

本文会针对树这种数据结构,进行相关内容的阐述。其实本文应该算是一篇读书笔记。
内容总览
- 树
- 二叉树
- 二叉查找树
- 堆和堆的一些操作
- 堆排序
- 堆的应用
另外,我先在这里给出 js 实现的源码地址:
树
这里简单说下树是什么。
树是一种非线性的数据结构。树中的元素称为“节点”。每个节点有有限个子节点或没有子节点,且树中不能有环路。
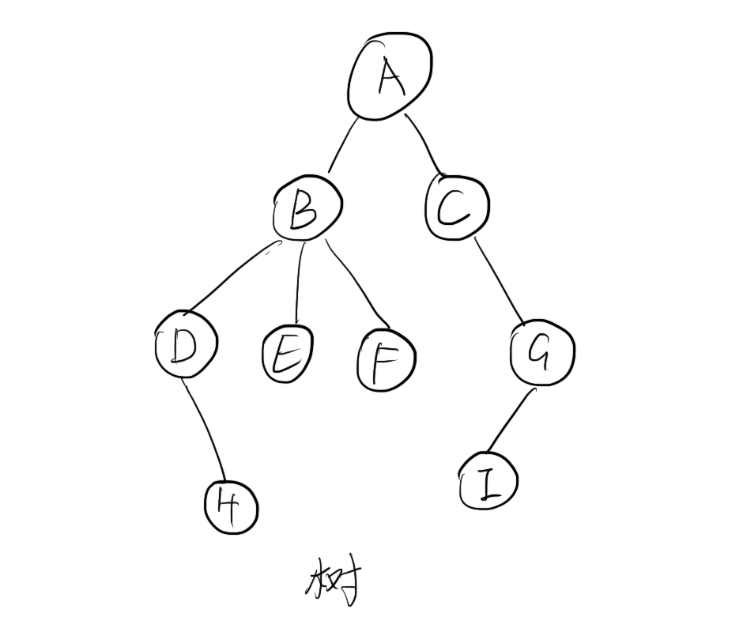
两个相连的节点的关系称为 “父子关系”。
一些术语(摘自维基百科):
- 节点的度:一个节点含有的子树的个数称为该节点的度;
- 树的度:一棵树中,最大的节点的度称为树的度;
- 叶节点或终端节点:度为零的节点;
- 非终端节点或分支节点:度不为零的节点;
- 父亲节点或父节点:若一个节点含有子节点,则这个节点称为其子节点的父节点;
- 孩子节点或子节点:一个节点含有的子树的根节点称为该节点的子节点;
- 兄弟节点:具有相同父节点的节点互称为兄弟节点;
- 节点的层次:从根开始定义起,根为第1层,根的子节点为第2层,以此类推;
- 深度:对于任意节点n,n的深度为从根到n的唯一路径长,根的深度为0;
- 高度:对于任意节点n,n的高度为从n到一片树叶的最长路径长,所有树叶的高度为0;
- 堂兄弟节点:父节点在同一层的节点互为堂兄弟;
- 节点的祖先:从根到该节点所经分支上的所有节点;
- 子孙:以某节点为根的子树中任一节点都称为该节点的子孙。
- 森林:由m(m>=0)棵互不相交的树的集合称为森林;
二叉树
树有很多种类,比如二叉树、三叉树、四叉树等。但最常用的树就是二叉树。
二叉树是每个节点最多只有两个分支的树结构,这两个分支的节点被称为 左子节点 和 右子节点。
满二叉树,指的是除了叶子节点,每个节点都有两个子节点的二叉树。
完全二叉树:除了最后一层,其他层的节点个数都要最大,且最后一层的节点都靠左排列的二叉树。

可能有人觉得完全二叉树看起来好像没什么用,怎么还靠左边的,靠中间不行吗?其实靠左是因为二叉树的其中一种数据存储方式是用数组存储,使用完全二叉树就不会浪费数组的空间(不会出现一些数组元素不存储的情况)
二叉树的存储
1. 链式存储法
链式存储法,是通过指针的方式来记录父子关系的一种方法。它有点类似链表,每个节点除了保存自身的数据外,还会有left 和 right 两个指针,指向另外两个节点。
const node = {
data: 1, // 节点保存的数据
left: node2, // 左子节点指向 node2 节点
right: null // null 表示没有右子节点
}
2. 顺序存储法
用数组存储。为了代码可读性更好,我们一般会选择浪费数组下标为 0 的存储位置,即根节点在下标为 1 的位置。 这时父节点和左右节点的下标关系如下:
left = 2 * i;
right = 2 * i + 1;
i = left / 2;
i = right / 2; // 这里是向下取整
这里的 i 为父节点下标,left 和 right 为两个子节点下标。
这里有个要注意的地方:这里的父节点的下标值是子节点除以 2 并 取整。(有些编程语言的整数相除,会自动将得到的结果去掉小数部分,而一些编程语言,比如 Javascript,是会得到小数的,需要手动向下取整。)
如果你就是不想浪费数组的第一个元素的存储位置,誓要将根节点保存在数组的第一个位置。那此时父节点和子节点的下标关系为:
left = 2 * i + 1;
right = 2 * i + 2;
i = (left - 1) / 2;
i = (right - 1) / 2;
如果某棵二叉树是一棵完全二叉树,那用数组存储无疑是最节省内存的一种方式。
二叉树的遍历
这个是很常见的面试题呢。
1. 前序遍历
根左右。 这里的“前”描述的是根节点,即根节点最先输出(打印),然后输出左子树,最后输出右子树。
代码中的树是用 链式存储法 存储的。代码实现用到了 递归。
