近期,来自 Facebook AI、新加坡国立大学、奇虎 360 的研究人员联合提出了一种新的卷积操作 (OctConv),用于替代现有的通用卷积。这款新卷积不仅占用更少的内存和计算,还有助于提高性能。
卷积神经网络(CNN)在很多计算机视觉任务中都取得了卓越的成就,然而高准确率的背后,却是很高的冗余度和不可忽视的计算开销。
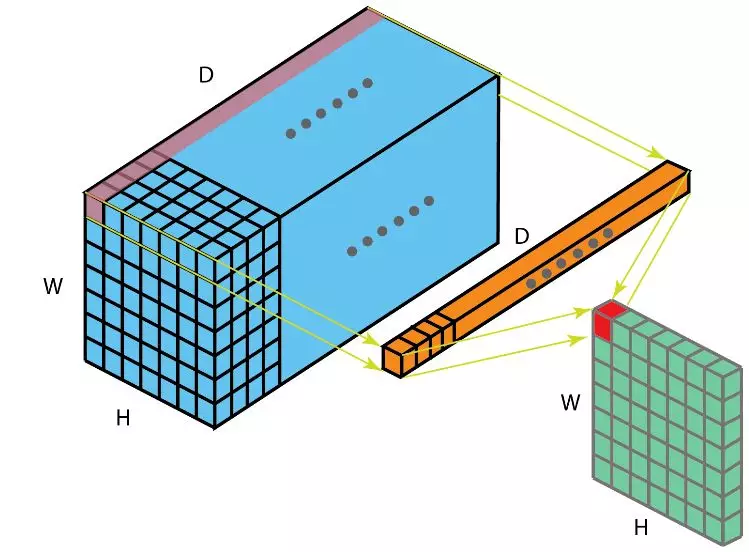
对于一个卷积操作而言(图 1),每个位置都是由一个 D 维特征向量 表示,而特征提取,则是通过滑动卷积,对每个位置分别处理得到对应的特征。
但是,这种为每个位置都分别存储一份特征表达,并分别一一处理的策略明显是不合理的。因为,对于图像而言,相邻位置往往描述的是同一个语义,从而共享一部分特征。

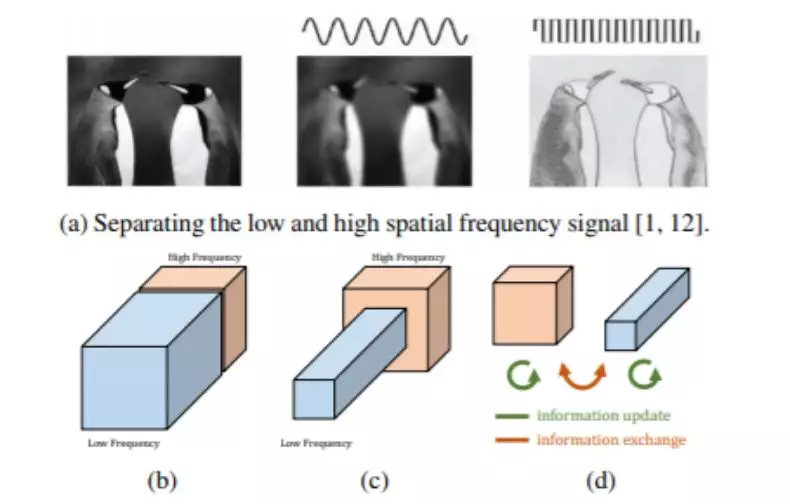
与此同时,CNN 所学习到的卷积核,也并非全是高频卷积核,如 图 2 所示。这意味着,一部分卷积专注于提取「低频特征」,而另一部分则专注于提取「高频特征」。对于低频卷积所对应的特征图而言,我们也许只需要保留它的低频信号即可,没必要存储在高分辨率下的特征图。
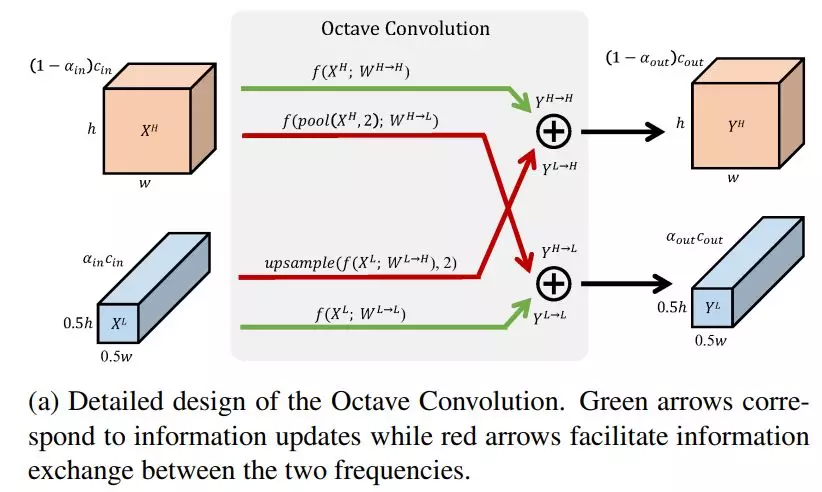
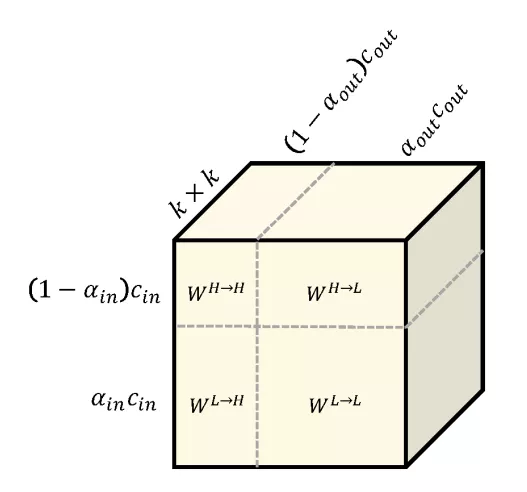
