

17)精益求精:聊聊提高GUI测试稳定性的关键技术
问题:同样的测试用例在同样的环境上,时而测试通过,时而测试失败;
造成GUI测试不稳定的常见五种因素:
- 非预计的弹出对话框;
- 页面控件属性的细微变化;
- 被测系统的A/B测试;
- 随机的页面延迟造成控件识别失败;
- 测试数据问题;
非预计的弹出对话框
新增异常场景恢复流程,一旦发现控件无法定位时,就走到该逻辑下,遍历满足的情况,执行相应的操作,缺点就是,不同对话框需要更新到该进程了,存在维护成本;
页面控件属性的细微变化
比如控件ID属性发生变化,也建议新增定位控件逻辑处理:
- 根据脚本里的属性找控件,如果没找到,尝试找控件的文本;
- 文本符合,获取该文本对应的控件属性;
- 判断脚本里的属性跟获取到的属性是否相似,相似则判定一致;
上面的方法只是一种思路,可以根据不同业务特性归总一定适用的方法来在出错时定位控件,提高识别率;
还可以使用xpath,但也一样存在属性被改的情况,只是相对控件元素,概率会少一点;
被测系统的A/B测试
在测试脚本内部对不同的被测版本做分支处理,脚本需要能够区分 A 和 B两个的不同版本,并做出相应的处理;
随机的页面延迟造成控件识别失败
增加重试机制,当操作失败时,自动发起重试;
18)眼前一亮:带你玩转GUI自动化的测试报告
主要是说,好的测试报告,需要有截图及高亮显示操作元素功能;
如果使用selenium,需要扩展selenium原来的操作函数和hook函数实现;
19)真实的战场:如何在大型项目中设计GUI自动化测试策略
- 对那些自定义开发的组件进行完整全面的测试;
- 基于前端模块封装开发业务流程脚本;
- 站在终端的视角以黑盒的方式使用网站的端到端的测试;
- 对各个前端业务模块的页面对象库和业务流程脚本,实施版本化管理机制;
20)与时俱进:浅谈移动应用测试方法与思路
三类移动应用的特点
- web app,移动端的web浏览器,技术栈是传统的HTML、js、css等,优点是跨平台;
- native APP,移动端的原生应用,安卓是apk(Java),ios是ipa(objective-c),能提供比较好的用户体验跟性能,方便操作手机本地资源;
- hybrid APP,介于
web APP和native APP两者之间的一种形态,在原生内嵌webview,通过webview来访问网页,优点是具备跨平台,维护更新,是主流的开发模式;
三类移动应用的测试方法
从业务功能测试的角度看,移动应用的测试用例设计和传统 PC 端的 GUI 自动化测试策略比较类似,只是测试框架不同,数据驱动、页面对象模型和业务流程封装依旧适用;
移动应用专项测试的思路和方法
交叉事件测试
也称场景测试,模拟各种交叉场景,手工测试为主;
兼容性测试
- 不同操作系统的兼容性,比如android和ios;
- 不同分辨率的兼容性;
- 不同机型的兼容性;
- 不同语言的兼容性;
- 不同网络的兼容性;
- 不同操作版本的兼容性;
因为需要大量真实社保,所以使用第三方的云测平台较多;
流量测试
- APP执行业务操作引起的流量;
- APP在后台运行时的消耗流量;
- APP安装后首次启动耗费的流量;
- APP安装包的size;
- APP内下载/升级需要的流量;
借助于Android 和 iOS 自带的工具进行流量统计,也可以利用 tcpdump、Wireshark 和 Fiddler 等网络分析工具;
对于 Android 系统,网络流量信息通常存储在 /proc/net/dev 目录下,也可以直接利用 ADB 工具获取实时的流量信息。另外,推荐一款 Android 的轻量级性能监控小工具 Emmagee,类似于 Windows 系统性能监视器,能够实时显示 App 运行过程中 CPU、内存和流量等信息;
对于 iOS 系统,可以使用 Xcode 自带的性能分析工具集中的 Network Activity,分析具体的流量使用情况;
常见流量优化的方法:
- 压缩图片;
- 优化数据格式,比如使用json;
- 压缩加密;
- 减少api调用次数;
- 回传数据只需要必要数据;
- 缓存机制;
耗电量测试
耗电量一般从三个方面思考:
- APP运行但没有执行业务操作时的耗电量;
- APP运行且密集执行业务操作时的耗电量;
- APP后台运行的耗电量;
检验方法,偏硬件的是耗电仪,软件则如下:
- 安卓adb 命令
adb shell dumpsys battery来获取应用的耗电量信息; - 安卓,Google推出的history batterian工具;
- iOS 通过 Apple 的官方工具
Sysdiagnose来收集耗电量信息,然后,可以进一步通过Instrument工具链中的Energy Diagnostics进行耗电量分析;
弱网络测试
日常生活中,弱网的场景比较多,如地铁、隧道、车库,伴随着就是丢包、延迟、断线的异常场景;
文中作者推荐Augmented Traffic Control,是Facebook的开源移动网络测试工具,详情请点击这里查阅;
而jb日常用的比较多的是fiddler来模拟弱网,感兴趣的点击这里查阅;
边界测试
意思就是找出程序的临界值场景,验证这些临界场景是否正常,常见的就是最大值最小值;
21)移动测试神器:带你玩转Appium
本文主要是介绍了Appium及安装使用,网上也有很多,请自行查阅;
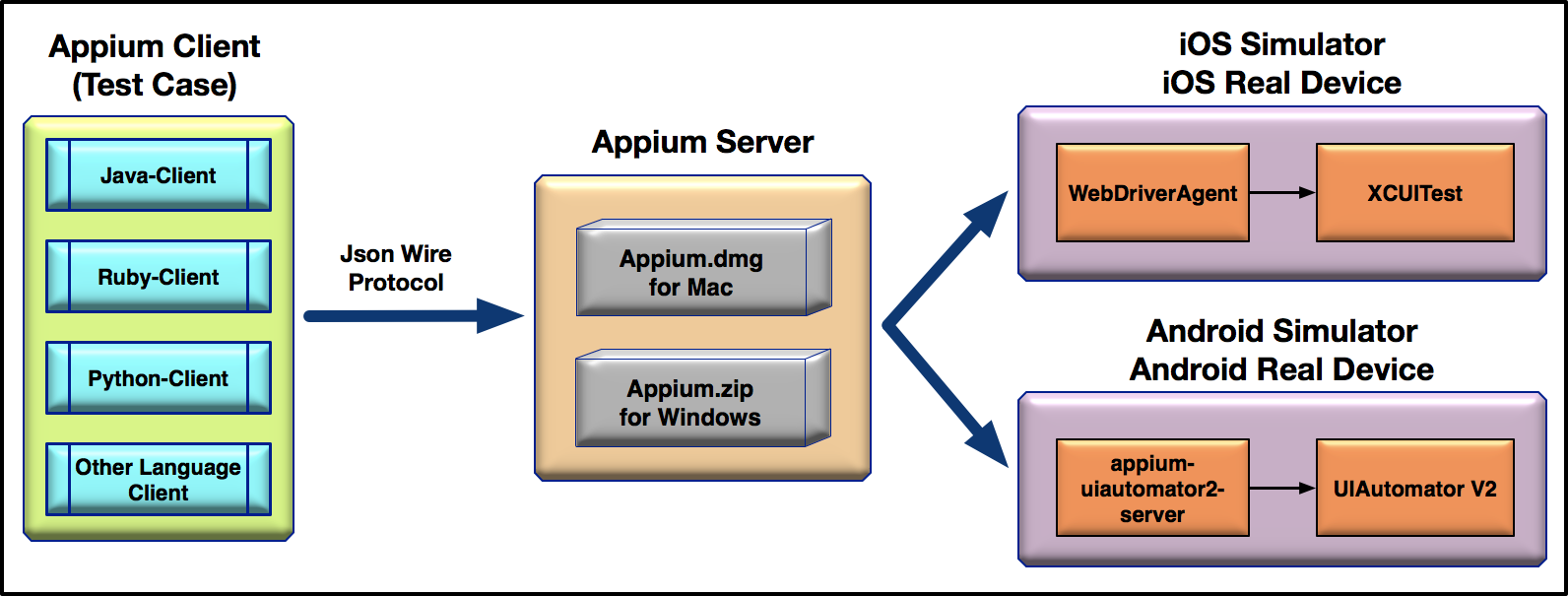
Appium 的内部原理可以总结为:
Appium 属于 C/S 架构,Appium Client 通过多语言支持的第三方库向 Appium Server 发起请求,基于 Node.js 的 Appium Server 会接受 Appium Client 发来的请求,接着和 iOS 或者 Android 平台上的代理工具打交道,代理工具在运行过程中不断接收请求,并根据 WebDriver 协议解析出要执行的操作,最后调用 iOS 或者 Android 平台上的原生测试框架完成测试。
22)从0到1:API测试怎么做?常用API测试工具简介
常用的api测试工具有cURL、postman,还有jmeter跟soapui也算;
cURL
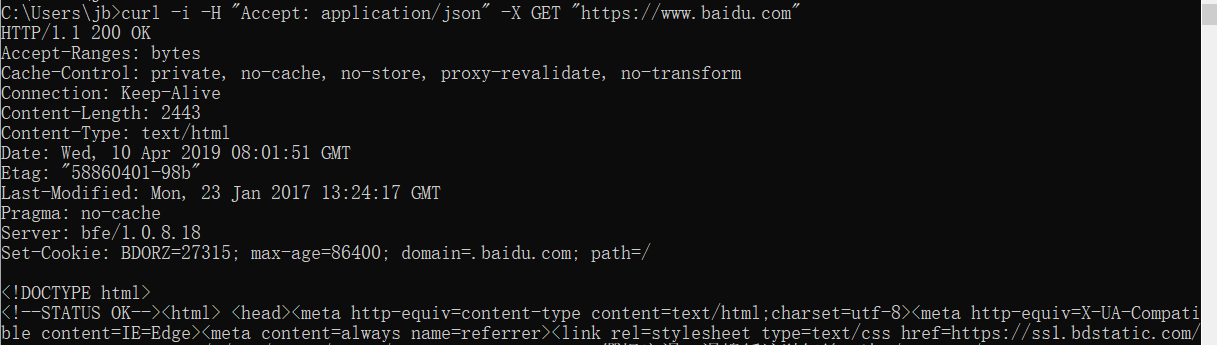
cURL是一款命令行工具,需要安装,然后执行下面的命令发起api调用;
curl -i -H "Accept: application/json" -X GET "https://www.baidu.com"
返回的内容如图:
常见的参数解析:
| 参数 | 含义 |
|---|---|
| -i | 显示response的header信息; |
| -H | 设置request中的header; |
| -X | 执行执行方法,如get、post、Put,不指定-X,则默认使用get; |
