

- 面试汇总一:2018大厂高级前端面试题汇总
- 高级面试:【半月刊】前端高频面试题及答案汇总
css内容
响应式布局
当前主流的三种预编译器比较
- CSS预处理器用一种专门的编程语言,进行Web页面样式设计,然后再编译成正常的CSS文件,以供项目使用;
- 让你的CSS更加简洁、适应性更强、可读性更佳,更易于代码的维护等诸多好处。
less,sass,stylus三者的区别
-
1.变量:
- Sass声明变量必须是『$』开头,后面紧跟变量名和变量值,而且变量名和变量值需要使用冒号:分隔开。
- Less 声明变量用『@』开头,其余等同 Sass。
- Stylus 中声明变量没有任何限定,结尾的分号可有可无,但变量名和变量值之间必须要有『等号』。
-
2.作用域:
- Sass:三者最差,不存在全局变量的概念。也就是说在 Sass 中定义了相同名字的变量时你就要小心蛋疼了。
- Less:最近的一次更新的变量有效,并且会作用于全部的引用!
- Stylus:Sass 的处理方式和 Stylus 相同,变量值输出时根据之前最近的一次定义计算,每次引用最近的定义有效;
-
3.嵌套:
- 三种 css 预编译器的「选择器嵌套」在使用上来说没有任何区别,甚至连引用父级选择器的标记 & 也相同。
-
4.继承:
- Sass和Stylus的继承非常像,能把一个选择器的所有样式继承到另一个选择器上。使用『@extend』开始,后面接被继承的选择器。Stylus 的继承方式来自 Sass,两者如出一辙。
- Less 则又「独树一帜」地用伪类来描述继承关系;
-
5.导入@Import:
- Sass 中只能在使用 url() 表达式引入时进行变量插值:
$device: mobile; @import url(styles.#{$device}.css);- Less 中可以在字符串中进行插值:
@device: mobile; @import "styles.@{device}.css";- Stylus 中在这里插值不管用,但是可以利用其字符串拼接的功能实现:
device = "mobile" @import "styles." + device + ".css" -
总结
- 1.Sass和Less语法严谨、Stylus相对自由。因为Less长得更像 css,所以它可能学习起来更容易。
- 2.Sass 和 Compass、Stylus 和 Nib 都是好基友。
- 3.Sass 和 Stylus 都具有类语言的逻辑方式处理:条件、循环等,而 Less 需要通过When等关键词模拟这些功能,这方面 Less 比不上 Sass 和 Stylus。
- 4.Less 在丰富性以及特色上都不及 Sass 和 Stylus,若不是因为 Bootstrap 引入了 Less,可能它不会像现在这样被广泛应用(个人愚见)。
link与@import区别与选择
<style type="text/css">
@import url(CSS文件路径地址);
</style>
<link href="CSSurl路径" rel="stylesheet" type="text/css" /
- link功能较多,可以定义 RSS,定义 Rel 等作用,而@import只能用于加载 css;
- 当解析到link时,页面会同步加载所引的 css,而@import所引用的 css 会等到页面加载完才被加载;
- @import需要 IE5 以上才能使用;
- link可以使用 js 动态引入,@import不行;
垂直居中布局
css3的高级特性举例
h5新增了哪些内容或者API,使用过哪些?
1像素边框问题
什么是BFC
BFC是什么
- BFC 英文解释: block formatting context。中文意思:块级格式化上下文;
- formatting context 意思是:页面中一个渲染区域,有自己的一套渲染规则,决定其子元素如何定位,以及和其他兄弟元素的关系和作用。
- BEC有如下特性
- 内部的box会在垂直方向,从顶部开始一个接一个地放置;
- box垂直方向的距离由margin决定。属于同一个BFC的两个相邻的box的margin会发生折叠;
- 每一个元素的margin box的左遍,与包含块border box的左边相接触。即使浮动元素也是如此;
- BFC区域不会与float box叠加;
- 计算 BFC 的高度时,浮动子元素也参与计算;
- 文字层不会被浮动层覆盖,环绕于周围
产生BFC 作用的css 属性
- float 除了none以外的值;
- overflow 除了visible 以外的值(hidden,auto,scroll );
- display (table-cell,table-caption,inline-block, flex, inline-flex);
- position值为(absolute,fixed) 这些属性值得元素都会自动创建 BFC;
BFC作用
- BFC 最大的一个作用就是:在页面上有一个独立隔离容器,容器内的元素 和 容器 外的元素布局不会相互影响。
- 解决上外边距重叠;重叠的两个box都开启bfc;
- 解决浮动引起高度塌陷;容器盒子开启bfc;
- 解决文字环绕图片;左边图片div,右边文本容器p,将p容器开启bfc;
js基础
for...in和for...of区别
- for...in
- 1.循环出来的是index索引,是字符串型的数字;
- 2.遍历顺序有可能不是按照实际数组的内部顺序;
- 3.使用for in会遍历数组所有的可枚举属性,包括原型上的以及数组自定义的属性;
- 所以for in更适合遍历对象,不要使用for in遍历数组。
- 推荐在循环对象属性的时候,使用for...in,在遍历数组的时候的时候使用for...of;
- for...in循环出的是key,for...of循环出的是value;
- 注意,for...of是ES6新引入的特性。修复了ES5引入的for...in的不足;
- for...of不能循环普通的对象,需要通过和Object.keys()搭配使用;
Object.prototype.objCustom = function () {};
Array.prototype.arrCustom = function () {};
let iterable = [3, 5, 7];
iterable.foo = "hello";
for (let i in iterable) {
console.log(i); // logs 0, 1, 2, "foo", "arrCustom", "objCustom"
}
for (let i of iterable) {
console.log(i); // logs 3, 5, 7
}
script 引入方式:
- html 静态',则只是在dom中插入了一行字符串,就更不会管字符串里引入的js了,所以不能用这个方法插入script!!!
- 比如: 1.js 依赖 2.js,2.js 依赖 3.js;实际的加载顺序是为 1.js,2.js,3.js
- 注意: 而实际模块运行的顺序,才是 3.js,2.js,1.js。所以,文件的加载、加载后文件的运行、模块的运行,这是 3 个东西啊,别混了。
// 1.js 中的代码
require([], functionA() {
// 主要逻辑代码
})
- 文件的加载:将
<script src='1.js'>节点插入dom中,之后,下载 1.js 文件; - 加载后文件的运行:1.js 文件加载完后,执行 1.js 中的代码,即执行 require() 函数!!!
- 模块的运行: require回调函数,上方的,主要逻辑代码,所在的函数,functionA,的运行!!!
- 文件加载/文件运行 顺序: 1.js , 2.js , 3.js;
- 模块运行 顺序:3.js , 2.js , 1.js;
webpack对比requirejs
- webpack在管理模块的时候不需要再封装一层像requireJS如下的东西
define(['jquery'], function(jquery){})
- 它实现了前端代码模块化,提高了代码的复用性,从而提供公共模块的缓存功能。
- webpack通过打包,不同页面单独加载自己的模块的javascript 和 common javascript,而requireJS将所有的javascript文件打包成一个文件,使得一个站点中多个页面之间公用的JS模块无法缓存。
- Webpack 引入了切分点(split point)与代码块(Chunk),切分点定义了所有依赖的模块,合起来就是一个代码块,从而实现一个页面引用一个代码块。
主流框架Vue
vue2中的diff算法是怎样实现的?