// 前序遍历(根左右)
preOrder() {
let order = '';
r(this.root);
order = order.slice(0, order.length - 1); // 这里只是去掉最后的一个逗号。
return order;
// 递归函数
function r(node) {
if (!node) return;
order += `${node.val},`;
r(node.left);
r(node.right);
}
},
2. 中序遍历
左根右。 “中序”的这个“中”也是指的根节点的输出位置是中间。中序遍历先输出左子树,再输出根节点,最后输出右子树。
// 中序遍历
inOrder() {
let order = '';
r(this.root);
order = order.slice(0, order.length - 1);
return order;
// 递归函数
function r(node) {
if (!node) return;
r(node.left);
order += `${node.val},`;
r(node.right);
}
},
3. 后续遍历
左右根。 先打印左子树,然后打印根节点,最后打印右子树。
postOrder() {
let order = '';
r(this.root);
order = order.slice(0, order.length - 1);
return order;
// 递归函数
function r(node) {
if (!node) return;
r(node.left);
r(node.right);
order += `${node.val},`;
}
},
4. 层次遍历
层次遍历,就是每层的节点从左往右遍历,直到遍历完所有节点。如果是顺序存储法存储的,数组从前往后遍历即可。如果是链式存储法存储树,实现就会复杂一些,要用到一个队列
levelOrder() {
if (this.root == null) return '';
let a = [],
left, right;
a.push(this.root);
// 节点入队,指针指向头部元素,如果它有left/right,入队。
// 指针后移,继续同样步骤。。。直至指针跑到队列尾部后面去。。。
for(let i = 0; i < a.length; i++) { // 需要注意的是,数组 a 的长度是动态变化的(不停变长)
left = a[i].left;
if (left) a.push(left);
right = a[i].right;
if (right) a.push(right);
}
return a.map(item => item.val).join(',');
}
二叉查找树
二叉查找树,也叫做 二叉搜索树。此外它也被称为 二叉排序树,因为中序遍历就可以得到有序的数据序列(非常高效,时间复杂度是 O(n))。
二叉查找树的作用是快速查找。除了快速查找,它也支持快速插入、删除数据。
那么什么样的二叉树才是二叉查找树呢?二叉查找树是任意一个节点的左子树的节点都小于该节点,任意一个节点的的右子树的节点都大于该节点的二叉树。
根据定义,二叉查找树是 不允许有两个数据相同的节点的。
二叉查找树的查找操作
先和根节点的值比较,如果相等,就找到了;如果要查找的值比根节点小,就在左子树中递归查找;如果比根节点大,就在右子树中递归查找。
find(val) {
// 假设二叉树没有重复数据
let p = this.root;
while(p != null) {
if (val == p.val) return p;
else if (val < p.val) p = p.left;
else p = p.right;
}
return null; // 没找到
},
二叉查找树的插入操作