| -d | 设置http参数,参数之间用&串接; |
| -b | 需要cookie时,指定cookie文件路径; |
Session 的场景
curl -i -H "sessionid:XXXXXXXXXX" -X GET "http://XXX/api/demoAPI"
Cookie 的场景
使用 cookie,在认证成功后,后端会返回 cookie给前端,前端可以把该 cookie 保存成为文件,当需要再次使用该 cookie 时,再用-b cookie_File的方式在 request 中植入 cookie 即可正常使用;
// 将 cookie 保存为文件
curl -i -X POST -d username=robin -d password=password123 -c ~/cookie.txt "http://XXX/auth"
// 载入 cookie 到 request 中
curl -i -H "Accept:application/json" -X GET -b ~/cookie.txt "http://XXX/api/demoAPI"
Postman
相对于cURL,postman用的比较频繁,官网地址点这里;
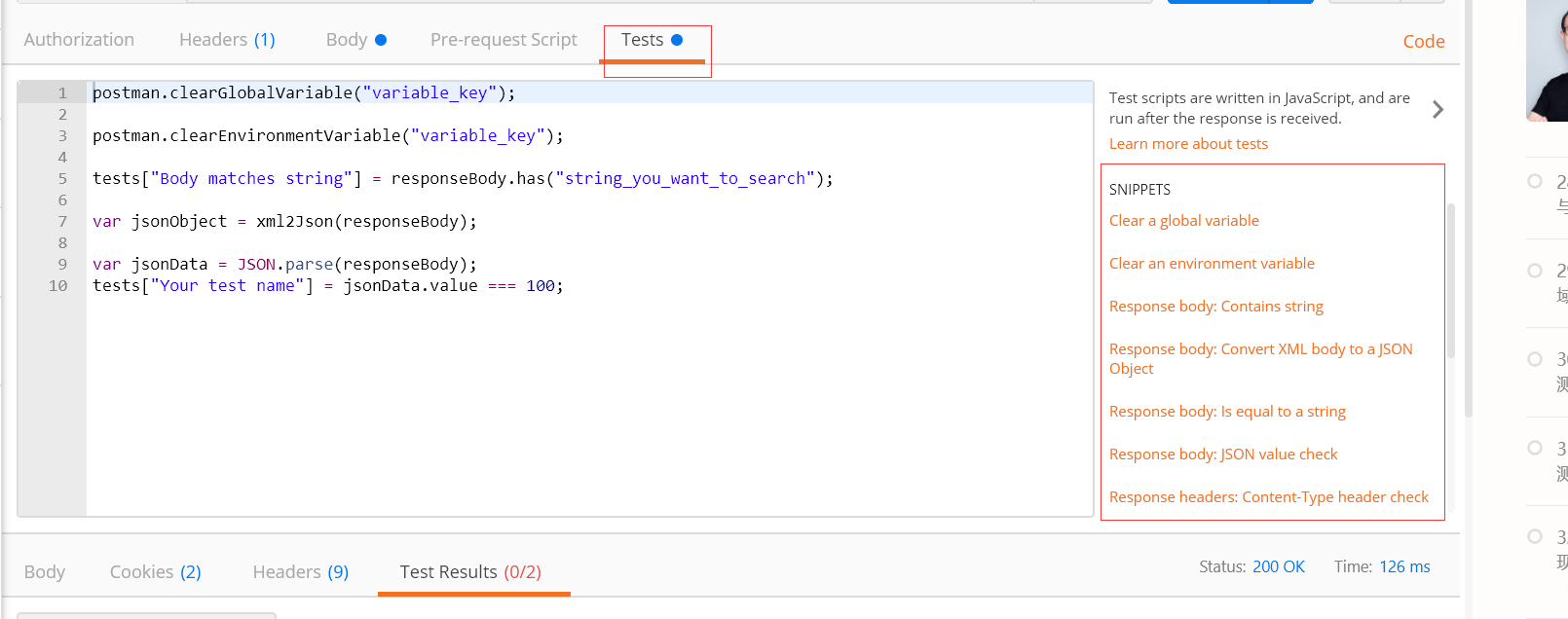
结果验证
点击Test右侧的SNIPPETS,挑选一些需要验证的场景,代码就会自动生成,当然也可以自己写;
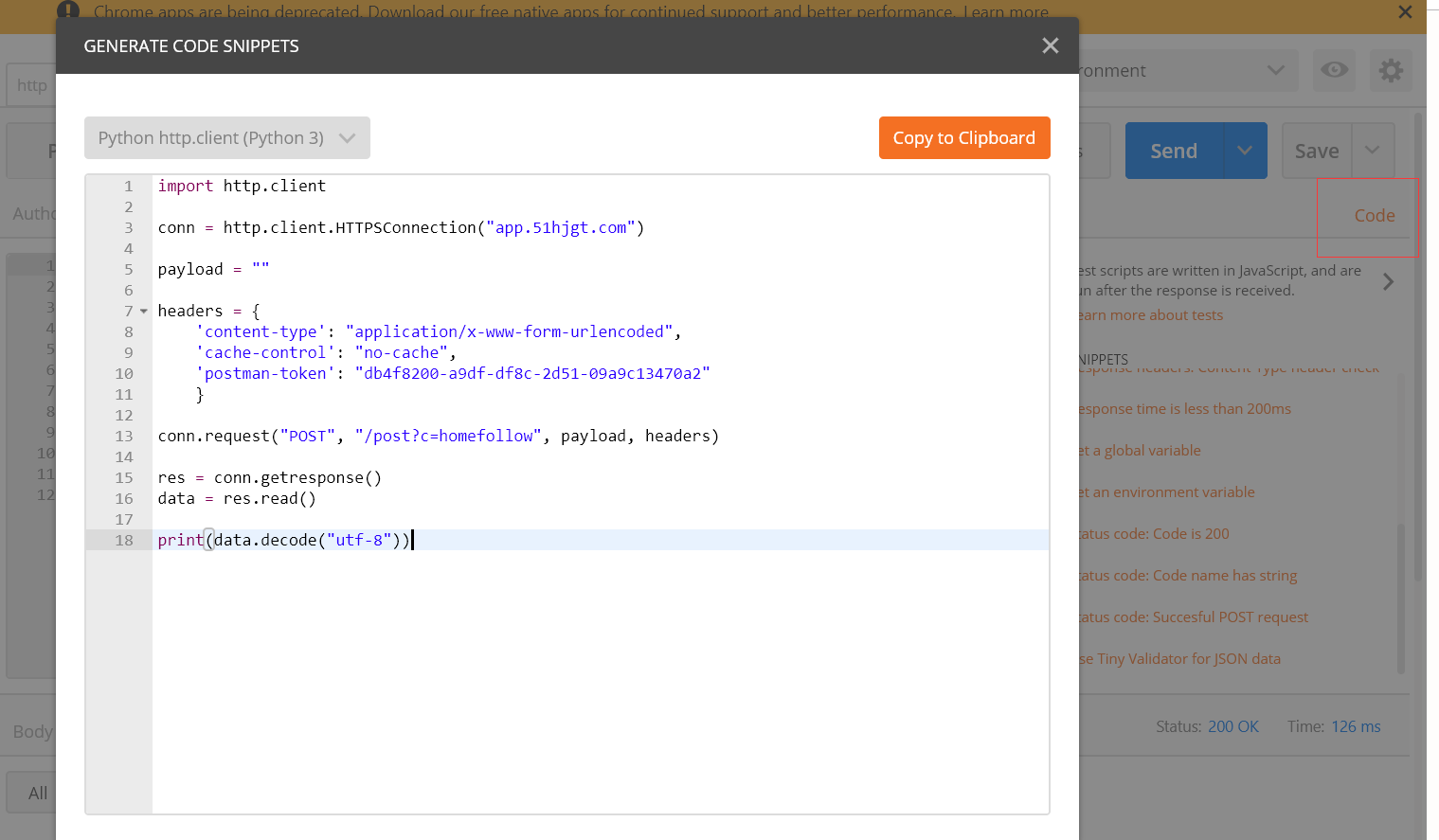
基于postman的测试代码自动生成
点击右侧的code,选择需要的语言,保存即可;
又或者,使用newman工具,直接执行postman的collection;
newman run examples/sample-collection.json;
复杂场景的api测试
多个api调用协助
通过代码将上个 API 调用返回的response中的某个值传递给下一个 API;
api依赖第三方
mock server;
异步api
异步 API 是指,调用后会立即返回,但是实际任务并没有真正完成,而是需要稍后去查询或者回调的API;
- 测试异步调用是否成功,检查返回值和后台工作现成是否被创建即可判断;
- 测试异步调用的业务逻辑处理是否正确,去访问、操作数据库或者消息队列看对应的数据是否被创建或更新,没权限就直接访问日志文件看记录;
23)API自动化测试框架的前世今生
早期的基于 Postman 的 API 测试在面临频繁执行大量测试用例,以及与 CI/CD 流水线整合的问题时,显得心有余而力不足。
为此,基于命令行的 API 测试实践,也就是 Postman+Newman`,具有很好的灵活性,解决了这两个问题。
但是,Postman+Newman 的测试方案,只能适用于单个 API 调用的简单测试场景,对于连续调用多个 API 并涉及到参数传递问题时,这个方案就变得不那么理想和完美了。随后,API 测试就过渡到了基于代码的 API 测试阶段;
respons结果发生变化时自动识别
具体实现的思路是,在 API 测试框架里引入一个内建数据库,推荐采用非关系型数据库(比如 MongoDB),然后用这个数据库记录每次调用的 request 和 response 的组合,当下次发送相同 request 时,API 测试框架就会自动和上次的 response 做差异检测,对于有变化的字段给出告警;
24)微服务模式下API测试要怎么做?
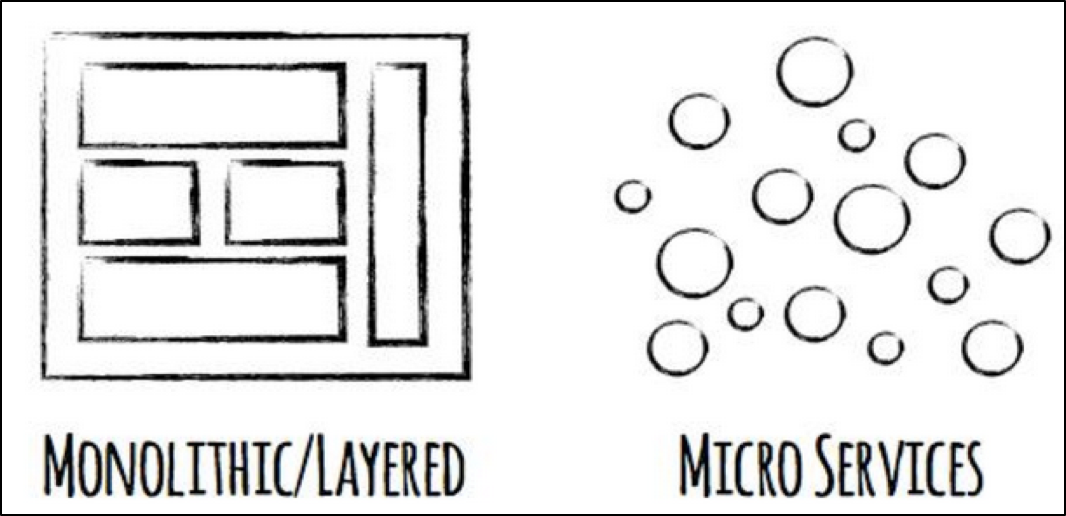
单体架构
单体架构是将所有的业务场景的表示层、业务逻辑层和数据访问层放在同一个工程中,最终经过编译、打包,并部署在服务器上。
缺点:
- 灵活性差,每次都要整包编译;
- 可扩展性差,不能以模块为单位扩展容量;
- 稳定性差,某模块出错会导致整体不可用;
- 可维护性差;
微服务架构
在微服务架构下,一个大型复杂软件系统不再由一个单体组成,而是由一系列相互独立的微服务组成;
测试的挑战
庞大的测试用例数量
消费者契约的 API 测试的核心思想是: 只测试那些真正被实际使用到的 API 调用,如果没有被使用到的,就不去测试;
微服务之间的耦合关系
契约的本质就是 Request 和 Response 的组合,基于契约的 Mock Service 完美地解决了 API 之间相互依赖耦合的问题;
25)掌握代码级测试的基本理念与方法
常见代码错误类型:
- 语法特征错误,编译语法发生错误;
- 边界行为特征错误;
- 经验特征错误,根据过往经验发现代码错误;
- 算法错误,代码完成的功能和之前设定的不一致,会直接影响到业务逻辑;
- 部分算法错误,在一些特定的条件或者输入情况下,算法不能准确完成业务要求实现的功能,这是常见的类型;
代码级测试常用方法:
- 静态方法,顾名思义就是在不实际执行代码的基础上发现代码缺陷的方法,又可以进一步细分为人工静态方法和自动静态方法;
- 动态方法是指,通过实际执行代码发现代码中潜在缺陷的方法,同样可以进一步细分为人工动态方法和自动动态方法。
这四类测试方法的特点,以及可以覆盖的错误类型,可以概括如下:
- 人工静态方法,本质上通过开发人员代码走查、结对编程、同行评审来完成的,理论上可以发现所有的代码错误,但也因为其对“测试人员”的过渡依赖,局限性非常大;
- 自动静态方法,主要的手段是代码静态扫描,可以发现语法特征错误、边界行为特征错误和经验特征错误这三类“有特征”的错误;
- 人工动态方法,就是传统意义上的单元测试,是发现算法错误和部分算法错误的最佳方式;
- 自动动态方法,其实就是自动化的边界测试,主要覆盖边界行为特征错误;
评论里面有提及到,Facebook 开源的静态分析工具 Infer,感兴趣的可以看看;
26)深入浅出之静态测试方法
人工静态方法
- 代码走查,code review,开发人员减产代码;
- 结对编程,一个开发实现代码,另一个审查输入的每一行代码;
- 同行评审,pull到master之前先审核,类似code review;
自动静态方法
常见的工具包括收费的企业级应用,比如Coverity。
其它免费的应用,比如Findbugs(Spotbugs), Java Checker Framework, PREfast, Splint, SPIN, Microsoft SLAM, PMD, Facebook Infer;
自动的特点在于:
- 相比于编译器,可以做到对代码更加严格、个性化的检查;
- 不真正检测代码的逻辑功能,只是站在代码本身的视角,基于规则,尽可能多地去发现代码错误;
能发现很多小问题:
- 使用未初始化的变量;
- 变量在使用前未定义;
- 空指针引用等等;
27)深入浅出之动态测试方法
人工动态方法
也就是单元测试,测试基本用不着,不展开;
自动动态方法
基于代码自动生成边界测试用例并执行来捕捉潜在的异常、崩溃和超时的测试方法;
如何实现边界测试用例的自动生成?