- 参考:让虚拟DOM和DOM-diff不再成为你的绊脚石
- 当数据发生改变时,set方法会让调用Dep.notify通知所有订阅者Watcher,订阅者就会调用patch给真实的DOM打补丁,更新相应的视图。
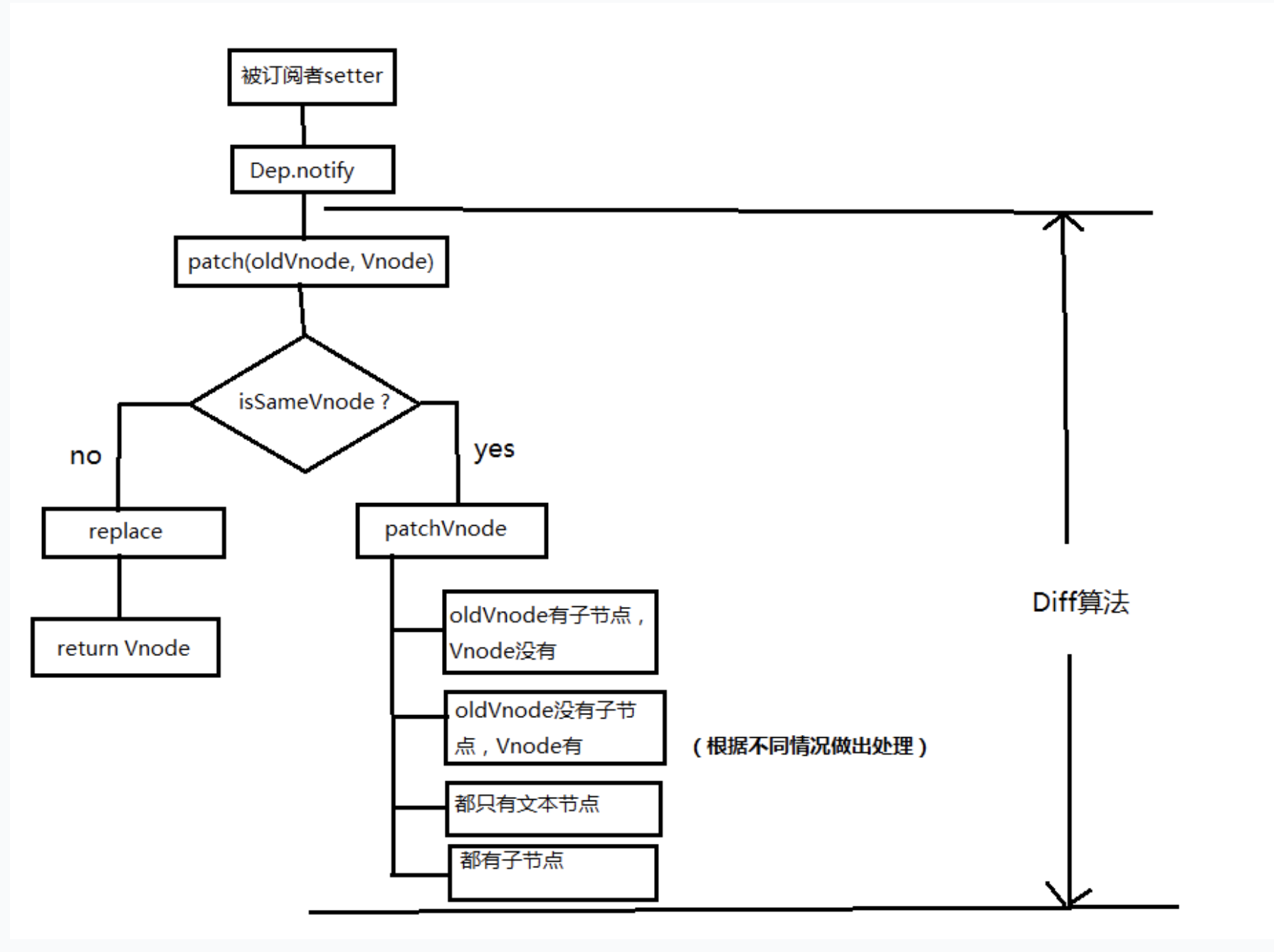
diff流程
- patch函数接收两个参数oldVnode和Vnode分别代表新的节点和之前的旧节点
- 判断两节点是否值得比较,值得比较则执行patchVnode;
- 不值得比较则用Vnode替换oldVnode;
- patchVnode:当我们确定两个节点值得比较之后我们会对两个节点指定patchVnode方法;
- 找到对应的真实dom,称为el;
- 判断Vnode和oldVnode是否指向同一个对象,如果是,那么直接return;
- 如果他们都有文本节点并且不相等,那么将el的文本节点设置为Vnode的文本节点;
- 如果oldVnode有子节点而Vnode没有,则删除el的子节点;
- 如果oldVnode没有子节点而Vnode有,则将Vnode的子节点真实化之后添加到el;
- 如果两者都有子节点,则执行updateChildren函数比较子节点,这一步很重要;
- updateChildren函数图解
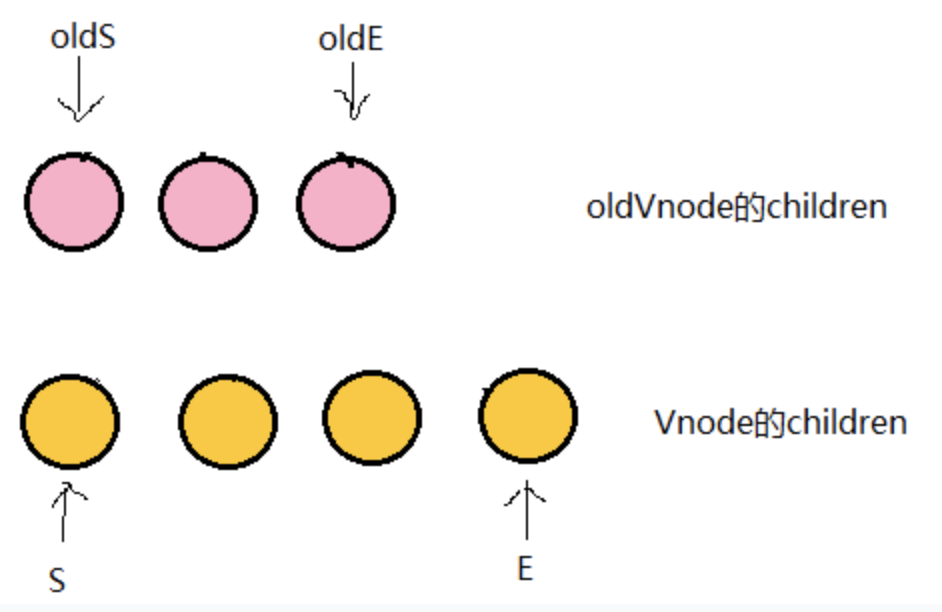
- 现在分别对oldS、oldE、S、E两两做sameVnode比较,有四种比较方式,当其中两个能匹配上那么真实dom中的相应节点会移到Vnode相应的位置,这句话有点绕,打个比方:
- 如果是oldS和E匹配上了,那么真实dom中的第一个节点会移到最后;
- 如果是oldE和S匹配上了,那么真实dom中的最后一个节点会移到最前,匹配上的两个指针向中间移动;
- 如果四种匹配没有一对是成功的,那么遍历oldChild,S挨个和他们匹配,匹配成功就在真实dom中将成功的节点移到最前面,如果依旧没有成功的,那么将S对应的节点插入到dom中对应的oldS位置,oldS和S指针向中间移动。
vue双向数据绑定
- vue.js 是采用数据劫持结合发布者-订阅者模式的方式,通过Object.defineProperty()来劫持各个属性的setter,getter,在数据变动时发布消息给订阅者,触发相应的监听回调。
- 第一步:需要observe的数据对象进行递归遍历,包括子属性对象的属性,都加上 setter和getter。这样的话,给这个对象的某个值赋值,就会触发setter,那么就能监听到了数据变化;
- 第二步:compile解析模板指令,将模板中的变量替换成数据,然后初始化渲染页面视图,并将每个指令对应的节点绑定更新函数,添加监听数据的订阅者,一旦数据有变动,收到通知,更新视图;
- 第三步:Watcher订阅者是Observer和Compile之间通信的桥梁,主要做的事情是:
- 1、在自身实例化时往属性订阅器(dep)里面添加自己
- 2、自身必须有一个update()方法
- 3、待属性变动dep.notice()通知时,能调用自身的update()方法,并触发Compile中绑定的回调,则功成身退。
- 第四步:MVVM作为数据绑定的入口,整合Observer、Compile和Watcher三者,通过Observer来监听自己的model数据变化,通过Compile来解析编译模板指令,最终利用Watcher搭起Observer和Compile之间的通信桥梁,达到数据变化 -> 视图更新;视图交互变化(input) -> 数据model变更的双向绑定效果。
细节点询问
- 基于vue数据绑定,如果data中的数据进行了一秒1000次的改变,每次改变会全部显示在页面中吗?