类似查找操作。从根节点开始,比较要插入的数据和节点的大小关系。如果要插入的数据比当前节点的数据大,且右子树为空,就作为该节点的右子节点;如果右子树不为空,就继续递归右子树。同理,比当前节点数据小,就看该节点的左子树,若为空,插入到左子节点位置;若不为空,就递归左子树。
// 插入节点
insert(val) {
if (this.root == null) {
this.root = node;
return true;
}
let node = new Node(val);
let p = this.root;
while (p != null) {
if (val < p.val) {
if (p.left == null) {
p.left = node;
return this.inOrder();
// 返回个中序遍历的结果,检查插入是否正确。(你可以改为 true,表示插入成功)
}
p = p.left;
}
else if (val > p.val) {
// preP = p;
if (p.right == null) {
p.right = node;
return this.inOrder();
}
p = p.right;
}
if (val == p.val) {
console.warn('二叉树中含相同值的数据,无法插入')
return false;
}
}
},
二叉查找树的删除操作
这个就很复杂,要分三种情况:
- 要删除的节点没有子节点:直接更新父节点指向其的指针为 null
- 要删除的节点只有一个子节点:父节点中指向要删除的节点的指针,更新为要删除节点的那个子节点。
- 要删除的节点有两个子节点:找到右子树中的最小节点(一般是叶子节点),替换到要删除的节点上。(当然你也可以选择找左子树的最大节点)
// 删除
remove(val) {
// 假设二叉树没有重复数据
let p = this.root;
let parent, dir; // 暂不考虑只有根节点一个的情况。
while(p != null) {
if (val == p.val) {
// 要删除的节点没有子节点
if (p.left == null && p.right == null) {
parent[dir] = null;
return true;
}
// 要删除的节点只有一个子节点
else if (p.left == null && p.right != null) {
parent[dir] = p.right
console.log('只有右节点');
return true;
} else if (p.right == null && p.left != null) {
parent[dir] = p.left;
console.log('只有左节点');
return true;
}
// 要删除的节点有两个子节点
// 可以将右子树的最小结点替换到被删除的节点位置,并删除这个最小节点
// 当然你也可以在左子树中找最大节点。
else if (p.left != null && p.right != null) {
// 因为要记录最小节点的父节点,所以不能用 this.findMin()
// 第一步:找出最小节点 minP
let minParent,
minP = p;
while (minP) {
if (minP.left == null) {
// 找到。
break;
// return minP;
}
minParent = minP;
minP = minP.left;
}
// 第二步:替换(把数据转移过去即可)
p.val = minP.val;
// 第三步:删除最小节点
if (minP.right == null) {
minParent.left = null;
console.log('最小节点没有子节点');
return true;
} else if (minP.right != null) {
minParent.left = minP.right;
console.log('最小节点只有右节点');
