

前言
其实Transform API在一个android工程的打包流程中作用非常大, 像是我们熟知的混淆处理, 类文件转dex文件的处理, 都是通过Transform API去完成的.
本篇内容主要围绕Transform做展开:
Transform API的使用及原理- 字节码处理框架
ASM使用技巧 Transform API在应用工程上的使用摸索
Transform的使用及原理
什么是Transform
自从1.5.0-beta1版本开始, android gradle插件就包含了一个Transform API, 它允许第三方插件在编译后的类文件转换为dex文件之前做处理操作.
而使用Transform API, 我们完全可以不用去关注相关task的生成与执行流程, 它让我们可以只聚焦在如何对输入的类文件进行处理
Transform的使用
Transform的注册和使用非常易懂, 在我们自定义的plugin内, 我们可以通过android.registerTransform(theTransform)或者android.registerTransform(theTransform, dependencies).就可以进行注册.
class DemoPlugin: Plugin<Project> {
override fun apply(target: Project) {
val android = target.extensions.findByType(BaseExtension::class.java)
android?.registerTransform(DemoTransform())
}
}
而我们自定义的Transform继承于com.android.build.api.transform.Transform, 具体我们可以看javaDoc, 以下代码是比较常见的transform处理模板
class DemoTransform: Transform() {
/**
* transform 名字
*/
override fun getName(): String = "DemoTransform"
/**
* 输入文件的类型
* 可供我们去处理的有两种类型, 分别是编译后的java代码, 以及资源文件(非res下文件, 而是assests内的资源)
*/
override fun getInputTypes(): MutableSet<QualifiedContent.ContentType> = TransformManager.CONTENT_CLASS
/**
* 是否支持增量
* 如果支持增量执行, 则变化输入内容可能包含 修改/删除/添加 文件的列表
*/
override fun isIncremental(): Boolean = false
/**
* 指定作用范围
*/
override fun getScopes(): MutableSet<in QualifiedContent.Scope> = TransformManager.SCOPE_FULL_PROJECT
/**
* transform的执行主函数
*/
override fun transform(transformInvocation: TransformInvocation?) {
transformInvocation?.inputs?.forEach {
// 输入源为文件夹类型
it.directoryInputs.forEach {directoryInput->
with(directoryInput){
// TODO 针对文件夹进行字节码操作
val dest = transformInvocation.outputProvider.getContentLocation(
name,
contentTypes,
scopes,
Format.DIRECTORY
)
file.copyTo(dest)
}
}
// 输入源为jar包类型
it.jarInputs.forEach { jarInput->
with(jarInput){
// TODO 针对Jar文件进行相关处理
val dest = transformInvocation.outputProvider.getContentLocation(
name,
contentTypes,
scopes,
Format.JAR
)
file.copyTo(dest)
}
}
}
}
}
每一个Transform都声明它的作用域, 作用对象以及具体的操作以及操作后输出的内容.
作用域
通过Transform#getScopes方法我们可以声明自定义的transform的作用域, 指定作用域包括如下几种
| QualifiedContent.Scope | |
|---|---|
| EXTERNAL_LIBRARIES | 只包含外部库 |
| PROJECT | 只作用于project本身内容 |
| PROVIDED_ONLY | 支持compileOnly的远程依赖 |
| SUB_PROJECTS | 子模块内容 |
| TESTED_CODE | 当前变体测试的代码以及包括测试的依赖项 |
作用对象
通过Transform#getInputTypes我们可以声明其的作用对象, 我们可以指定的作用对象只包括两种
| QualifiedContent.ContentType | |
|---|---|
| CLASSES | Java代码编译后的内容, 包括文件夹以及Jar包内的编译后的类文件 |
| RESOURCES | 基于资源获取到的内容 |
TransformManager整合了部分常用的Scope以及Content集合,
如果是application注册的transform, 通常情况下, 我们一般指定TransformManager.SCOPE_FULL_PROJECT;如果是library注册的transform, 我们只能指定TransformManager.PROJECT_ONLY , 我们可以在LibraryTaskManager#createTasksForVariantScope中看到相关的限制报错代码
Sets.SetView<? super Scope> difference =
Sets.difference(transform.getScopes(), TransformManager.PROJECT_ONLY);
if (!difference.isEmpty()) {
String scopes = difference.toString();
globalScope
.getAndroidBuilder()
.getIssueReporter()
.reportError(
