


前言
学习算法课程的时候,老师推荐了两本算法和数据结构入门书,一本是《算法图解》、一本是《大话数据结构》,《算法图解》这本书最近读完了,读完的最大感受就是对算法不再感到畏惧和陌生,对常用的算法和数据结构都会在心里有个基本的概念,这篇文章记录下这本书的主要内容和知识点。
总的来说,这本书是一本不错的算法入门书,作者以从实际开发场景出发,介绍了软件开发中最基本、最常用的一些数据结构和算法思想,同时作者写得非常深入浅出,联系实际应用场景,并结合了大量的算法推演图示,举例生动形象,循序渐进,使读者易于理解,能够很大地培养读者对算法的兴趣,从而引导读者进一步地进行学习研究。
正如作者在书开头关于本书中所说,阅读这本书最佳姿势是从头到尾读,因为作者对内容顺序专门做了精心地编排,从简到难。前三章是最基础的部分,第一章通过二分查找算法来引出衡量算法优劣的大O表示法概念,同时介绍了数组和链表这两种最基本的数据结构,通过这两种最基本的数据结构,可以来创建更高级更复杂的数据结构,第三章则介绍了递归,一种被众多算法(如快速排序)采用的编程技巧。
从第四章开始,介绍地都是应用特别广泛的一些算法,第四章介绍了快速排序,一种效率最高的排序算法。第五章介绍了散列表,也叫哈希表或者字典,介绍了哈希表的实现,怎么解决冲突,应用场景等内容。第六七章主要介绍的是图这种数据结构,有向图还是无向图,带权值还是不带权值,以及和图相关的几种算法,广度优先算法和狄克斯特算法。第八章介绍了贪婪算法,在没有高效的解决方案是,可以考虑用贪婪算法来得到近似答案。第九章介绍的是动态规划,第十章介绍一种简单的机器学习算法 K 最近邻算法,可以应用于创建推荐系统、OCR引擎、预测股价以及物体分类等领域,最后一章介绍了其他一些解决特定问题的常见算法。
二分查找
二分查找解决的是如何最快地在一个有序的集合中找到一个目标数的问题。使用二分查找,每次都折半,通过和中间大的数比对,缩小范围,最终只需要 O(logn) 的事件复杂度。
/*
二分查找
array:有序数组
target: 目标数
loopCount: 寻找次数
return: 目标数下标
*/
- (NSInteger)binarySearchSortInArray:(NSArray<NSNumber *> *)array target:(NSNumber *)target loopCount:(NSInteger *)loopCount
{
NSInteger low = 0;
NSInteger high = array.count - 1;
while (low <= high) {
NSInteger mid = (low + high) / 2;
NSInteger guess = array[mid].integerValue;
*loopCount = *loopCount + 1;
if (guess == target.integerValue) {
// 猜中了
return mid;
}
if (guess < target.integerValue) {
// 猜小了
low = mid + 1;
} else {
// 猜大了
high = mid - 1;
}
}
return -1;
}
// 测试数据 -----------------------------------------------------
NSArray *array = @[@1, @2, @5, @6, @9, @10, @13, @18, @22, @30];
NSInteger loopCount = 0;
NSInteger result = [self binarySearchInSortArray:array target:@2 loopCount:&loopCount];
if (result >= 0) {
NSLog(@"找到目标数,目标数的的下标是:%ld,寻找:%ld 次", result, (long)loopCount);
} else {
NSLog(@"没有找到找到目标数,目标数的的下标是:%ld, 寻找:%ld 次", result, (long)loopCount);
}
// 打印日志 ------------------------------------------------------
找到目标数,目标数的的下标是:1,寻找:2 次
递归
递归是一种自己调用自己的函数,每个递归有两个条件,分别是基线条件和递归条件。如著名的斐波那契数列,在数学上,就是可以用递推公式来表示这个数列。

在编程领域,是常被很多算法所采用的一种编程技巧。如上面的二分查找也可以使用递归来写:
int binary_search(int nums[], int target, int low, int high)
{
if(low > high) {return low;} // 基线条件
int mid = low + (high - low) / 2;
if(nums[mid] == target) {
return mid;
} else if (nums[mid] > target) {
// 中间值大于目标值,递归条件
return binary_search(nums, target, low, mid - 1);
} else {
// 中间值小于目标值,递归条件
return binary_search(nums, target, mid + 1, high);
}
}
// 测试 -----------------------------------------------------
int array[10] = {1, 2, 5, 6, 9, 10, 13, 18, 22, 30};
int result = binary_search(array, 9, 0, sizeof(array)/sizeof(int));
printf("result = %d", result); // result = 4
排序
#选择排序
选择排序的思想是,每次都从数组中选择最小的数然后依次从起始的位置开始存放,有两层循环,所以时间复杂度是 n^2。
// 选择排序
void select_sort(int nums[], int length)
{
int a = nums[0];
// n -1 轮选择
for(int i = 0; i < length - 1; i++)
{
// 最小值所在索引
int min_index = i;
for(int j = i + 1; j < length; j++)
{
if(nums[min_index] > nums[j]) {
// 有更小的
min_index = j;
}
}
// 如果正好,就不用交换
if (i != min_index) {
// 交换位置
int temp = nums[i];
nums[i] = nums[min_index];
nums[min_index] = temp;
}
}
}
// 测试数据 ------------------------------------------
