

1、HBase在Ad Tracking的应用
1.1 输入标Ad Tracking的业务场景题
Ad Tracking是TalkingData的移动广告监测产品,其核心业务模型是归因。App用户点击广告之后,及随后安装广告跳转到的应用或者游戏,Ad Tracking会对这些点击事件(用户点击广告的行为)和激活事件(用户安装应用的行为)进行监测。
归因需要做的是,接收到激活事件之后,通过激活事件匹配之前接收到的点击事件,如果激活归因到了点击,那么这个激活事件就是点击广告带来的,也就归因到了该广告对应的推广活动,而推广活动对应某个渠道,归因到了推广活动就归因到了投放广告的渠道等。后续的所有效果点事件(例如应用内的注册、登录等事件)也都将通过对应的激活事件找到对应的推广活动信息。
激活和各种效果点事件的原始信息,包括对应的设备、归因到的推广活动等,都可以提供给Ad Tracking用户为参考——Ad Tracking的数据导出功能。
1.2 HBase与数据导出
HBase作为一个分布式的列式存储,拥有强悍的数据写入能力,由于是列式存储,随着后期需求的增加,可以动态的增加存储的字段,非常契合Ad Tracking的数据导出的业务场景。
通过合理的设计rowkey,HBase又能保证很快的查询速度,用户在Ad Tracking后台进行数据导出之后,基本上秒级时间就能够完成数据的下载,能够保证很好的导出体验。
下面将对HBase的架构原理和Ad Tracking数据导出功能中的应用进行介绍下。
2、HBase的架构
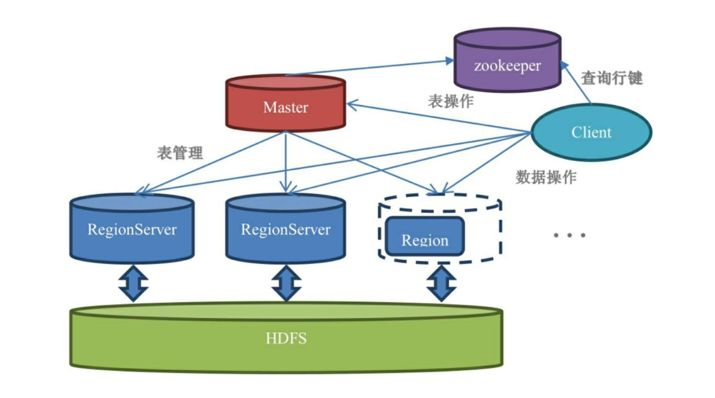
图:HBase的基本架构
master:
▫表的操作,例如修改列族配置等
▫region的分配,merge,分割
zookeeper:
▫维护服务器存活、是否可访问的状态
▫master的HA
▫记录HBase的元数据信息的存储位置
region server:数据的写入与查询
hdfs:数据的存储,region不直接跟磁盘打交道,通过hdfs实现数据的落盘和读取
3、数据的写入
3.1 数据的写入过程
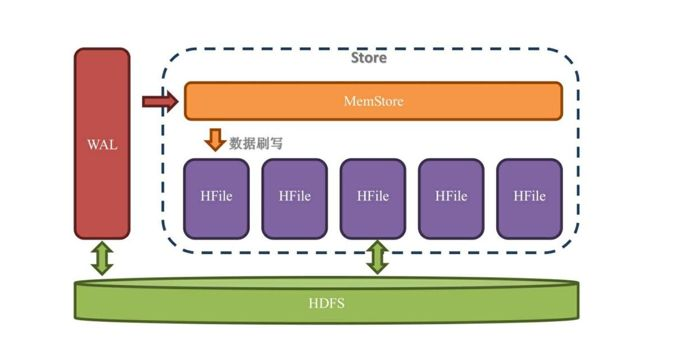
图:数据的写入概览
WAL:write ahead log,数据首先写入log,保证数据不丢失,该log也是保存在hdfs上
MemStore:数据进入内存,按照rowkey进行排序
HFile:MemStore中的数据到达一定量或者一定时间,创建HFile落盘
3.2、数据格式
HBase存储的所有内容都是byte数组,所以只要能转化成byte数组的数据都可以存储在HBase中。
4、存储模型
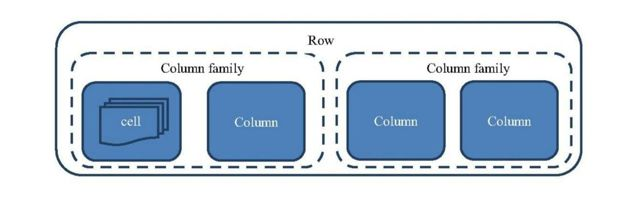
图:HBase的存储概念模型
表:一个表由一个或者多个列族构成
行:一个行包含多个列,列通过列族进行分类,每一行都有唯一主键rowkey
列族:列族包含若干列,这些列在物理上存储在一起,所以列族内的列一般是在查询的时候需要一起读取。数据的属性,例如超时时间、压缩算法等,都需要在列族上定义
列:一个行包含多个列,多个列维护在一个或者多个列族中
单元格:列的内容保存在单元格中,如果有过更新操作,会有多个版本
5、存储实现
