

好久没更新博客了,之前学了一些 R 语言和机器学习的内容,做了一些笔记,之后也会放到博客上面来给大家共享。一个月前就打算更新 Spark Sql 的内容了,因为一些别的事情耽误了,今天就简单写点,Spark1.2 马上就要出来了,不知道变动会不会很大,据说添加了很多的新功能呢,期待中...
首先声明一下这个版本的代码是 1.1 的,之前讲的都是 1.0 的。
Spark 支持两种模式,一种是在 spark 里面直接写 sql,可以通过 sql 来查询对象,类似. net 的 LINQ 一样,另外一种支持 hive 的 HQL。不管是哪种方式,下面提到的步骤都会有,不同的是具体的执行过程。下面就说一下这个过程。
Sql 解析成 LogicPlan
使用 Idea 的快捷键 Ctrl + Shift + N 打开 SQLQuerySuite 文件,进行调试吧。
def sql(sqlText: String): SchemaRDD = {
if (dialect == "sql") {
new SchemaRDD(this, parseSql(sqlText))
} else {
sys.error(s"Unsupported SQL dialect: $dialect")
}
}
从这里可以看出来,第一步是解析 sql,最后把它转换成一个 SchemaRDD。点击进入 parseSql 函数,发现解析 Sql 的过程在 SqlParser 这个类里面。 在 SqlParser 的 apply 方法里面,我们可以看到 else 语句里面的这段代码。
//对input进行解析,符合query的模式的就返回Success
phrase(query)(new lexical.Scanner(input)) match {
case Success(r, x) => r
case x => sys.error(x.toString)
}
这里我们主要关注 query 就可以。
protected lazy val query: Parser[LogicalPlan] = (
select * (
UNION ~ ALL ^^^ { (q1: LogicalPlan, q2: LogicalPlan) => Union(q1, q2) } |
INTERSECT ^^^ { (q1: LogicalPlan, q2: LogicalPlan) => Intersect(q1, q2) } |
EXCEPT ^^^ { (q1: LogicalPlan, q2: LogicalPlan) => Except(q1, q2)} |
UNION ~ opt(DISTINCT) ^^^ { (q1: LogicalPlan, q2: LogicalPlan) => Distinct(Union(q1, q2)) }
)
| insert | cache
)
这里面有很多看不懂的操作符,请到下面这个网址里面去学习。这里可以看出来它目前支持的 sql 语句只是 select 和 insert。
www.scala-lang.org/api/2.10.4/…
我们继续查看 select。
// ~>只保留右边的模式 opt可选的 ~按顺序合成 <~只保留左边的
protected lazy val select: Parser[LogicalPlan] =
SELECT ~> opt(DISTINCT) ~ projections ~
opt(from) ~ opt(filter) ~
opt(grouping) ~
opt(having) ~
opt(orderBy) ~
opt(limit) <~ opt(";") ^^ {
case d ~ p ~ r ~ f ~ g ~ h ~ o ~ l =>
val base = r.getOrElse(NoRelation)
val withFilter = f.map(f => Filter(f, base)).getOrElse(base)
val withProjection =
g.map {g =>
Aggregate(assignAliases(g), assignAliases(p), withFilter)
}.getOrElse(Project(assignAliases(p), withFilter))
val withDistinct = d.map(_ => Distinct(withProjection)).getOrElse(withProjection)
val withHaving = h.map(h => Filter(h, withDistinct)).getOrElse(withDistinct)
val withOrder = o.map(o => Sort(o, withHaving)).getOrElse(withHaving)
val withLimit = l.map { l => Limit(l, withOrder) }.getOrElse(withOrder)
withLimit
}
可以看得出来它对 sql 的解析是和我们常用的 sql 写法是一致的,这里面再深入下去还有递归,并不是看起来那么好理解。这里就不继续讲下去了,在解析 hive 的时候我会重点讲一下,我认为目前大家使用得更多是仍然是来源于 hive 的数据集,毕竟 hive 那么稳定。
到这里我们可以知道第一步是通过 Parser 把 sql 解析成一个 LogicPlan。
LogicPlan 到 RDD 的转换过程
好,下面我们回到刚才的代码,接着我们应该看 SchemaRDD。
override def compute(split: Partition, context: TaskContext): Iterator[Row] =
firstParent[Row].compute(split, context).map(_.copy())
override def getPartitions: Array[Partition] = firstParent[Row].partitions
override protected def getDependencies: Seq[Dependency[_]] =
List(new OneToOneDependency(queryExecution.toRdd))
SchemaRDD 是一个 RDD 的话,那么它最重要的 3 个属性:compute 函数,分区,依赖全在这里面,其它的函数我们就不看了。
挺奇怪的是,我们 new 出来的 RDD,怎么会有依赖呢,这个 queryExecution 是啥,点击进去看看吧,代码跳转到 SchemaRDD 继承的 SchemaRDDLike 里面。