return true;
}
}
return p;
}
// 继续找要删除的节点。
else {
parent = p;
if (val < p.val) {
p = p.left;
dir = 'left';
} else {
p = p.right;
dir = 'right';
}
}
}
return null; // 没找到
// 要保存父节点,且要记录当前节点是父节点的 left 还是 right。
},
还有另一种简单的删除操作,就是标记一个节点为“已删除”,虽然操作变得简单了,但“已删除”的数据仍然在内存中,会浪费内存空间。
支持重复数据的二叉查找树
一般来说,根据定义,二叉查找树是不允许有重复数据的。但实际开发中,数据一般不可能不重复。所以我们看看怎么使二叉查找树支持重复数据存储:
- 节点改为可以存储多个数据,而不是只有一个数据。可以考虑链表和动态扩容数组。
- 插入过程中,如果发现已经有重复的数据了,就放到这个节点的右子树的最左节点的位置(当然你也可以考虑放到左子树的最右边节点位置)。如果是这样的实现的话,查找操作和删除操作就要跟着做一些小修改。
平衡二叉树
维基百科的定义:平衡二叉搜索树(英语:Balanced Binary Tree)是一种结构平衡的二叉搜索树,即叶节点高度差的绝对值不超过1,并且左右两个子树都是一棵平衡二叉树。它能在O(logn)内完成插入、查找和删除操作,最早被发明的平衡二叉搜索树为AVL树。
平衡二叉树的发明,是为了解决二叉树在不断插入、删除等动态操作后,导致时间复杂度退化的问题。它会让二叉树尽量地保持平衡,即保持 矮矮胖胖* 的样子。
平衡二叉树中,最为有名的就是 红黑树 了。是不是经常有群友开玩笑说他们招人,要求当场手写红黑树呢。红黑树的性能很好,广泛用于实际开发中,其他的平衡二叉树则很少出现在人们的视野之中。
平衡二叉树的实现很复杂,就暂时不详细分析了。
堆
堆是一个 每个节点的数据都大于等于(或小于等于)它的子节点的完全二叉树。
对于每个节点的值都大于等于子树中每个节点值的堆,我们叫作 大顶堆。对于每个节点的值都小于等于子树中每个节点值的堆,我们叫作 小顶堆。
因为堆是完全二叉树,所以我们用数组存储。
1. 插入一个元素
插入元素到堆,具体做法是插入到数组的末尾,然后通过 堆化 操作,对树进行调整,重新变成堆。
堆化(heapify),是指一个节点,不停地向上或向下进行交换,直到找到合适的位置,使当前的二叉树变成堆。
插入时进行的堆化是 从下往上堆化。新插入的元素位于末尾,需要不停地和父元素进行比较和进行交换,直到找到合适的位置结束,此时树就会又变成堆。
// 入堆,从下往上堆化。
insert(val) {
// count 指的是当前数组存储数据的大小,n 为 数组的容量
//(当然js的数组是动态数组。这里的 n 是我手动加的限制)
if (this.count >= this.n) {
console.log('堆满了,别加了!!')
return;
}
this.count++;
let a = this.a; // a 是存储数据的数组
a[this.count] = val;
let i = this.count,
j = Math.floor(i/2); // 临时存储 i/2
while (i > 1 && a[i] > a[j]) {
[a[i], a[j]] = [a[j], a[i]];
i = j;
j = Math.floor(i/2);
}
return true;
}
2. 删除堆顶元素
删除了堆顶元素后,我们需要把最后一个元素移动到堆顶元素位置,然后进行 从上往下的堆化。
从上往下堆化具体的实现是:最后一个元素替换掉堆顶元素后,就比较堆顶元素和它的两个子节点,看看谁最大,如果不是堆顶元素最大,堆顶元素就和值最大的子节点交换。重复上面的步骤,直到当前节点最大或者当前节点成为叶子节点(到底了)。
// 删除堆顶元素
removeMax() {