vue生命周期的执行过程
- 首先创建一个vue实例,Vue();
- 在创建Vue实例的时候,执行了init(),在init过程中首先调用了beforeCreate。
- Created之前,对data内的数据进行了数据监听,并且初始化了Vue内部事件。具体如下:
- 完成了数据观测;
- 完成了属性和方法的运算;
- 完成了watch/event事件的回调;
- 但是此时还未挂载dom上,$el属性是不可见的;
- beforeMount之前,完成了模板的编译。把data对象里面的数据和vue的语法写的模板编译成了html,但是此时还没有将编译出来的html渲染到页面;
- 1、在实例内部有template属性的时候,直接用内部的,然后调用render函数去渲染。
- 2、在实例内部没有找到template,就调用外部的html(“el”option(选项))。实例内部的template属性比外部的优先级高。 render函数 > template属性 > 外部html;
- 3、要是前两者都不满足,那么就抛出错误。
- Mounted之前执行了render函数,将渲染出来的内容挂载到了DOM节点上。mounted是将html挂载到页面完成后触发的钩子函数;当mounted执行完毕,整个实例算是走完了流程;在整个实例过程中,mounted仅执行一次;
- beforeUpdate:数据发生变化时,会调用beforeUpdate,然后经历virtual DOM,最后updated更新完成;
- beforeDestory是实例销毁前钩子函数,销毁了所有观察者,子组件以及事件监听;
- destoryed实例销毁执行的钩子函数;
总结
- beforeCreate:初始化了部分参数,如果有相同的参数,做了参数合并,执行 beforeCreate;el和数据对象都为undefined,还未初始化;
- created :初始化了 Inject 、Provide 、 props 、methods 、data 、computed 和 watch,执行 created ;data有了,el还没有;
- beforeMount :检查是否存在 el 属性,存在的话进行渲染 dom 操作,执行 beforeMount;$el和data都初始化了,但是dom还是虚拟节点,dom中对应的数据还没有替换;
- mounted :实例化 Watcher ,渲染 dom,执行 mounted ;vue实例挂载完成,dom中对应的数据成功渲染;
- beforeUpdate :在渲染 dom 后,执行了 mounted 钩子后,在数据更新的时候,执行 beforeUpdate ;
- updated :检查当前的 watcher 列表中,是否存在当前要更新数据的 watcher ,如果存在就执行 updated ;
- beforeDestroy :检查是否已经被卸载,如果已经被卸载,就直接 return 出去,否则执行 beforeDestroy ;
- destroyed :把所有有关自己痕迹的地方,都给删除掉;
Vue.js的template编译
- 参考:Vue2 原理浅谈
const ast = parse(template.trim(), options) // 构建抽象语法树
optimize(ast, options) // 优化
const code = generate(ast, options) // 生成代码
return {
ast,
render: code.render,
staticRenderFns: code.staticRenderFns
}
- 可以分成三部分
- 将模板转化为抽象语法树;
- 优化抽象语法树;
- 根据抽象语法树生成代码;
- 具体做了什么
- 第一部分其实就是各种正则了,对左右开闭标签的匹配以及属性的收集,通过栈的形式,不断出栈入栈去匹配以及更换父节点,最后生成一个对象,包含children,children又包含children的对象;
- 第二部分则是以第一部分为基础,根据节点类型找出一些静态的节点并标记;
- 第三部分就是生成render函数代码了
- 简言之,就是先转化成AST树,再得到的render函数返回VNode(Vue的虚拟DOM节点);
- 回答:
- 首先,通过compile编译器把template编译成AST语法树(abstract syntax tree 即 源代码的抽象语法结构的树状表现形式),compile是createCompiler的返回值,createCompiler是用以创建编译器的。另外compile还负责合并option。
- 然后,AST会经过generate(将AST语法树转化成render funtion字符串的过程)得到render函数,render的返回值是VNode,VNode是Vue的虚拟DOM节点,里面有(标签名、子节点、文本等等);
数据到视图的整体流程
- 在组件级别,vue会执行一个new Watcher;
- new Watcher首先会有一个求值的操作,它的求值就是执行一个函数,这个函数会执行render,其中可能会有编译模板成render函数的操作,然后生成vnode(virtual dom),再将virtual dom应用到视图中;
- 其中将virtual dom应用到视图中(这里涉及到diff后文会讲),一定会对其中的表达式求值(比如{{message}},我们肯定会取到它的值再去渲染的),这里会触发到相应的getter操作完成依赖的收集;
- 当数据变化的时候,就会notify到这个组件级别的Watcher,然后它还会去求值,从而重新收集依赖,并且重新渲染视图;
vue的computed和watch区别
