

#回顾 由上一篇文章知道:通过python代码向服务器发送request,然后通过获取response就可以获取到网页的内容了。那么python如何向网站发起请求呢?这个过程又是如何实现的呢?
Urllib
python的Urllib库为我们实现了想浏览器发起请求的过程,Urllib是python内置的一个http请求库(不需要额外的手动安装),除了发起request,Urllib还提供了比较强大的url解析函数。

其中:
- request模块是用来模拟人工点击,向网站发起request
- err是异常处理模块:如果出现请求错误。可以捕捉这个异常,然后进行重试或者其他操作,保证程序不会意外的终止。
- parse是一个根据模块,提供了很多URL处理方法:拆分合并之类的
- robotparser:主要是依赖识别网站的robots.txt文件,然后判断哪些网站是可以爬去的,哪些是不可以爬取的,使用的比较少。
import urllib.requst
response = urllib.request.urlopen('http://www.baidu.com')
urllib其实不太好用,后面会介绍其他更好用的库:它是基于Urllib库来实现的。urllib作为最基本的请求库,这里还是介绍一下urllib库的基本原理和使用。
##request.urlopen()函数介绍 urllib.request.urlopen( url, data=None, [timeout, ]*, cafile=None, capath=None, cadefault=False, context=None )
其中
- url: 需要打开的网址
- data:Post提交的数据,应该是byte类型的数据
- timeout:设置网站的访问超时时间
###urlopen返回的response对象提供方法: - read() , readline() ,readlines() , fileno() , close() :对HTTPResponse类型数据进行操作,返回的是byte类型的数据,需要使用decode方法转换为字符串,获取响应体的内容 - info():返回HTTPMessage对象,表示远程服务器返回的头信息 - getcode():返回Http状态码。如果是http请求,200请求成功完成 ; 404网址未找到 - geturl():返回请求的url
####案例:
- 测试get请求
from urllib import request
response = request.urlopen('http://www.baidu.com')
print(response.read().decode('utf-8'))
上面代码打印出来的是浏览器访问“www.baidu.com”时返回的第一个html页面:
注:如果你在浏览器中看不到上面的源代码,可以清除cookie试试
2.测试post请求
from urllib import request
from urllib import parse
#request.urlopean(url,data,)
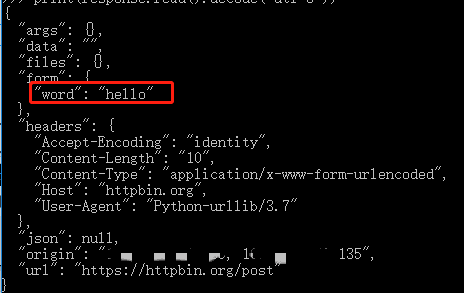
data = bytes(parse.urlencode({'word':'hello'}),encoding='utf-8')
response = request.urlopen('http://httpbin.org/post',data=data);#这是一个HTTP测试网站
print(response.read().decode('utf-8'))
上面代码的输出的是json格式:
3.超时设置:在规定时间没有得到响应就会抛出异常
from urllib import request
response = request.urlopen('http://httpbin.org/get',timeout=0.1);#这是一个HTTP测试网站,超时时间设置为0.1秒
print(response.read().decode('utf-8'))
上面代码会报异常:socket.timeout: timed out
下面代码输出的是:TimeOut
from urllib import request
from urllib import error
import socket
try:
response = request.urlopen('http://httpbin.org/get',timeout=0.1);#超时0.1s
except error.URLError as e:
if isinstance(e.reason,socket.timeout):
print('TimeOut')
上面是urlopen使用,即发如何发起request请求,下面介绍response相关知识点
#response
- response的类型:
from urllib import request
response = request.urlopen('http://www.python.org');
print(type(response))
输出的结果是: 打印出来的是: class 'http.client.HTTPResponse'
2.response中的主要成员:状态码和响应头
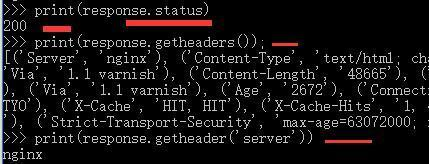
from urllib import request
response = request.urlopen('http://www.python.org');
print(response.status)
print(response.getheaders());
print(response.getheader('server'))#获取响应头中的某一个取值
输出结果:
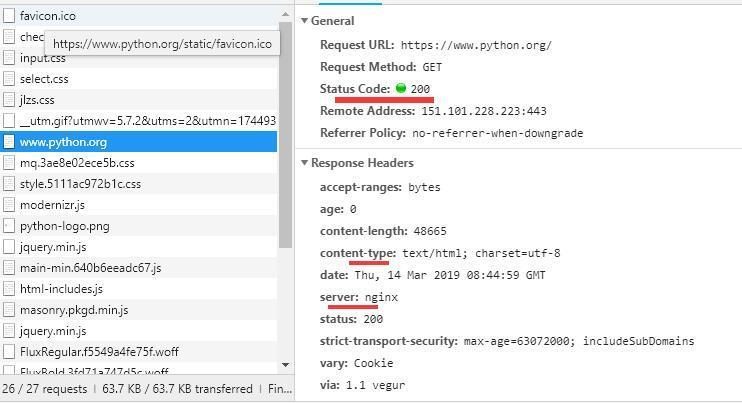
上面结果对应浏览器的下面结果:
3.获取response响应体的内容
from urllib import request
response = request.urlopen('http://www.python.org');
print(response.read.decode('utf-8'))
输出的内容在文章开头的get请求中以已经介绍了
#Request对象
- urlopen可以传入一个Request对象,我们可以在Request对象中配置header,method等

