

之前通过三篇文章简单介绍了机器学习常用的几种经典算法,当然也包括了目前很火的 CNNs 算法了:
这些算法各有各的优缺点和适用的领域,了解熟悉它们是很有必要的,但如何应用它们还需要具体问题具体分析,而机器学习常见的应用方向,包括以下几个:
- 计算机视觉(CV)
- 自然语言处理(NLP)
- 语音识别
- 推荐系统
- 广告
等等
更详细的可以参考之前推荐过的一个网站:
这个网站非常详细划分了 16 个大方向,包括总共 1081 个子方向。如果想进入机器学习领域,首先还是选择一个方向领域,然后了解和熟悉该方向领域内所需要的算法,特定的解决技巧等。
当然,这篇文章主要介绍的是计算机视觉的应用,计算机视觉也算是这 16 个方向里面最热门也是发展最成熟的其中一个方向了。
计算机视觉可以分为以下几大方向:
- 图像分类
- 目标检测
- 图像分割
- 风格迁移
- 图像重构
- 超分辨率
- 图像生成
- 人脸
- 其他
虽然这里说的都是图像,但其实视频也属于计算机视觉的研究对象,所以还有视频分类、检测、生成,以及追踪,但篇幅的关系,以及目前研究工作方向也集中于图像,暂时就不介绍视频方面应用的内容。
每个方向会简单介绍该方向需要解决的问题,以及推荐一些 Github 项目、论文或者是综述文章。
1. 图像分类(Image Classification)
图像分类,也可以称为图像识别,顾名思义,就是辨别图像是什么,或者说图像中的物体属于什么类别。
图像分类根据不同分类标准可以划分为很多种子方向。
比如根据类别标签,可以划分为:
- 二分类问题,比如判断图片中是否包含人脸;
- 多分类问题,比如鸟类识别;
- 多标签分类,每个类别都包含多种属性的标签,比如对于服饰分类,可以加上衣服颜色、纹理、袖长等标签,输出的不只是单一的类别,还可以包括多个属性。
根据分类对象,可以划分为:
- 通用分类,比如简单划分为鸟类、车、猫、狗等类别;
- 细粒度分类,目前图像分类比较热门的领域,比如鸟类、花卉、猫狗等类别,它们的一些更精细的类别之间非常相似,而同个类别则可能由于遮挡、角度、光照等原因就不易分辨。
根据类别数量,还可以分为:
- Few-shot learning:即小样本学习,训练集中每个类别数量很少,包括
one-shot和zero-shot; - large-scale learning:大规模样本学习,也是现在主流的分类方法,这也是由于深度学习对数据集的要求。
推荐的 Github 项目如下:
论文:
- ImageNet Classification With Deep Convolutional Neural Networks, 2012
- Very Deep Convolutional Networks for Large-Scale Image Recognition, 2014.
- Going Deeper with Convolutions, 2015.
- Deep Residual Learning for Image Recognition, 2015.
- Inceptionv4 && Inception-ResNetv2,2016
- RexNext,2016
- NasNet,2017
- ShuffleNetV2,2018
- SKNet,2019
文章:
常用的图像分类数据集:
- Mnist:手写数字数据集,包含 60000 张训练集和 10000 张测试集。
- Cifar:分为 Cifar10 和 Cifar100。前者包含 60000 张图片,总共10个类别,每类 6000 张图片。后者是 100 个类别,每个类别 600 张图片。类别包括猫狗鸟等动物、飞机汽车船等交通工具。
- Imagenet:应该是目前最大的开源图像数据集,包含 1500 万张图片,2.2 万个类别。
2. 目标检测(Object Detection)
目标检测通常包含两方面的工作,首先是找到目标,然后就是识别目标。
目标检测可以分为单物体检测和多物体检测,即图像中目标的数量,例子如下所示:


以上两个例子是来自 VOC 2012 数据集的图片,实际上还有更多更复杂的场景,如 MS COCO 数据集的图片例子:

目标检测领域,其实有很多方法,其发展史如下所示:
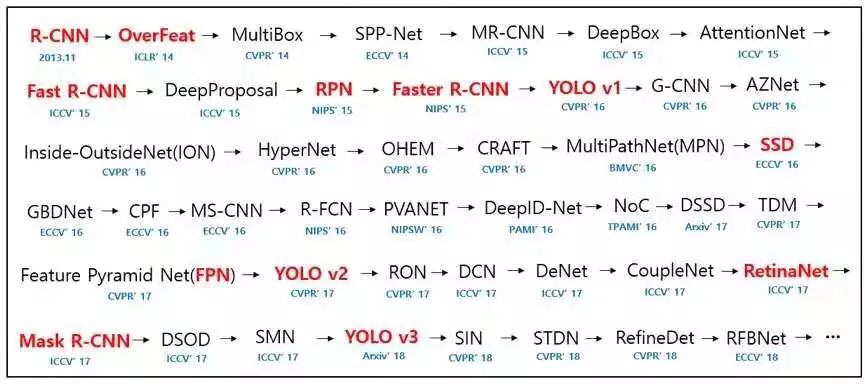
从上图可以知道有几个方法系列:
- R-CNN 系列,从 R-CNN 到 Fast R-CNN、Faster R-CNN,Mask R-CNN;
- YOLO 系列,从 v1 到 2018 年的 v3 版本
Github 项目:
论文:
- R-CNN,2013
- Fast R-CNN,2015
- Faster R-CNN,2015
- Mask R-CNN,2017
- YOLO,2015
- YOLOv2,2016
- YOLOv3,2018
- SSD,2015
- FPN,2016
文章:
- 一文读懂目标检测:R-CNN、Fast R-CNN、Faster R-CNN、YOLO、SSD
- 教程 | 单级式目标检测方法概述:YOLO 与 SSD
- 从 RCNN 到 SSD,这应该是最全的一份目标检测算法盘点
- 从 R-CNN 到 RFBNet,目标检测架构 5 年演进全盘点
常用的数据集:
3. 图像分割(Object Segmentation)
图像分割是基于图像检测的,它需要检测到目标物体,然后把物体分割出来。
图像分割可以分为三种:
- 普通分割:将不同分属于不同物体的像素区域分开,比如前景区域和后景区域的分割;
- 语义分割:普通分割的基础上,在像素级别上的分类,属于同一类的像素都要被归为一类,比如分割出不同类别的物体;
- 实例分割:语义分割的基础上,分割出每个实例物体,比如对图片中的多只狗都分割出来,识别出来它们是不同的个体,不仅仅是属于哪个类别。
一个图形分割的例子如下所示,下图就是一个实例分割的例子,用不同的颜色表示不同的实例。

Github:
论文:
文章:
4. 风格迁移(Style Transfer)
风格迁移是指将一个领域或者几张图片的风格应用到其他领域或者图片上。比如将抽象派的风格应用到写实派的图片上。
一个风格迁移的例子如下, 图 A 是原图,后面的 B-F 五幅图都是根据不同风格得到的结果。

一般数据集采用常用的数据集加一些著名的艺术画作品,比如梵高、毕加索等。
Github:
- A simple, concise tensorflow implementation of style transfer (neural style)
- TensorFlow (Python API) implementation of Neural Style
- TensorFlow CNN for fast style transfer
论文:
- A Neural Algorithm of Artistic Style,2015
- Image Style Transfer Using Convolutional Neural Networks, 2016
- Deep Photo Style Transfer,2017
文章:
- 图像风格迁移(Neural Style)简史
- Style Transfer | 风格迁移综述
- 感知损失(Perceptual Losses)
- 图像风格转换(Image style transfer)
- 风格迁移(Style Transfer)论文阅读整理(一)
5. 图像重构(Image Reconstruction)
图像重构,也称为图像修复(Image Inpainting),其目的就是修复图像中缺失的地方,比如可以用于修复一些老的有损坏的黑白照片和影片。通常会采用常用的数据集,然后人为制造图片中需要修复的地方。
一个修复的例子如下所示,总共是四张需要修复的图片,例子来自论文"Image Inpainting for Irregular Holes Using Partial Convolutions"。

论文:
- Pixel Recurrent Neural Networks, 2016.
- Image Inpainting for Irregular Holes Using Partial Convolutions, 2018.
- Highly Scalable Image Reconstruction using Deep Neural Networks with Bandpass Filtering, 2018.
- Generative Image Inpainting with Contextual Attention, 2018
- Free-Form Image Inpainting with Gated Convolution,2018
- EdgeConnect: Generative Image Inpainting with Adversarial Edge Learning,2019
Github:
文章:
6. 超分辨率(Super-Resolution)
超分辨率是指生成一个比原图分辨率更高、细节更清晰的任务。一个例子如下图所示,图例来自论文"Photo-Realistic Single Image Super-Resolution Using a Generative Adversarial Network"。

