

之前在简书的文章,搬迁过来 ^-^
先放大神的论文和源码镇楼:
SSD Github: https://github.com/weiliu89/caffe
请选择分支 SSD
SSD paper: arxiv.org/abs/1512.02…
对于SSD来说,最有新意的就是它的多尺度特征,而整个代码中调整频度最高的应该是它的Prior_box,我们就从这些方面来分享一下我自己的理解。
##多尺度 先说一下多尺度特征。在之前的Faster-RCNN中,特征向量都是从最后一层的Feature Maps上得到的,对于这种单一的特征层而言,感受野是十分有限的,没有完全利用好前面几级的特征网络。在SSD中,作者从CONV4_3开始,利用多级Feature Maps的组合作为分类和回归的依据,达到了论文中提到的多尺度的效果。 借用论文中的一张图来说明,作者是拿YOLO和SSD做的对比:
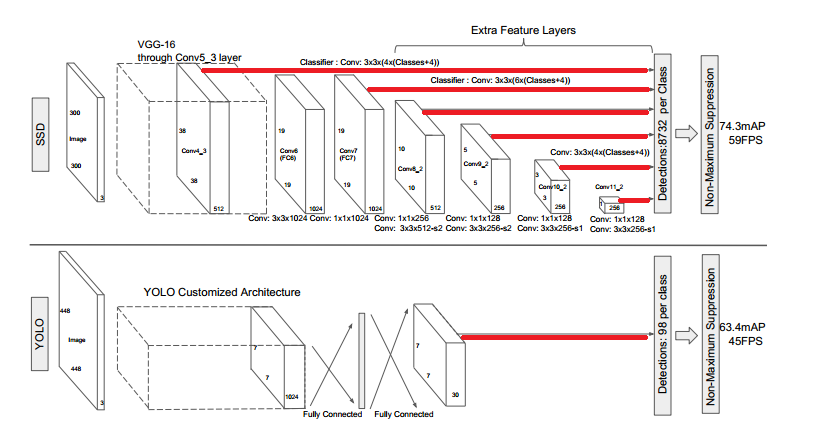
可以看出SSD 的特征是从不同的卷积层提取出来(上图红线),进行组合再进行回归和分类,而YOLO只有一层,在YOLO之后的版本中也借鉴了 SSD的这种多尺度的思想来提高mAp。也就是说,SSD就是Faster-RCNN和YOLO中做了一次的分类和检测过程放在不同的图像大小上做了多次。
##Prior_box
知道了SSD的特征是从不同尺度上提取的,那么论文中所说的8732 BOXES又是怎么来的呢?用下面这张表来告诉你。
| name | Out_size | Prior_box_num | Total_num |
|---|---|---|---|
| conv4-3 | 38x38 | 4 | 5776 |
| fc7 | 19x19 | 6 | 2166 |
| conv5-2 | 10x10 | 6 | 600 |
| conv7-2 | 5x5 | 6 | 150 |
| conv8-2 | 3x3 | 6 | 36 |
| conv9-2 | 1x1 | 4 | 4 |
| 8732 |
和 Faster-RCNN一样,SSD也是特征图上的每一个点对应一组预选框。然后每一层中每一个点对应的prior box的个数,是由PriorBox这一层的配置文件决定的。拿conv4-3对应的priorbox来说,caffe的模型配置文件如下:
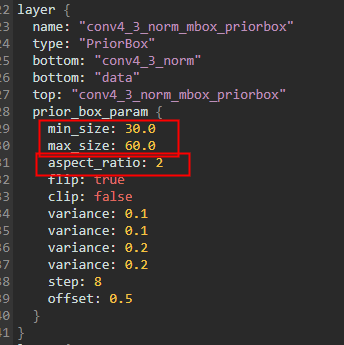
那么SSD是怎么生成对应的四个priorbox的呢? 框的生成过程大概分为下面三种方式:
-
先以 min_size为宽高生成一个框。
-
如果存在max_size则用sqrt(min_size_ * max_size_),生成一个框。
-