- computed 是计算一个新的属性,并将该属性挂载到 vm(Vue 实例)上,而 watch 是监听已经存在且已挂载到 vm 上的数据,所以用 watch 同样可以监听 computed 计算属性的变化(其它还有 data、props)
- computed 本质是一个惰性求值的观察者,具有缓存性,只有当依赖变化后,第一次访问 computed 属性,才会计算新的值,而 watch 则是当数据发生变化便会调用执行函数
- 从使用场景上说,computed 适用一个数据被多个数据影响,而 watch 适用一个数据影响多个数据;
computed的原理,是如何和被计算的数据联系起来的
- 需要考虑
- 如何与其他的属性建立联系的;
- 属性改变后,如何通知计算属性重新计算的;
- 初始化data时,会使用Object.defineProperty 对所有的属性数据劫持;
- 初始化computed,会遍历所有的computed,对每一个计算属性会调用initComputed函数,生成watcher实例;
- watcher实例中会进行依赖收集;
- computed计算时:
- 会将当前的watcher实例赋给 Dep.target;
- 执行计算属性的getter方法;
- 去读取被计算的属性时,就会触发这些被计算属性的相应getter方法。当判定被计算的属性是计算属性的相关依赖时,就会去建立依赖关系,既将计算属性的watcher添加到这些被计算属性的watcher内的消息订阅器dep中。
- 完成之后将Dep.target 赋为 null 并返回求值函数结果。
vue组件间的七种交互
- 1.props和$emit
- 父组件向子组件传递数据是通过prop传递的,子组件传递数据给父组件是通过$emit触发事件来做到的。
- 2.特性绑定$attrs和$listeners
- 如果父组件A下面有子组件B,组件B下面有组件C,这时如果组件A想传递数据给组件C怎么办呢? 如果继续用上面的方法,会变得非常复杂,不利于维护;Vue 2.4开始提供了$attrs和$listeners来解决这个问题,能够让组件A之间传递消息给组件C。
- 3.中央事件总线 Events Bus
- 新建一个Vue事件bus对象,然后通过bus.$emit触发事件,bus.$on监听触发的事件。
- 4.依赖注入:provide和inject
- 父组件中通过provider来提供变量,然后在子组件中通过inject来注入变量。
- 不论子组件有多深,只要调用了inject那么就可以注入provider中的数据。而不是局限于只能从当前父组件的prop属性来获取数据,只要在父组件的生命周期内,子组件都可以调用。
// 父组件 name: "Parent", provide: { for: "demo" }, components:{ childOne } // 子组件 name: "childOne", inject: ['for'], data() { return { demo: this.for } }, components: { childtwo } - 5.v-model
- 父组件通过v-model传递值给子组件时,会自动传递一个value的prop属性,在子组件中通过this.$emit(‘input’,val)自动修改v-model绑定的值
- 子组件引用:ref和$refs
- 7.父链和子索引:$parent和$children
- 8.vue1中boradcast和dispatch
- vue1.0中提供了这种方式,但vue2.0中没有,但很多开源软件都自己封装了这种方式,比如min ui、element ui和iview等。
- 9.vuex
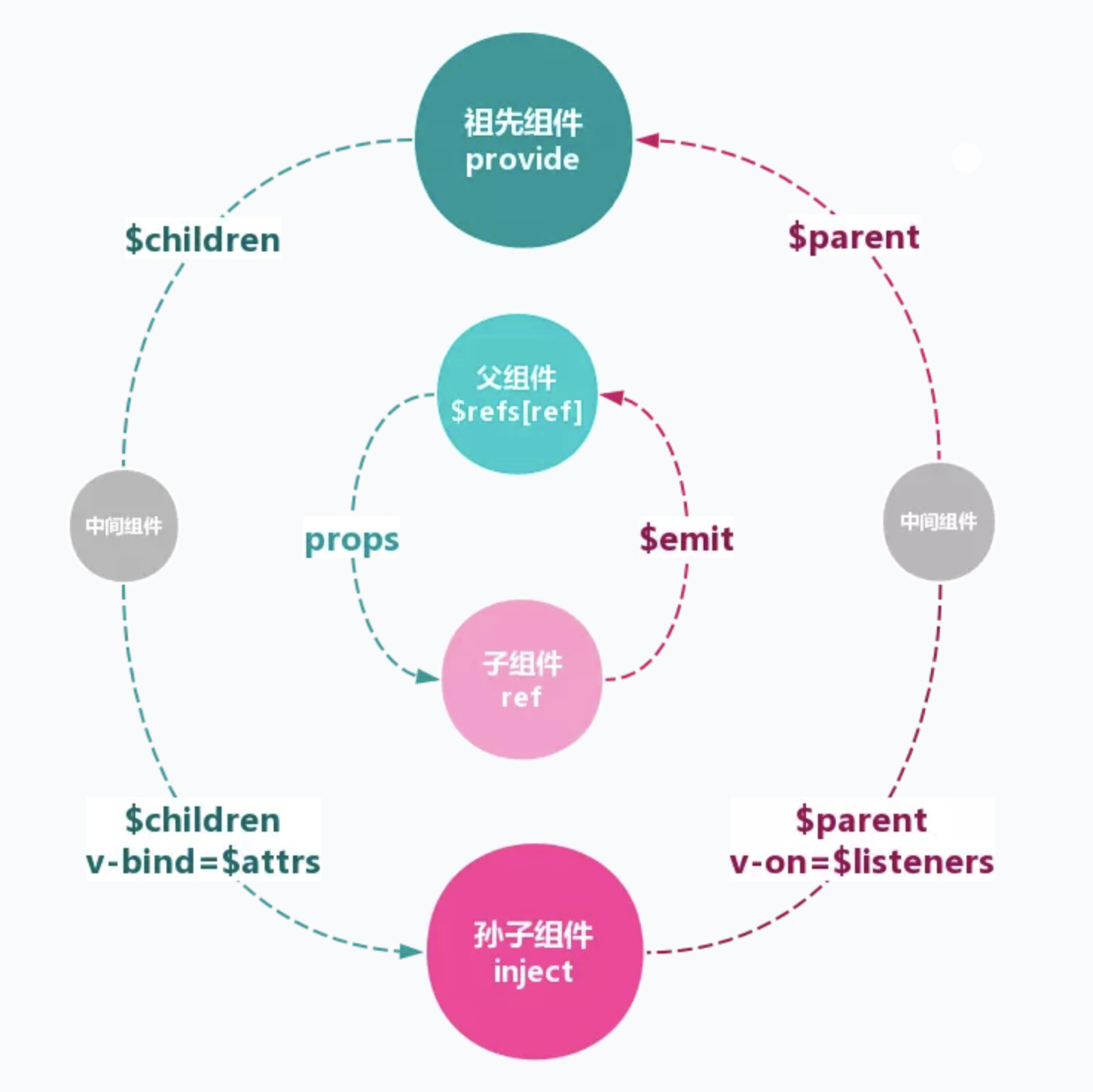
组件之间通信使用的设计模式?
- 目前还没有答案~~~~(阿里电话面试的一个问题)
vuex原理
- 参考:深入vuex原理(上)
- 参考:Vuex 源码解析
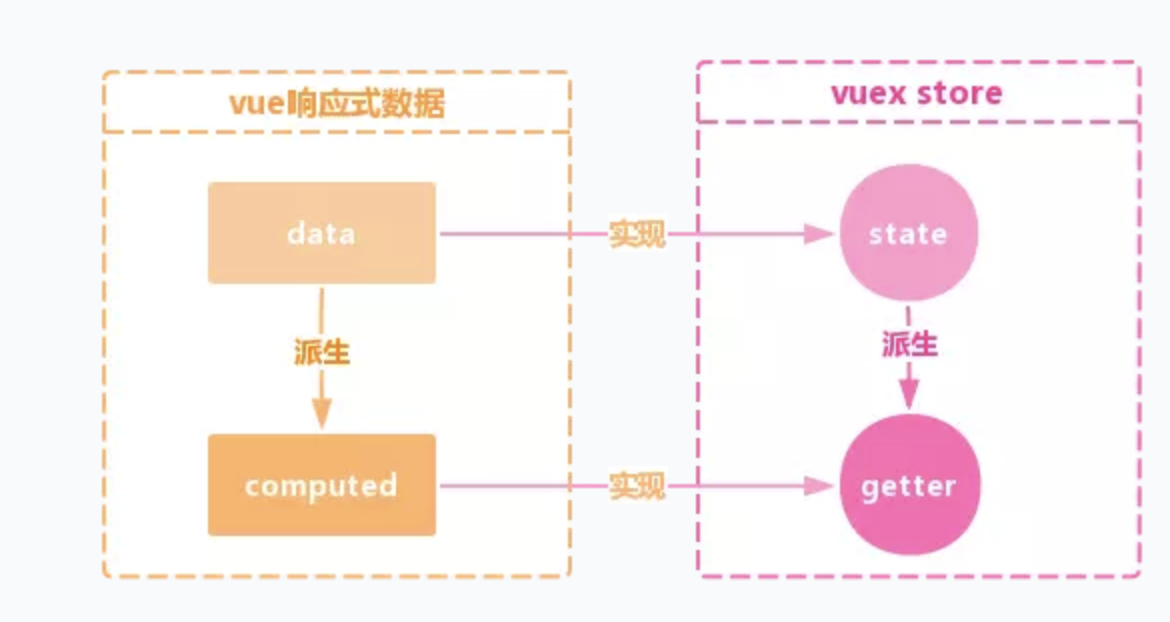
- vuex的state是借助vue的响应式data实现的。
// 使用 this.$store.getters.xxx 获取 xxx 属性时,实际上是获取的store._vm.data.$$state 对象上的同名属性
get state () {
return this._vm._data.$$state
}
// 处理state 和 getter的核心函数resetStoreVM(this, state)
store._vm = new Vue({
data: {
$$state: state
}
})
// 由于vue的data是响应式的,所以,$$state也是响应式的,那么当我们 在一个组件实例中 对state.xxx进行 更新时,基于vue的data的响应式机制,所有相关组件的state.xxx的值都会自动更新,UI自然也会自动更新
- getter是借助vue的计算属性computed特性实现的。
// wrappedGetters方法
const computed = {};
// 处理getters
forEachValue(wrappedGetters, (fn, key) => {
computed[key] = () => fn(store) // 将getter存储在computed上
//this.$store.getters.XXX的时候获取的是store._vm.XXX
Object.defineProperty(store.getters, key, {
get: () => store._vm[key],
enumerable: true
})
})
- 其设计思想与vue中央事件总线如出一辙。中央事件总线的实现,简单讲就是新建了一个vue对象,借助vue对象的特性(emit 与on) 作为其他组件的通信桥梁,实现组件间的通信 以及数据共享!