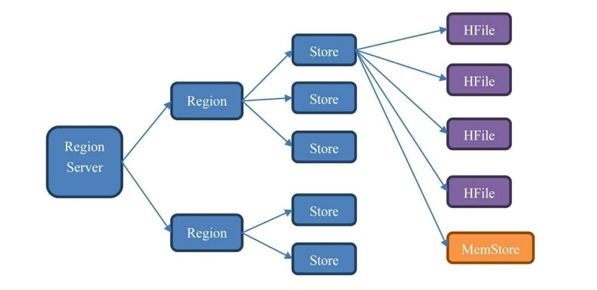
图:HBase的存储结构
5.1 region
Table的数据以region的形式分布在所有的服务器上。region的存在是为了解决横向扩展问题。
5.1.1 region的拆分
通过将数据均衡的分布到所有机器上,可以充分利用各个服务器的能力,提高查询速度。随着数据的不断写入,region会不断增大,region太大会影响查询性能,所以hbase会自动对region进行拆分。
下面是两种常见的region的拆分策略:
ConstantSizeRegionSplitPolicy:老版本的Hbase使用的拆分策略,按照固定的大小进行拆分,默认为10G。缺点:太死板、太简单,无论是数据写入量大还是小,都是通过这个固定的值来判断
IncreasingToUpperBoundRegionSplitPolicy:新版本的默认策略,这个策略能够随着数据增长,动态改变拆分的阈值。
5.1.2 region的merge
场景:region中大量数据被删除,不需要开始那么多region,可以手动进行region的merge
5.2 store
一个region内部有多个store,store是列族级别的概念,一个表有三个列族,那么在一台服务器上的region中会有三个store。
5.2.1 MemStore
每个列族/store对应一个独立的MemStore,也就是一块内存空间,数据写入之后,列族的内容进入对应的MemStore,会按照rowkey进行排序,并创建类似于Btree的索引——LMS-Tree。
LMS-Tree(Log-Structured Merge Tree)
LMS树采用的索引结构与B+Tree相同,而且通过批量存储技术规避磁盘随机写入问题,因为数据过来之后,首先会在内存中进行排序,构建索引,当到达一定的量的时候,flush到磁盘中,随着磁盘中的小文件的增多,后台进行会自动进行合并,过多的小文件合并为一个大文件,能够有效加快查询速度。
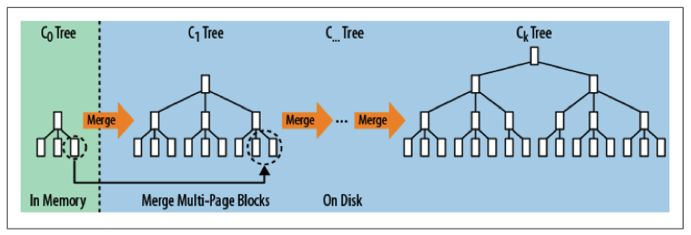
图:LMS树的合并
flush时机:
大小达到刷写阀值
整个RegionServer的memstore总和达到阀值
Memstore达到刷写时间间隔
WAL的数量大于maxLogs
手动触发flush
5.2.2 HFile
HBase的数据文件,HBase的所有数据都保存在HFile中,查询的时候也是从HFile中进行查询。
HFile包含多个数据块,存储了一个列族内的数据,以及相关的索引:
scan block:scan查询的时候需要读取的部分
▫data block:数据KV存储
▫leaf index block:Btree的叶子节点
▫bloom block:布隆过滤器
none scan block
▫meta block
▫intermediate index block:Btree的中间节点
load on open:HFile加载的时候,需要加载到内存的部分
▫root index block:Btree的根节点
▫meta index
▫file info
▫bloom filter metadata:布隆过滤器的索引
trailer:记录上面各个部分的偏移量,HFile读取的时候首先读取该部分,然后获取其他部分所在的位置