然后根据 aspect_ratio,再去生成。如上面的配置文件,aspect_ratio=2,那么会自动的再添加一个aspect_ratiod = 1/2,然后根据下面的计算方法:

分别生成两个框,一个对应 ar = 2 一个对应 ar= 1/2。
直观点说,就是min_size和max_size会分别生成一个正方形的框,aspect_ratio参数会生成2个长方形的框。所以输出框的个数 :
prior_box_num = count(min_size)*1+count(max_size)*1+count(aspect_ratio)*2。
PS: min_size是必须要有的参数,否则不会进入对应的框的生成过程。论文跟实际代码是有一些出入的,Git上也有人在讨论这个,基本都选择无视论文。。。
这里还有一个比较关键的参数,就是step,在conv4-3中设置为8,这个又是怎么来的呢?还是用一个表来看一下:
| name | Out_size | Cal_scale | Real_scale |
|---|---|---|---|
| conv4-3 | 38x38 | 7.8 | 8 |
| fc7 | 19x19 | 15.78 | 16 |
| conv5-2 | 10x10 | 30 | 32 |
| conv7-2 | 5x5 | 60 | 64 |
| conv8-2 | 3x3 | 100 | 100 |
| conv9-2 | 1x1 | 300 | 300 |
Cal_scale = 300/out_size 实际就是 原图与特征图 大小的比值,比如conv4-3 width = 38 ,输入的大小为300,那么scale=7.8,所以这里设置的step=8。代码中实现如下:
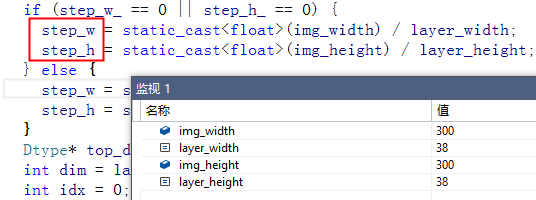
这一部分的计算过程可以在 prior_box_layer.cpp的Forward_cpu中看到。
##特征的表出形式 如果你看了SSD的网络结构会发现,每一个 convXXXX_mbox_loc 或者 convXXXX_mbox_conf后面都会跟一个permute+flatten layer,如下图:
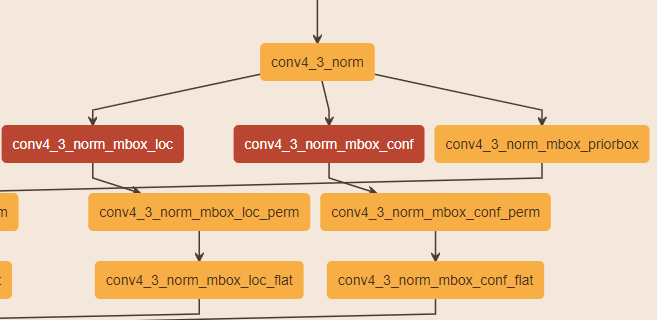
这是在干什么呢? 使用CAFFE的同学都知道 ,CAFFE的数据结构是 NCHW的形式(N:样本个数, C:通道数,H:高,W:宽),而SSD的 XX_conf 和 XX_loc层的输出,是用通道来保存特征向量的,所以这里需要将通道数调整到最后,也就是 permute所做的事情,通过该层后,数据的顺序被换成了 NHWC,再通过 flatten拉成一列。
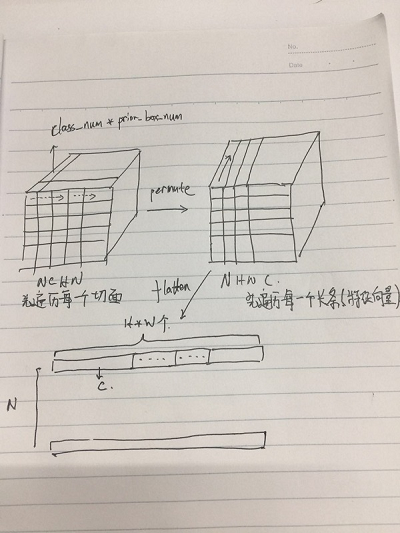