Type.GENERIC,
new EvalIssueException(
String.format(
"Transforms with scopes '%s' cannot be applied to library projects.",
scopes)));
}
而作用对象我们主要常用到的是TransformManager.CONTENT_CLASS
TransformInvocation
我们通过实现Transform#transform方法来处理我们的中间转换过程, 而中间相关信息都是通过TransformInvocation对象来传递
public interface TransformInvocation {
/**
* transform的上下文
*/
@NonNull
Context getContext();
/**
* 返回transform的输入源
*/
@NonNull
Collection<TransformInput> getInputs();
/**
* 返回引用型输入源
*/
@NonNull Collection<TransformInput> getReferencedInputs();
/**
* 额外输入源
*/
@NonNull Collection<SecondaryInput> getSecondaryInputs();
/**
* 输出源
*/
@Nullable
TransformOutputProvider getOutputProvider();
/**
* 是否增量
*/
boolean isIncremental();
}
关于输入源, 我们可以大致分为消费型和引用型和额外的输入源
消费型就是我们需要进行transform操作的, 这类对象在处理后我们必须指定输出传给下一级, 我们主要通过getInputs()获取进行消费的输入源, 而在进行变换后, 我们也必须通过设置getInputTypes()和getScopes()来指定输出源传输给下个transform.- 引用型输入源是指我们不进行transform操作, 但可能存在查看时候使用, 所以这类我们也不需要输出给下一级, 在通过覆写
getReferencedScopes()指定我们的引用型输入源的作用域后, 我们可以通过TransformInvocation#getReferencedInputs()获取引用型输入源 - 另外我们还可以额外定义另外的输入源供下一级使用, 正常开发中我们很少用到, 不过像是
ProGuardTransform中, 就会指定创建mapping.txt传给下一级; 同样像是DexMergerTransform, 如果打开了multiDex功能, 则会将maindexlist.txt文件传给下一级
Transform的原理
Transform的执行链
我们已经大致了解它是如何使用的, 现在看下他的原理(本篇源码基于gradle插件3.3.2版本)在去年AppPlugin源码解析中, 我们粗略了解了android的com.android.application以及com.android.library两个插件都继承于BasePlugin, 而他们的主要执行顺序可以分为三个步骤
- project的配置
- extension的配置
- task的创建
在BaseExtension内部维护了一个transforms集合对象,
android.registerTransform(theTransform)实际上就是将我们自定义的transform实例新增到这个列表对象中.
在3.3.2的源码中, 也可以这样理解. 在BasePlugin#createAndroidTasks中, 我们通过VariantManager#createAndroidTasks创建各个变体的相关编译任务, 最终通过TaskManager#createTasksForVariantScope(application插件最终实现方法在TaskManager#createPostCompilationTasks中, 而library插件最终实现方法在LibraryTaskManager#createTasksForVariantScope中)方法中获取BaseExtension中维护的transforms对象, 通过TransformManager#addTransform将对应的transform对象转换为task, 注册在TaskFactory中.这里关于一系列Transform Task的执行流程, 我们可以选择看下application内的相关transform流程, 由于篇幅原因, 可以自行去看相关源码, 这里的transform task流程分别是从Desugar->MergeJavaRes->自定义的transform->MergeClasses->Shrinker(包括ResourcesShrinker和DexSplitter和Proguard)->MultiDex->BundleMultiDex->Dex->ResourcesShrinker->DexSplitter, 由此调用链, 我们也可以看出在处理类文件的时候, 是不需要去考虑混淆的处理的.
TransformManager
TransformManager管理了项目对应变体的所有Transform对象, 它的内部维护了一个TransformStream集合对象streams, 每当新增一个transform, 对应的transform会消费掉对应的流, 而后将处理后的流添加会streams内
public class TransformManager extends FilterableStreamCollection{
private final List<TransformStream> streams = Lists.newArrayList();
}
我们可以看下它的核心方法addTransform
@NonNull
public <T extends Transform> Optional<TaskProvider<TransformTask>> addTransform(
@NonNull TaskFactory taskFactory,
@NonNull TransformVariantScope scope,
@NonNull T transform,
@Nullable PreConfigAction preConfigAction,
@Nullable TaskConfigAction<TransformTask> configAction,
@Nullable TaskProviderCallback<TransformTask> providerCallback) {
...