如图 3 所示,本文提出将 特征图分为两组:低频特征(蓝色)和 高频特征(橙红),并将空间上变化较为缓慢的「低频特征图」存储在低分辨率的张量中,共享相邻位置间的特征。而本文所提出的 OctConv 则是一种可以直接作用在该特征表达下的卷积操作。它包含每个频率自身状态的更新(绿色箭头),以及频率间的信息交互(红色箭头)。
Octave Convolution(OctConv)的命名应该是受到了 SIFT 特征的启发。而 Octave 是八个音阶的意思,音乐里降 8 个音阶代表频率减半。本文通过一个 Octave 将 高频 和 低频 特征隔离到不同的组中,并将低频的分辨率减半。
研究人员指出 OctConv 可以直接用于替代现有卷积,并且即插即用,无需调参,也不影响 CNN 的网络结构以及模型大小。由于 OctConv 专注于降低 CNN 空间维度上的冗余,因此它与现有专注于网络拓补结构设计,以及减少网络特征容易的方法是正交和互补的。
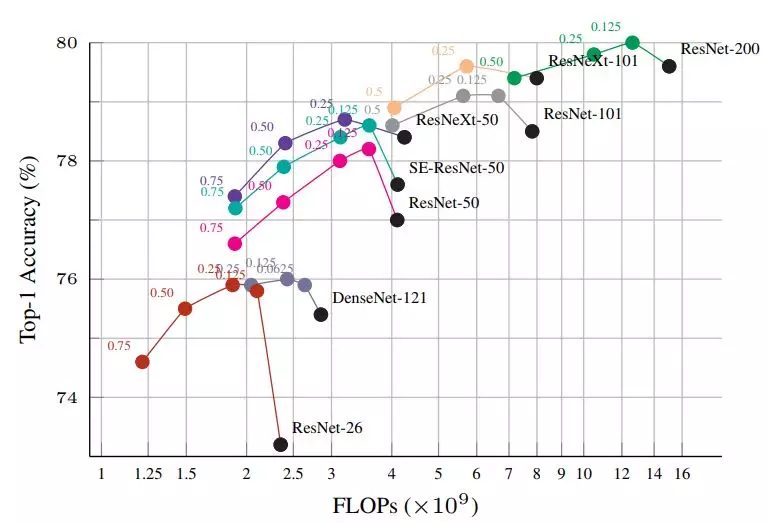
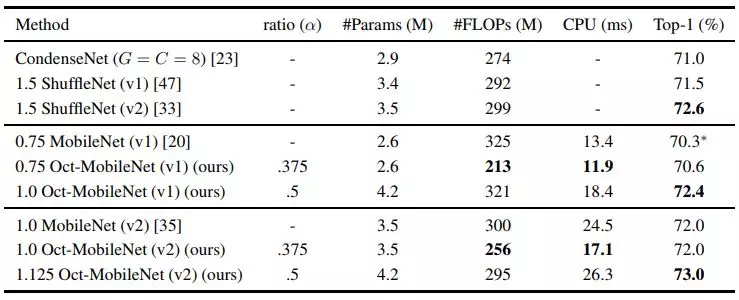
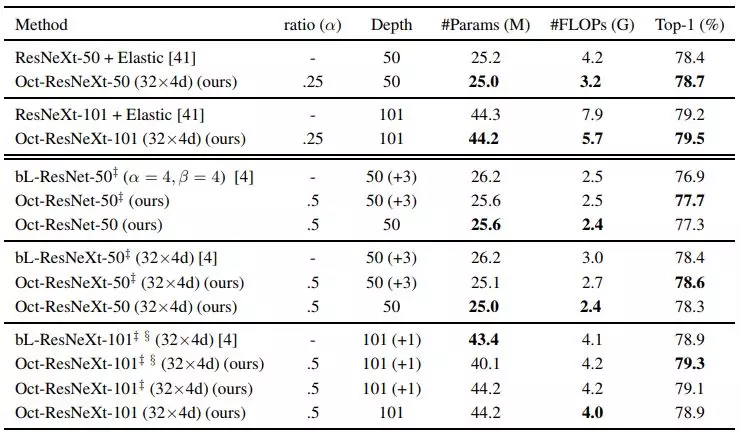
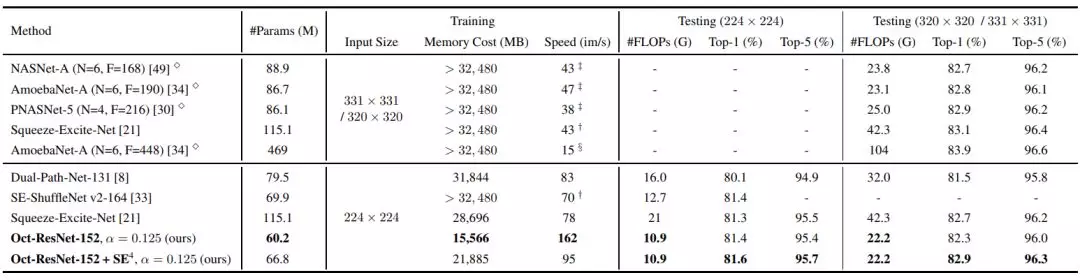
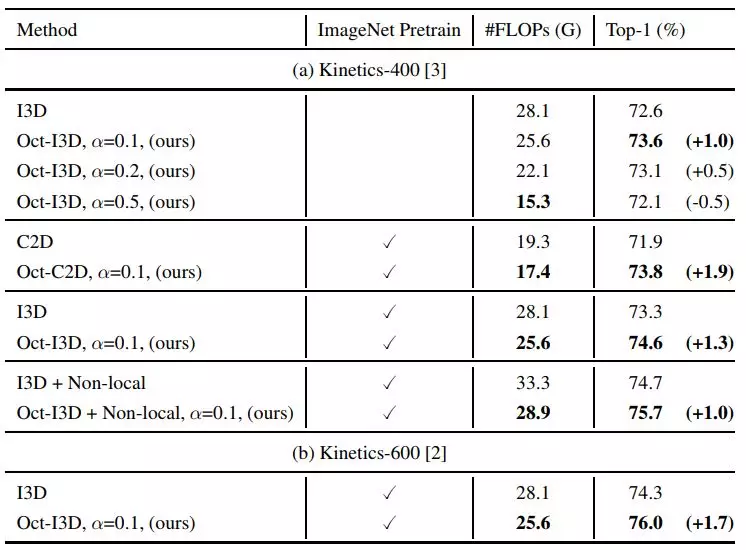