这里还有还是要说一下 XX_LOC 和 XX_CONF 层的输出通道的规则,XX_LOC层是用来回归框的,所以需要4个坐标信息,而XX_CONF是用来做分类的,所以需要class_num个信息,同时每个点会有多个prior_box ,我们令 K = count(prior_box),那么相应的XX_LOC的输出的通道个数应为4*K,而XX_CONF的输出通道个数应为 class_num*K,作为验证,我们还是看一下针对于VOC的模型的参数设置,
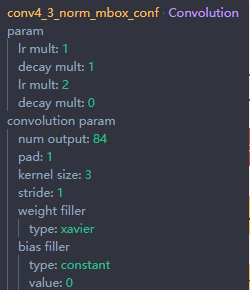
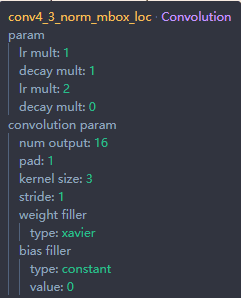
还是看conv4_3,这一层对应了4个prior_box ,VOC的分类个数是21(20个分类+1个背景),所以对应的conv4_3_norm_mbox_loc 的num output = 16 = 4*4 ,而 conf的 num_output = 84 = 21*4。所以,如果针对的是自己的训练集,一定要记着修改 XX_CONF的输出通道数。
其实简单点理解,就是SSD的最后几层的输出信息都是保存在Channel这一维度的,而一个LOC+CONF+PRIOR的模块可以认为等效于一个 Faster-rcnn的最后的回归+分类过程,通过将这些子模块的特征拼接起来,得到一组特征向量,达到提取多尺度特征的目的(多个F-RCNN同时工作于同一图片的不同尺度上)。
#####再看一下为什么一个特征点要对应几个prior_box。 原图中的某一个片区域,在经过几层的提取后,会抽象成特征图上的一个点,那么多对于多个prior_box而言,他们对应的都是同一组信息,那么多个prior_box的意义是什么呢?看下图:
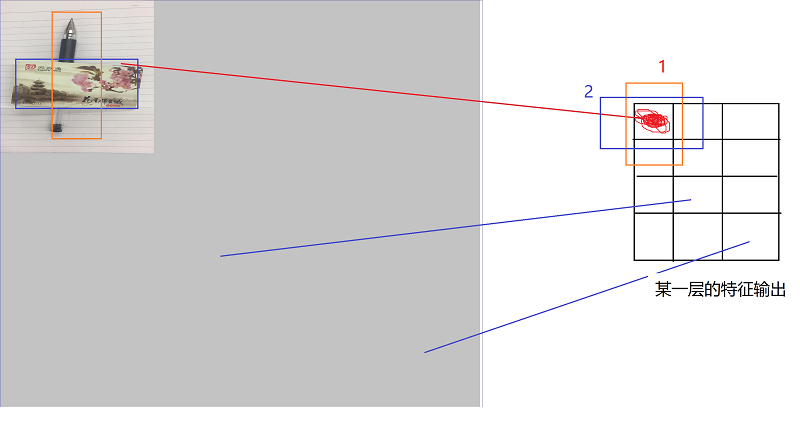
该图只是示意作用,我假设某一层的特征输出中的一个点,在原图中的感受野刚好是上图左上角的区域,可以看出卡片遮挡了笔的部分特征(橙色和蓝色的框是我标注上去的,2根蓝线是示意作用,可以忽略),如果没有多个prioro_box的时候,这种场景就无法正确分类,要么认为是卡片,要么认为是笔。这时候多个Prior_box的价值就来了,因为多个框都会输出自己的坐标回归和分类,它们会去关注自己对应的特征,然后不同的框给出不同的分类得分,个人觉得有点类似于一个Attention的结构。
##最后还是要提一下SSD的数据增强 SSD的数据增强有很多,随机的剪裁,放缩,亮度,饱和度的调整,等等。参数也基本是见名知意的,所以最好自己跟着代码看一下比较有效。如果自己需要做数据增强不妨学习一下他的用法。 这里推荐一个 GIT: https://github.com/eric612/MobileNet-SSD-windows
这个GIT的SSD版本是可以在 WINDOWS上跑的,这样就能用宇宙最强IDE——VS一步一步的跟着看图片的变化了。