Hfile的compaction:
每次memstore的刷写都会产生一个新的HFile,而HFile毕竟是存储在硬盘上的东西,凡是读取存储在硬盘上的东西都涉及一个操作:寻址,如果是传统硬盘那就是磁头的移动寻址,这是一个很慢的动作。当HFile一多,每次读取数据的时候寻址的动作变多,查询速度也就变慢。所以为了防止寻址的动作过多,需要适当地减少碎片文件,后台需要持续进行compaction操作。
compaction的分类:
小compaction:小的HFile的合并成大的
大compaction:大的最终合并成一个,注意:只有在大compaction之后,标记删除的文档才会真正被删除
compaction的过程:
读取compaction列表中的hfile
创建数据读取的scanner
读取hfile中的内容到一个临时文件中
临时文件替换compaction之前的多个hfile
6、数据查询
6.1 查询顺序
1. 首先查找block cache:HFile的load on open部分是常驻内存的,data block是在磁盘上的,查询的时候,定位到某个data block之后,HBase会将整个data block加载到block cache中,后续查询的时候,先检查是否存在block cache中,如果是,优先查询block cache。之所以可以这么放心的使用block cache,是基于Hfile的不可变性,后续的修改和删除操作不会直接修改HFile,而是追加新的文件,所以只要HFile还在,对应的block cache就是不变的。
2. block cache查询不到再去查找region(memstore + hfile):通过hbase的元数据表,找到需要查询的rowkey所在的region server,从而定位到memstore和hfile
6.2 region的查找过程
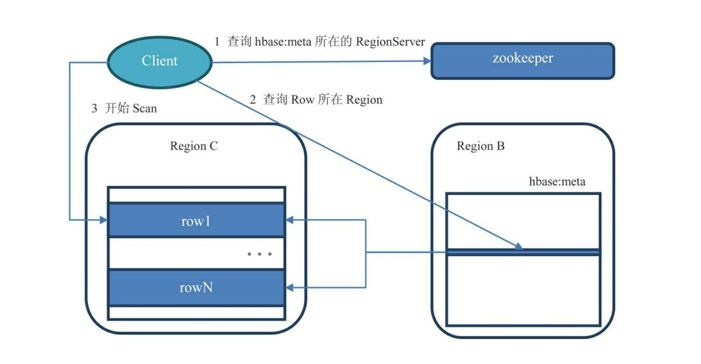
图:region的查找过程
一个表有多个region,分布在不同机器上,需要一定的机制来确定需要查找的region
通过zk找到meta所在的sever:meta表的位置保存在zk中,meta中保存了每个region的rowkey范围,以及region所在的位置
通过meta查询出需要查询的region所在的服务器
到服务器上进行查询
客户端会对meta信息进行缓存,加快查询速度。
6.3 查询API
get:查询某个rowkey对应的列
scan:指定rowkey范围的扫描(setStartRow, setStopRow)
filter:scan过程中,对内容进行过滤
其中指定rowkey范围是最有效的加快查询速度的方式,不限定rowkey的范围则需要全表扫
7 Ad Tracking的HBase设计
rowkey结构:分区key-pid-eventTime-spreadid-序列
分区key:应用的唯一key(随机字符串)的hashcode / hbase的region个数
pid:应用的自增唯一主键
eventTime:事件的时间
spreadid:推广活动的自增唯一主键
序列:随机序列,保证上述字段相同的事件不会覆盖写入