实验表明,用 OctConv 替代普通卷积可以稳定提高现有的 2D CNN 网络(包括 ResNet、ResNeXt、DenseNet、MobileNet、SE-Net)提高其在 ImageNet 上的图像识别的性能,此外也可以稳定提高 3D CNN 网络(C2D、 I3D)并在 Kinetics(行视频动作识别数据集)上取得了更佳的性能。配备了 OctConv 的 Oct-ResNet-152 甚至可以媲美当前最佳的自动搜索的网络 (NAS, PNAS 等)。
论文:Drop an Octave: Reducing Spatial Redundancy in Convolutional Neural Networks with Octave Convolution

第三方复现结果:github.com/terrychenis…
在自然图像中,信息以不同的频率传输,其中较高频率通常以细节进行编码,而较低频率通常以总体结构进行编码。同样地,一个卷积层的输出特征图也可视为不同频率的信息混合。
在本文中,研究人员提出基于频率对混合特征图进行分解,并设计了一种新的 Octave 卷积(OctConv)操作,以存储和处理较低空间分辨率下空间变化「较慢」的特征图,从而降低内存和计算成本。
与现有多尺度方法不同,OctConv 是一种单一、通用和即插即用的卷积单元,可以直接代替(普通)卷积,而无需对网络架构进行任何调整。OctConv 与那些用于构建更优拓扑或者减少分组或深度卷积中通道冗余的方法是正交和互补的。