根据被测函数的输入参数生成可能的边界值;
28)解读不同视角的软件性能与性能指标

- 终端用户是软件系统的最终使用者;
终端用户眼中的软件性能
用户在界面上完成一个操作开始,到系统把本次操作的结果以用户能察觉的方式展现出来的全部时间;
- 系统响应时间,细分为应用系统处理时间、数据库处理时间和网络传输时间;
- 前端展示时间,取决于用户端的处理能力;
运维人员眼中的软件性能
软件性能除了包括单个用户的响应时间外,更要关注大量用户并发访问时的负载,以及在负载下的系统健康状态、并发处理能力、当前部署的系统容量、可能的系统瓶颈、系统配置层面的调优、数据库的调优,以及长时间运行稳定性和可扩展性;
开发人员眼中的软件性能
在软件设计开发人员眼中,软件性能通常会包含算法设计、架构设计、性能最佳实践、数据库相关、软件性能的可测试性这五大方面;
- 算法设计
-
- 核心算法的设计与实现是否高效;
-
- 设计上是否采用 buffer 机制以提高性能,降低 I/O;
-
- 是否存在潜在的内存泄露;
-
- 是否存在并发环境下的线程安全问题;
-
- 是否存在不合理的线程同步方式;
-
- 是否存在不合理的资源竞争;
- 架构设计
-
- 站在整体系统的角度,是否可以方便地进行系统容量和性能扩展;
-
- 应用集群、缓存集群、数据库的可扩展性是否经过测试和验证;
- 性能
-
- 代码实现是否遵守开发语言的性能最佳实践;
-
- 关键代码是否在白盒级别进行性能测试;
-
- 是否考虑前端性能的优化;
-
- 必要的时候是否采用数据压缩传输; 对于既要压缩又要加密的场景,是否采用先压缩后加密的顺序;
- 数据库
-
- 数据库表设计是否高效;
-
- 是否引入必要的索引;
-
- SQL 语句的执行计划是否合理;
-
- SQL 语句除了功能是否要考虑性能要求;
-
- 数据库是否需要引入读写分离机制;
-
- 系统冷启动后,缓存大量不命中的时候,数据库承载的压力是否超负荷;
- 软件性能的可测试性
-
- 是否为性能分析(Profiler)提供必要的接口支持;
-
- 是否支持高并发场景下的性能打点;
-
- 是否支持全链路的性能分析。
性能测试人员眼中的软件性能
三个最常用的指标:并发用户数、响应时间,以及系统吞吐量;
并发用户数
并发用户数,包含了业务层面和后端服务器层面的两层含义;
- 业务层面的并发用户数,指的是实际使用系统的用户总数;
- 后端服务器层面的并发用户数,指的是“同时向服务器发送请求的数量”,直接反映了系统实际承载的压力;
获取用户行为模式的方法,主要分为两种:
- 对于已经上线的系统来说,往往采用
系统日志分析法获取用户行为统计和峰值并发量等重要信息; - 而对于未上线的全新系统来说,通常的做法是参考行业中类似系统的统计信息来建模,然后分析;
响应时间
响应时间反映了完成某个操作所需要的时间,其标准定义是“应用系统从请求发出开始,到客户端接收到最后一个字节数据所消耗的时间”,是用户视角软件性能的主要体现;
响应时间,可以分为前端展现时间和系统响应时间:
- 前端时间,又称呈现时间,取决于客户端收到服务器返回的数据后渲染页面所消耗的时间;
- 系统响应时间,可以划分为web服务器时间、应用服务器时间、数据库时间,以及各服务器间通信的网络时间;
系统吞吐量
是直接体现软件系统负载承受能力的指标;
所有对吞吐量的讨论都必须以“单位时间”作为基本前提;
以不同方式表达的吞吐量可以说明不同层次的问题:
Bytes/Second和Pages/Second表示的吞吐量,主要受网络设置、服务器架构、应用服务器制约,考察http或者业务层面;Requests/Second表示的吞吐量,主要受应用服务器和应用本身实现的制约,考察系统层面或网络层面;
一个优秀的性能测试工程师,一般需要具有以下技能:
- 性能需求的总结和抽象能力;
- 根据性能测试目标,精准的性能测试场景设计和计算能力;
- 性能测试场景和性能测试脚本的开发和执行能力;
- 测试性能报告的分析解读能力;性能瓶颈的快速排查和定位能力; - 性能测试数据的设计和实现能力;
- 面对互联网产品,全链路压测的设计与执行能力,能够和系统架构师一起处理流量标记、影子数据库等的技术设计能力;
- 深入理解性能测试工具的内部实现原理,当性能测试工具有限制时,可以进行扩展二次开发;
- 极其宽广的知识面,既要有“面”的知识,比如系统架构、存储架构、网络架构等全局的知识,还要有大量“点”的知识积累,比如数据库 SQL 语句的执行计划调优、JVM 垃圾回收(GC)机制、多线程常见问题等等;
小结
- 终端用户希望自己的业务操作越快越好;
- 系统运维人员追求系统整体的容量和稳定;
- 开发人员以“性能工程”的视角关注实现过程的性能;
- 性能测试人员需要全盘考量、各个击破;
最常用的指标:并发用户数,响应时间,系统吞吐量:
- 并发用户数包含不同层面的含义,既可以指实际的并发用户数,也可以指服务器端的并发数量;
- 响应时间也包含两层含义,技术层面的标准定义和基于用户主观感受时间的定义;
- 系统吞吐量是最能直接体现软件系统承受负载能力的指标,但也必须和其他指标一起使用才能更好地说明问题;
29)性能测试的基本方法与应用领域
并发用户数、响应时间、系统吞吐量之间的关系
当系统并发用户数较少时,系统的吞吐量也低,系统处于空闲状态,这个阶段称为 “空闲区间”;
当系统整体负载并不是很大时,随着系统并发用户数的增长,系统的吞吐量也会随之呈线性增长,称为 “线性增长区间”;
随着系统并发用户数的进一步增长,系统的处理能力逐渐趋于饱和,因此每个用户的响应时间会逐渐变长。相应地,系统的整体吞吐量并不会随着并发用户数的增长而继续呈线性增长,称为系统的“拐点”;
随着系统并发用户数的增长,系统处理能力达到过饱和状态。此时,如果继续增加并发用户数,最终所有用户的响应时间会变得无限长;相应地,系统的整体吞吐量会降为零,系统处于被压垮的状态,称为“过饱和区间”;
后端性能测试的测试负载,一般只会把它设计在线性增长区间内;而压力测试的测试负载,则会将它设计在系统拐点上下,甚至是过饱和区间;
常用的七种性能测试方法
后端性能测试
也叫服务端性能测试,是通过性能测试工具模拟大量的并发用户请求,然后获取系统性能的各项指标,并且验证各项指标是否符合预期的性能需求的测试手段;
这里的性能指标,除了包括并发用户数、响应时间和系统吞吐量外,还应该包括各类资源的使用率,比如系统级别的 CPU 占用率、内存使用率、磁盘 I/O 和网络 I/O 等,再比如应用级别以及 JVM 级别的各类资源使用率指标等;
后端性能测试的场景设计主要包括以下两种方式:
- 基于性能需求目标的测试验证;
- 探索系统的容量,并验证系统容量的可扩展性;
前端性能测试
通常来讲,前端性能关注的是浏览器端的页面渲染时间、资源加载顺序、请求数量、前端缓存使用情况、资源压缩等内容,希望借此找到页面加载过程中比较耗时的操作和资源,然后进行有针对性的优化,最终达到优化终端用户在浏览器端使用体验的目的;
而业界普遍采用的前端测试方法,是根据雅虎前端团队总结的优化规则,可以点击这里查看;
以下列出作者觉得重要的规则:
- 减少http请求次数,http请求数量越多,执行过程越长;
- 减少dns查询次数,dns作用是将URL转化为实际IP地址,是分级查找,需要耗费20ms+;
- 避免页面跳转;
- 使用内容分发网络CDN;
- Gzip压缩传输文件,压缩可以减少传输文件大小,减少;
代码级性能测试
代码级性能测试,是指在单元测试阶段就对代码的时间性能和空间性能进行必要的测试和评估,以防止底层代码的效率问题在项目后期才被发现的尴尬;