int a[10] = {12, 7, 67, 8, 5, 199, 78, 6, 2, 1};
select_sort(a, 10);
for(int i = 0; i < 10; i++)
{
printf("%d ", a[i]);
}
// 打印日志 -----------------------------------------
1 2 5 6 7 8 12 67 78 199
#快速排序
快速排序是最快的一种排序算法,使用递归的思路,每次从数组中找出一个基准点,将数组分割成三分部分,小于所有基准点的元素组成一个数组less,大于基准点的元素组成一个数组greater,less + 基准点 + greater 就是新的数组,小数组也按照这种思路选取基准点进行分割,递归下去,递归的基线条件是数组的长度小于 2 时停止,意味着数组不能再分割下去了。这种思路下排序的时间复杂度是O(nlogn)。
// 快速排序
func quickSort(_ array:[Int]) -> [Int]
{
if array.count < 2 {
// 基线条件
return array;
} else {
// 递归条件
let pivot = array[0]
let less = array.filter{$0 < pivot}
let greater = array.filter{$0 > pivot}
return quickSort(less) + [pivot] + quickSort(greater)
}
}
// 测试
var array = [1, 78, 8, 76, 98, 90, 3, 100, 45, 78]
var newArray = quickSort(array)
// 打印
print(newArray) // [1, 3, 8, 45, 76, 78, 90, 98, 100]
散列表
散列表是一种非常常见的数据结构,通过数组结合散列函数实现,散列函数计算出值所对应的数组下标映射,在其他一些平台上也被称为散列映射、映射、字典和关联数组,能做到 O(1) 平均复杂度的访问、插入和删除操作,是一种比较底层的数据结构。
散列表常用于查找、去重、缓存等应用场景,几乎每种编程语言都有自己的散列表实现,如 Objective-C 的 NSDictionary,要想散列表有较好的性能和避免冲突(两个键映射到了同一个位置),意味着需要有较低的填装因子(散列表包含的元素数/占用存储的位置总数)和良好的散列函数。
一个不错的经验是,一旦填装因子大于0.7,就要调整散列表的长度。而一旦发生冲突的一种解决办法是,在冲突的位置存储一个链表,将多个值存储到链表的不同的节点上,这样访问的时候就还需要从头遍历一遍该位置的链表才行,好的散列函数应该是将键均匀的映射到散列表的不同位置。
leetCode上第一道两数之和的题目就可以使用散列表来降低算法的时间复杂度。
/*
* @lc app=leetcode.cn id=1 lang=swift
*
* [1] 两数之和
*
* https://leetcode-cn.com/problems/two-sum/description/
*
* algorithms
* Easy (44.51%)
* Total Accepted: 243.9K
* Total Submissions: 548K
* Testcase Example: '[2,7,11,15]\n9'
*
* 给定一个整数数组 nums 和一个目标值 target,请你在该数组中找出和为目标值的那 两个 整数,并返回他们的数组下标。
*
* 你可以假设每种输入只会对应一个答案。但是,你不能重复利用这个数组中同样的元素。
*
* 示例:
*
* 给定 nums = [2, 7, 11, 15], target = 9
*
* 因为 nums[0] + nums[1] = 2 + 7 = 9
* 所以返回 [0, 1]
*
*
*/
// C 两层循环实现
int* twoSum(int* nums, int numsSize, int target) {
static int resultArray[2];
for (int i = 0; i < numsSize; i ++) {
for (int j = i + 1; j < numsSize; j++) {
if (nums[i] + nums[j] == target) {
resultArray[0] = i;
resultArray[1] = j;
}
}
}
return resultArray;
}
// swift 使用散列表实现
class Solution {
func twoSum(_ nums: [Int], _ target: Int) -> [Int] {
var hash = [Int: Int]
for (index, item) in nums {
// 使用散列表来判断元素是否在散列表中,有的话返回元素的下标,即散列表的值
if let firstIndex = hash[target - item] {
return [firstIndex, index]
}
// 将数组元素的值当做散列表的键,下标当做散列表的值存储在散列表中
hash[item] = index
}
return [-1,-1]
}
}
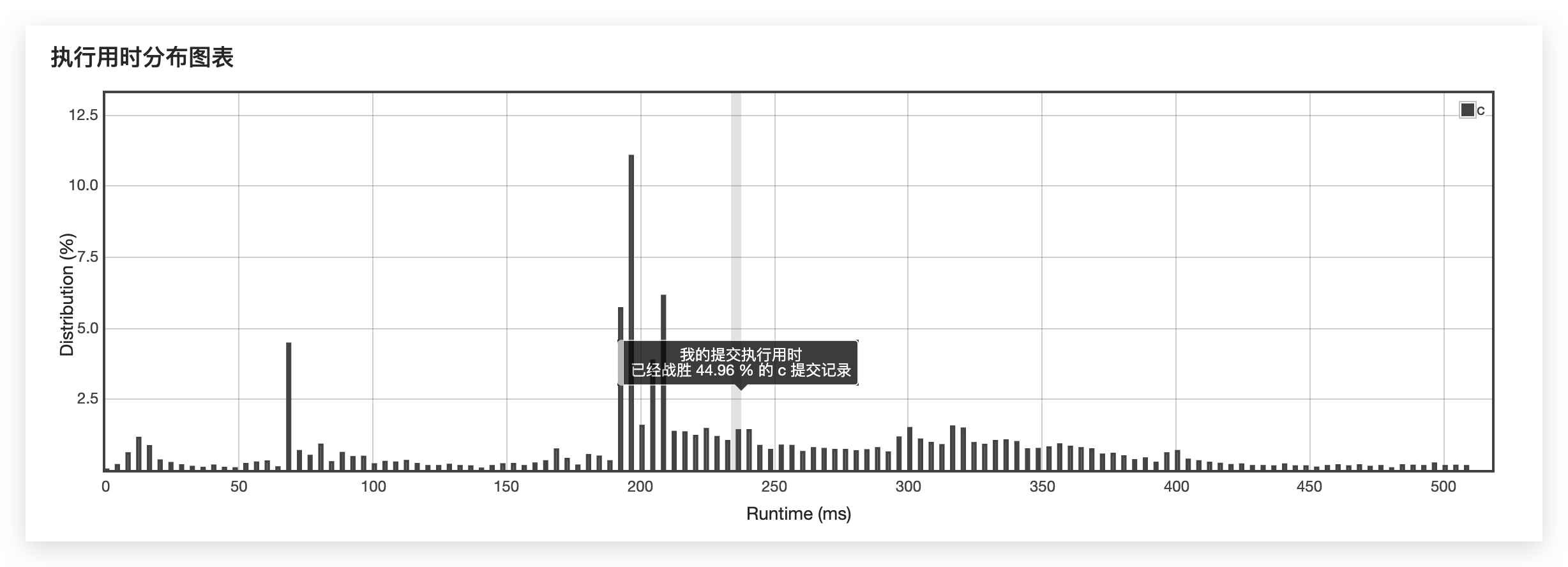
使用散列表实现后:
广度优先搜索算法(breadth-first-search,BFS)
广度优先搜索要解决的问题是基于图这种数据结构的最短路径的问题。是一种用于图的查找算法,可帮助回答两类问题:
- 从顶点 a 出发,有前往顶点 b 的路径吗?
- 从顶点 a 出发,前往顶点 b 的哪条路径最短?
再看一下图的定义:
图(Graph)是由
顶点的有穷非空集合和顶点之间边的集合组成,通常表示为:G(V,E),其中,G 表示一个图,V 是图 G 中顶点的集合,E 是图 G 中边的集合。
图有很多种类:
- 按照有无方向可以分为
有向图和无向图,有向图的边又称为弧,有弧头和弧尾之分。 - 按照边或弧的多少又分为
稀疏图和稠密图。如果任意两个顶点之间都存在边叫做完全图,边有向的叫做有向完全图,若无重复的边或者顶点到自身的边叫做简单图。 - 图上的边或者弧带上权则叫做
网。
可以得出结论,
广度优先搜索解决问题的数据模型是有向图,且不加权。
书中列举了两个列子,先来看第一个,如何选择换乘公交最少的路线?,假设你住在旧金山,现在要从双子峰前往金门大桥,如图所示:
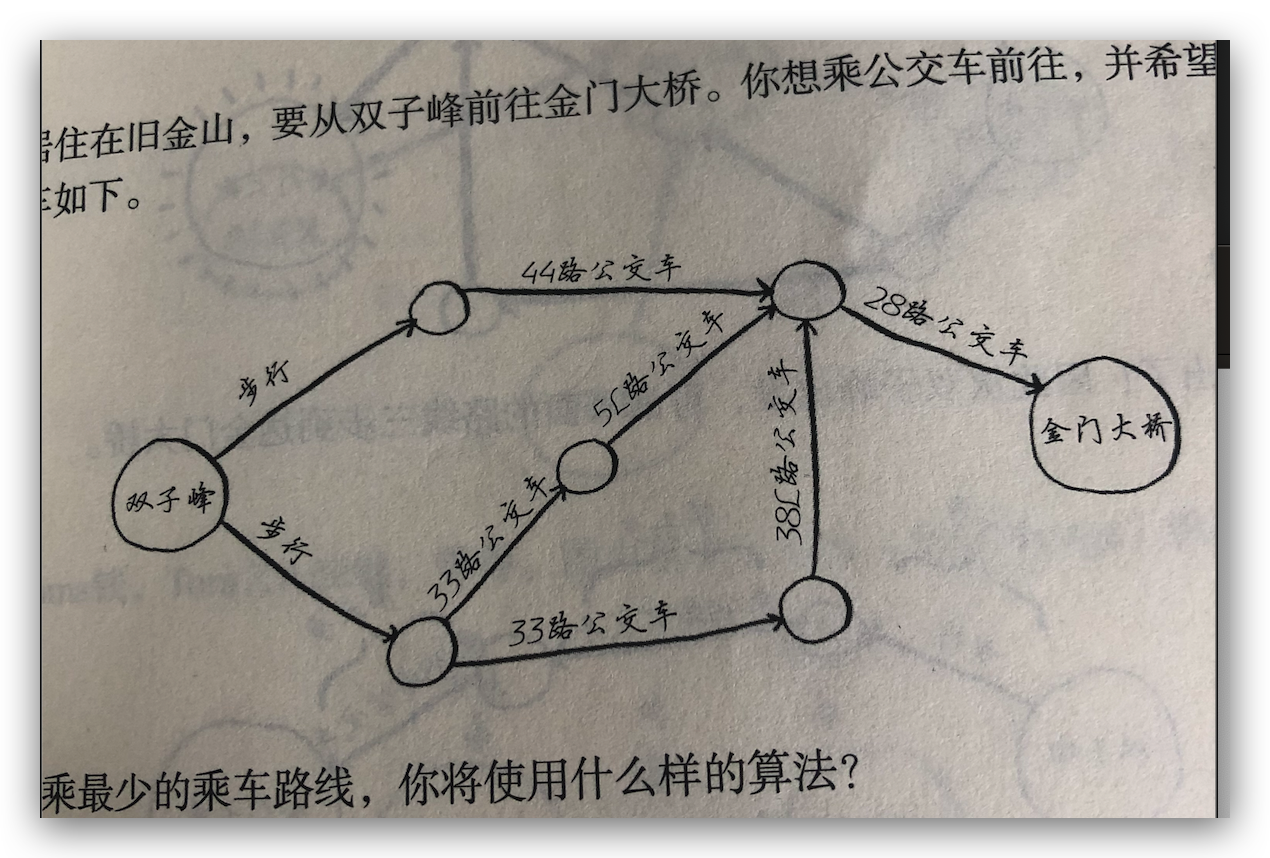
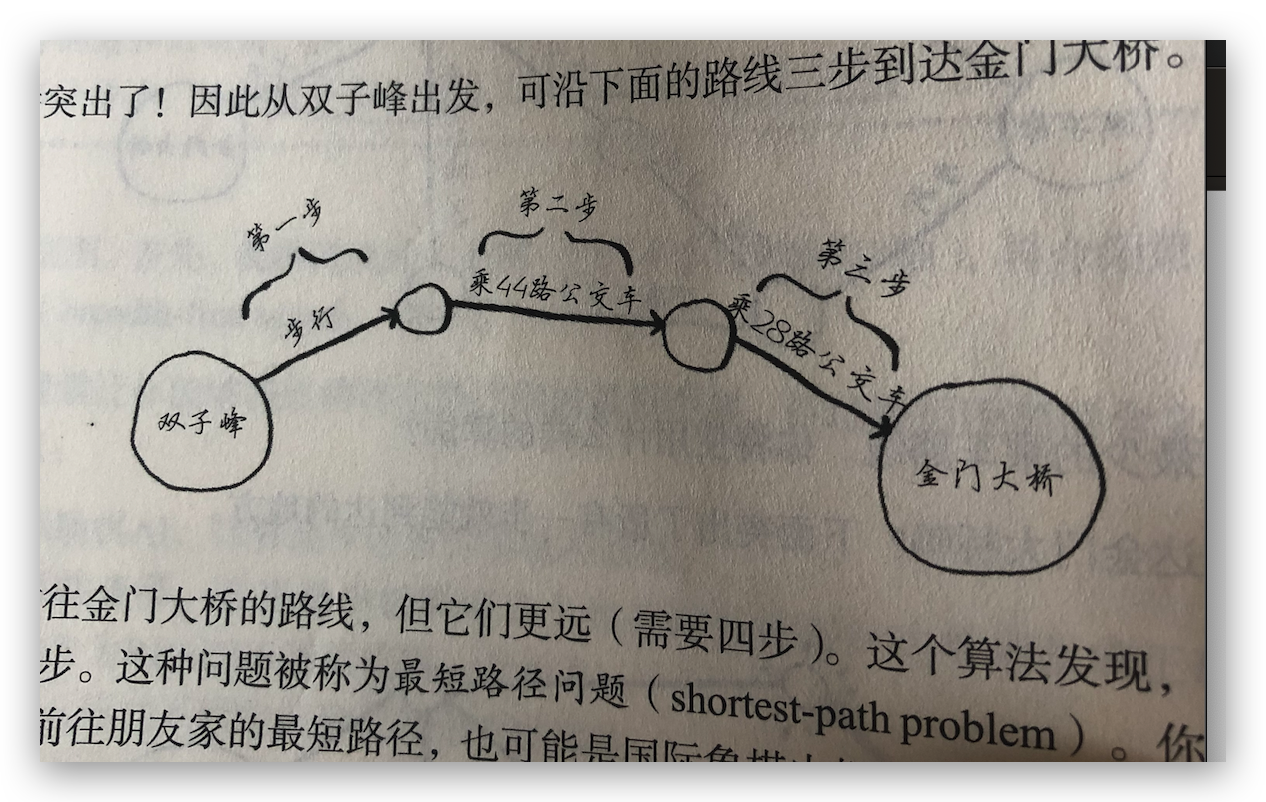
可以从图中得知,到达金门大桥最少需要三步,最短路径是从双子峰步行到搭乘 44 路公交,然后再换乘 28 路公交最短。
第二个例子是这样的,假设你经营一个芒果农场,需要寻找芒果销售商,如何在你自己的朋友关系网中找到芒果销售商,这种关系包括你自己的朋友,这个是一度关系,也包括朋友的朋友,这个是二度关系,依次类推,那怎么找到最短路径呢?