执行结果:

另外一种添加header的方式:

#代理:Handle
- 可以通过代理伪装自己的IP,爬取数据的时候服务器获取到的是代理的IP地址:
from urllib import request
proxy_handle = request.ProxyHandle({
‘http':http://代理ip
'https':https://代理IP
})
opener = request.builder_opener(proxy_handle)
response = opener.open('www.baidu.com')
##cookie 在爬虫中,cookie主要是用来维持用户账号的登录状态 1.cookie的获取
#---------------获取cookie
from http import cookiejar
from urllib import request
cookie = cookiejar.CookieJar()
handler = request.HTTPCookieProcessor(cookie)
opener = request.build_opener(handler)
response = opener.open('http://www.baidu.com')
for item in cookie:
print(item.name+' = '+item.value)
2.**cookie保存:**因为cookie可以用来保持登录信息的,所以可以把cookie保存成文本文件。如果cookie没有失效,我们可以从文件读取cookie,并将cookie附加在request中:
#---------------保存cookie
from http import cookiejar
from urllib import request
filename= 'cookie.txt'
cookie = cookiejar.MozillaCookieJar(filename)
handler = request.HTTPCookieProcessor(cookie)
opener = request.build_opener(handler)
response = opener.open('http://www.baidu.com')
cookie.save(ignore_discard=True,ignore_expires=True)
3.cookie:cookie可以保存成不同的格式,但是这不太重要,你使用什么格式存储的就使用什么格式读取就好,下面是另外一种cookie保存格式,主要是类
#---------------保存cookie另外一种格式
from http import cookiejar
from urllib import request
filename= 'cookie.txt'
cookie = cookiejar.LWPCookieJar(filename)
handler = request.HTTPCookieProcessor(cookie)
opener = request.build_opener(handler)
response = opener.open('http://www.baidu.com')
cookie.save(ignore_discard=True,ignore_expires=True)