最常使用的改造方法是:
- 将原本只会执行一次的单元测试用例连续执行 n 次,这个 n 的取值范围通常是 2000~5000;
- 统计执行 n 次的平均时间。如果这个平均时间比较长(也就是单次函数调用时间比较长)的话,比如已经达到了秒级,那么通常情况下这个被测函数的实现逻辑一定需要优化;
压力测试
压力测试,通常指的是后端压力测试,一般采用后端性能测试的方法,不断对系统施加压力,并验证系统化处于或长期处于临界饱和阶段的稳定性以及性能指标,并试图找到系统处于临界状态时的主要瓶颈点,压力测试往往被用于系统容量规划的测试;
配置测试
用于观察系统在不同配置下的性能表现,通常使用后端性能测试的方法:
- 通过性能基准测试建立性能基线;
- 调整配置;
- 基于同样的性能基准测试,找到特定压力模式下的最佳配置;
这里的配置是广义,包含且不止:
- 宿主操作系统的配置;
- 应用服务器的配置;
- 数据库的配置;
- JVM的配置;
- 网络环境的配置;
并发测试
指的是在同一时间,同时调用后端服务,期间观察被调用服务在并发情况下的行为表现,旨在发现诸如资源竞争、资源死锁之类的问题;
可靠性测试
验证系统在常规负载模式下长期运行的稳定性,本质就是通过长时间模拟真实的系统负载来发现系统潜在的内存泄漏、链接池回收等问题;
性能测试的应用领域
这里“应用领域”主要包括能力验证、能力规划、性能调优、缺陷发现四大方面;
能力验证
主要是验证某系统能否在 A 条件下具有 B 能力,通常要求在明确的软硬件环境下,根据明确的系统性能需求设计测试方案和用例;
能力规划
能力规划关注的是,如何才能使系统达到要求的性能和容量,通常情况下会采用探索性测试的方式来了解系统的能力;
能力规划解决的问题,主要包括以下几个方面:
- 能否支持未来一段时间内的用户增长;
- 应该如何调整系统配置,使系统能够满足不断增长的用户数需求;
- 应用集群的可扩展性验证,以及寻找集群扩展的瓶颈点;
- 数据库集群的可扩展性验证;
- 缓存集群的可扩展性验证;
性能调优
性能调优主要解决性能测试过程中发现的性能瓶颈的问题,通常会涉及多个层面的调整,包括硬件设备选型、操作系统配置、应用系统配置、数据库配置和应用代码实现的优化等等;
缺陷发现
通过性能测试的各种方法来发现诸如内存泄露、资源竞争、不合理的线程锁和死锁等问题;
最常用的测试方法主要有并发测试、压力测试、后端性能测试和代码级性能测试;
30)后端性能测试工具原理与行业常用工具简介
完整的后端性能测试应该包括性能需求获取、性能场景设计、性能测试脚本开发、性能场景实现、性能测试执行、性能结果报告分析、性能优化和再验证;
使用性能测试工具获得性能测试报告只是性能测试过程中的一个必要步骤而已,而得出报告的目的是让性能测试工程师去做进一步的分析,以得出最终结论,并给出性能优化的措施;
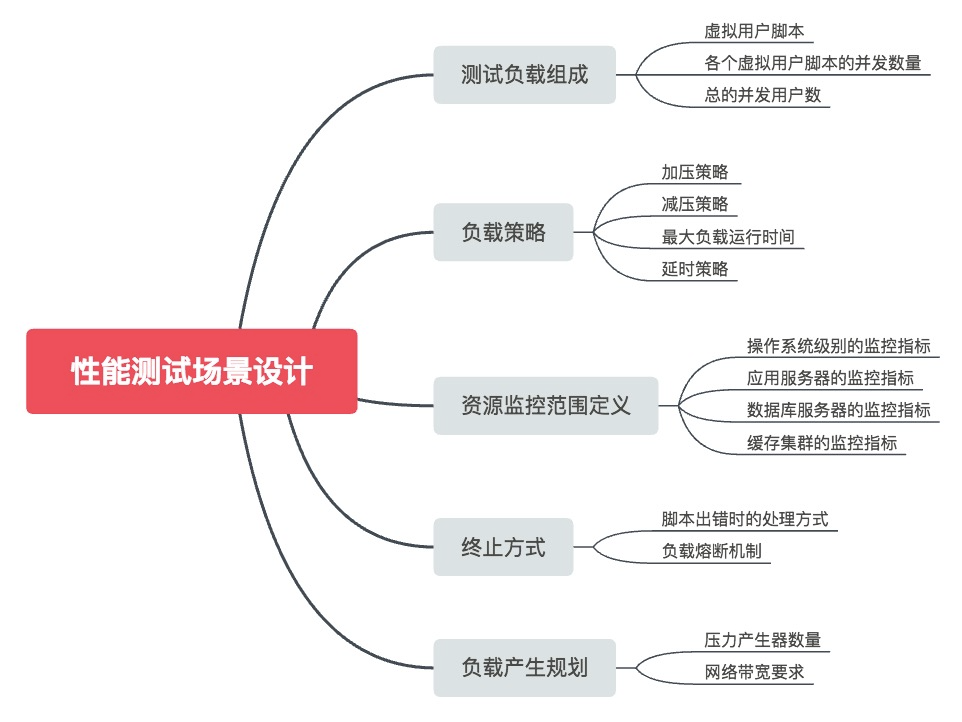
性能测试场景设计
常用的工具
业内有很多成熟的后端性能测试工具,比如LoadRunner、JMeter、NeoLoad 等,还有很多云端部署的后端性能测试工具或平台,比如 CloudTest、Loadstorm、阿里的 PTS 等;
目前最主流的是jmeter,因为开源免费、灵活、功能也强大,适合互联网企业;
而LR是按照并发用户数收费的,而且LR对定制功能支持不是特别好,传统企业用的会比较多;
原理
- 首先通过虚拟用户脚本生成器生成虚拟用户脚本;
- 然后根据性能测试场景设计的要求,通过压力控制器控制协调各个压力产生器以并发的方式执行虚拟用户脚本;
- 同时在测试执行过程中,通过系统监控器收集各种性能指标以及系统资源占用率;
- 最后,通过测试结果分析器展示测试结果数据;
前端性能测试工具原理与行业常用工具简介
webPagetest
是前端性能测试的利器:
- 可以为我们提供全方位的量化指标,包括页面的加载时间、首字节时间、渲染开始时间、最早页面可交互时间、页面中各种资源的字节数、后端请求数量等一系列数据;
- 还可以自动给出被测页面性能优化水平的评价指标,告诉哪些部分的性能已经做过优化处理了,哪些部分还需要改进;
- 同时,还能提供
Filmstrip视图、Waterfall视图、Connection视图、Request` 详情视图和页面加载视频慢动作;
参数解读
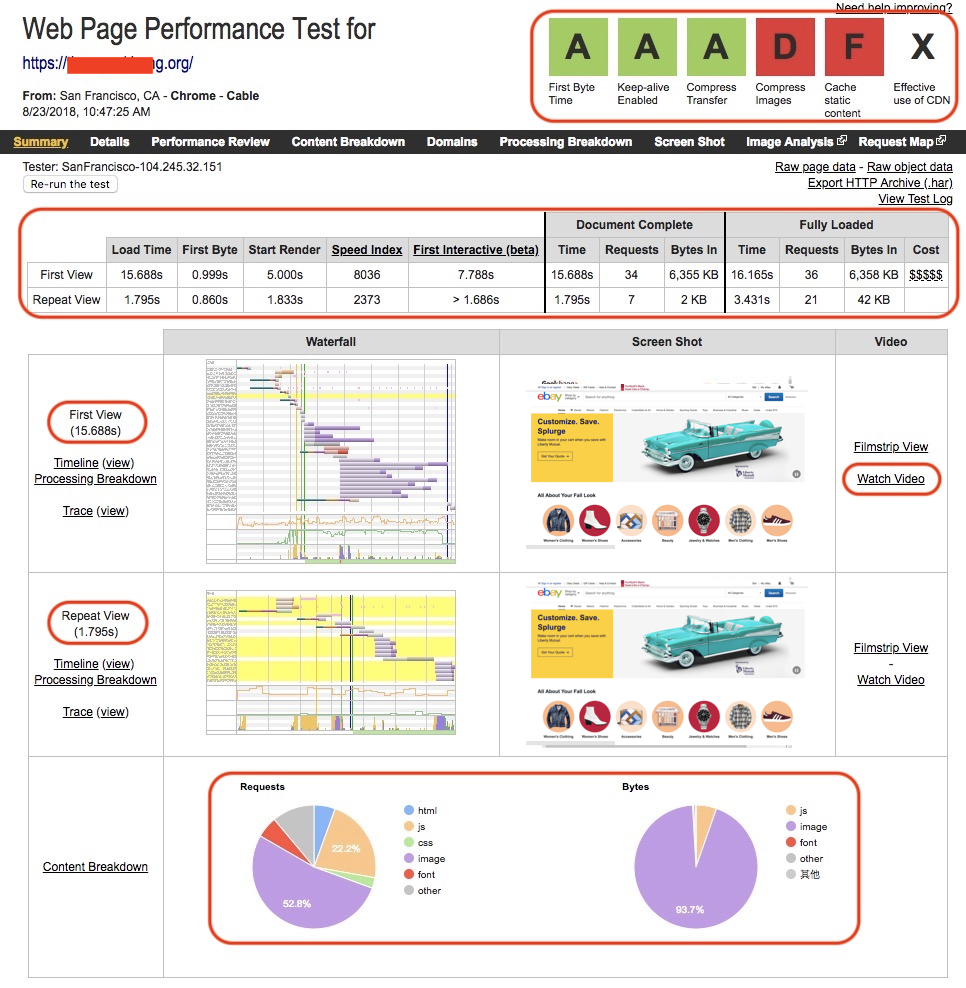
First Byte Time
指的是用户发起页面请求到接收到服务器返回的第一个字节所花费的时间。这个指标反映了后端服务器处理请求、构建页面,并且通过网络返回所花费的时间;
本次测试的结果,首次打开页面(First View)花费的时间是 999 ms,重复打开页面(Repeat View)花费的时间是 860 ms。这两个指标都在 1 s 以下,所以 WebPagetest 给出了 A 级的评分;
Keep-alive Enabled
要求每次请求使用已经建立好的链接,它属于服务器上的配置,不需要对页面本身进行任何更改,启用了 Keep-alive 通常可以将加载页面的时间减少 40%~50%,页面的请求数越多,能够节省的时间就越多;
Compress Transfer
如果将页面上的各种文本类的资源,比如 Html、JavaScript、CSS 等,进行压缩传输,将会减少网络传输的数据量,同时由于 JavaScript 和 CSS 都是页面上最先被加载的部分,所以减小这部分的数据量会加快页面的加载速度,同时也能缩短 First Byte Time。
Compress Images
为了减少需要网络传输的数据量,图像文件也需要进行压缩处理。显然本次测试结果显示(图 5),所有的 JPEG 格式图片都没有经过必要的压缩处理,并且所有的 JPEG 格式图片都没有使用渐进式 JPEG(Progressive JPEG)技术,所以 WebPagetest 给出了 D 级的评分;
Cache Static Content
页面上的静态资源不会经常变化,所以如果你的浏览器可以缓存这些资源,那么当重复访问这些页面时,就可以从缓存中直接使用已有的副本,而不需要每次向 Web 服务器请求资源。这种做法,可以显著提高重复访问页面的性能,并减少 Web 服务器的负载。
WebPagetest 实际使用中需要解决的问题
第一个问题是,如果被测网站部署在公司内部的网络中,那么处于外网的 WebPagetest 就无法访问这个网站,也就无法完成测试。
要解决这个问题,你需要在公司内网中搭建自己的私有 WebPagetest 以及相关的测试发起机。具体如何搭建,点击这里;
第二个问题是,用 WebPagetest 执行前端测试时,所有的操作都是基于界面操作的,不利于与 CI/CD 的流水线集成。
要解决这个问题,就必须引入 WebPagetest API Wrapper;
WebPagetest API Wrapper 是一款基于 Node.js,调用了 WebPagetest 提供的 API 的命令行工具。也就是说,你可以利用这个命令行工具发起基于 WebPagetest 的前端性能测试,这样就可以很方便地与 CI/CD 流水线集成了。具体的使用步骤如下:
- 通过
npm install webpagetest -g安装该命令行工具; - 访问
https://www.webpagetest.org/getkey.php获取你的WebPagetest API Key; - 使用
webpagetest test -k API-KEY 被测页面 URL发起测试,该调用是异步操作,会立即返回,并为你提供一个testId; - 使用