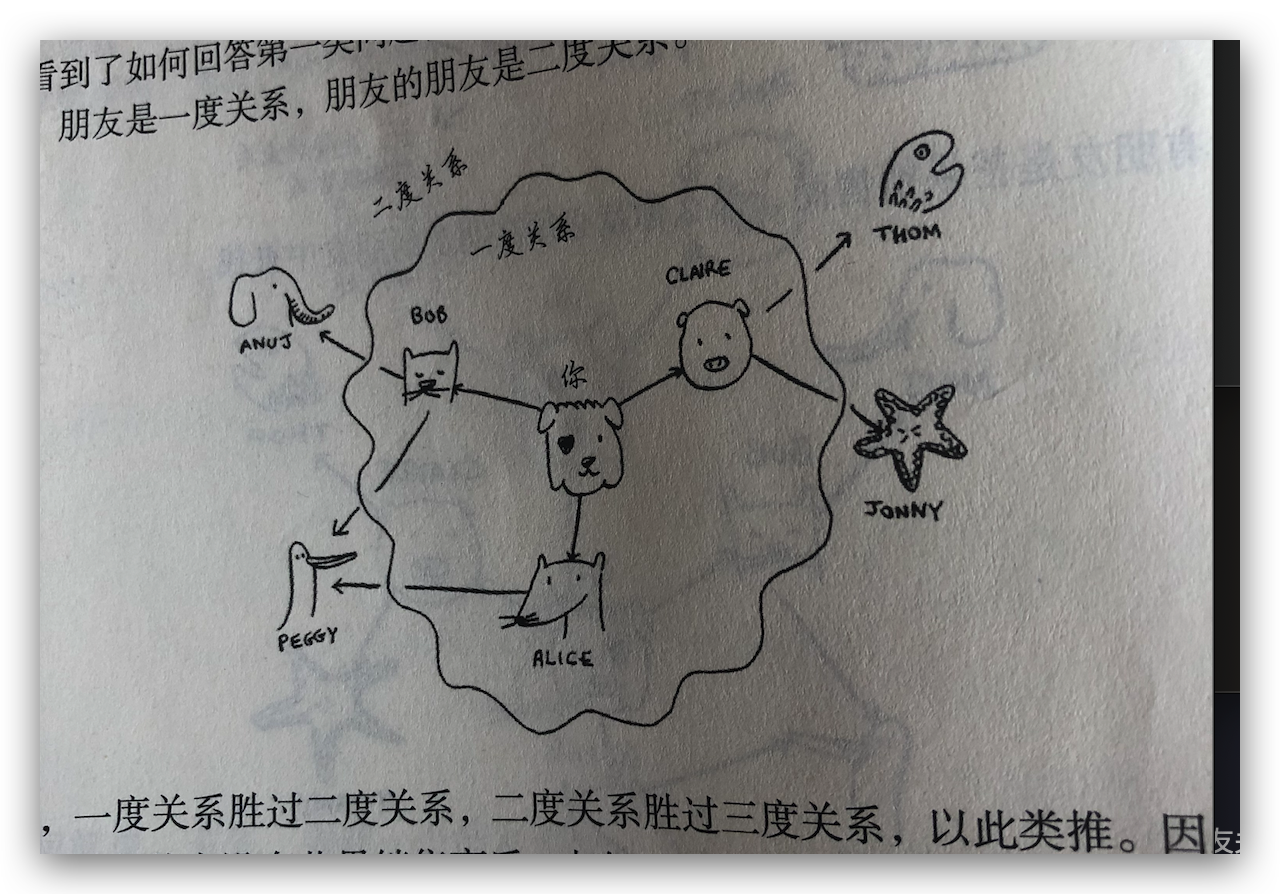
解题思路:
使用散列表来存储关系网,使用队列来存储查找顺序,优先查找一度关系,再二度关系,依次类推。然后遍历队列判断是否是芒果销售商,是的话就是最近的芒果销售商,如果不是,再查找二度关系,如果最后都没有找到就是关系网里面没有芒果销售商。
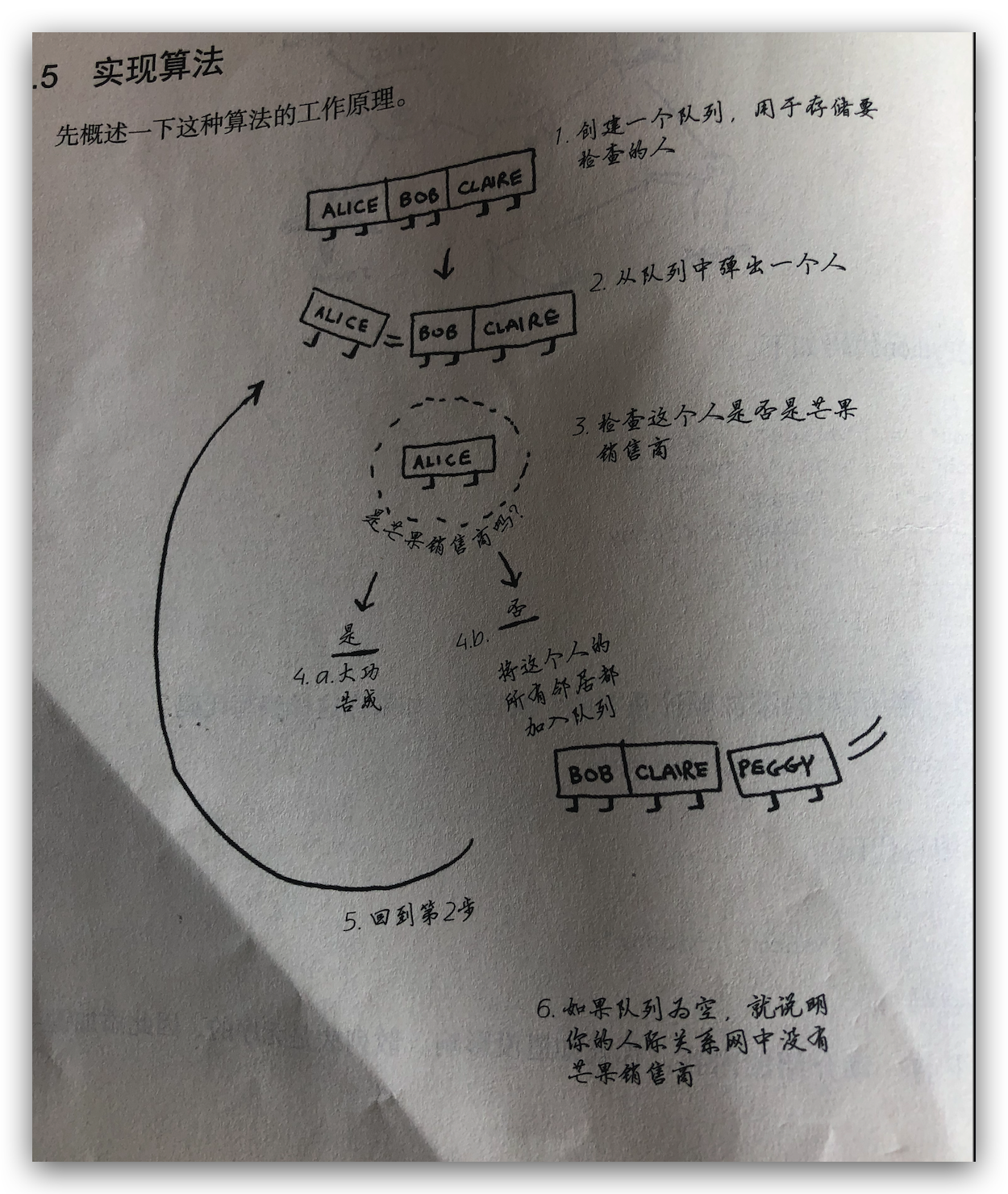
swift 实现代码如下:
// 1. 使用数组来实现一个队列,先进先出
struct Queue<Element> {
private var elements: [Element] = []
init() {
}
var count: Int {
return elements.count
}
var isEmpty: Bool {
return elements.isEmpty
}
// 队列第一个元素
var peek: Element? {
return elements.first
}
// 入队
mutating func enqueue(_ element:Element) {
elements.append(element)
}
// 出队
mutating func dequeue() -> Element?{
return isEmpty ? nil : elements.removeFirst()
}
}
extension Queue: CustomStringConvertible {
var description: String {
return elements.description
}
}
// 2. 使用散列表来存储关系网
var graph = [String:Any]()
// 一度关系
graph["you"] = ["claire", "bob", "alice"]
// 二度关系
graph["bob"] = ["anuj", "peggy"]
graph["claire"] = ["thom", "jonny"]
graph["alice"] = ["peggy"]
// 三度关系
graph["anuj"] = []
graph["peggy"] = []
graph["thom"] = []
graph["jonny"] = []
// 3. 广度优先搜索算法
func search(_ name: String, inGraph g: [String:Any]) -> Bool {
// 搜索队列
var searchQueue = Queue<String>()
// 入队列
for item in g[name] as! Array<String> {
searchQueue.enqueue(item)
}
// 记录已经查找过的人
var searched = [String]()
// 循环结束条件 1. 找到一位芒果销售商;2. 队列为空,意味着关系网里面没有芒果销售商
while !searchQueue.isEmpty {
// 出队
let person = searchQueue.dequeue()
// 判断是否已经检查过,检查过就不再检查,防止出现死循环
if !searched.contains(person!) {
if personIsSeller(person!) {
print("找到了芒果销售商:\(person!)")