Ad Tracking的hbase的rowkey是按照业务字段来设计的,相同应用的数据保存在同一个region中,查询快,但是由于用户的数据量不同,查询量也不同,可能导致热点数据,造成某台机器负载过高,影响机群正常工作。目前Ad Tracking的HBase的各个region空间占用尚存在一定程度的不均衡,但是还能接受。
一般HBase的rowkey中或多或少的会包含业务相关的信息,完全采用随机的rowkey,跟业务不相关,查询的时候只能全表扫,查询效率低。rowkey设计的关键就在于权衡查询速度和数据均衡之间的关系,下面介绍几方面rowkey的设计建议。
7.1 rowkey长度设计建议
数据的持久化文件 HFile 中是按照 KeyValue 存储的,如果 rowkey 过长,比如超过 100 字节,1000w 行数据,光 rowkey 就要占用 100*1000w=10 亿个字节,将近 1G 数据,这样会极大影响 HFile 的存储效率;
MemStore 将缓存部分数据到内存,如果 rowkey 字段过长,内存的有效利用率就会降低,系统不能缓存更多的数据,这样会降低检索效率;
目前操作系统大都是 64 位系统,内存 8 字节对齐,rowkey长度建议控制在 16 个字节(8 字节的整数倍),充分利用操作系统的最佳特性。
7.2 rowkey设计方式-加盐
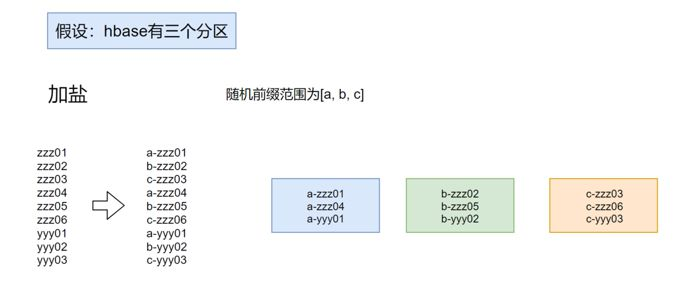
图:rowkey设计方式-加盐
使用固定的随机前缀:
优点:数据均衡
缺点:因为前缀是随机的,所以无法快速get;而scan的速度还可以
7.3 rowkey设计方式-hash
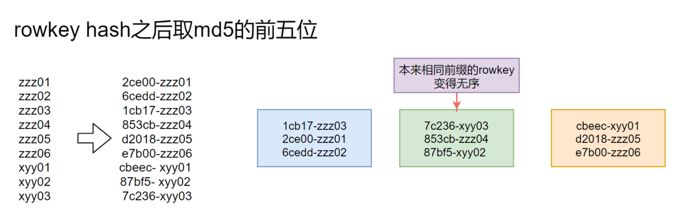
图:rowkey设计方式-哈希
rowkey hash之后取md5的前五位:
优点:打散数据,前缀在查询的时候能通过rowkey得到,可以很快get
缺点:相同前缀的rowkey被打散,scan变慢
7.4 rowkey设计方式-反转
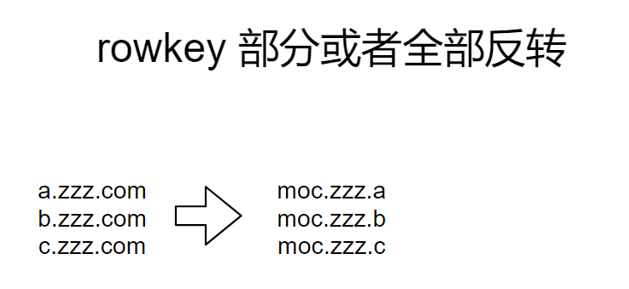
图:rowkey设计方式-反转
反转一段固定长度的rowkey,或者整个反转。上图中三个网址属于相同域名下的,但是如果不反转,会完全分散到不同的region中,不利于查询。
end
参考资料
- [hbase-io-hfile-input-output](http://blog.cloudera.com/blog/2012/06/hbase-io-hfile-input-output/)
- [深入理解HBase的系统架构](https://blog.csdn.net/Yaokai_AssultMaster/article/details/72877127)
- [HBase底层存储原理](https://www.cnblogs.com/panpanwelcome/p/8716652.html)
- [HBase – 探索HFile索引机制](http://hbasefly.com/2016/04/03/hbase_hfile_index/)
- [HBase – 存储文件HFile结构解析](
http://hbasefly.com/2016/03/25/hbase-hfile/)
作者: TalkingData 战鹏弘