webpagetest status testId查询测试是否完成; - 测试完成后,就可以通过
webpagetest results testId查看测试报告,但是会发现测试报告是个很大的 JSON 文件,可读性较差; - 通过
npm install webpagetest-mapper -g安装webpagetest-mapper工具,这是为了解决测试报告可读性差的问题,将WebPagetest生成的 JSON 文件格式的测试报告转换成为 HTML 文件格式; - 使用
Wptmap -key API-KEY --resultIds testId --output ./test.html将 JSON 文件格式的测试结果转换成 HTML 格式;
32-33)基于LoadRunner实现企业级服务器端性能测试的实践
LR的主要模块
Virtual User Generator
用于生成模拟用户行为的测试脚本,生成的手段主要是基于协议的录制,也就是由性能测试脚本开发人员在通过 GUI 执行业务操作的同时,录制客户端和服务器之间的通信协议,并最终转化为代码化的 LoadRunner 的虚拟用户脚本;
LoadRunner Controller
Controller 相当于性能测试执行的控制管理中心,负责控制 Load Generator 产生测试负载,以执行预先设定好的性能测试场景;
同时,还负责收集各类监控数据;
LoadRunner Analysis
Analysis 是 LoadRunner 中一个强大的分析插件;
不仅能图形化展示测试过程中收集的数据,还能很方便地对多个指标做关联分析,找出它们之间的因果关系;
最根本的目的就是,分析出系统可能的性能瓶颈点以及潜在的性能问题;
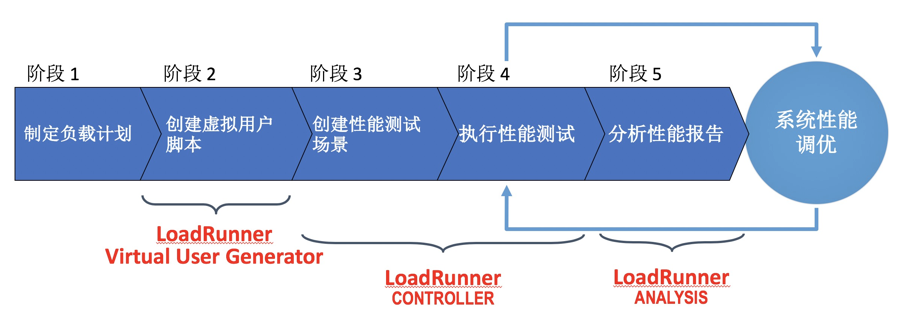
从宏观角度来讲,基于 LoadRunner 完成企业级性能测试,可以划分为五个阶段:
- 性能需求收集以及负载计划制定;
- 录制并增强虚拟用户脚本;
- 创建并定义性能测试场景;
- 执行性能测试场景;
- 分析测试报告;
35)企业级实际性能测试案例与经验分享
性能基准测试
是每次对外发布产品版本前都需要做的类型;
- 启动速度;
- 同一接口响应时间;
- CPU占用率;
- 帧率;
- 卡顿等
是需要用上一个版本数据做基准,在同一操作环境下进行对比,目的是为了保证新版本整体性能不会下降;
稳定性测试
又称可靠性测试,主要是通过长时间(7*24 小时)模拟被测系统的测试负载,来观察系统在长期运行过程中是否有潜在的问题;
移动端里面典型的就是monkey,一般来说,稳定性是发布前的硬性要求;
并发测试
并发测试,是在高并发情况下验证单一业务功能的正确性以及性能的测试手段;
容量规划测试
是软件产品为满足用户目标负载而调整自身生产能力的过程;
容量规划的主要目的是,解决当系统负载将要达到极限处理能力时,应该如何通过垂直扩展(增加单机的硬件资源)和水平扩展(增加集群中的机器数量)增加系统整体的负载处理能力的问题;
35-38)测试数据的准备/构造
这4章都是讲测试数据相关,之前也单独提炼出一篇文章,这里不重复,直接点击这里查看;
39)什么是Selenium Grid
本篇都在讲selenium grid相关,之前jb看了虫师的selenium2的书籍,也做了一些笔记,里面也有提及到selenium grid,因此这里不打算重复描述,内容相似,点击[这里]juejin.cn/post/684490…)查看;
40-41) 聊聊测试执行环境的架构设计
测试执行环境
- 狭义的测试执行环境,单单指测试执行的机器或者集群;
- 广义的测试执行环境,除了包含具体执行测试的测试执行机以外,还包括测试执行的机器或者集群的创建与维护、测试执行集群的容量规划、测试发起的控制、测试用例的组织以及测试用例的版本控制等等;
广义的测试执行环境,也称测试基础架构;
测试基础架构可以解决的问题:
- 简化测试执行过程;
- 最大化测试执行机器的资源利用率;
- 提供大量测试用例的并发执行能力;
- 提供测试用例的版本控制机制;
- 提供友好的用户界面;
因此在设计测试基础架构,需要考虑几个方面:
- 对使用者而言,测试基础架构的透明性;
- 对维护者而言,技术基础架构的易维护性;
- 做到对大量测试用例并发执行的
可扩展性; - 兼顾移动 App对测试执行环境的需求;
早期的测试基础架构
将测试用例存储在代码仓库中,然后是用 Jenkins Job来pull代码并完成测试的发起工作;
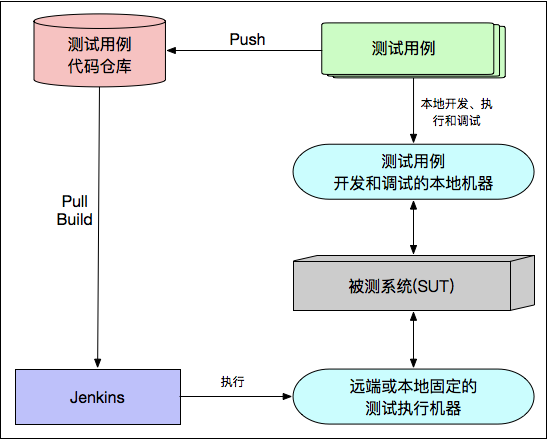
在这种架构下,自动化测试用例的开发和执行流程,是按照以下步骤执行的:
- 自动化测试开发人员在本地机器开发和调试测试用例;
- 将开发的测试用例代码push到代码仓库;
- 在jenkins中建立一个job,用于发起测试的执行,先从测试用例代码仓库中
Pull测试用例代码,并发起构建操作;然后,在远端或者本地固定的测试执行机上发起测试用例的执行;
弊端是对测试执行机器信息不可知,比如ip等是否发生变化、环境是否一致;
经典的测试基础架构
利用selenium Grid代替早期的远程或本地固定的测试执行机器;
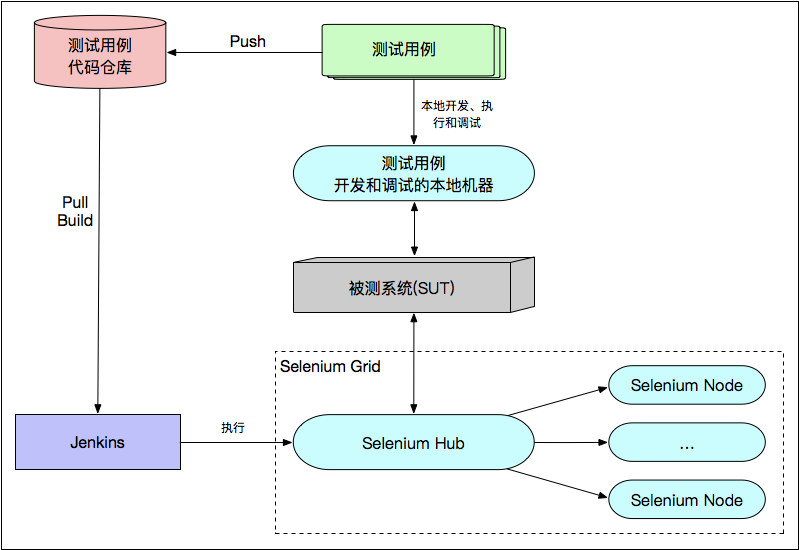
每次发起测试时,就不再需要指定具体的测试执行机器了,只要提供固定的 Selenium Hub 地址就行,然后 Selenium Hub 就会自动帮你选择合适的测试执行机;
在测试规模比较少的情况下,可以采用第一种方式,但一旦规模庞大起来,就需要调整了;
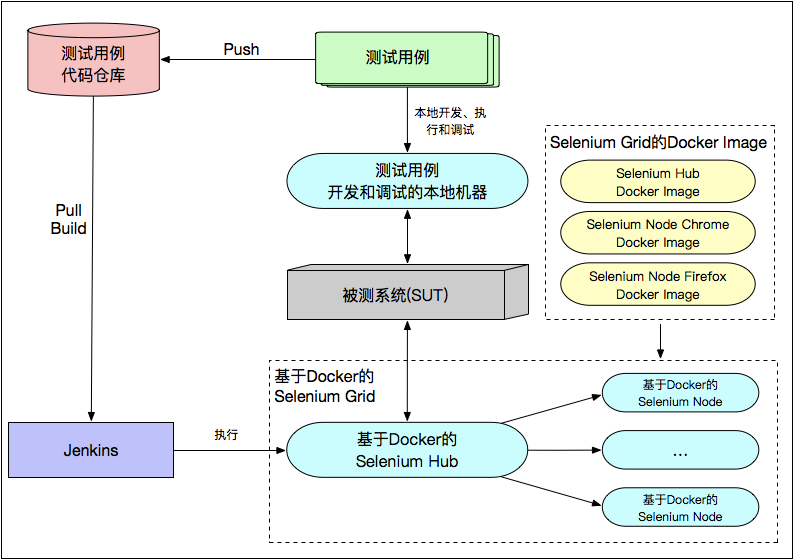
基于 Docker 实现的 Selenium Grid 测试基础架构
Selenium Grid虽然能解决问题,但是随着测试用例的增加,需要维护多个Node,因此引入docker代替原来的方案,可以降低维护成本:
- 由于 Docker 的更新维护更简单,只要维护不同浏览器的不同镜像文件即可,而无需为每台机器安装或者升级各种软件;
- Docker 轻量级的特点,使得 Node 的启动和挂载所需时间大幅减少,直接由原来的分钟级降到了秒级;
- Docker 高效的资源利用,使得同样的硬件资源可以支持更多的 Node,可以在不额外投入硬件资源的情况下,扩大 Selenium Grid 的并发执行能力;
引入统一测试执行平台的测试基础架构
随着项目数量增加,jenkins配置时间也会增加,因此作者提出实现一个GUI界面系统来管理和执行这些jenkins job;
- 测试用例的版本化管理;
- 提供基于
restful api的测试执行接口供CI/CD使用;
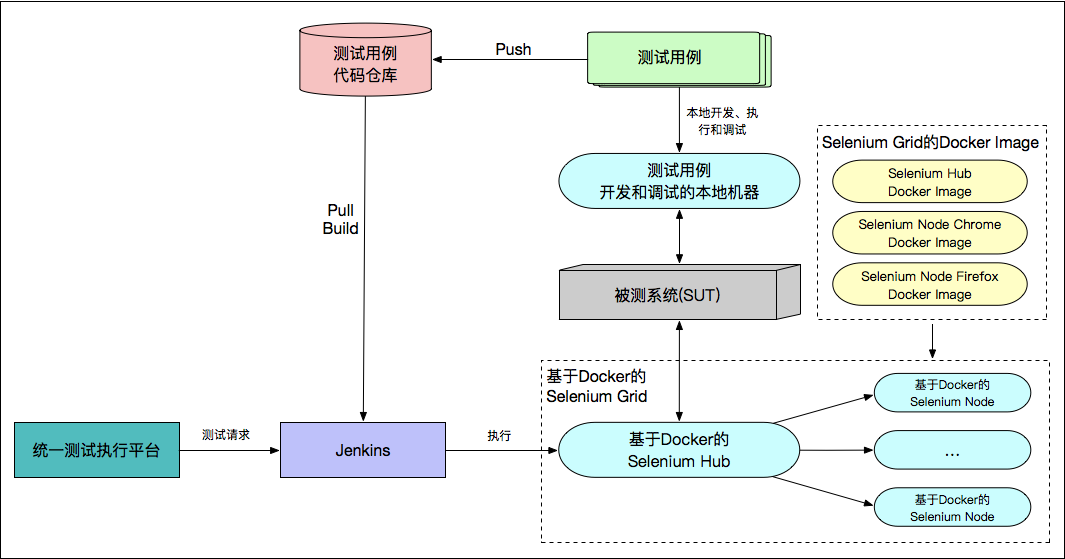
基于 Jenkins 集群的测试基础架构
单个 Jenkins 成了整个测试基础架构的瓶颈节点。因为,来自于统一测试执行平台的大量测试请求,会在 Jenkins 上排队等待执行,而后端真正执行测试用例的 Selenium Grid 中很多 Node 处于空闲状态;
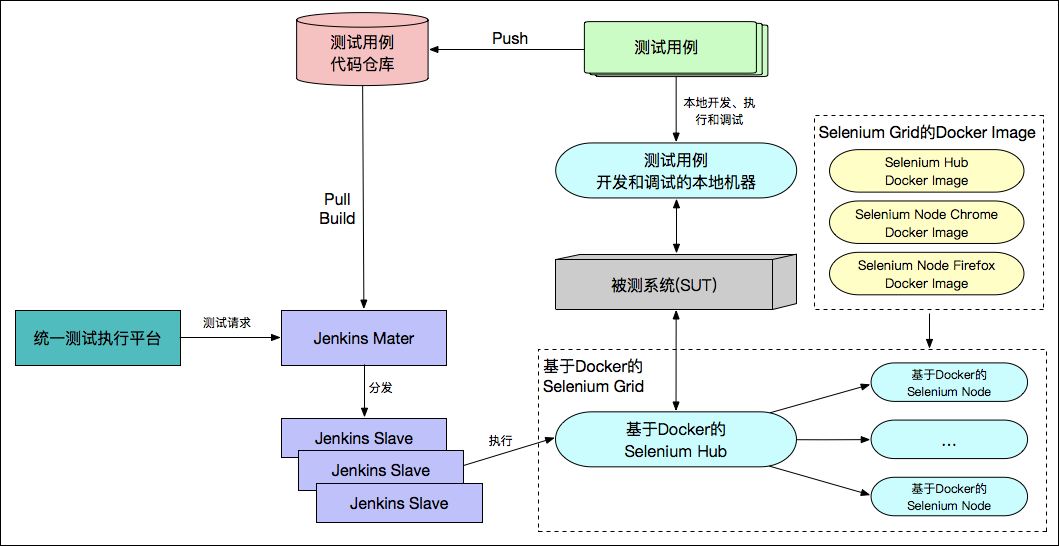
测试负载自适应的测试基础架构
引入了 Jenkins 集群后,整个测试基础架构已经很成熟了,基本上可以满足绝大多数的测试场景了;
但是,还有一个问题一直没有得到解决,那就是:
Selenium Grid 中 Node 的数量到底多少才合适?