return true
} else {
// 寻找下一度关系
// 入队列
for item in g[person!] as! Array<String> {
searchQueue.enqueue(item)
}
// 将这个人标记检查过
searched.append(person!)
}
}
}
// 循环结束,没有找到
return false
}
// 是不是销售商,规则可以随便设置
func personIsSeller(_ name: String) -> Bool {
if let c = name.last {
return c == "y"
}
return false
}
// 测试
search("you", inGraph: graph) // 找到了芒果销售商:jonny
search("bob", inGraph: graph) // 找到了芒果销售商:peggy
狄克斯特算法
深度优先算法BFS适用于无加权图,找出的最短路径是边数最少的路径,而狄克斯特算法解决的是加权图中的最短路径问题,找出的是最经济最划算的路径。
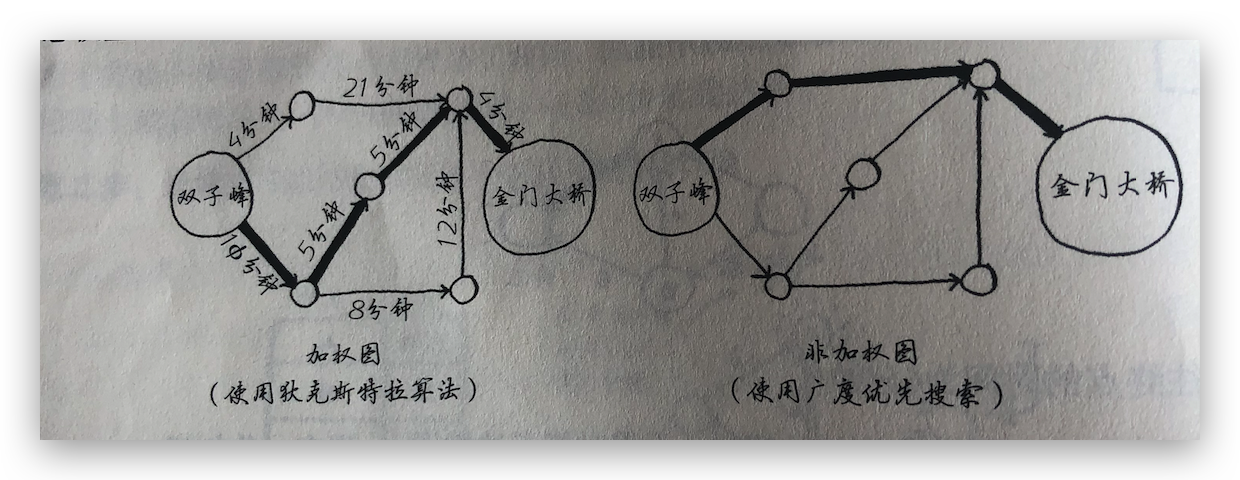
注意:狄克斯特算法也不适用于带环的图,只适用于
有向无环图,也不适用于负权边的图,负权边的图的最短路径问题可以使用贝尔曼-福德算法。
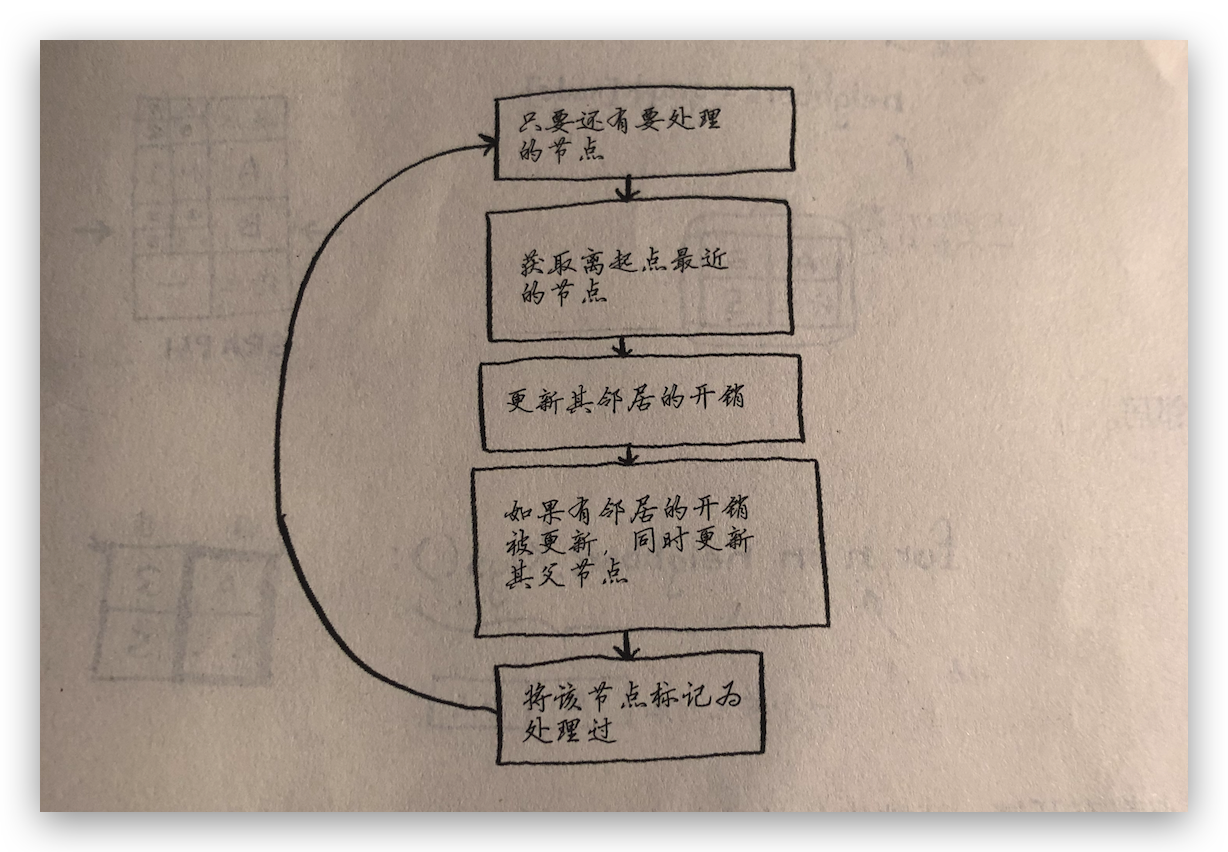
狄克斯特算法包含四个步骤:
- 找出最便宜的顶点,即可在最少权重内到达前往的顶点;
- 对于该顶点的邻居,检查是否有前往他们的更短路径,如果有,就更新其开销;
