

如何用Golang实现一个简单的ForkJoin框架
扔上我的项目地址
简易原理
-
什么是ForkJoin
接触到
ForkJoin框架是因为学习Java中的Stream中的并行流,并行流的底层就是借助ForkJoin框架ForkJoin框架更适合现在CPU多核的机器,一般用于处理可以将一个大任务分解成数个互相没有依赖性的小任务,利用分治的策略,将任务不断变小,将这些小任务分发到CPU的核中,将子任务并行运行,大大加快任务处理速度具体的很多博客上说的都很不错,这里也不细说了,给几个我当时学习的博客地址吧
-
任务偷窃
任务偷窃算法其实就是
Worker可以从自己对应的工作队列头部或者其他Worker的工作队列尾部获取元素。每次在轮询任务队列时,先从每个
Worker对应的任务队列中去获取任务,如果发现任务队列此时没有待处理的任务,那么这个时候就会采用随机选取策略,随机选择一个Worker对应的工作队列,去窃取它的任务 -
Join子任务结果
在Java中需要去不断的获取任务的执行情况,如果任务执行完就返回任务处理的结果;而在Golang中,由于chan的存在,使得Java的Future模式非常容易实现,只需要任务Join的时候去读取通道就可以,因为当我们把chan的cap设置为1时,如果通道中没有数据,读取一方是会被阻塞等待的
func (f *ForkJoinTask) Join() (bool, interface{}) {
for {
select {
case data, ok := <-f.result:
if ok {
return true, data
}
case <-f.ctx.Done():
panic(f.taskPool.err)
}
}
}
核心代码
任务队列
对任务队列进行遍历操作。任务队列不止一个,而是存在多个任务队列,每次都会从这些任务队列中获取一个任务出来,如果任务存在则将任务包装成一个结构体;在获取到任务后,就是获取一个任务的执行者worker了,随后将包装好的任务送入Worker的chan通道中异步发送任务
func (fp *ForkJoinPool) run(ctx context.Context) {
go func() {
wId := int32(0)
for {
select {
case <-ctx.Done():
fmt.Printf("here is err")
fp.err = fp.wp.err
return
default:
hasTask, job, ft := fp.taskQueue.dequeueByTali(wId)
if hasTask {
fp.wp.Submit(ctx, &struct {
T Task
F *ForkJoinTask
C context.Context
}{T: job, F: ft, C: ctx})
}
wId = (wId + 1) % fp.cap
}
}
}()
}
获取一个Worker
在ForkJoin初始化的时候,根据CPU核数对Worker池进行初始化操作
func newPool(ctx context.Context, cancel context.CancelFunc) *Pool {
...
wCnt := runtime.NumCPU()
for i := 0; i < wCnt; i ++ {
w := newWorker(p)
w.run(ctx)
p.workers = append(p.workers, w)