lazy val queryExecution = sqlContext.executePlan(baseLogicalPlan)
protected[sql] def executePlan(plan: LogicalPlan): this.QueryExecution =
new this.QueryExecution { val logical = plan }
把这两段很短的代码都放一起了,executePlan 方法就是 new 了一个 QueryExecution 出来,那我们继续看看 QueryExecution 这个类吧。
lazy val analyzed = ExtractPythonUdfs(analyzer(logical))
lazy val optimizedPlan = optimizer(analyzed)
lazy val sparkPlan = {
SparkPlan.currentContext.set(self)
planner(optimizedPlan).next()
}
// 在需要的时候加入Shuffle操作
lazy val executedPlan: SparkPlan = prepareForExecution(sparkPlan)
lazy val toRdd: RDD[Row] = executedPlan.execute()
从这里可以看出来 LogicPlan 是经过了 5 个步骤的转换,要被 analyzer 和 optimizer 的处理,然后转换成 SparkPlan,在执行之前还要被 prepareForExecution 处理一下,最后调用 execute 方法转成 RDD.
下面我们分步讲这些个东东到底是干啥了。
首先我们看看 Anayzer,它是继承自 RuleExecutor 的,这里插句题外话,Spark sql 的作者 Michael Armbrust 在 2013 年的 Spark Submit 上介绍 Catalyst 的时候,就说到要从整体地去优化一个 sql 的执行是很困难的,所有设计成这种基于一个一个小规则的这种优化方式,既简单又方便维护。
好,我们接下来看看 RuleExecutor 的 apply 方法。
def apply(plan: TreeType): TreeType = {
var curPlan = plan
//规则还分批次的,分批对plan进行处理
batches.foreach { batch =>
val batchStartPlan = curPlan
var iteration = 1
var lastPlan = curPlan
var continue = true
// Run until fix point (or the max number of iterations as specified in the strategy.
while (continue) {
//用batch种的小规则从左到右挨个对plan进行处理
curPlan = batch.rules.foldLeft(curPlan) {
case (plan, rule) =>
val result = rule(plan)
result
}
iteration += 1
//超过了规定的迭代次数就要退出的
if (iteration > batch.strategy.maxIterations) {
continue = false
}
//经过处理成功的plan是会发生改变的,如果和上一次处理接触的plan一样,这说明已经没有优化空间了,可以结束,这个就是前面提到的Fixed point
if (curPlan.fastEquals(lastPlan)) {
continue = false
}
lastPlan = curPlan
}
}
curPlan
}
看完了 RuleExecutor,我们继续看 Analyzer,下面我只贴出来 batches 这块的代码,剩下的要自己去看了哦。
val batches: Seq[Batch] = Seq(
//碰到继承自MultiInstanceRelations接口的LogicPlan时,发现id以后重复的,就强制要求它们生成一个新的全局唯一的id
//涉及到InMemoryRelation、LogicRegion、ParquetRelation、SparkLogicPlan
Batch("MultiInstanceRelations", Once,
NewRelationInstances),
//如果大小写不敏感就把属性都变成小写
Batch("CaseInsensitiveAttributeReferences", Once,
(if (caseSensitive) Nil else LowercaseAttributeReferences :: Nil) : _*),
//这个牛逼啊,居然想迭代100次的。
Batch("Resolution", fixedPoint,
//解析从子节点的操作生成的属性,一般是别名引起的,比如a.id
ResolveReferences ::
//通过catalog解析表名
ResolveRelations ::
//在select语言里,order by的属性往往在前面没写,查询的时候也需要把这些字段查出来,排序完毕之后再删除
ResolveSortReferences ::
//前面讲过了
NewRelationInstances ::
//清除被误认为别名的属性,比如sum(score) as a,其实它应该是sum(score)才对
//它被解析的时候解析成Project(Seq(Alias(g: Generator, _)),直接返回Generator就可以了
ImplicitGenerate ::
//处理语句中的*,比如select *, count(*)
StarExpansion ::
//解析函数
ResolveFunctions ::
//解析全局的聚合函数,比如select sum(score) from table
GlobalAggregates ::
//解析having子句后面的聚合过滤条件,比如having sum(score) > 400
UnresolvedHavingClauseAttributes ::
//typeCoercionRules是hive的类型转换规则
typeCoercionRules :_*),
//检查所有节点的属性是否都已经处理完毕了,如果还有没解析出来的属性,这里就会报错!