- 重复这个过程,直到图中的每个顶点都这样做了;
- 计算最终路径;
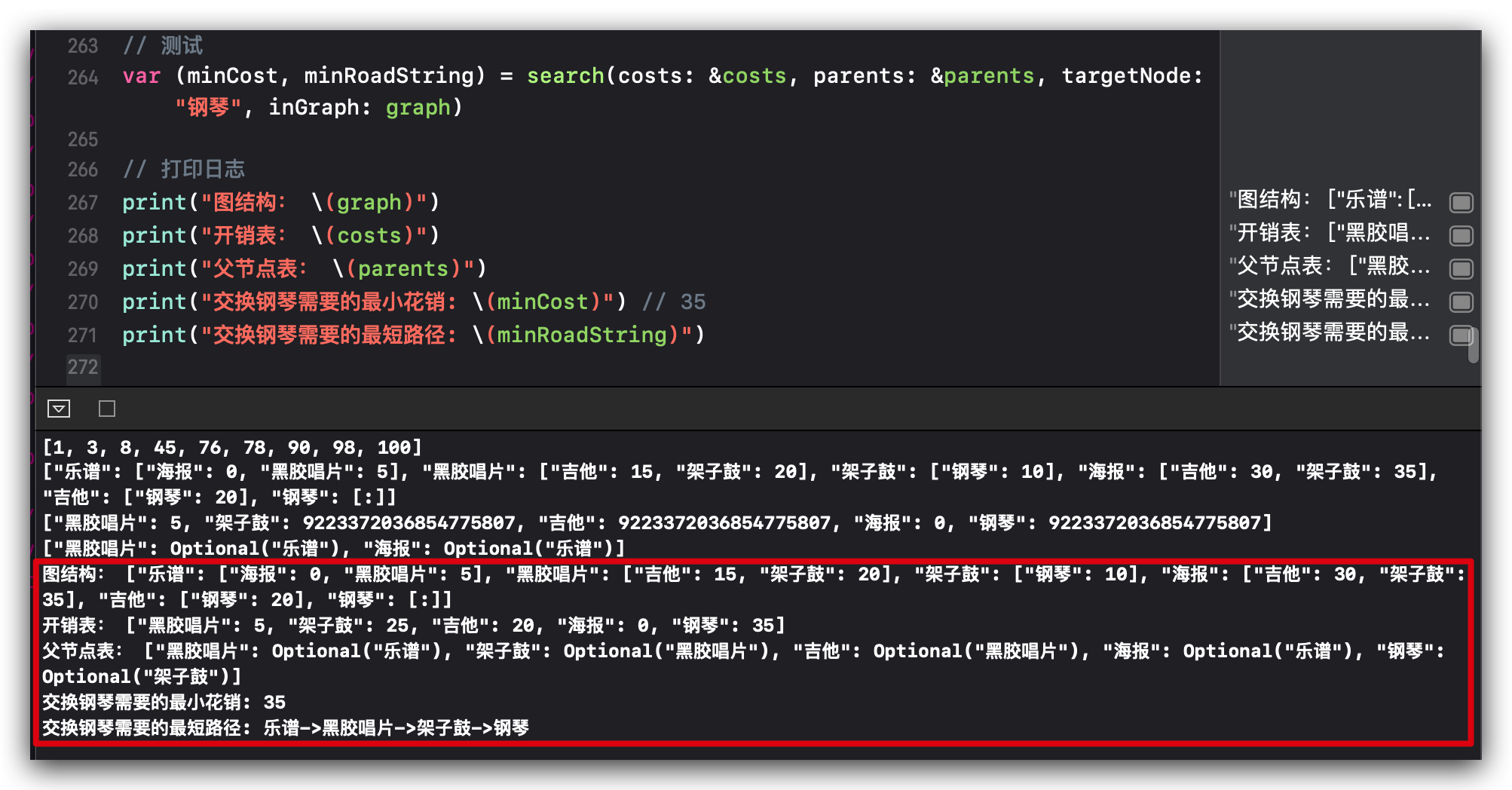
书中举了一个换钢琴的例子,如何用乐谱再加最少的钱换到钢琴的问题,使用狄克斯特算法的解决思路是:
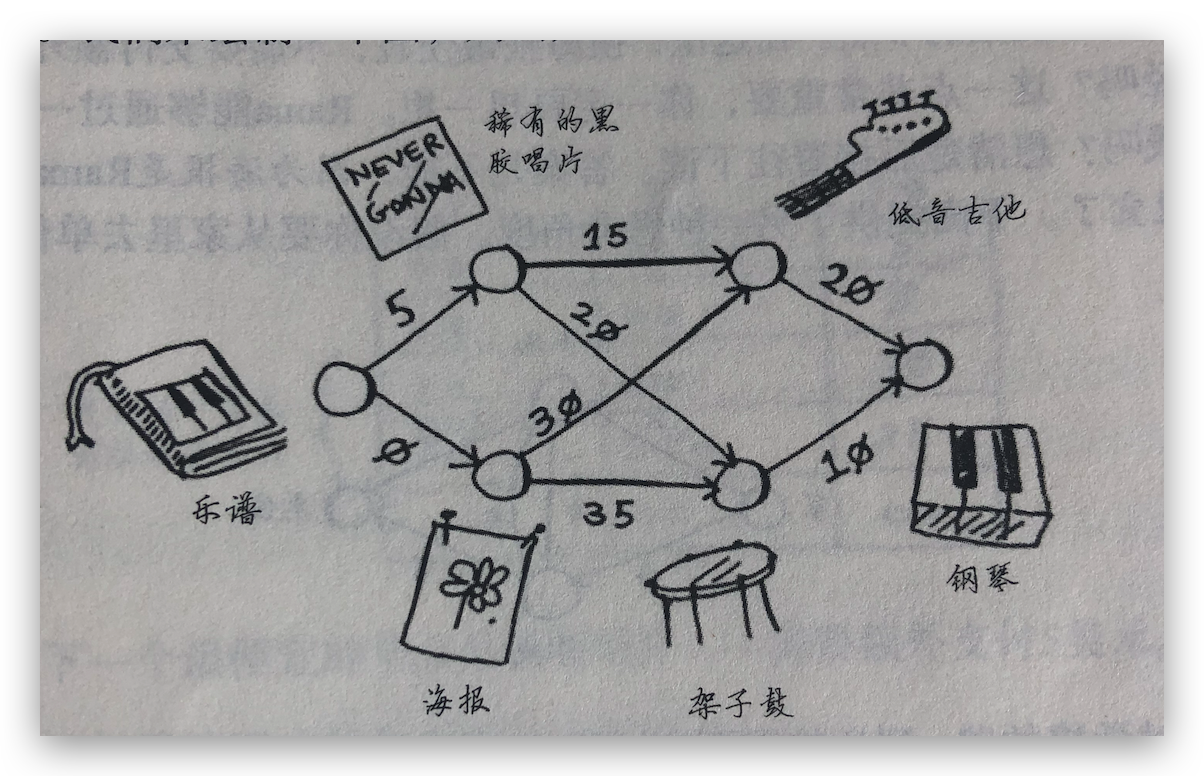
解题思路:
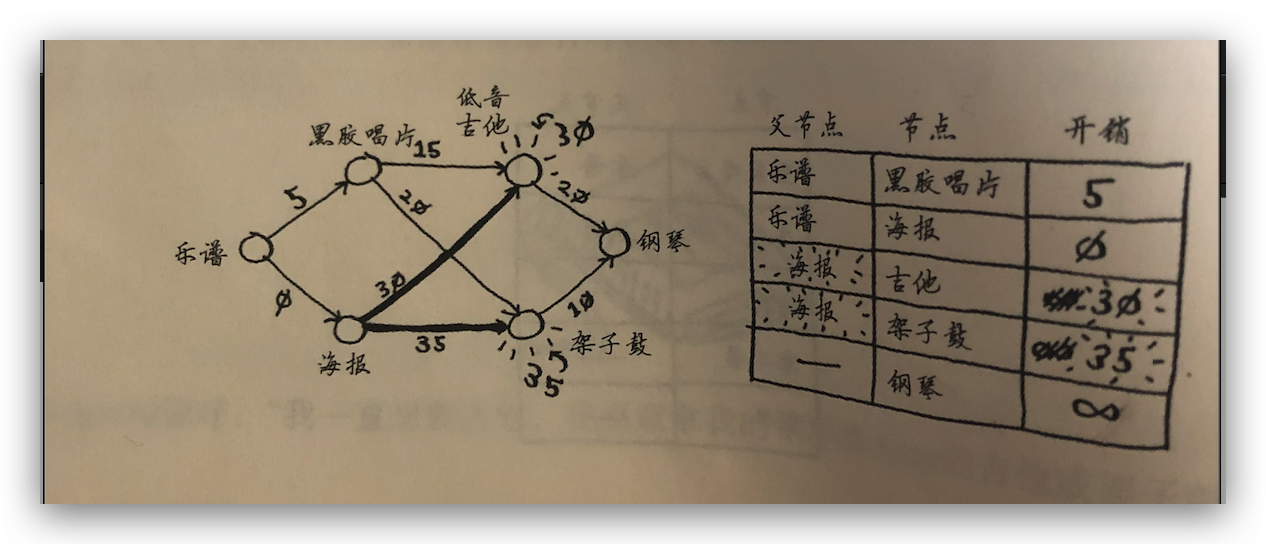
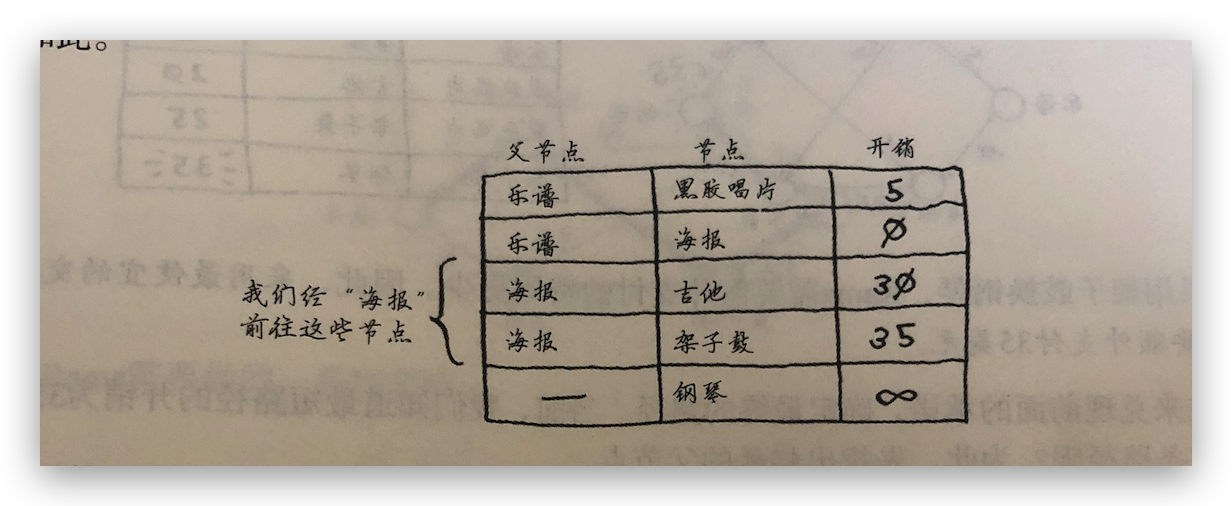
一、找出最便宜的节点,乐普的邻居是唱片和海报,换唱片要支付 5 美元,换海报不用钱。先创建一个表格,记录每个节点的开销以及父节点。所以下一个最便宜的节点是海报。
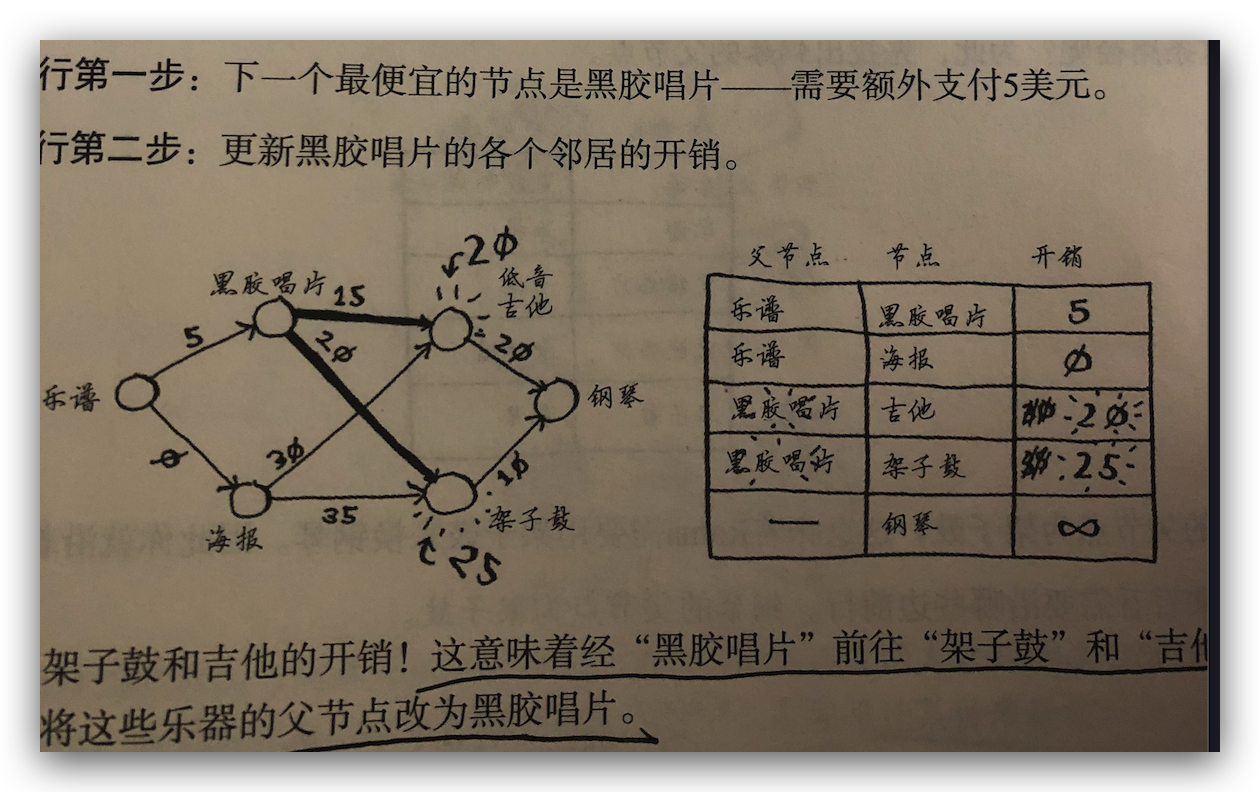
二、计算前往该节点的各个邻居节点的开销。第一步中海报最便宜,所以先从海报出发,海报可以换吉他需要加 30 美元,还可以换架子鼓需要加 35 美元,再计算黑胶唱片,黑胶唱片可以换吉他需要加 15 美元,还可以换架子鼓需要加 20 美元,和第一步的相加可以算出,通过黑胶唱片这条路径前往,开销最短,更新上一步中最便宜的节点为黑胶唱片。从乐普换吉他最少需要花 20 美元,换架子鼓最少需要花 25 美元。所以下一个最便宜的节点是海报。
三、优先从吉他出发,计算其邻居节点开销。吉他的邻居就是钢琴,需要加 20 美元,总开销加上之前的 20 美元是 40 美元,再从架子鼓出发,计算架子鼓到其邻居节点的开销,架子鼓的邻居节点也是钢琴,开销 10 美元,加上之前的 25 美元总开销是 35 美元,所以更新最优节点是架子鼓。