List<TransformStream> inputStreams = Lists.newArrayList();
// transform task的命名规则定义
String taskName = scope.getTaskName(getTaskNamePrefix(transform));
// 获取引用型流
List<TransformStream> referencedStreams = grabReferencedStreams(transform);
// 找到输入流, 并计算通过transform的输出流
IntermediateStream outputStream = findTransformStreams(
transform,
scope,
inputStreams,
taskName,
scope.getGlobalScope().getBuildDir());
// 省略代码是用来校验输入流和引用流是否为空, 理论上不可能为空, 如果为空, 则说明中间有个transform的转换处理有问题
...
transforms.add(transform);
// transform task的创建
return Optional.of(
taskFactory.register(
new TransformTask.CreationAction<>(
scope.getFullVariantName(),
taskName,
transform,
inputStreams,
referencedStreams,
outputStream,
recorder),
preConfigAction,
configAction,
providerCallback));
}
在TransformManager中添加一个Transform管理, 流程可分为以下几步
- 定义transform task名
static String getTaskNamePrefix(@NonNull Transform transform) {
StringBuilder sb = new StringBuilder(100);
sb.append("transform");
sb.append(
transform
.getInputTypes()
.stream()
.map(
inputType ->
CaseFormat.UPPER_UNDERSCORE.to(
CaseFormat.UPPER_CAMEL, inputType.name()))
.sorted() // Keep the order stable.
.collect(Collectors.joining("And")));
sb.append("With");
StringHelper.appendCapitalized(sb, transform.getName());
sb.append("For");
return sb.toString();
}
从上面代码, 我们可以看到新建的transform task的命名规则可以理解为transform${inputType1.name}And${inputType2.name}With${transform.name}For${variantName}, 对应的我们也可以通过已生成的transform task来验证
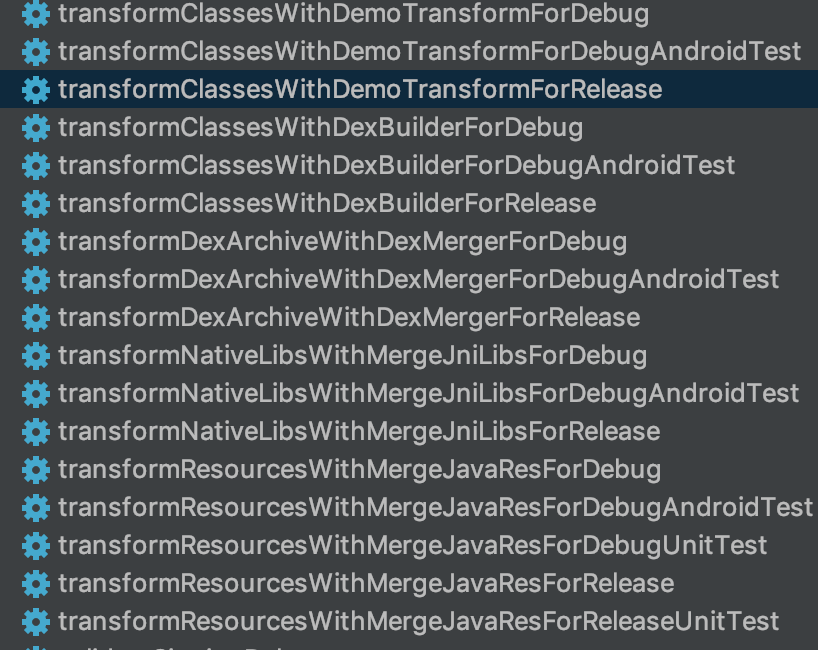
streams作用域和作用类型的交集来获取对应的流, 将其定义为我们需要的引用型流
private List<TransformStream> grabReferencedStreams(@NonNull Transform transform) {
Set<? super Scope> requestedScopes = transform.getReferencedScopes();
...
List<TransformStream> streamMatches = Lists.newArrayListWithExpectedSize(streams.size());
Set<ContentType> requestedTypes = transform.getInputTypes();
for (TransformStream stream : streams) {
Set<ContentType> availableTypes = stream.getContentTypes();
Set<? super Scope> availableScopes = stream.getScopes();
Set<ContentType> commonTypes = Sets.intersection(requestedTypes,
availableTypes);
Set<? super Scope> commonScopes = Sets.intersection(requestedScopes, availableScopes);
if (!commonTypes.isEmpty() && !commonScopes.isEmpty()) {
streamMatches.add(stream);
}
}
return streamMatches;
}
- 根据transform内定义的SCOPE和INPUT_TYPE, 获取对应的消费型输入流, 在streams内移除掉这一部分消费性的输入流, 保留无法匹配SCOPE和INPUT_TYPE的流; 构建新的输出流, 并加到streams中做管理
private IntermediateStream findTransformStreams(
@NonNull Transform transform,
@NonNull TransformVariantScope scope,
@NonNull List<TransformStream> inputStreams,
@NonNull String taskName,
@NonNull File buildDir) {
Set<? super Scope> requestedScopes = transform.getScopes();
...