为了解决这种测试负载不均衡的问题,Selenium Grid 的自动扩容和收缩技术就应运而生了;
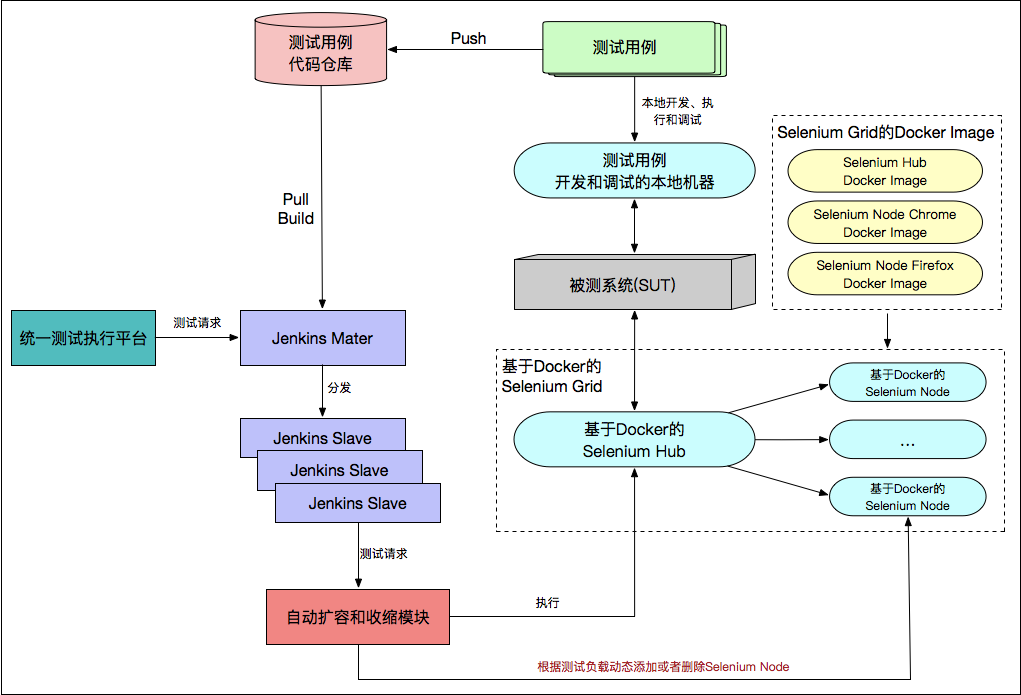
如何选择适合自己的测试基础架构
如果所在的企业如果规模不是很大,测试用例执行的总数量相对较少,而且短期内也不会有大变化的情况,那么测试基础架构完全就可以采用经典的测试基础架构,而没必要引入 Docker 和动态扩容等技术;
如果是大型企业,测试用例数量庞大,同时还会存在发布时段大量测试请求集中到来的情况,那么此时就不得不采用 Selenium Gird 动态扩容的架构了,而一旦要使用动态扩容,那么势必你的 Node 就必须做到 Docker 容器化,否则无法完全发挥自动扩容的优势;
因此根据不同的情况而酌情选择,是由测试需求推动的;
42)大型全球化电商的测试基础架构设计
大型全球化电商网站全局测试基础架构的设计思路,可以总结为测试服务化;
也就是说,测试过程中需要用的任何功能都通过服务的形式提供,每类服务完成一类特定功能,这些服务可以采用最适合自己的技术栈,独立开发,独立部署;
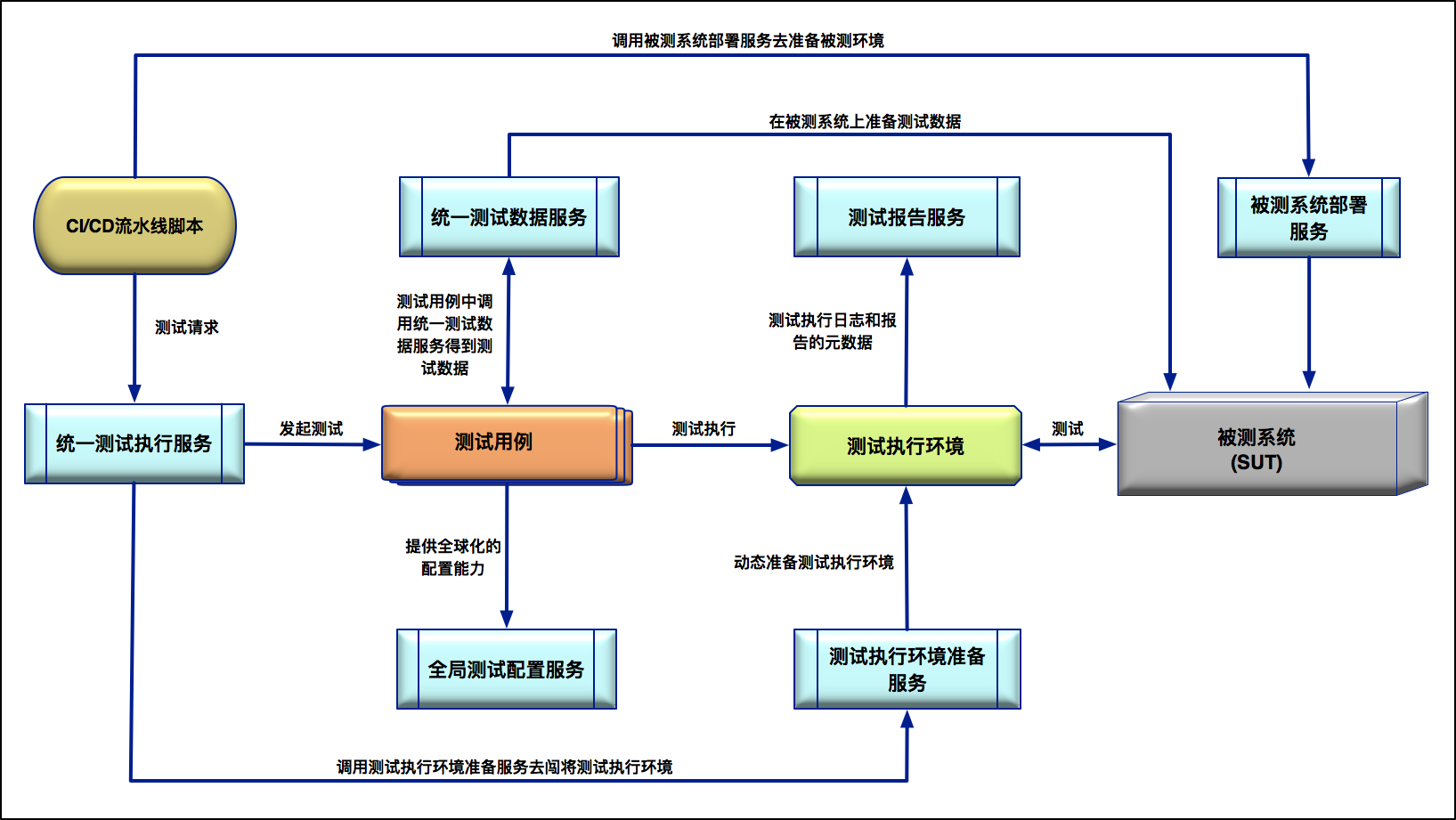
理想的测试基础架构,应该包含6种不同的测试服务:
统一测试执行服务
通过 Spring Boot 框架提供 Restful API,内部实现是通过调度 Jenkins Job 具体发起测试;
本质是统一测试执行平台;
统一测试数据服务
统一测试数据平台;
测试执行环境准备服务
这里测试执行环境,特指具体执行测试的测试执行机器集群:
对于 GUI 自动化测试来说,指的就是 Selenium Grid;
对于 API 测试来说,指的就是实际发起API调用的测试执行机器集群;
被测系统部署服务
主要是被用来安装部署被测系统和软件;
被测报告服务
主要作用是为测试提供详细的报告;
全局测试配置服务
本质是要解决测试配置和测试代码的耦合问题;
43)探索性测试
什么是探索性测试
- 探索式测试是一种软件测试风格,而不是一种具体的软件测试技术;
- 作为一种思维方法,探索式测试强调依据当前语境与上下文选择最适合的测试技术,并且强调独立测试工程师的个人自由和责任,其目的是为了持续优化其工作价值;
- 在整个项目过程中,将测试相关学习、测试设计、测试执行和测试结果解读作为小相互支持的活动,并行执行;
如何开展探索性测试
- 会对软件的单一功能进行比较细致的探索式测试,主要是基于功能需求以及非功能性需求进行扩展和延伸;
- 开展系统交互的探索性测试,采用基于反馈的探索性测试方法;
探索性测试更多关注的就是循序渐进,迭代深入的过程;
44)测试驱动开发TDD
测试驱动开发,也就是 Test-Driven Develop,通常简称为 TDD;
核心思想,是在开发人员实现功能代码前,先设计好测试用例的代码,然后再根据测试用例的代码编写产品的功能代码;
最终目的是让开发前设计的测试用例代码都能够顺利执行通过;
TDD优势
- 保证开发的功能一定是符合实际需求的;
- 更加灵活的迭代方式;
- 保证系统的可扩展性;
- 更好的质量保证;
- 测试用例即文档;
测试驱动开发的实施过程
- 需要实现的新功能添加一批测试;
- 运行所有测试,看看新添加的测试是否失败;
- 编写实现软件新功能的实现代码;
- 再次运行所有的测试,看是否有测试失败;
- 重构代码;
- 重复以上步骤直到所有测试通过;
TDD的难点
- 需要一定的代码能力;
- 推动TDD,需要改革整个研发流程;
TDD放大到开发流程
评论里有一套开发流程,可以参考下:
- 所有人员参与需求评审;
- 测试编写测试用例;
- 所有人员参与用例评审;
- 开发按照测试用例进行编码;
- 开发执行用例,自测,到用例通过后;
- 开发提测;
- 测试介入测试;
好处:
- 提早发现不合理需求,减少后面返工的几率;
- 研发自测,提高自测质量;
以上是评论区看到的,仅供参考;
45)精准测试
核心思想
借助一定的技术手段、通过算法的辅助对传统软件测试过程进行可视化、分析以及优化的过程,使得测试过程可视、智能、可信和精准;
拥有几个特征:
- 是对传统测试的补充;
- 采用的是黑盒与白盒相结合的模式;
- 数据可信度高;
- 不直接面对产品代码;
- 与平台无关,多维度的测试分析算法系统;
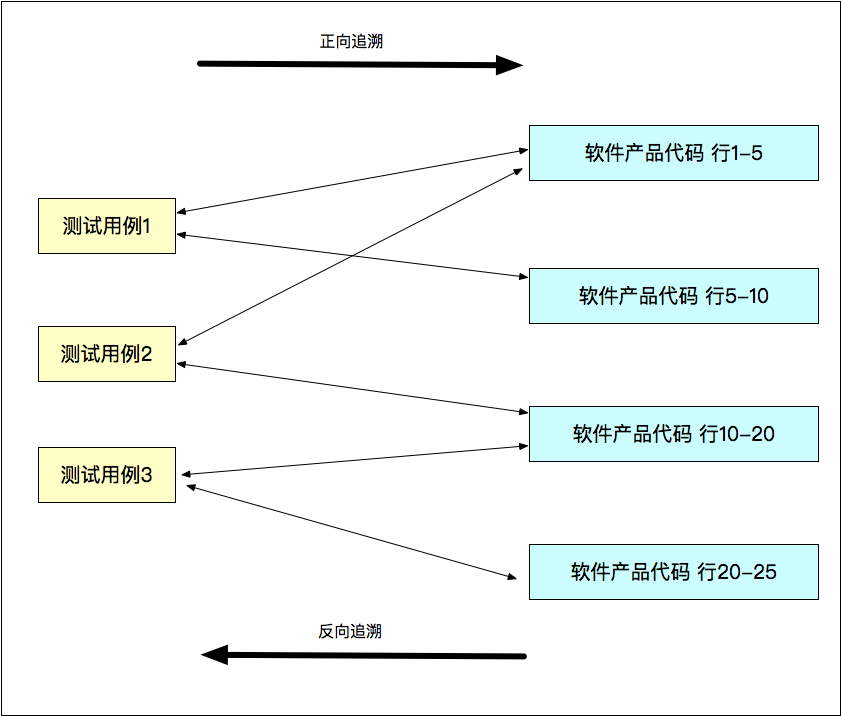
双向mapping关系
是通过代码覆盖率工具来实现的;
- 基于该产品的开发语言,选择好一款代码覆盖率工具,然后把测试用例到产品代码这条路打通;
- 再通过这些代码覆盖率工具的APIs,等到跑完这个测试用例,拿到源文件 、
Class,Method,Line等相关信息; - 把测试用例信息以及上面拿到的
mapping信息记录表中,这样就形成了双向mapping; - 这样一旦代码修改,可以通过
class,method等信息,去数据库搜到关联的测试用例,就能实现精准测试了;
46) 渗透测试
渗透测试的定义
渗透测试指的是,由专业安全人员模拟黑客,从其可能存在的位置对系统进行攻击测试,在真正的黑客入侵前找到隐藏的安全漏洞,从而达到保护系统安全的目的;
渗透测试的常用方法
针对性测试
针对性的测试,属于研发层面的渗透测试;
参与这类测试的人员,可以得到被测系统的内部资料,包括部署信息、网络信息、详细架构设计,甚至是产品代码;
需要完全了解系统内部情况的前提下开展;
外部测试
外部测试,是针对外部可见的服务器和设备(包括:域名服务器(DNS)、Web 服务器或防火墙、电子邮箱服务器等等),模拟外部攻击者对其进行攻击,检查它们是否能够被入侵,以及如果被成功入侵了,会被入侵到系统的哪一部分、又会泄露多少资料;
一般是不清楚系统内部情况下开展的;
内部测试
由测试工程师模拟内部人员,在内网(防火墙以内)进行攻击,因此测试人员会拥有较高的系统权限,也能够查看各种内部资料,目的是检查内部攻击可以给系统造成什么程度的损害;
盲测
盲测,指的是在严格限制提供给测试执行人员或团队信息的前提下,由他们来模拟真实攻击者的行为和上下文;
双盲测试
双盲测试可以用于测试系统以及组织的安全监控和事故识别能力,及其响应过程。一般来说,双盲测试一般是由外部的专业渗透测试专家团队完成,所以实际开展双盲测试的项目并不多;
执行渗透测试的步骤
- 规划和侦察,包含定义测试的范围和目标、初步确定要使用的工具和方法、明确需要收集的情报;
- 安全扫描,分为静态和动态分析;
- 获取访问权限,比如sql输入、xss脚本攻击等方式来发现系统漏洞;
- 维持访问权限;
- 入侵分析,可以被利用的特定漏洞、利用该漏洞的具体步骤、能够被访问的敏感数据;