Vue-router 中hash模式和history模式的区别
- hash模式url里面永远带着#号,我们在开发当中默认使用这个模式。那么什么时候要用history模式呢?如果用户考虑url的规范那么就需要使用history模式,因为history模式没有#号,是个正常的url适合推广宣传。
- 当然其功能也有区别,比如我们在开发app的时候有分享页面,那么这个分享出去的页面就是用vue或是react做的,咱们把这个页面分享到第三方的app里,有的app里面url是不允许带有#号的,所以要将#号去除那么就要使用history模式,但是使用history模式还有一个问题就是,在访问二级页面的时候,做刷新操作,会出现404错误,那么就需要和后端人配合让他配置一下apache或是nginx的url重定向,重定向到你的首页路由上就ok啦。
- 路由的哈希模式其实是利用了window可以监听onhashchange事件,也就是说你的url中的哈希值(#后面的值)如果有变化,前端是可以做到监听并做一些响应(搞点事情),这么一来,即使前端并没有发起http请求他也能够找到对应页面的代码块进行按需加载。
- pushState与replaceState,这两个神器的作用就是可以将url替换并且不刷新页面,好比挂羊头卖狗肉,http并没有去请求服务器该路径下的资源,一旦刷新就会暴露这个实际不存在的“羊头”,显示404。这就需要服务器端做点手脚,将不存在的路径请求重定向到入口文件(index.html)。
自定义组件
- 参考:Vue——关于自定义组件
- secondDemoComponent.js
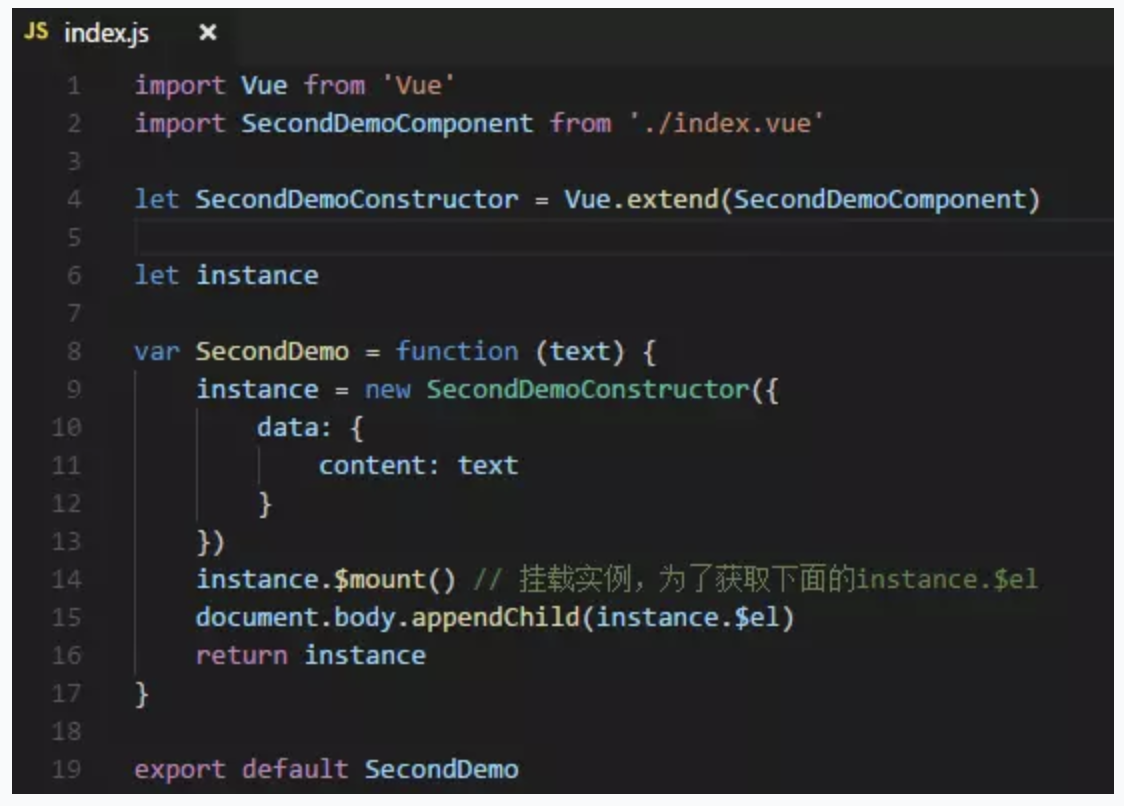
- index.js:index.js文件帮我们把所有自定义的组件都通过Vue.component注册了,最后export一个包含install方法的对象给Vue.use()使用。
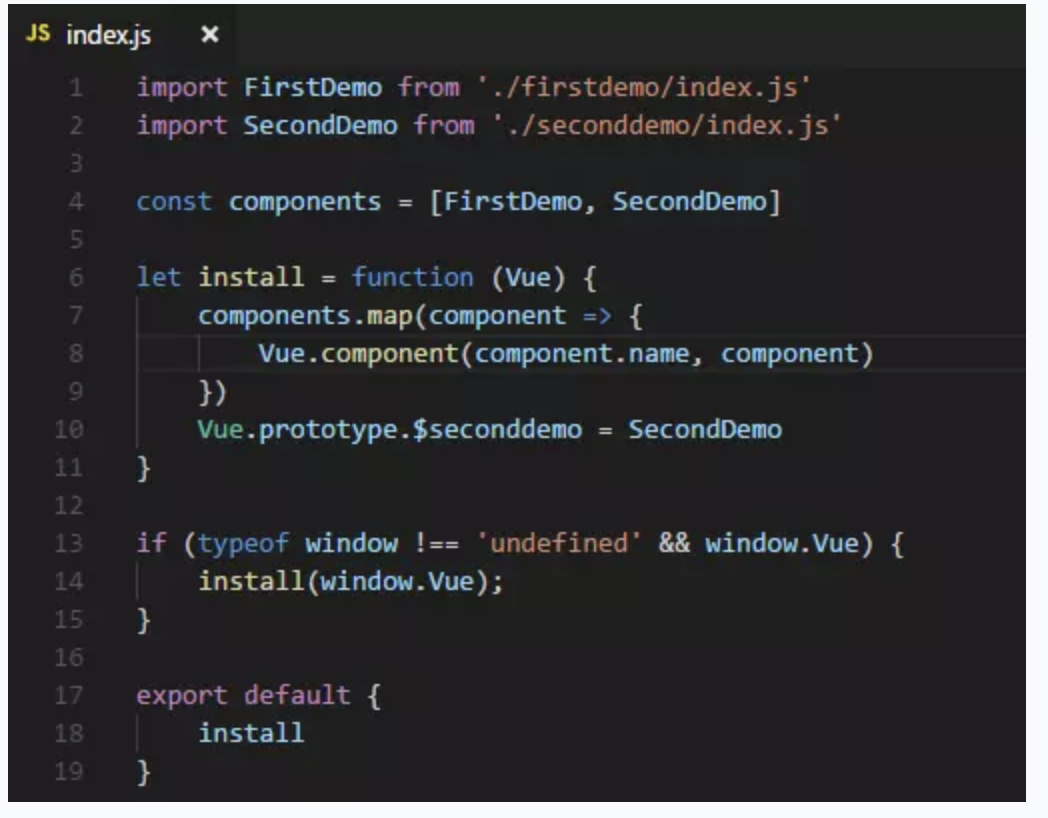
- 统一导入
import global from './components/global/index.js'
Vue.use(global)
计算机网络
http 状态码的分类?什么是无状态?