通常超分辨率的模型也可以用于解决图像恢复(image restoration)和修复(inpainting),因为它们都是解决比较关联的问题。
常用的数据集主要是采用现有的数据集,并生成分辨率较低的图片用于模型的训练。
Github:
- Image Super-Resolution for Anime-Style Art--用于动漫图片的超分辨率应用,14k 的 stars
- neural-enhance
- Image super-resolution through deep learning
论文:
- Photo-Realistic Single Image Super-Resolution Using a Generative Adversarial Network, 2017.
- Deep Laplacian Pyramid Networks for Fast and Accurate Super-Resolution, 2017.
- Deep Image Prior, 2017.
- ESRGAN: Enhanced Super-Resolution Generative Adversarial Networks,2018
文章:
7. 图像生成(Image Synthesis)
图像生成是根据一张图片生成修改部分区域的图片或者是全新的图片的任务。这个应用最近几年快速发展,主要原因也是由于 GANs 是最近几年非常热门的研究方向,而图像生成就是 GANs 的一大应用。
一个图像生成例子如下:

Githubs:
- tensorflow-generative-model-collections--集成了多种 GANs 的代码
- The-gan-zoo--收集了当前的所有 GANs 相关的论文
- AdversarialNetsPapers
论文:
- Unsupervised Representation Learning with Deep Convolutional Generative Adversarial Networks, 2015.
- Conditional Image Generation with PixelCNN Decoders, 2016.
- Pix2Pix--Image-to-image translation with conditional adversarial networks,2016
- Unpaired Image-to-Image Translation using Cycle-Consistent Adversarial Networks, 2017.
- bigGAN--LARGE SCALE GAN TRAINING FOR HIGH FIDELITY NATURAL IMAGE SYNTHESIS,2018
文章:
- 干货 | 深入浅出 GAN·原理篇文字版(完整)
- 深度 | 生成对抗网络初学入门:一文读懂GAN的基本原理(附资源)
- 独家 | GAN之父NIPS 2016演讲现场直击:全方位解读生成对抗网络的原理及未来(附PPT)
- 英伟达再出GAN神作!多层次特征的风格迁移人脸生成器
8. 人脸
人脸方面的应用,包括人脸识别、人脸检测、人脸匹配、人脸对齐等等,这应该是计算机视觉方面最热门也是发展最成熟的应用,而且已经比较广泛的应用在各种安全、身份认证等,比如人脸支付、人脸解锁。
这里就直接推荐几个 Github 项目、论文、文章和数据集
Github:
- awesome-Face_Recognition:近十年的人脸相关的所有论文合集
- face_recognition:人脸识别库,可以实现识别、检测、匹配等等功能。
- facenet
论文:
- FaceNet: A Unified Embedding for Face Recognition and Clustering,2015
- Face Recognition: From Traditional to Deep Learning Methods,2018
- MSFD:Multi-Scale Receptive Field Face Detector,2018
- DSFD: Dual Shot Face Detector,2018
- Neural Architecture Search for Deep Face Recognition,2019
文章:
数据集:
10. 其他
实际上还有其他很多方向,包括:
- 图文生成(Image Captioning):给图片生成一段描述。
Show and Tell: A Neural Image Caption Generator, 2014.
- 文本生成图片(Text to Image):基于文本来生成图片。
AttnGAN: Fine-Grained Text to Image Generation with Attentional Generative Adversarial Networks, 2017.
- 图片上色(Image Colorization):将图片从黑白变为彩色图。
Colorful Image Colorization, 2016.
- 人体姿态估计(human pose estimation):识别人的行为动作
Cascaded Pyramid Network for Multi-Person Pose Estimation, 2017
还有包括 3D、视频、医学图像、问答、自动驾驶、追踪等等方向,具体可以查看下面这个网站:
paperswithcode.com/area/comput…
而如果认定一个方向,想开始学习这方面的内容,首先推荐可以先查找中文方面的综述文章或者论文,当然如果英语阅读能力比较好的,也可以查看英文的综述文章,通过看综述来查看下自己需要阅读的论文,论文推荐先看最近3-5年内的论文,太过久远的论文,除非需要更加深入了解某个算法,否则都不太需要阅读。
此外,就是需要结合实际项目来加深对算法的了解,通过跑下代码,也可以更好了解某个算法具体是如何实现的。
参考
小结
本文简单介绍了几个计算机视觉方面的应用,包括应用解决的问题以及推荐了几个 Github 项目和论文、文章,和常用数据集。
欢迎关注我的微信公众号--机器学习与计算机视觉,或者扫描下方的二维码,大家一起交流,学习和进步!

往期精彩推荐
机器学习系列
- 初学者的机器学习入门实战教程!
- 模型评估、过拟合欠拟合以及超参数调优方法
- 常用机器学习算法汇总比较(完)
- 常用机器学习算法汇总比较(上)
- 机器学习入门系列(2)--如何构建一个完整的机器学习项目(一)
- 特征工程之数据预处理(上)