- 装载cookie
#---------------读取cookie
from http import cookiejar
from urllib import request
filename= 'cookie.txt'
cookie = cookiejar.LWPCookieJar(filename)
cookie.load('cookie.txt',ignore_discard=True,ignore_expires=True);
handler = request.HTTPCookieProcessor(cookie)
opener = request.build_opener(handler)
response = opener.open('http://www.baidu.com')
print(response.read().decode('utf-8'))
#异常处理
from urllib import request,error
try:
response = request.urlopen('网址')#当网页不存在的时候,异常可以捕获到,程序不会终止退出
except error.URLError as e:
print(e.reason)
上面的异常也可以像java那样分类捕捉异常,主要有三个error: 1.URLError 2.HTTPError(URLError的子类) 3.ContentTooShortError
#parse,URL解析
from urllib.parse import urlparse
result = urlparse('http://www.baidu.com/index.html;user?id=5#comment')
print(type(result,result))
type:class 'urllib.parse.ParseResult' result: scheme='http', netloc='www.baidu.com', path='/index.html', params='user', query='id=5', fragment='comment'
- urlparse:url的切分
- urlunparse:将几部分字符串合成一个url
from urllib.parse import urunlparse
data = ['http','www.baidu.com','index.html','a=6','comment']
print(urlunparse(data))
#http://www.baidu.com/index.html?a=6#comment
- url拼接:urljoin,urlencode
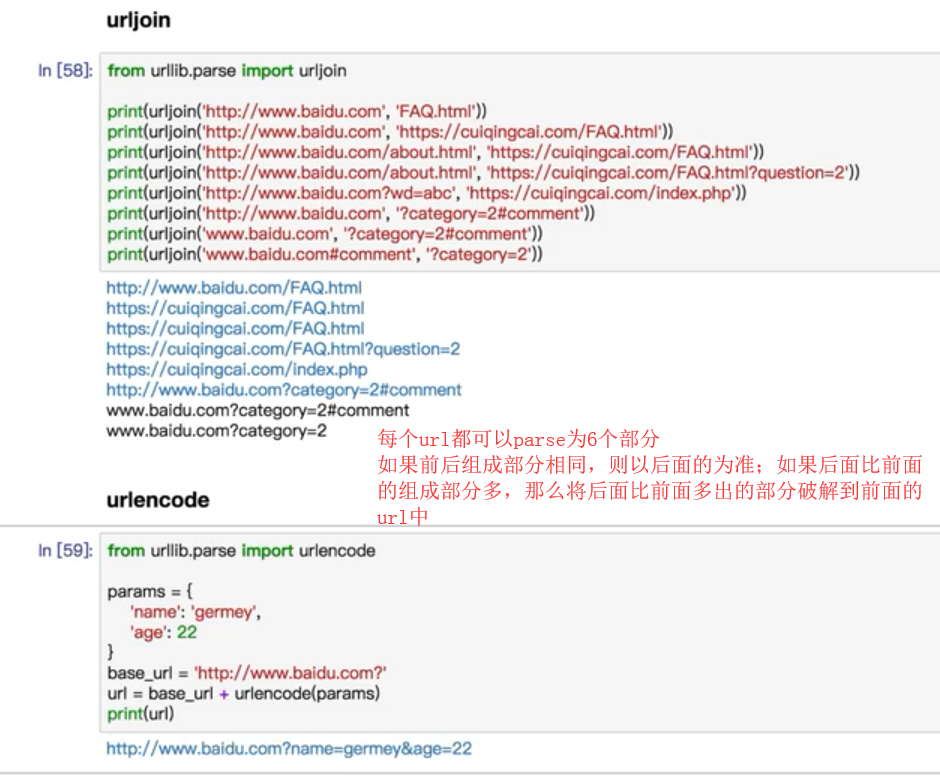
urlencode将以字典形式组织的参数拼接到url上
资料分享
欢迎关注个人公众号【菜鸟名企梦】,公众号专注:互联网求职面经、java、python、爬虫、大数据等技术分享**:
公众号**菜鸟名企梦后台发送“csdn”即可免费领取【csdn】和【百度文库】下载服务;
公众号菜鸟名企梦后台发送“资料”:即可领取5T精品学习资料**、java面试考点和java面经总结,以及几十个java、大数据项目,资料很全,你想找的几乎都有