- http无状态
- 服务器中没有保存客户端的状态,客户端必须每次带上自己的状态去请求服务器;
- 每次的请求都是独立的,<它的执行情况和结果>与<前面的请求>和<之后的请求>是无直接关系的
- 状态码分类
- 1XX指示信息,表示信息已接收,继续处理;
- 2XX成功-表示请求已被成功接收;
- 3XX重定向,表示要完成请求进行更进一步操作;
- 4XX客户端错误,请求依法错误或请求无法实现;
- 5XX服务器端错误,服务器未能实现合法请求;
- 举例:
- 200,请求成功;
- 302:重定向;
- 304:上次请求后页面未修改;
- 400:客户端请求语法错误;
- 401:权限问题;
- 403,服务器接受请求,但拒绝提供服务;
- 404,请求资源未存在;
- 500,服务器内部错误;
http 1.1 与 http 2 的区别
- HTTP/2采用二进制格式而非文本格式
- 比起像HTTP/1.x这样的文本协议,二进制协议解析起来更高效、“线上”更紧凑,更重要的是错误更少。
- HTTP/2是完全多路复用的,而非有序并阻塞的——只需一个连接即可实现并行
- HTTP/1.x 有个问题叫线端阻塞(head-of-line blocking), 它是指一个连接(connection)一次只提交一个请求的效率比较高, 多了就会变慢。 HTTP/1.1 试过用流水线(pipelining)来解决这个问题, 但是效果并不理想(数据量较大或者速度较慢的响应, 会阻碍排在他后面的请求). 此外, 由于网络媒介(intermediary )和服务器不能很好的支持流水线, 导致部署起来困难重重。而多路传输(Multiplexing)能很好的解决这些问题, 因为它能同时处理多个消息的请求和响应; 甚至可以在传输过程中将一个消息跟另外一个掺杂在一起。所以客户端只需要一个连接就能加载一个页面。
- 使用报头压缩,HTTP/2降低了开销
- HTTP2通过gzip和compress压缩头部然后再发送,同时客户端和服务器端同时维护一张头信息表,所有字段都记录在这张表中,这样后面每次传输只需要传输表里面的索引Id就行,通过索引ID就可以知道表头的值了
- HTTP/2让服务器可以将响应主动“推送”到客户端缓存中
- HTTP2支持在客户端未经请求许可的情况下,主动向客户端推送内容
post和get请求的区别
基本区别
- 应用:表单的method属性设置post时发送的是post请求,其余都是get请求(没有考虑AJAX);
- 传参方式:get请求通过url地址发送请求参数,post请求通过请求体发送请求参数;
- 安全性:get请求直接通过url地址发送请求参数,参数在地址栏可见,不太安全;post请求通过请求体发送请求参数,参数在地址栏不可见,相对安全;
- 大小限制:get请求直接通过url地址发送请求参数,url地址的长度限制在255字节内,所以get请求不能发送过多的参数,post请求通过请求体发送参数,长度没有限制。
- Get方法提交的数据大小长度并没有限制,而是IE浏览器本身对地址栏URL长度(5.7备注:是浏览器对请求头有限制,不能超过多少~~~)有最大长度限制:2048个字符。
高级区别
- GET 的本质是「得」,而 POST 的本质是「给」。GET 的内容可以被浏览器缓存,而 POST 的数据不可以。
- 1.get产生一个TCP数据包,一个是请求头,一个请求体的;post产生两个TCP数据包;
- 2.在一次请求中,get一次性完成,post在部分浏览器(除了火狐)需要发送两次信息,所以get比post更快,更有效率。
什么是跨域,解决跨域的方法及原理是什么?
- 1.不同源就是跨域
- 2.同源策略是浏览器的一种安全策略
- 3.协议,域名,端口号完全相同就是同源,只要有一处不一样就是跨域
- 4.特例: ajax在判断域名的时候只能解析字符串,导致(localhost和127.0.0.1)在它看来也是跨域请求
- 5.解决跨域的方式通常用cors和jsonp
- 6.JSONP
- 1.JSONP是一种技巧,不是一门新的技术
- 2.利用scirpt标签的src属性不受跨域的限制的特点
- 3.解决跨域:
- 1.浏览器端:动态生成script标签,提前定义好回调函数,在合适的时机添加src属性指定请求的地址。
- 2.服务器端:后台接收到回调函数,将数据包括在回调函数调用的句柄中,一起返回。
- 3.只支持get请求
function jsonp({url,params,callback}){
return new Promise((resolve,reject)=>{
// 创建srcipt
let script = document.createElement("script")
window[callback] = function(data){
resolve(data)
document.body.removeChild(script)
}
// 参数重新格式化
params = {...params,callback} // wd=b&callback=show
let arrs = []
for(let key in params){
arrs.push(`${key}=${params[key]}`)
}
// 后台获取数据的接口拼接上参数
script.src = `${url}?${arrs.join('&')}`
// srcipt插入
document.body.appendChild(script)
})
}
jsonp({
url: 'http://localhost:3000/say',
params: { wd: 'Iloveyou' },
callback: 'show'
}).then(data=>{
console.log(databufen)
})
- 7.CORS
- 1.浏览器端什么也不用干;
- 2.服务器端设置响应头:Access-Control-Allow-Origin
- 3.cors是一门技术,在本质上让ajax引擎允许跨域
- 4.get和post请求都支持
为什么cros能解决跨域?// TODO
- 和第一次发送的option请求有关;
- 跨域时,浏览器会拦截Ajax请求,并在http头中加Origin。
浏览器问题
浏览器缓存
客户端两种存储
sessionStorage用法和localStorage区别
- 生命周期:
- localStorage(本地存储)生命周期是永久,这意味着除非用户显示在浏览器提供的UI上清除localStorage信息,否则这些信息将永远存在。
- sessionStorage(会话存储)生命周期为当前窗口或标签页,一旦窗口或标签页被关闭了,那么所有通过sessionStorage存储的数据也就被清空了。
- 作用域不同:不同浏览器无法共享localStorage或sessionStorage中的信息。
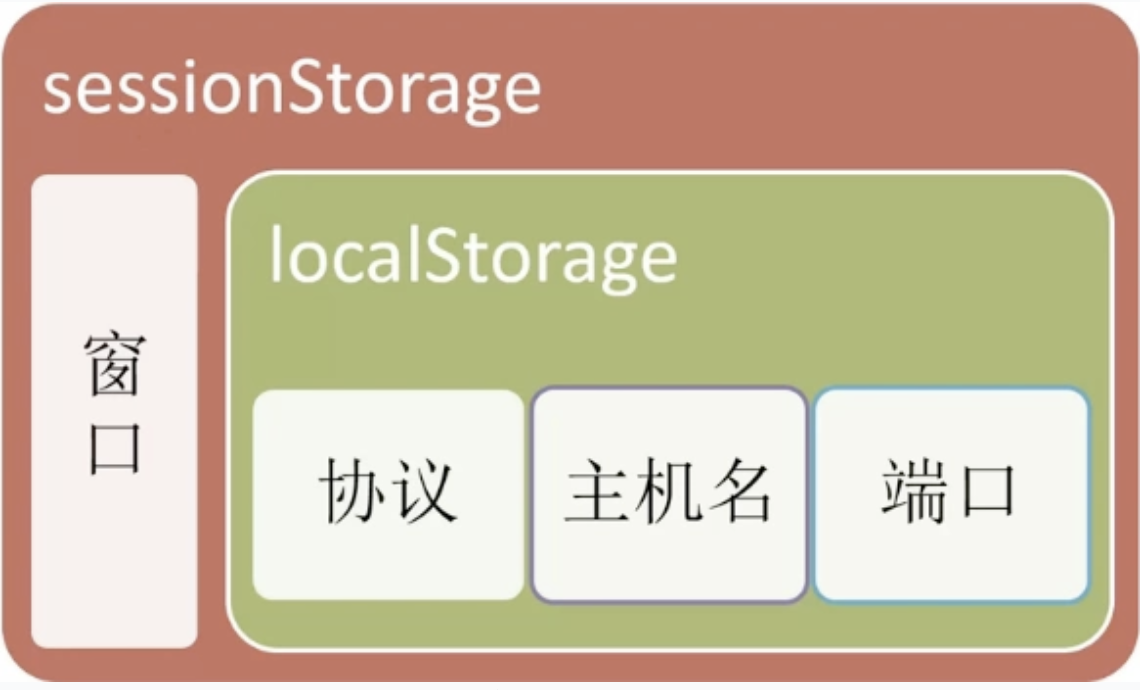
- 相同浏览器的不同页面间可以共享相同的 localStorage(页面属于相同域名和协议,主机和端口);
- 不同页面或标签页间无法共享sessionStorage的信息。
- localStorage只要在相同的协议、相同的主机名、相同的端口下,就能读取/修改到同一份localStorage数据。
- sessionStorage比localStorage更严苛一点,除了协议、主机名、端口外,还要求在同一窗口(也就是浏览器的标签页)下。
- 存储大小:localStorage和sessionStorage的存储数据大小一般都是:5MB;
- 存储位置:localStorage和sessionStorage都保存在客户端,不与服务器进行交互通信。
- 存储内容类型:localStorage和sessionStorage只能存储字符串类型,对于复杂的对象可以使用ECMAScript提供的JSON对象的stringify和parse来处理;
- 获取方式:localStorage:window.localStorage;sessionStorage:window.sessionStorage;
- 应用场景:localStoragese:常用于长期登录(+判断用户是否已登录),适合长期保存在本地的数据;sessionStorage:敏感账号一次性登录。
localStorage和cookie选择使用的标准是什么
- 应该是和服务端有关,
- cookie每次的发送请求是被默认带上的,但是东西存在localstorage是没有带上的,需要写进去;
session的生命周期为什么只在一次会话中?
