.1 主备结构之备库提升
- 确定哪台备库的数据最新。检查每台备库上 SHOW_SLAVE_STATUS 命令的输出,选择其中 Master_Log_File 和 Read_Master_Log_Pos 的值最新的那个。
- 让所有备库执行完所有从老主库崩溃前获得的中继日志。
- 在新主库上执行 STOP SLAVE。
- 在新主库上执行 CHANGE MASTER TO MASTER_HOST='',然后再执行 RESET SLAVE,使其断开与老主库的连接,并丢弃 master.info 里记录的信息。
- 执行 SHOW MASTER STATUS 记录新主库的二进制日志坐标。
- 比较每台备库和新主库上的 Master_Log_File 和 Read_Master_Log_Pos 的值。
- 将客户端连接到新主库。
- 在每台备库上执行 CHANGE MASTER TO 语句,使用之前获得的二进制日志坐标,指向新的主库。
如果已经在所有备库上开启了 log_bin 和 log_slave_updates,就可以将所有备库恢复到一个一致的时间点,如果没有开启这两个选项,则很难做到这一点。
上面过程中比较重要的一点是确定日志位置。接下来,我们就来看看如何却。
3 确定日志位置
如果有备库和新主库的位置不相同,则需要找到该备库最后一条执行的事件在新主库的二进制日志中对应的位置,然后再执行 CHANGE MASTER TO。可以通过 mysqlbinlog 工具来找到备库执行的最后一条查询,然后再主库上找到同样的查询,进行简单的计算即可得到。
为了便于描述,假设每个日志事件都有一个自增数字 ID。新主库在老主库崩溃时获得了编号为 100 的事件,另外两条备库:R2 和 R3。R2 已结获取了 99 号事件,R3 获取了 98 号事件。
如果把 R2 和 R3 都指向新主库的同一个二进制日志位置,它们将从 101 号事件开始复制,从而导致数据不同步。但只要新主库的二进制日志已结通过 log_slave_updates 打开,就可以在新主库的二进制日志中找到 99 号 和 100 号事件,从而将备库恢复到一致的状态。
由于服务器重启,不同的配置,日志轮转或者 FLUSH LOGS 命令,同一个事件在不同的服务器上可能有不同的偏移量。我们可以通过 mysqlbinlog 从二进制日志或中继日志中解析出每台备库上执行的最后一个事件,并还有该命令解析新主库上的二进制文件,找到相同的查询,mysqlbinlog 会打印出该事件的偏移量,在 CHANGE MASTER TO 命令中使用这个值。
更快的方法是把新主库和停止的备库上的字节偏移量相减,它显示了字节位置的差异。然后把这个值和新主库当前二进制日志的位置相减,就可以得到期望的查询位置。
一起来看个栗子。
假设 s1 是 s2 和 s3 的主库。其中 s1 已经崩溃。根据 SHOW SLAVE STATUS 获得 Master_Log_File 和 Read_Master_Log_Pos 的值,s2 已结执行完了 s1 上所有的二进制日志,但 s3 还没有。如图 1:
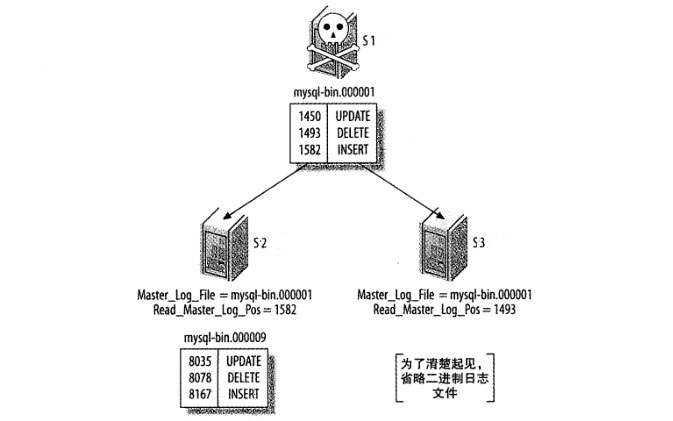
我们可以肯定 s2 已经执行完了主库上的所有二进制日志,因为 Master_log_File 和 Read_Master_Log_Pos 的值和 s1 上最后的日志位置相吻合。因此,我们可以将 s2 提升为新主库,并将 s3 设置为 s2 的备库。
应该在 s3 上为需要执行的 CHANGE MASTER TO 语句赋予什么参数呢?这里需要做一点计算。
s3 在偏移量 1493 处停止,比 s2 执行的最后一条语句的偏移量 1582 要小 89 字节。
s2 正在向偏移量为 8167 的二进制日志写入,因此,理论上我们应该将 s3 指向 s2 日志的偏移量为 8167-89=8078 的位置。
最后在 s2 日志中的 8078 位置,确定该位置上是否是正确的日志事件。
如果验证没问题,可以通过下面命令将 s3 切换为 s2 的备库:
CHANGE MASTER TO MASTER_HOST="s2 host", MASTER_LOG_FILE="mysql-bin.000009", MASTER_LOG_POS=8078;
如果服务器在它崩溃时已经执行完成并记录了一个事件 a。因为 s2 仅仅读取并执行到了 1582,因此可能会失去事件 a。但是如果老主库的磁盘没有损坏,仍然可以通过 mysqlbinlog 或者从日志服务器的二进制日志中找到丢失的事件。
总结
- 备库提升区分计划内和计划外场景。
- 备库提升,找到新主库准确的二进制日志位置是关键。