实验表明,通过用 OctConv 替代普通卷积,研究人员可以持续提高图像和视频识别任务的准确率,同时降低内存和计算成本。一个配备有 OctConv 的 ResNet-152 能够以仅仅 22.2 GFLOP 在 ImageNet 上达到 82.9% 的 top-1 分类准确率。
方法
在本节中,研究人员首先介绍了用来降低特征图中空间冗余的特征表示,接着描述了直接作用于该表征的 Octave 卷积(图 4)。研究人员还讨论了实现细节,展示了如何将 OctConv 融入分组和深度卷积架构。
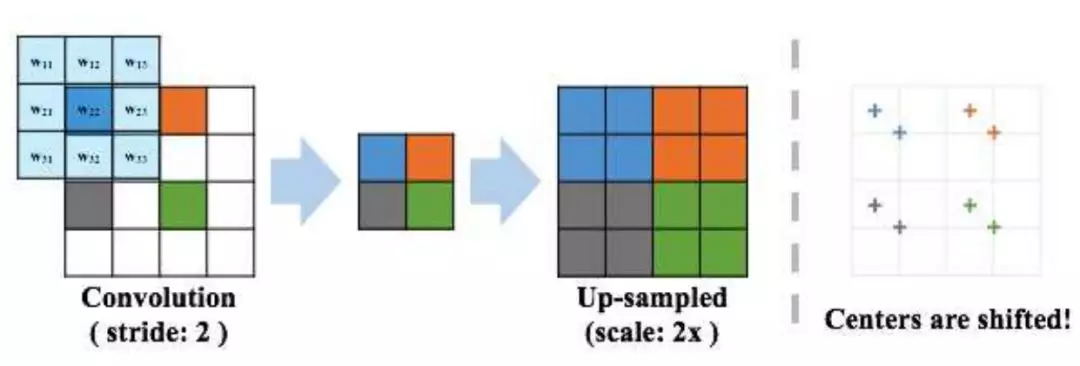
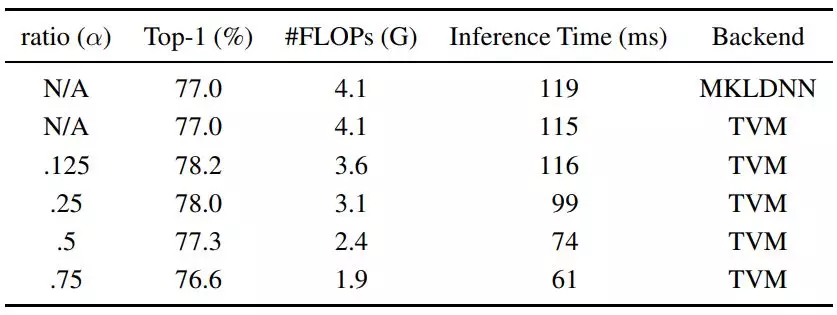
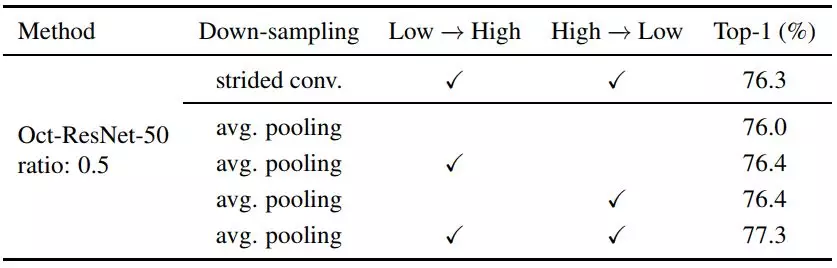
这里,有一点很有意思。研究人员指出,通过卷积降采样会导致特征图无法准确对齐。并推荐使用池化操作来进行降采样。
实验评估
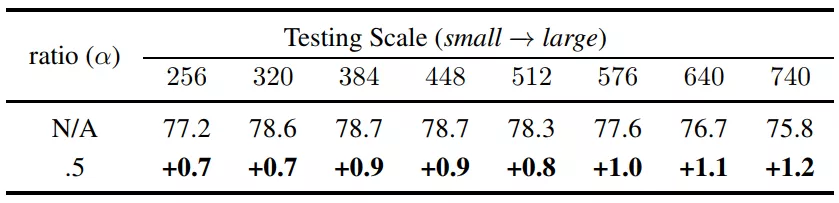
在本节中,研究人员验证了提出的 Octave 卷积对于 2D 和 3D 网络的效能和效率。研究人员首先展示了 ImageNet 上图像分类的控制变量研究,然后将其与当前最优的方法进行了比较。之后,研究人员使用 Kinetics-400 和 Kinetics-600 数据集,展示了提出的 OctConv 也适用于 3D CNN。每一类别 / 块的最佳结果在论文中以粗体字显示。