- 至今没有详细的答案~~当时的回答如下:
- session是服务端的;它用来和客户端的cookie进行匹配,说它一次会话保存的意思是sessionID每次会话都是一个新的,但是session一直是有的。
Cookie存储和Web Storage存储区别
- localStorage与sessionStorage作为新时代的产物,相比旧时代的cookie有其巨大的优越性。优越性有三:
- 其一在能存储的数据量,cookie最大能存储4kb的数据,而localStorage与sessionStorage最大能存储5Mb,目前各大浏览器支持的标准都是如此;
- 其二在功能上,cookie只能存储String类型的数据,以往要将用户数据存储在本地,需要将数据拼接成字符串,再存进cookie,取数据的时候同样麻烦,先将整个cookie对象拿到(String对象),再按拼接的规则拆分,再拿需要的数据,存取都很麻烦! localStorage与sessionStorage不仅支持传统的String类型,还可以将json对象存储进去,存取数据都方便不少,json的优越性就不赘述,localStorage与sessionStorage无疑更现代化;
- 其三是cookie是不可或缺的,cookie的作用是与服务器进行交互,作为http规范的一部分而存在;而web storage仅仅是为了在本地‘存储’而生;
- 其四在语义层面上,localStorage与sessionStorage语法更优雅、简便。
//cookie的操作 设置cookie: document.cookie = 'key=value'; 获取cookie: document.cookie; 删除cookie: document.cookie = "key=value;max-age=0"; 设置max-age存储期限: document.cookie = "key=value;max-age=1000"; // 1000秒 //web storage操作 保存数据 setItem(key,value) 读取数据 getItem(key) 删除单个数据 removeItem(key) 清空全部数据 clearItem() 获取数据索引 key(index)
浏览器内核?以及常见的浏览器兼容问题
- 浏览器内核
- Trident(IE内核):以IE为代表,IE6、IE7、IE8(Trident 4.0)、IE9(Trident 5.0)、IE10(Trident 6.0)。
- Gecko(Firefox内核): Gecko 内核的浏览器还是Firefox (火狐) 用户最多,所以有时也会被称为Firefox内核。
- webkit(Safari内核,Chrome内核原型,开源):它是苹果公司自己的内核,也是苹果的Safari浏览器使用的内核。 Apple Safari也会用。
- presto(Opera前内核) (已废弃): Opera12.17及更早版本曾经采用的内核,现已停止开发并废弃。Opera现已改用Google Chrome的Blink内核。
常见的浏览器兼容问题
HTML中的兼容问题
- 不同浏览器的标签默认的外补丁和内补丁不同;
- 场景:随便写几个标签,不加样式控制的情况下,各自的margin 和padding差异较大。
- 解决方法:上来先消除默认样式*{margin:0;padding:0;};
- 块属性标签float后,又有横行的margin情况下,在IE6显示margin比设置的大(即双倍边距bug);
- 场景:常见症状是IE6中后面的一块被顶到下一行;
- 解决方法:在float的标签样式控制中加入 display:inline;将其转化为行内属性
- IE6中 z-index失效
- 场景:元素的父级元素设置的z-index为1,那么其子级元素再设置z-index时会失效,其层级会继承父级元素的设置,造成某些层级调整上的BUG;
- 原因:z-index起作用有个小小前提,就是元素的position属性要 是relative,absolute或是fixed。
- 解决方案:1.position:relative改为position:absolute;2.去除浮动;3.浮动元素添加position属性(如relative,absolute等)。
- 在写a标签的样式,写的样式没有效果,其实只是写的样式被覆盖了
- 正确的a标签顺序应该:link/ visited/hover/active
- 24位的png图片,ie6中不兼容透明底儿
- 解决方式:使用png透明图片呗,但是需要注意的是24位的PNG图片在IE6是不支持的,解决方案有两种:
- 使用8位的PNG图片;
- 为IE6准备一套特殊的图片
- 解决方式:使用png透明图片呗,但是需要注意的是24位的PNG图片在IE6是不支持的,解决方案有两种:
js在不同浏览器中的兼容问题
- 事件监听的兼容;
- IE不支持addEventListener;
- 解决:给IE使用attachEvent
var addHandler = function(el, type, handler, args) {
if (el.addEventListener) {
el.addEventListener(type, handler, false);
} else if (el.attachEvent) {
el.attachEvent('on' + type, handler);
} else {
el['on' + type] = handler;
}
};
var removeHandler = function(el, type, handler, args) {
if (el.removeEventListener) {
el.removeEventListener(type, handler, false);
} else if (el.detachEvent) {
el.detachEvent('on' + type, handler);
} else {
el['on' + type] = null;
}
};
- event.target的兼容,引发事件的DOM元素。
- IE6789不支持event.target;