常用的工具
Nmap
是进行主机检测和网络扫描的重要工具。它不仅可以收集信息,还可以进行漏洞探测和安全扫描,从主机发现、端口扫描到操作系统检测和 IDS 规避 / 欺骗;
Aircrack-ng
是评估 Wi-Fi 网络安全性的一整套工具。它侧重于 WiFi 安全的领域,主要功能有:网络侦测、数据包嗅探、WEP 和WPA/WPA2-PSK 破解;
sqlmap
是一种开源的基于命令行的渗透测试工具,能够自动进行 SQL 注入和数据库接入;
Wifiphisher
是一种恶意接入点工具,可以对 WiFi 网络进行自动钓鱼攻击;
AppScan
一款企业级商业 Web 应用安全测试工具,采用的是黑盒测试,可以扫描常见的 Web 应用安全漏洞;
原理:
- 从起始页爬取站下所有的可见页面,同时测试常见的管理后台;
- 利用 SQL 注入原理测试所有可见页面,是否在注入点和跨站脚本攻击的可能;
- 同时,检测 Cookie 管理、会话周期等常见的 Web 安全漏洞;
47)基于模型的测试
MBT的基本原理
MBT 是一种基于被测系统的模型,由工具自动生成测试用例的软件测试技术;
原理是通过建立被测系统的设计模型,然后结合不同的算法和策略来遍历该模型,以此生成测试用例的设计;
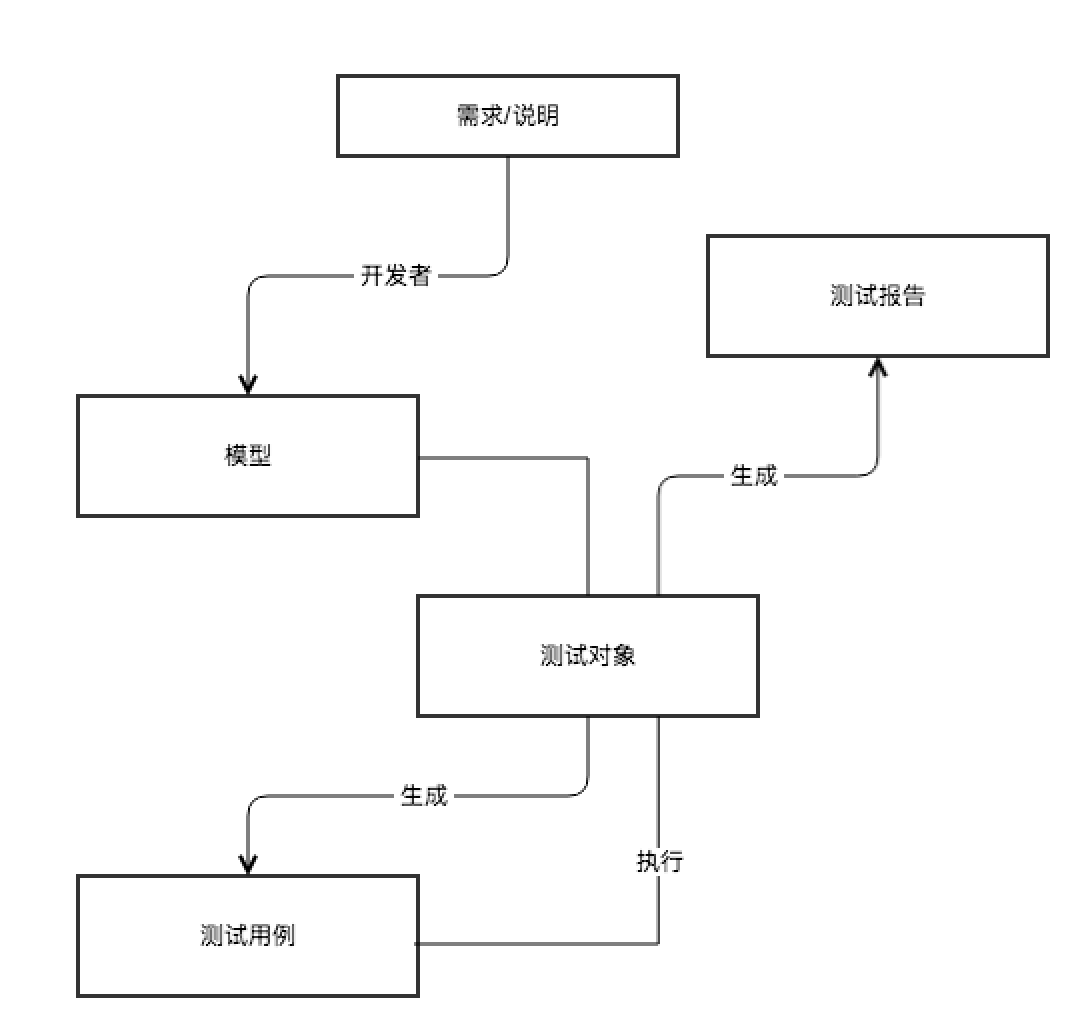
开发者首先根据产品需求或者说明来构建模型,然后结合测试对象生成测试用例,测试用例针对测试对象执行完之后,生成测试报告比对测试结果;
常用模型简介
有限状态机
有限状态机可以帮助测试人员根据选中的输入来评估输出,不同的输入组合对应着不同的系统状态;
状态图
状态图是有限状态机的延伸,用于描述系统的各种行为,尤其适用于复杂且实时的系统;
UML
UML 即统一建模语言,是一种标准化的通用建模语言;
UML 可以通过创建可视化模型,来描述非常复杂的系统行为;
工具简介
BPM-X
BPM-X 根据不同的标准(比如,语句、分支、路径、条件)从业务流程模型创建测试用例;
fMBT fMBT 是一组免费的、用于全自动测试生成和执行的工具,也是一组支持高水平测试自动化的实用程序和库,主要被应用在 GUI 测试中;
GraphWalker
GraphWalker 以有向图的形式读取模型,读取这些模型,然后生成测试路径,更适合于多状态以及基于事件驱动的状态转换的后台系统;
MBT优势
- 测试用例维护更轻松;
- 软件缺陷发现的更早;
- 测试自动化的水平更高;
- 测试覆盖率变的更高;
- 基于模型间接维护测试用例的方式更高效;
MBT劣势
- 学习成本较高;
- 初期投资较大;
- 根据模型生成测试用例的技术并不是非常成熟;
49)深入浅出网站高性能架构设计
前端的高性能架构
前端高性能架构比较直观易懂,其本质就是通过各种技术手段去优化用户实际感受到的前端页面展现时间。
后端服务器的高性能架构
缓存
- 浏览器级别的缓存,用来存储之前在网络上下载过的静态资源;
- CDN本质就是缓存,属于部署在网络服务供应商机房中的缓存;
- 反向代理服务器也是缓存,属于用户数据中心最前端的缓存;
- 数据库中的热点数据,在应用服务器集群中有一级缓存,在缓存服务集群中有二级缓存;
读取缓存的处理:
- 如果读取成功,很大程度降低访问数据库的时间开销;
- 如果没有读取到或者失效,则会访问数据库获取,获取到后,会把数据写入缓存里,以备下次使用;
缓存主要用来存储那些相对变化较少,并且遵从“二八原则”的数据;这里的“二八原则”指的是 80% 的数据访问会集中在 20% 的数据上;
缓存技术并不适用于那些需要频繁修改的数据;
与缓存相关的测试场景:
- 对于前端,需要考虑缓存命中和不命中下的页面加载时间;
- 基于缓存过期的设计,需要考虑到重新获取数据的测试场景;
- 缓存脏数据,即数据库已经更新了,但是缓存的数据还没更新;
- 缓存穿透,即数据不存在,这类数据会一直重复访问数据库;
- 分布式缓存集群,不同集群缓存算法可能不同,需要进行测试和评估;
集群
- 集群容量扩展,新增节点,是否会对原有的session会有影响;
- 对于无状态的应用,是否可以实现灵活的实效转移;
- 当集群出现宕机时,对在线用户的影响评估;
- 负载均衡算法的效果;
- 高并发场景下,集群能够承载的最大容量;
50)深入浅出网站高可用架构设计
网站高可用指的就是,在绝大多的时间里,网站一直处于可以对外提供服务的正常状态,业界通常使用有多少个“9”来衡量网站的可用性指标,具体的计算公式也很简单,就是一段时间内(比如一年)网站可用的时间占总时间的百分比;
- 基本可用,99%;
- 较高可用,99.9%;
- 具备故障自动恢复能力的可用,99.99%;
- 极高可用,99.999%;
造成网站不可用的主要原因
服务器硬件故障
如宕机,需要保障的是即使出现了硬件故障,也要保证系统的高可用;
解决方案就是从硬件层面加入必要的冗余,同时充分发挥集群的牲口优势;
这样就需要准备至少两台同样的服务器,当其中一台宕机的时候,另外一台能正常对外服务;
那么,从测试人员的角度来看,我们依旧可以针对这种情况设计出针对部分数据服务器发生故障时的测试用例,以完成系统应对故障的反应情况的测试。
发布新应用的过程
在发布过程,会因为部署新版本而重启服务器的情况,会导致短暂时间不可用;
解决方案就是灰度发布,前提是服务器必须采用集群架构;
假如有N个节点的集群需要更新新版本,这时候更新过程是这样的:
- 从负载均衡器的服务器列表中删除其中的一个节点;
- 将新版本的应用部署到这台删除的节点中并重启该服务;
- 重启完成后,将包含新版本应用的节点重新挂载到负载均衡服务器中,让其真正接受外部流量,并严密观察新版本应用的行为;
- 如果没有问题,那么将会重复以上步骤将下一个节点升级成新版本应用,如果有问题,就会回滚这个节点的上一个版本;
- 如此反复,直至集群的节点全部更新为新版本应用;
程序本身的问题
- 上线前回归测试;
- 预发布验证;
- 线上日志监控;
预发布的原因是因为,经常出现测试环境没问题,生产环境有问题,可能是因为网络、数据量、依赖的第三方库不一样等各种原因导致,而预发布环境的要求是跟生产环境一模一样,只是不会对外暴露而已;
集群、分布式、微服务
该内容文中没有提及到,是jb自行补充的,直接找了逼乎的例子;
分布式&集群:分散压力; 微服务:分散能力;
分布式一般部署到多台,而多台关联的机器,可以称为集群;
- 分布式
-
- 不同模块部署在不同服务器上;
-
- 作用:分布式解决网站高并发带来问题;
- 集群
-
- 相同的服务多台服务器部署相同应用构成一个集群;
-
- 作用:通过负载均衡设备共同对外提供服务,提供高性能;
- 微服务
-