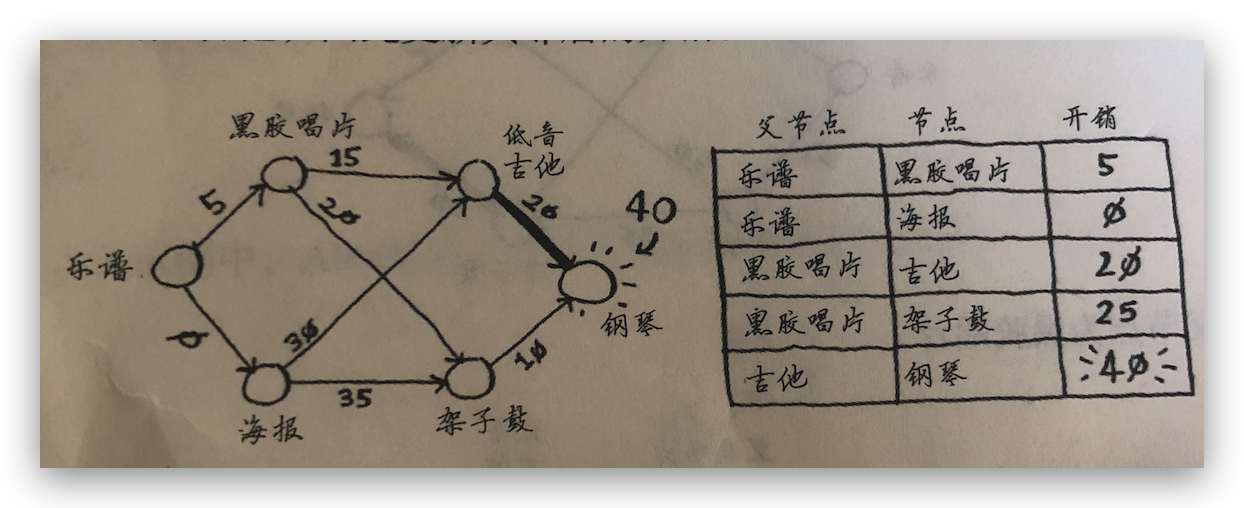
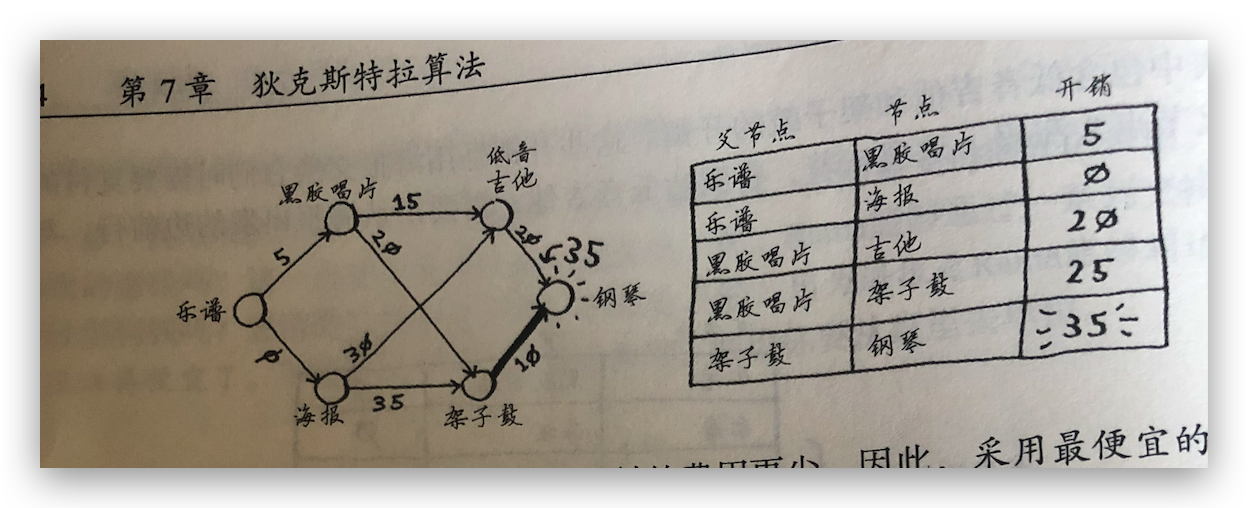
最终路径是从乐谱->黑胶唱片->架子鼓->钢琴。
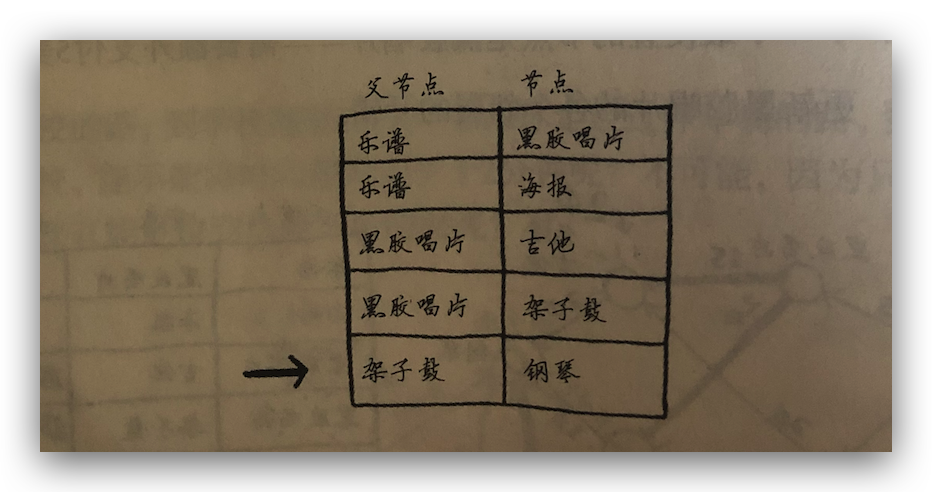
算法实现
需要三个散列表,一个用来存储整个图结构,一个用来存储节点的开销,最后一个用来存储节点的父节点。算法执行流程图:
// 狄克斯特搜索算法
// 参数g:图形结构散列表
// costs:节点开销散列表 inout 关键字可以是得函数内部可以修改外部参数的值
// parents: 父节点散列表
// targetNode:目标节点
// 返回值:(总的最少花销,最短路径步骤,排序数组)
func search(costs:inout [String :Int], parents:inout [String: String?], targetNode: String, inGraph g: [String : Any]) ->(Int, String)
{
// 存储处理过的节点
var processed = [String]()
// 找出最便宜的节点
func findLowerCostNode(_ costs: [String:Int]) -> String? {
var lowestCost = Int.max
var lowerCostNode: String?