Batch("Check Analysis", Once,
CheckResolution),
//清除多余的操作符,现在是Subquery和LowerCaseSchema,
//第一个是子查询,第二个HiveContext查询树里面把子节点全部转换成小写
Batch("AnalysisOperators", fixedPoint,
EliminateAnalysisOperators)
)
可以看得出来 Analyzer 是把 Unresolved 的 LogicPlan 解析成 resolved 的,解析里面的表名、字段、函数、别名什么的。
我们接着看 Optimizer, 从单词上看它是用来做优化的,但是从代码上来看它更多的是为了过滤我们写的一些垃圾语句,并没有做什么实际的优化。
object Optimizer extends RuleExecutor[LogicalPlan] {
val batches =
//递归合并相邻的两个limit
Batch("Combine Limits", FixedPoint(100),
CombineLimits) ::
Batch("ConstantFolding", FixedPoint(100),
//替换null值
NullPropagation,
//替换一些简单的常量表达式,比如 1 in (1,2) 直接返回一个true就可以了
ConstantFolding,
//简化like语句,避免全表扫描,目前支持'%demo%', '%demo','demo*','demo'
LikeSimplification,
//简化过滤条件,比如true and score > 0 直接替换成score > 0
BooleanSimplification,
//简化filter,比如where 1=1 或者where 1=2,前者直接去掉这个过滤,后者这个查询就没必要做了
SimplifyFilters,
//简化转换,比如两个比较字段的数据类型是一样的,就不需要转换了
SimplifyCasts,
//简化大小写转换,比如Upper(Upper('a'))转为认为是Upper('a')
SimplifyCaseConversionExpressions) ::
Batch("Filter Pushdown", FixedPoint(100),
//递归合并相邻的两个过滤条件
CombineFilters,
//把从表达式里面的过滤替换成,先做过滤再取表达式,并且掉过滤里面的别名属性
//典型的例子 select * from (select a,b from table) where a=1
//替换成select * from (select a,b from table where a=1)
PushPredicateThroughProject,
//把join的on条件中可以在原表当中做过滤的先做过滤
//比如select a,b from x join y on x.id = y.id and x.a >0 and y.b >0
//这个语句可以改写为 select a,b from x where x.a > 0 join (select * from y where y.b >0) on x.id = y.id
PushPredicateThroughJoin,
//去掉一些用不上的列
ColumnPruning) :: Nil
}
真是用心良苦啊,看来我们写 sql 的时候还是要注意一点的,你看人家花多大的功夫来优化我们的烂 sql。要是我肯定不优化。写得烂就慢去吧!
接下来,就改看这一句了 planner(optimizedPlan).next() 我们先看看 SparkPlanner 吧。
protected[sql] class SparkPlanner extends SparkStrategies {
val sparkContext: SparkContext = self.sparkContext
val sqlContext: SQLContext = self
def codegenEnabled = self.codegenEnabled
def numPartitions = self.numShufflePartitions
//把LogicPlan转换成实际的操作,具体操作类在org.apache.spark.sql.execution包下面
val strategies: Seq[Strategy] =
//把cache、set、expain命令转化为实际的Command
CommandStrategy(self) ::
//把limit转换成TakeOrdered操作
TakeOrdered ::
//名字有点蛊惑人,就是转换聚合操作
HashAggregation ::
//left semi join只显示连接条件成立的时候连接左边的表的信息
//比如select * from table1 left semi join table2 on(table1.student_no=table2.student_no);
//它只显示table1中student_no在表二当中的信息,它可以用来替换exist语句
LeftSemiJoin ::
//等值连接操作,有些优化的内容,如果表的大小小于spark.sql.autoBroadcastJoinThreshold设置的字节
//就自动转换为BroadcastHashJoin,即把表缓存,类似hive的map join(顺序是先判断右表再判断右表)。
//这个参数的默认值是10000
//另外做内连接的时候还会判断左表右表的大小,shuffle取数据大表不动,从小表拉取数据过来计算
HashJoin ::
//在内存里面执行select语句进行过滤,会做缓存
InMemoryScans ::
//和parquet相关的操作
ParquetOperations ::
//基本的操作
BasicOperators ::
//没有条件的连接或者内连接做笛卡尔积
CartesianProduct ::
//把NestedLoop连接进行广播连接
BroadcastNestedLoopJoin :: Nil
......