- 架构设计概念,各服务间隔离;
-
- 作用:各服务可独立应用,组合服务也可系统应用,各能力独立,相互不影响;
厨房例子
- 当业务量过多,单机服务忙不过来,那么多请几个厨师,这是简单的复制,增加人手,可以理解为一群人做事,是集群;
- 简单复制的话,一个厨师请假,服务不会fail,厨师长可以做负载均衡工作;
- 如果厨房断水断电,再多厨师也白搭。分布式并不是将业务切分为买菜,洗菜,切菜,配菜,做菜,这叫微服务,不是分布式;
- 而每一个工序都可以是分布式的,如果有必要的话。为了满足更恶劣的条件,断水断电,厨师罢工,服务仍然可用,对厨房进行分布式改造,在多个地点设置厨房,每个厨房不需要包含所有工序,但不允许一个工序只在一个厨房,即分区容错性;
- 同时,付出的代价是一道菜可能有多个副本,防止突发事件使得一道菜的原料丢失;
- 简单复制的集群当然具有分区容错性,因为都一样;
- 微服务可以使厨师专注于自己的工序,为了让微服务能够顶住恶劣的生存环境,需要分布式和集群,整个厨房是分布式的,但其中的一个工序既可以是简单复制负载平衡,也可以是一个小的,独立的分布式;
月嫂例子:
单体架构
家里生小宝宝啦,由于自己没有照顾小宝宝的经验,所以请了位经验丰富的月嫂。 这位月嫂从买菜,到做饭,洗衣,拖地,喂奶,哄睡,洗澡,换纸尿裤,擦屁股,做排气操,夜间陪护,给奶妈做月子餐等等,全部都做, 这种叫做单体架构。
集群
什么都做,一个月嫂怎么够呢,肯定忙不过来呀,那就请两个月嫂吧,这叫做集群;
高可用
有一个月嫂过生日,想请假回去和亲戚打一天麻将。如果只有一个月嫂,她走了,就叫做服务中断了;
但是因为做了集群,有两个月嫂,走了一个,另一个还是能用,虽然相比较吃力一些,但是毕竟还是能用的,这个现象叫做高可用;
分布式
一个月嫂,一个月的费用基本上都要1万多,还有房贷,还有车贷,生活费用还高,实在是请不起两位啊,那就还是请一位吧;
可是事情那么多,她实在忙不过来,怎么办呢? 那就把爷爷请过来买菜,把奶奶请过来做饭。 这样服务本来仅仅是由月嫂一人提供的,变成了和宝宝相关的由月嫂负责,采购由爷爷负责,餐饮由奶奶负责。 这就叫做分布式了;
低耦合
做宝宝服务的月嫂去打麻将了,不影响做饭的奶奶。 做采购的爷爷去喝酒了,也不影响月嫂的宝宝服务,这叫做低耦合;
高内聚
和宝宝相关的事情都是月嫂在做,月嫂兑奶方式快慢,只会影响自己,对爷爷和奶奶的服务没影响. 这叫做高内聚;
集群+分布式
奶奶一个人做饭,做久了也烦啊,也累啊,也想打麻将呀。 那么就把姥姥也请过来吧。 这样做饭这个服务,就由奶奶和姥姥这个集群来承担啦。她们俩,谁想去汗蒸了,都有另一位继续提供做饭服务。
这就叫做集群+分布式;
51)深入浅出网站伸缩性架构设计
可伸缩性和可扩展性的概念区别
可伸缩性,指的是通过简单地增加硬件配置而使服务处理能力呈线性增长的能力,最简单直观的例子,就是通过在应用服务器集群中增加更多的节点,来提高整个集群的处理能力;
可扩展性,指的是网站的架构设计能够快速适应需求的变化,当需要增加新的功能实现时,对原有架构不需要做修改或者做很少的修改就能够快速满足新的业务需求;
分层的可伸缩性架构
- 根据功能进行物理分离来实现伸缩;
- 物理分离后的单一功能通过增加或者减少硬件来实现伸缩;
从整体架构的角度来看,应用服务器、缓存集群和数据库服务器各自都有适合自己的可伸缩性设计策略:应用服务器主要通过集群来实现可伸缩性,缓存集群主要通过 Hash 一致性算法来实现,数据库可以通过业务分库、读写分离、分布式数据库以及 NoSQL 来实现可伸缩性;
52)深入浅出网站可扩展性架构设计
从技术实现上来看,消息队列是实现可扩展性的重要技术手段之一;
其基本核心原理是各模块之间不存在直接的调用关系,而是使用消息队列,通过生产者和消费者模式来实现模块间的协作,从而保持模块与模块间的松耦合关系;
引入消息队列后,测试数据的创建和测试结果的验证工作,都需要通过读写消息队列来完成。同时,我们还要考虑到消息队列满、消息队列扩容,以及消息队列服务器宕机情况下的系统功能验证;
53)全链路压测
全链路压测,是基于真实的生产环境来模拟海量的并发用户请求和数据,对整个业务链路进行压力测试,试图找到所有潜在性能瓶颈点并持续优化的实践;
全链路压测的应用场景,不仅仅包括验证系统在峰值期间的稳定性,还会包含新系统上线后的性能瓶颈定位以及站点容量的精准规划;
单系统独立压测
- 根据设计的压力来直接模拟大量的并发调用;
- 先获取线上真是的流量请求,数据清洗,回放模拟大量的并发调用;
都会涉及到流量模拟、数据准备、数据隔离等常规操作;
局限性:
- 单系统压测的时候,会假设其依赖的所有系统能力都是无限的,而实际情况一定不是这样,这就造成了单系统压测的数据普遍比较乐观的情况;
- 在大压力环境下,各系统间的相互调用会成为系统瓶颈,但这在单系统压测的时候根本无法体现;
- 大压力环境下,各系统还会出现抢占系统资源(比如网络带宽、文件句柄)的情况,这种资源抢占必然会引入性能问题,但是这类问题在单系统压测过程中也无法体现出来;
- 由于是单系统测试,所以通常都只会先选择最核心的系统来测试,这就意味着其他的非核心系统会被忽略,而在实际项目中,这些非核心系统也很有可能会造成性能瓶颈;
全链路的难点
海量并发请求的发起
这种情况一般会采用jmeter,因为LR是按并发用户数费用,费用高;
难点:
- 采用了分布式的
JMeter方案,并发数量也会存在上限,因此会改用Jenkins Job单独调用JMeter节点来控制和发起测试压力,因为jmeter是相互独立,只有jenkins job足够多,就可以发起足够大的并发; - 测试脚本、测试数据和测试结果在分布式 JMeter 环境中的分发难题,解决方案就是基于jmeter搭建一个压测框架,如脚本分发、数据分发以及结果回传等都由平台完成;
- 流量发起的地域要求,需要在不同城市的数据中心搭建
jmeter slave;
全链路压测流量和数据的隔离
需要对压测流量进行特殊的数据标记,以区别于真实的流量和数据;
实际业务负载的模拟
这里的难点主要体现在两个方面:
- 要估算负载的总体量级;
- 需要详细了解总负载中各个操作的占比情况以及执行频次;
业界通常采用的策略是,采用已有的历史负载作为基准数据,然后在此基础上进行适当调整;
具体到执行层面,通常的做法是,录制已有的实际用户负载,然后在此基础上做以下两部分修改:
- 录制数据的清晰,将录制得到的真实数据统一替换成为压测准备的数据;
- 基于用户模型的估算,在压测过程中,按比例放大录制脚本的负载;
真实交易和支付的撤销以及数据清理
对这些交易的流量和数据进行了特定标记,可以比较方便地筛选出需要撤销的交易,然后通过自动化脚本的方式来完成批量的数据清理工作;