for (key, value) in costs {
// 遍历开销散列表,找出没有处理过且到起点花费最小开销的节点
if value < lowestCost && !processed.contains(key){
lowestCost = value
lowerCostNode = key
}
}
return lowerCostNode
}
var node = findLowerCostNode(costs)
// 遍历所有的节点
while (node != nil) {
// 节点开销
let cost = costs[node!]
// 遍历当前节点的所有的邻居节点
var neighbors = graph[node!]
for n in (neighbors?.keys)! {
// 判断该邻居节点如果从当前节点经过的总开销是否小于该邻居节点原来的开销,如果小于,就更新该邻居节点的开销
let new_cost = cost! + (neighbors?[n])!
if costs[n]! > new_cost {
// 更新该节点的邻居节点的最新最短开销
costs[n] = new_cost
// 更新该邻居节点的父节点为当前节点
parents[n] = node!
}
}
// 将当前节点标记为已经处理过的节点
processed.append(node!)
// 继续寻找下一个最少开销且未处理过的节点
node = findLowerCostNode(costs)
}
// 到达目标节点的最少开销
let minCost = costs[targetNode]
// 最短路径
var minRoadArray = [targetNode]
var parent:String? = targetNode
while parents[parent!] != nil {
parent = parents[parent!]!
minRoadArray.append(parent!)
}
return (minCost!, minRoadArray.reversed().joined(separator: "->"))
}
// 测试 ————————————————————-------------------------------------------
// 1. 存储图结构
var graph = [String : Dictionary<String, Int>]()
// 乐谱的邻居节点
graph["乐谱"] = [String : Int]()
// 到唱片的开销
graph["乐谱"]?["黑胶唱片"] = 5
// 到海报的开销
graph["乐谱"]?["海报"] = 0
// 唱片节点的邻居节点
graph["黑胶唱片"] = [String : Int]()
// 唱片节点到吉他的开销
graph["黑胶唱片"]?["吉他"] = 15
// 唱片节点到架子鼓的开销
graph["黑胶唱片"]?["架子鼓"] = 20
// 海报节点的邻居节点
graph["海报"] = [String : Int]()
// 海报节点到吉他的开销
graph["海报"]?["吉他"] = 30
// 海报节点到架子鼓的开销
graph["海报"]?["架子鼓"] = 35
// 吉他节点的邻居节点
graph["吉他"] = [String : Int]()
// 吉他节点到钢琴的开销
graph["吉他"]?["钢琴"] = 20
// 架子鼓节点的邻居节点
graph["架子鼓"] = [String : Int]()
// 架子鼓节点到钢琴的开销
graph["架子鼓"]?["钢琴"] = 10
// 钢琴节点
graph["钢琴"] = [String : Int]()
print(graph)
// 2. 创建开销表,表示从乐谱到各个节点的开销
var costs = [String : Int]()
// 到海报节点开销
costs["海报"] = 0
// 到黑胶唱片节点开销
costs["黑胶唱片"] = 5
// 到钢琴节点开销,不知道,初始化为最大
costs["吉他"] = Int.max
// 到钢琴节点开销,不知道,初始化为最大
costs["架子鼓"] = Int.max
// 到钢琴节点开销,不知道,初始化为最大
costs["钢琴"] = Int.max
print(costs)
// 3. 创建父节点表
var parents = [String : String?]()
// 海报节点的父节点是乐谱
parents["海报"] = "乐谱"
// 黑胶唱片的父节点是乐谱
parents["黑胶唱片"] = "乐谱"
// 吉他的父节点,不知道
parents["吉他"] = nil
// 架子鼓的父节点,不知道
parents["架子鼓"] = nil
// 钢琴的父节点, 不知道
parents["钢琴"] = nil
print(parents)
// 测试
var (minCost, minRoadString) = search(costs: &costs, parents: &parents, targetNode: "钢琴", inGraph: graph)
打印日志:
贪婪算法
贪婪算法是一种通过寻找局部最优解来试图获取全局最优解的一种易于实现、运行速度快的近似算法。是解决 NP 完全问题(没有快速算法问题)的一种简单策略。书上总共举了四个例子来说明贪婪算法的一些场景。
1. 教师调度问题
有如下课程表,要怎么排课调度,使得有尽可能多的课程安排在某间教室上。
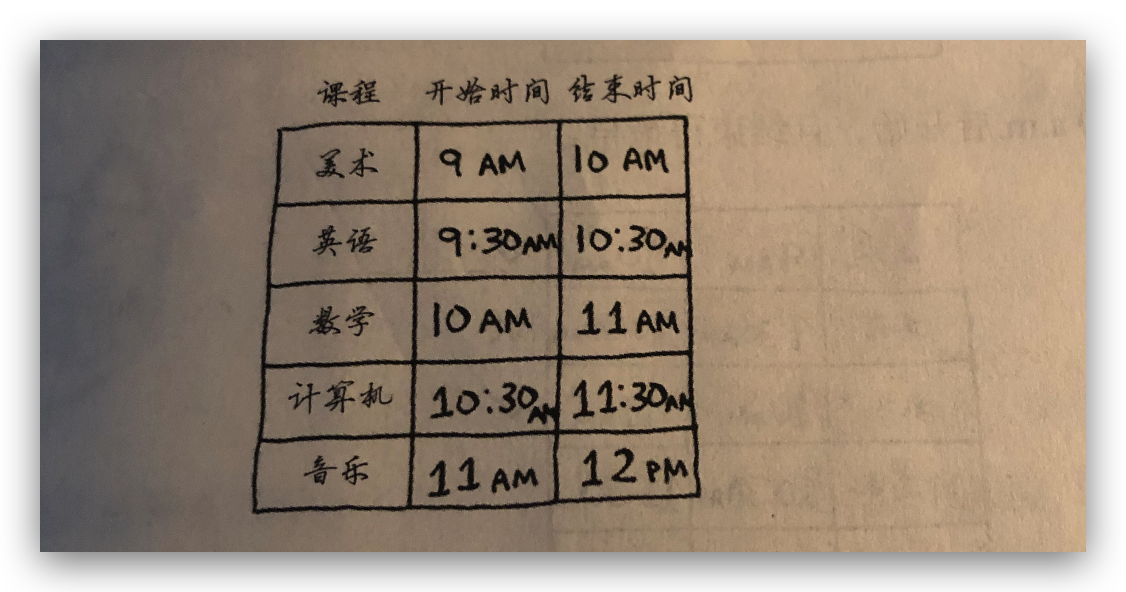
这个问题就可以使用贪婪算法来解决。
- 选出结束最早的课,他就是要在这件教室上的第一节课。
- 接着,选择第一节课结束后才开始的课,同样选择结束最早的课,这就是要在这件教室上的第二节课。重复这样做,就能找出答案。

2. 背包问题
这个问题是这样的,如何在容量有限的背包中装入总价值最高的商品。这个问题不适用贪婪算法,按照贪婪算法,每次都需要往背包里先装最大价值的商品,然后根据背包剩余容量,再选择最大价值的商品,这样有可能背包的空间利用率不是最高的,却不一定会是最优解。
2. 集合覆盖问题
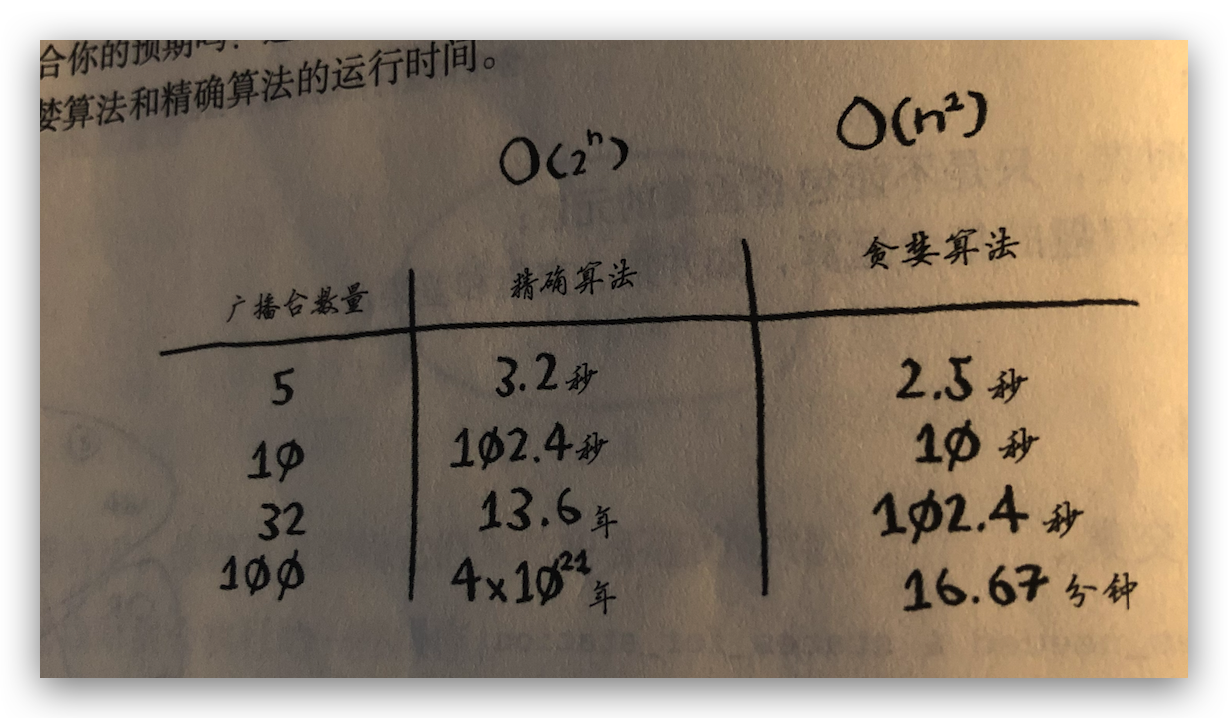
背景是这样的,有个广播节目,要让全美 50 各州的听众都能听到,需要在选出覆盖全美 50 各州的最小广播台集合。如果要需求最优解,可能的子集有 2^n 次方个,如果个广播台很多,那么这个算法的复杂度将非常之高,几乎没有任何算法可以足够快速的解决这个问题,而使用贪婪算法可以快速的找到近似解,算法的复杂度是 O(n^2)。步骤如下:
- 选择一个覆盖最多未覆州的广播台,即时已经覆盖了一些已经覆盖过的州也没关系。
- 重复第一步,知道覆盖了所有的州。
代码模拟实现:
// 要覆盖的州列表
var statesNeeded = Set(["mt", "wa", "or", "id", "nv", "ut", "ca", "az"])
// 广播台清单
var stations = [String: Set<String>]()
stations["kone"] = Set(["id", "nv", "ut"])
stations["ktwo"] = Set(["wa", "id", "mt"])
stations["kthree"] = Set(["or", "nv", "ca"])
stations["kfour"] = Set(["nv", "ut"])
stations["kfive"] = Set(["ca", "az"])
// 最终选择的广播台集合
var finalStations = Set<String>()
// 如果要覆盖的州列表不为空
while !statesNeeded.isEmpty {
// 覆盖了最多没覆盖州的广播台
var bestStation:String?
// 已经覆盖了的州的集合
var statesCovered = Set<String>()
// 遍历所有的广播台
for (station, states) in stations {
// 取交集操作
let covered = statesNeeded.intersection(states)
if covered.count > statesCovered.count {
bestStation = station
statesCovered = covered
}
}
// 取差集操作
statesNeeded = statesNeeded.subtracting(statesCovered)
finalStations.insert(bestStation!)
}
// 打印
print(finalStations) // ["ktwo", "kfive", "kone", "kthree"]
对比一下两种算法的运行效率差异:
3. 旅行商问题
旅行商问题的背景是一个旅行商商想要找出前往若干个城市的最短路径,如果城市数量少,比如两个,可能的路径有 2 条,三个城市有 有 6 条,4 个城市有 24 条,5 个城市有 120 条,n 个城市有 n! 个可能路线,n! 复杂度是一种非常难以快速找出最优解的问题。就可以考虑贪婪算法快速地去求近似解。
4. 如何判断 NP 完全问题
上面的集合覆盖问题和旅行商问题都是 NP 完全问题,如果能够判断出问题属于 NP 完全问题,就可以考虑贪婪算法求近似解的策略了,但是判断 NP 完全问题并不容易,作者归纳了一些常见场景:
- 随着元素增加,速度会变得非常慢。
- 涉及
所有组合的问题通常是 NP 完全问题。 - 不能将问题分成小问题,必须考虑各种可能的情况。也可能是 NP 完全问题。
- 如果问题涉及序列(如旅行商问题中的城市序列)且难以解决,可能就是 NP 完全问题。
- 如果问题涉及集合(如广播台集合的例子)且难以解决,可能就是 NP 完全问题。
- 如果问题可转换成
集合覆盖问题或者旅行商问题,那肯定是 NP 完全问题。
动态规划
动态规划常用来解决一些在给定约束条件下的最优解问题,如背包问题的约束条件就是背包的容量,一般可以将大问题分解为彼此独立且离散的小问题时,可以通过使用网格,每个小网格就是分解的小问题的手段的方式来解决。使用动态规划来解决的实际问题场景有:
- 最长公共子串、最长公共子序列来判断两个字符串的相似程度。生物学家通过最长公共序列来确定 DNA 链的相似性。
- git diff 文件对比命令,也是通过
动态规划实现的。 - word 中的断字功能。
K 最近邻算法
KNN 用来分类和回归,分类是编组,回归是预测一个结果。通过特征抽取,大规模训练,然后比较数据之间的相似性,从而分类或是预测一个结果。有如下常见应用场景:
- 推荐系统。
- 机器学习。
- OCR(光学字符识别),计算机通过浏览大量的数字图像,并将这个图像的特征提取出来,遇到新图像时,从数据中寻找他最近的邻居。
- 垃圾邮件过滤器,通过使用
朴素贝叶斯分类器计算出邮件为垃圾邮件的概率。 - 预测股票市场。
其他一些算法介绍
- 树,二叉查找树,左子节点的值总比自己小,右子节点的值总比自己大,可以用来优化数组插入和删除的复杂度底的问题,二叉查找树的查找、插入、删除的复杂度都是O(logn)。
- 反向索引。一种将单词映射到包含他的页面的数据结构,可用于创建
搜索引擎。 - 傅里叶变换。傅里叶变换可以将数字信号中的各种频率分离出来,可计算歌曲中每个音符对整个音乐的贡献,用来做音乐压缩,音乐识别等。
- 并行算法。利用设备的多核优势,提高算法的执行性能。也会有一些额外开销,如并行性管理和负载均衡。
- MapReduce。一种分布式并行算法,可让算法在多台计算机上运行,非常适合用于在短时间内完成海量工作,MapReduce的两个概念,映射(map)和归并(reduce)函数。映射(map)是将序列中的元素都执行一种处理然后返回另一个序列,归并(reduce)是序列归并为一个元素。MapReduce 使用这个两个概念在多台计算机上执行数据查询,能极大的提高速度。
- 布隆过滤器和 HypelogLog。布隆过滤器是一种
概率性数据结构,有点在于占用空间小,非常适用于不要求答案绝对准确的情况。HypelogLog 近似地计算集合中不同的元素数,也是类似于布隆过滤器的一种概率性算法。 - SHA 算法。SHA 算法是一种安全散列算法,给定一个字符串,SHA 算法返回其散列值,可用来比较文件,检查密码。
- 局部敏感散列算法。Simhash 是一种
局部敏感散列算法。如果字符串只有细微的差别,那么散列值也只存在细微的差别,这就能够用来通过比对散列值来判断两个字符串的相似程度,也很有用。 - Diffie-Hellman 秘钥交换算法。可用来解决
如何对消息加密后只有收件人能看懂的问题。这个种算法使用两个秘钥,公钥和私钥,公钥是公开的,发送消息使用公钥加密,加密后的消息只有使用私钥才能解密。通信双方无需知道加密算法,要破解比登天还难。 - 线性规划。线性规划算法用于在
给定约束条件下最大限度地改善指定的指标。线性规划使用 Simplex 算法,是一种非常宽泛的算法,如所有的图算法都可以用线性规划来实现,图问题只是线性规划的一个子集。
扩展阅读
分享个人技术学习记录和跑步马拉松训练比赛、读书笔记等内容,感兴趣的朋友可以关注我的公众号「青争哥哥」。