}
...
}
随后,处理任务肯定需要一个对应的worker去执行的,因此每次在获取worker时,会先去worker池中判断是否还存在空闲的worker,如果存在就直接获取一个worker,否则直接创建一个worker进行接受任务
func (p *Pool) retrieveWorker(ctx context.Context) *Worker {
var w *Worker
idleWorker := p.workers
if len(idleWorker) >= 1 {
p.lock.Lock()
n := len(idleWorker) - 1
w = idleWorker[n]
p.workers = idleWorker[:n]
p.lock.Unlock()
} else {
if cacheWorker := p.workerCache.Get(); cacheWorker != nil {
w = cacheWorker.(*Worker)
} else {
w = &Worker{
pool: p,
job: make(chan *struct {
T Task
F *ForkJoinTask
C context.Context
}, 1),
}
}
w.run(ctx)
}
return w
}
Worker
真正执行任务的对象,每个worker绑定一个goruntine,并且有一个chan通道,用于异步接收任务以及在goruntine中异步将任务取出并执行;当任务执行完后,将worker返回到worker池中
func (w *Worker) run(ctx context.Context) {
go func() {
var tmpTask *ForkJoinTask
defer func() {
if p := recover(); p != nil {
w.pool.panicHandler(p)
if tmpTask != nil {
w.pool.err = p
close(tmpTask.result)
}
}
}()
for {
select {
case <-ctx.Done():
fmt.Println("An exception occurred and the task has stopped")
return
default:
for job := range w.job {
if job == nil {
w.pool.workerCache.Put(w)
return
}
tmpTask = job.F
job.F.result <- job.T.Compute()
w.pool.releaseWorker(w)
}
}
}
}()
}
成果
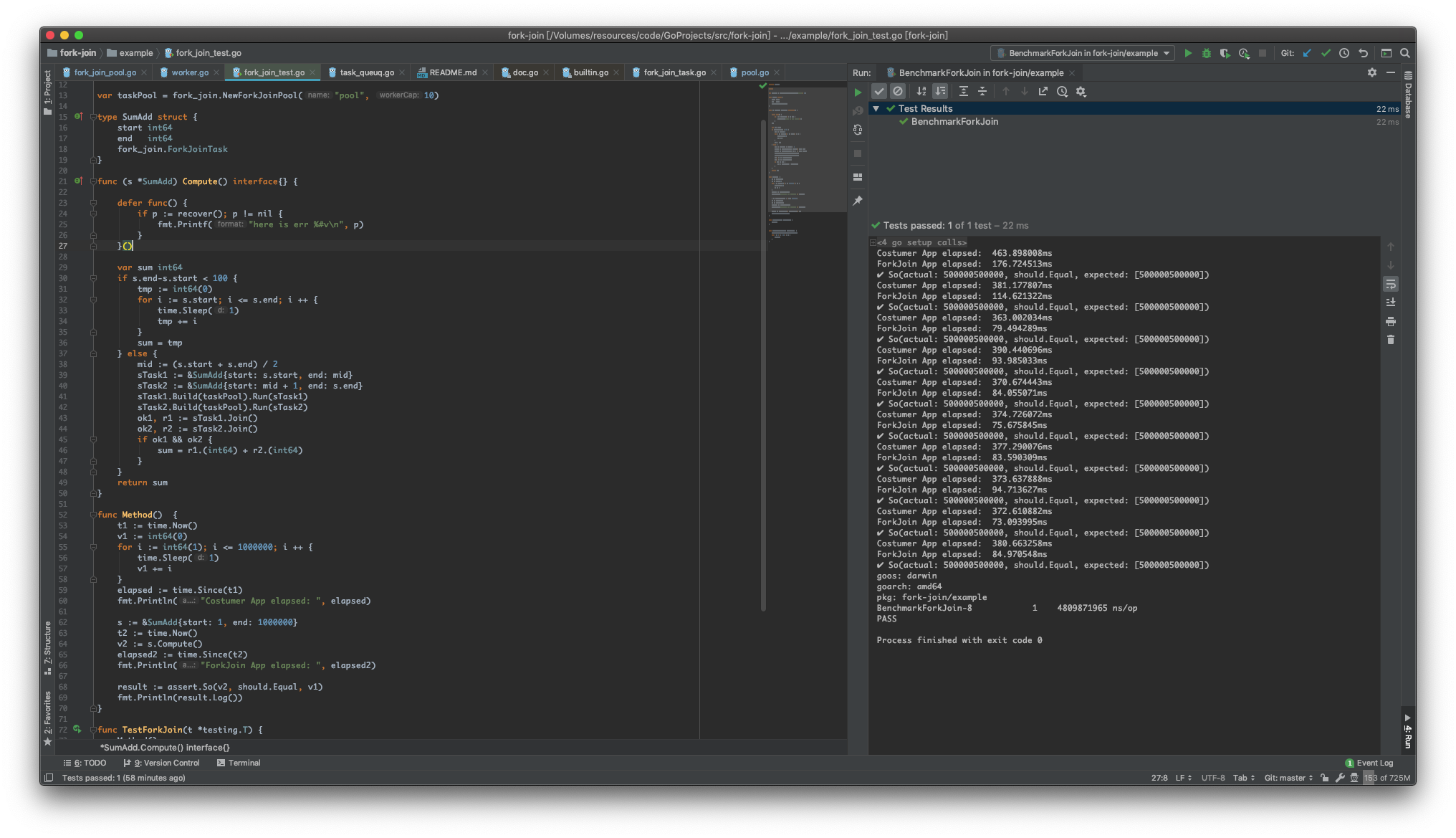
正在改进的地方
-
任务偷窃算法
目前v0.1的任务偷窃算法并不能说像Java的ForkJoin那样,支持两个worker同时从一个队列中获取任务,而是在获取任务的时候锁住整个队列,因此并发性能不太好,目前正在采用CAS去替换悲观锁,实现两个Worker可同时读取一个队列中的数据,如果两
Worker同时向一个长度只有1的任务队列获取元素,则乐观锁上升为悲观锁进行控制 -
Worker数量控制
目前的Worker数量会随着任务的不断分解而不断创建,如果任务分解过深可能会导致创建大量的
Worker,因此还需要继续理解ForkJoin的关于线程资源的调度