Set<ContentType> requestedTypes = transform.getInputTypes();
// 获取消费型输入流
// 并将streams中移除对应的消费型输入流
consumeStreams(requestedScopes, requestedTypes, inputStreams);
// 创建输出流
Set<ContentType> outputTypes = transform.getOutputTypes();
// 创建输出流转换的文件相关路径
File outRootFolder =
FileUtils.join(
buildDir,
StringHelper.toStrings(
AndroidProject.FD_INTERMEDIATES,
FD_TRANSFORMS,
transform.getName(),
scope.getDirectorySegments()));
// 输出流的创建
IntermediateStream outputStream =
IntermediateStream.builder(
project,
transform.getName() + "-" + scope.getFullVariantName(),
taskName)
.addContentTypes(outputTypes)
.addScopes(requestedScopes)
.setRootLocation(outRootFolder)
.build();
streams.add(outputStream);
return outputStream;
}
- 最后, 创建TransformTask, 注册到TaskManager中
TransformTask
如何触发到我们实现的Transform#transform方法, 就在TransformTask对应的TaskAction中执行
void transform(final IncrementalTaskInputs incrementalTaskInputs)
throws IOException, TransformException, InterruptedException {
final ReferenceHolder<List<TransformInput>> consumedInputs = ReferenceHolder.empty();
final ReferenceHolder<List<TransformInput>> referencedInputs = ReferenceHolder.empty();
final ReferenceHolder<Boolean> isIncremental = ReferenceHolder.empty();
final ReferenceHolder<Collection<SecondaryInput>> changedSecondaryInputs =
ReferenceHolder.empty();
isIncremental.setValue(transform.isIncremental() && incrementalTaskInputs.isIncremental());
GradleTransformExecution preExecutionInfo =
GradleTransformExecution.newBuilder()
.setType(AnalyticsUtil.getTransformType(transform.getClass()).getNumber())
.setIsIncremental(isIncremental.getValue())
.build();
// 一些增量模式下的处理, 包括在增量模式下, 判断输入流(引用型和消费型)的变化
...
GradleTransformExecution executionInfo =
preExecutionInfo.toBuilder().setIsIncremental(isIncremental.getValue()).build();
...
transform.transform(
new TransformInvocationBuilder(TransformTask.this)
.addInputs(consumedInputs.getValue())
.addReferencedInputs(referencedInputs.getValue())
.addSecondaryInputs(changedSecondaryInputs.getValue())
.addOutputProvider(
outputStream != null
? outputStream.asOutput(
isIncremental.getValue())
: null)
.setIncrementalMode(isIncremental.getValue())
.build());
if (outputStream != null) {
outputStream.save();
}
}
通过上文的介绍, 我们现在应该知道了自定义的Transform执行的时序, 位置, 以及相关原理. 那么, 我们现在已经拿到了编译后的所有字节码, 我们要怎么去处理呢? 我们可以了解下ASM
ASM的使用
想要处理字节码, 常见的框架有AspectJ, Javasist, ASM. 关于框架的选型网上相关的文章还是比较多的, 从处理速度以及内存占用率上, ASM明显优于其他两个框架.本篇主要着眼于ASM的使用.
什么是ASM
ASM是一个通用的Java字节码操作和分析框架。它可以用于修改现有类或直接以二进制形式动态生成类. ASM提供了一些常见的字节码转换和分析算法,可以从中构建自定义复杂转换和代码分析工具.