}
这一步是把逻辑计划转换成物理计划,或者说是执行计划了,里面有很多概念是我以前没听过的,网上查了一下才知道,原来数据库的执行计划还有那么多的说法,这一块需要是专门研究数据库的人比较了解了。剩下的两步就是 prepareForExecution 和 execute 操作。
prepareForExecution 操作是检查物理计划当中的 Distribution 是否满足 Partitioning 的要求,如果不满足的话,需要重新弄做分区,添加 shuffle 操作,这块暂时没咋看懂,以后还需要仔细研究。最后调用 SparkPlan 的 execute 方法,这里面稍微讲讲这块的树型结构。
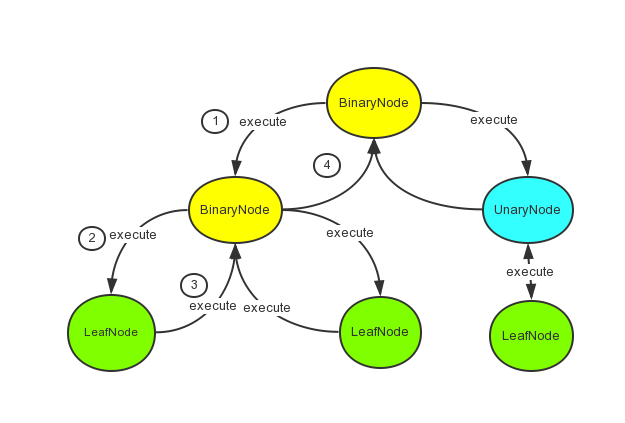
sql 解析出来就是一个二叉树的结构,不管是逻辑计划还是物理计划,都是这种结构,所以在代码里面可以看到 LogicPlan 和 SparkPlan 的具体实现类都是有继承上面图中的三种类型的节点的。
非 LeafNode 的 SparkPlan 的 execute 方法都会有这么一句 child.execute(),因为它需要先执行子节点的 execute 来返回数据,执行的过程是一个先序遍历。
最后把这个过程也用一个图来表示吧,方便记忆。
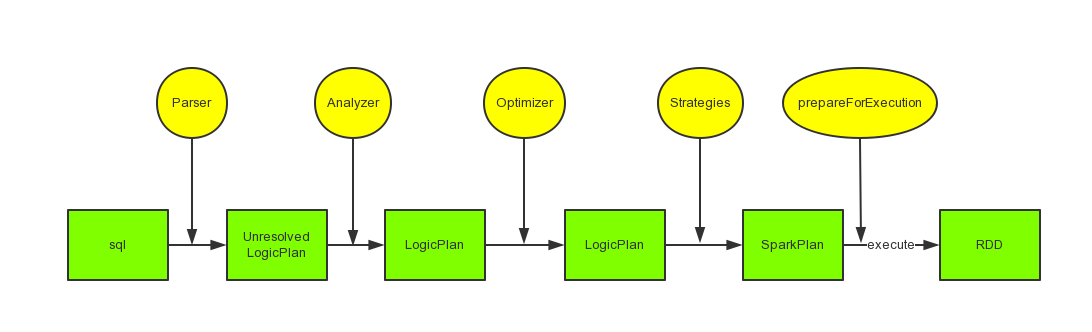
(1) 通过一个 Parser 来把 sql 语句转换成 Unresolved LogicPlan,目前有两种 Parser,SqlParser 和 HiveQl。
(2) 通过 Analyzer 把 LogicPlan 当中的 Unresolved 的内容给解析成 resolved 的,这里面包括表名、函数、字段、别名等。
(3) 通过 Optimizer 过滤掉一些垃圾的 sql 语句。
(4) 通过 Strategies 把逻辑计划转换成可以具体执行的物理计划,具体的类有 SparkStrategies 和 HiveStrategies。
(5) 在执行前用 prepareForExecution 方法先检查一下。
(6) 先序遍历,调用执行计划树的 execute 方法。