- 解决方法:event.srcElement;
// 以下为兼容写法
target = event.target || event.srcElement;
- 阻止系统默认的兼容
- IE6789不支持event.preventDefault;
// 以下为兼容写法
event.preventDefault ? event.preventDefault() : (event.returnValue = false);
- 阻止事件冒泡的兼容
- IE6789不支持event.stopPropagation;
// 以下为兼容写法
event.stopPropagation ? event.stopPropagation() : (event.cancelBubble = false);
业务问题
360搜索图片这种的瀑布流布局
图片懒加载
- 高逼格方法:getBoundingClientRect()直接获取元素到顶部的距离。
- 原因:在页面中我们往往需要放上很多张图,性能是个大问题,一次性加载所有图片一般都会卡很久,因此,在需要预览的时候再加载,是一个很好的解决方案。
- 思路:当图片出现在浏览器可视区域中时,再把图片的url传给它,也可以在这个时候创建图片,而图片被包裹在一个容器中,比如li或div,图片的url放在其容器的自定义属性data-src中;
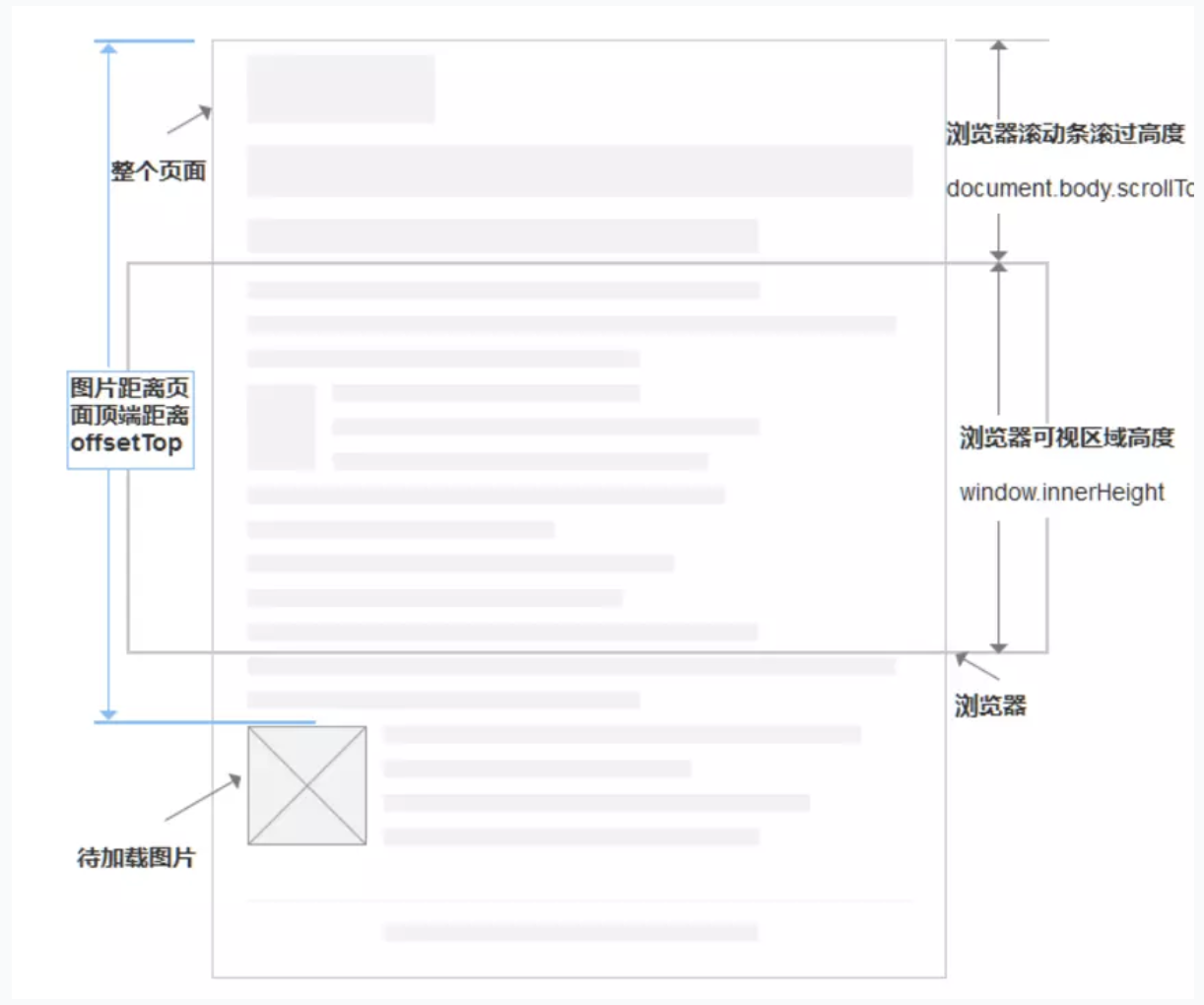
- 过程:
- 给img标签的元素添加一个自定义属性,比如data-src,而真正的src设置为空;
- 判断图片距离页面顶端的距离小于浏览器滚动距离加上可视区域高度,即它出现在可视区域时就加载他;
// h = window.innerHeight——可视区域高度 // s = document.documentElement.scrollTop || document.body.scrollTop——滚动距离; // getTop(imgs[i])通过getBoundingClientRect()获取当前图片距离顶端的高度 if (h + s > getTop(imgs[i]) && !imgs[i].getAttribute('src'))- 加载图片
imgs[i].src = imgs[i].getAttribute('data-src'); - 最后在把页面滚动函数赋值给元素window.onload,在所有元素加载完以后再进行操作,这一步很重要!
window.onload = window.onscroll = function () { // 懒加载的函数 lazyLoad(imgs); }
项目中遇见的问题
ajax中使用get的问题
- 问题一. 缓存:当每次访问的url相同,客户端直接读取本地缓存里面的内容,即使后台数据变化前台也不会有变化;
- 解决方法:在?后面链接一个num=【随机数Math.random()】或者num=【时间戳new Date().getTime()】,'1.php?username="May"&'+num(这里没有变量名,避免和后台参数冲突)
性能优化

- 雪碧图
- 减少dom操作:事件代理,fragment;
- 压缩js和css,html;
主流框架问题
vue、react和angular区别
- 借鉴angular的模板和数据绑定技术;
- 借鉴react的组件化和虚拟DOM技术;
- 体积下, 运行效率高, 编码简洁, PC/移动端开发都合适;
- 它本身只关注UI, 可以轻松引入vue插件和其它第三库开发项目;
编码题(字节跳动的视频面试)
- 第一题:定义一个Queue类,第一次调用可以隔1000秒输出1,,第二次调用可以隔2000秒输出2...最后可以调用run();
new Queue()
.task(() => {
console.log(1)
}, 1000) .task(() => {
console.log(2)
}, 2000) .task(() => {
console.log(3)
}, 3000) .run()
- 第二题:定义一个函数,求和函数,可以无数次调用,并且在最后调用valueOf显示最终求和结果;
sum(1)(2)(3)(4).valueOf()
- 第三题:第一步Promise+axios实现并发请求;写完之后,要求再在此基础上实现每次都并发5个请求(不会~~~);
// Promise+axios实现并发请求
// 实现并发5次请求
// 第一个答案
function getRequest(){
return axios.get(url)
};
function postrequest(){
return axios.post(url)
};
axios.all([getRequest(),postrequest()])
.then()
- 最近面试的一个整理情况,有些是面试中被问到的,有些是看文章时遇到感觉很有可能会问到的。有的有答案,有的还没有答案,没答案的原因有两种的:一种是常见的问题,希望能闲下来之后详细整理一下更高逼格的答案;另一种是目前还没有解决,但是会在面试告一段落之后再研究研究给出答案,也特别欢迎大家在留言上给出这些题的答案或者思路。
- 有同学在评论中说了感觉题比较简单,我想说,看到好多题的时候我也是这么感觉得,但是,可能后面就会往深层次问你了。
- 比如:new或者instanceof的实现原理?第二问就是:请手写一个new或者instanceof;再比如,cookie和session区别,第二问就是:从服务端的角度来说一下cookie和session区别把?然后:为什么session只在一次回话有效,他是服务器的一个字段吗?还是服务器的什么?再来,了解vue组件通信吗?第二问就是:请说出这些组件通信的设计模式用了哪些?最后,用过npm和yarn吗?第二问:你们是如何解决npm包的版本依赖的?package-lock的原理是什么?
- 我想说的是,文字能呈现的东西很简单,但是想深究的话,深无底线~~~ 这些很大的目的是作个记录,可以在面试上楼前再瞜一眼~~~ 工程师们在工作中一定要时刻保持可以离开的资本啊,知其然并且知其所以然!另外,面试前一定一定要准备,至少一周啦~~~~