ASM库提供了两个用于生成和转换编译类的API:Core API提供基于事件的类表示,而Tree API提供基于对象的表示。由于基于事件的API(Core API)不需要在内存中存储一个表示该类的对象数, 所以从执行速度和内存占用上来说, 它比基于对象的API(Tree API)更优.然后从使用场景上来说, 基于事件的API使用会比基于对象的API使用更为困难, 譬如当我们需要针对某个对象进行调整的时候.由于一个类只能被一种API管理, 所以我们应该要区分场景选取使用对应的API
ASM插件
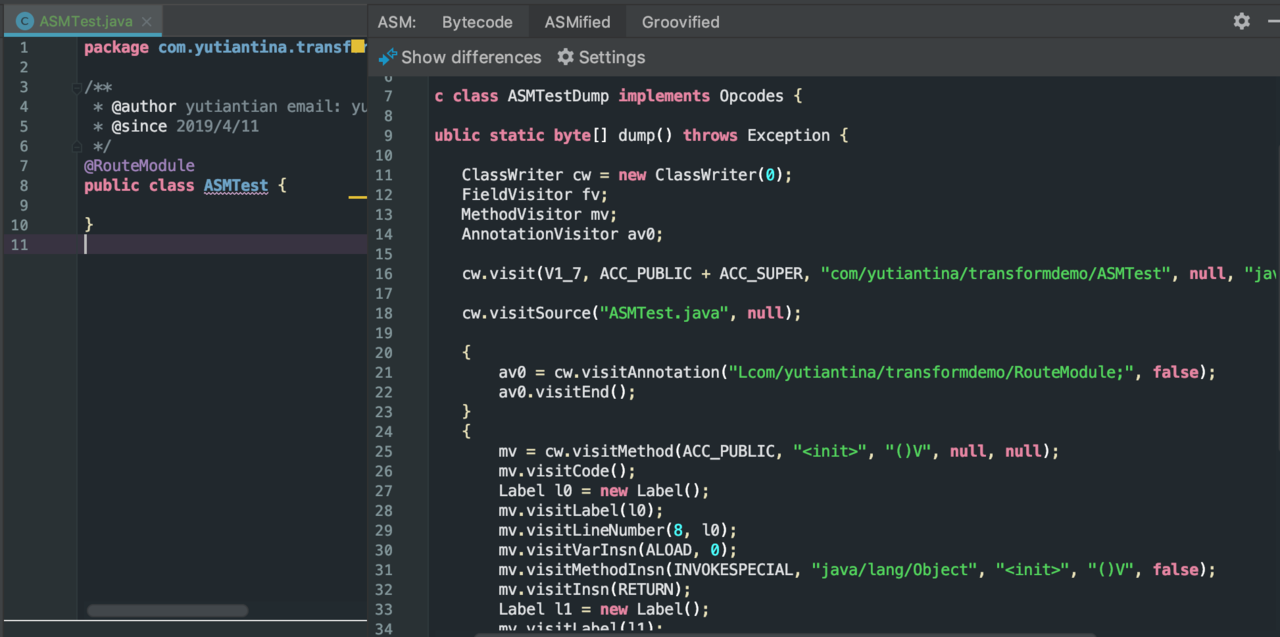
ASM的使用需要一定的学习成本, 我们可以通过使用ASM Bytecode Outline插件辅助了解, 对应插件在AS中的插件浏览器就可以找到
@RouteModule
public class ASMTest {
}
Transform API在应用工程方面的摸索使用
组件通信中的作用
Transform API在组件化工程中有很多应用方向, 目前我们项目中在自开发的路由框架中, 通过其去做了模块的自动化静态注册, 同时考虑到路由通过协议文档维护的不确定性(页面路由地址的维护不及时导致对应开发无法及时更新对应代码), 我们做了路由的常量管理, 首先通过扫描整个工程项目代码收集路由信息, 建立符合一定规则的路由原始基础信息文件, 通过variant#registerJavaGeneratingTask注册 通过对应原始信息文件生成对应常量Java文件下沉在基础通用组件中的task, 这样上层依赖于这个基础组件的项目都可以通过直接调用常量来使用路由.在各组件代码隔离的情况下, 可以通过由组件aar传递原始信息文件, 仍然走上面的步骤生成对应的常量表, 而存在的类重复的问题, 通过自定义Transform处理合并
业务监控中的作用
在应用工程中, 我们通常有关于网络监控,应用性能检测(包括页面加载时间, 甚至包括各个方法调用所耗时间, 可能存在超过阈值需要警告)的需求, 这些需求我们都不可能嵌入在业务代码中, 都是可以基于Transform API进行处理. 而针对于埋点, 我们也可以通过Transform实现自动化埋点的功能, 通过ASM Core和ASM Tree将尽可能多的字段信息形成记录传递, 这里有些我们项目中已经实现了, 有一些则是我们需要去优化或者去实现的.
其他
关于结合Transform+ASM的使用, 我写了个一个小Demo, 包括了如何处理支持增量功能时的转换, 如何使用ASM Core Api和ASM Tree Api, 做了一定的封装, 可以参阅