if (this.count == 0) return false; // 堆为空
this.a[1] = this.a[this.count];
this.a[this.count] = undefined;
this.count--;
// 从上往下 堆化
let i = 1,
maxPos = i;
while (true) {
if (i * 2 <= this.count && this.a[i*2] > this.a[maxPos]) maxPos = i * 2;
if (i * 2 + 1 <= this.count && this.a[i*2 + 1] > this.a[maxPos]) maxPos = i * 2 + 1;
if (maxPos == i) {
break;
}
[this.a[i], this.a[maxPos]] = [this.a[maxPos], this.a[i]];
i = maxPos;
}
return true;
}
堆排序
堆排序算法分两个步骤:先建堆,然后进行排序。
1. 建堆
对数组进行 原地 建堆。原地是指在原数组上进行操作,不需要另开一个堆。
建堆的方式有两种:
- 借助前面提到的插入操作的方式。
这里就是往 “堆区域” 末尾插入元素,然后从下往上堆化。类似插入排序,我们将数组分为 “堆区域” 和 “未处理区域”,不停地将“未处理区域”里的元素插入到“堆区域” 中,直到遍历完整个数组。
- 从最后一个非叶子节点开始往前,进行 从上往下的堆化。
叶子节点因为没有子节点,所以不需要进行堆化。另外,对于完全二叉树来说,最后一个非叶子节点的下标为 i / 2(i 从1开始,你可以自己画个完全二叉树验证一下)。
建堆的复杂度是 O(n)。
2. 排序
将堆顶节点和最后一个节点进行交换,然后对剩余的 n -1 个元素进行从上往下堆化。然后我们再交换堆顶节点和第 n - 1 个元素,然后对剩余的 n - 2 个元素进行从上往下堆化,就这样不停地交换和堆化,直到堆中只有一个元素。
性能分析
1. 堆排序的时间复杂度是 O(nlogn)。
建堆的时间复杂度是 O(n),排序过程的时间复杂度是 O(nlogn),所以堆排序的时间复杂度是 O(nlogn)。
2. 堆排序是不稳定的排序
因为排序过程中,堆顶元素会和堆的最后一个元素进行交换,导致排序不稳定。
3. 堆排序是原地排序
堆排序和快速排序的比较
快速排序比堆排序好。理由如下:
- 堆排序访问数据方式不好,是跳着访问数组元素的,不利于 CPU缓存。
- 堆排序的交换操作更多。堆排序的建堆完成后,会降低数据的有序堆,这样会使得交换操作变多。
代码实现是在原数组上进行数据交换的。
堆的应用
1. 优先级队列
优先级可以用于解决 合并有序小文件、高性能定时器 等问题。
2. 求 TopK 数据
这个就是维护一个大小为 k 的小顶堆。将未入堆的元素和堆顶元素比较,如果比堆顶元素大,就入堆,直到所有元素都入堆后,这个堆就是 TopK 元素了。
时间复杂度是 O(nlogK)。最坏情况下,一次堆化需要 O(logK),要进行 n 次堆化操作。
3. 求中位数
如果是静态数据,先排序,然后求中位数即可,这样边际成本低。
如果是动态数据,那就需要维护一个 大顶堆 和一个小顶堆。要求大顶堆的数量等于小顶堆的数量或小顶堆的数量+1,且大顶堆的元素都小于小顶堆的元素。中位数即大顶堆的堆顶元素。
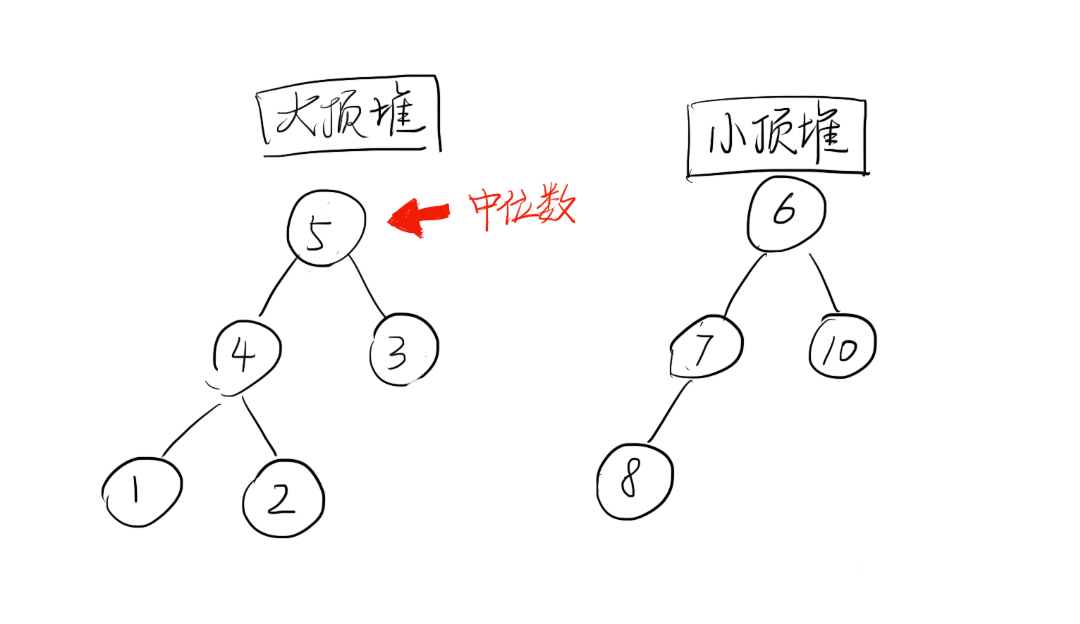
初始化的时候,可以用类似 topK 算法,弄一个数量为 k 为 n/2 的小顶堆放数组右边,然后将剩余的元素转换为大顶堆。
然后每次添加数据的时候,都会分别比较大顶堆的堆顶元素和小顶堆的堆顶元素,决定插入到哪边。插入后,还要进行一些堆的插入和删除操作,以维持这两个堆数量要差不多相同(左右元素数量相同或者左边堆比右边多一个)。
除了可以利用堆求中位数,我们还可以利用堆计算 “99% 响应时间” 的问题。即维护数量为 99/n 的大顶堆和数量为 1/n 的小顶堆。
