

作者:杨克特/伍翀 整理:徐前进(Apache Flink Contributor) 校对:杨克特/伍翀
本文整理自12月20日在北京举行的Flink-forward-china-2018大会, 分享嘉宾杨克特:花名鲁尼,Apache Flink Committer,2011年硕士毕业加入阿里,参与多个计算平台核心项目的设计和研发,包括搜索引擎、调度系统、监控分析等。目前负责Blink SQL的研发和优化。 分享嘉宾伍翀:花名云邪,Apache Flink Committer,从Flink v1.0就参与贡献,从事Flink Table & SQL相关工作已有三年,目前在阿里Blink SQL项目组。
文章概述:基于Flink以流为本的计算引擎去构建一个流与批统一的解决方案 本文主要从以下5个方面来介绍基于Flink Streaming构建统一的数据处理引擎的挑战和实践。
-
为什么要统一批和流
-
什么是统一的SQL处理引擎
-
如何统一批和流
-
性能表现
-
未来计划
一、为什么要统一批和流
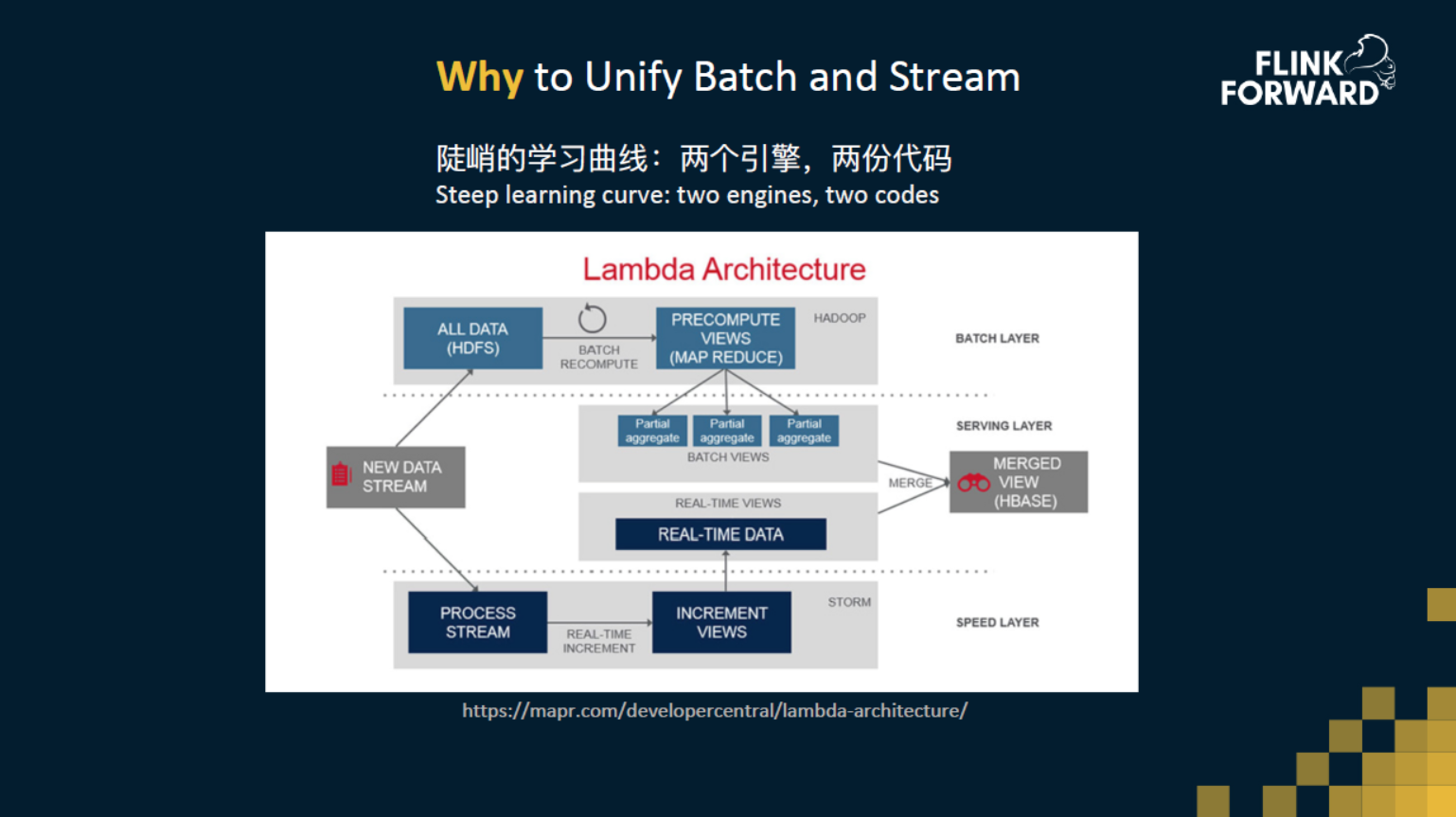
一般公司里面都会有一个比较传统的批处理系统每天去算一些报表,随着越来越多更实时的需求,大家也许会采用 Storm、Flink、Spark 来做流计算,同时又会在边上跑一个批处理,以小时或天的粒度去计算一个结果,来实现两边的校验。这个就是经典的 Lambda 架构。
但是这个架构有很多问题,比如用户需要学习两套引擎的开发方式,运维需要同时维护两套系统。更重要的问题是,我们需要维护两套流程,一套增量流程,一套全量流程,同时这两套流程之间必须要有一定的自洽性,它们必须要保证一致。当业务变得越来越复杂的时候,这种一致性本身也会成为一个挑战。
这也是 Flink SQL 希望解决的问题,希望通过 Flink SQL,不管是开发人员还是运维人员,只需要学习一套引擎,就能解决各种大数据的问题。也不仅限于批处理或者说流计算,甚至可以更多。例如:支持高时效的批处理达到 OLAP 的效果,直接用SQL语法去做复杂事件处理(CEP),使用 Table API 或 SQL 来支持机器学习,等等。在 SQL 上还有非常多的想象空间。
二、什么是统一的SQL处理引擎

那么什么是统一的 SQL 处理引擎呢?统一的 SQL 引擎道路上有哪些挑战呢?
从用户的角度来说,一句话来描述就是“一份代码,一个结果”。也就是只需要写一份代码,流和批跑出来的最终结果是一样。这个的好处是,用户再也不用去保证增量流程和全量流程之间的一致性了,这个一致性将由 Flink 来保证。
从开发的角度来看,其实更加关注底层架构的统一,比如说一些技术模块是不是足够通用,流和批模式下是否能做到尽可能地复用。精心设计的高效数据结构是不是可以广泛地应用在引擎的很多模块中。
用户角度
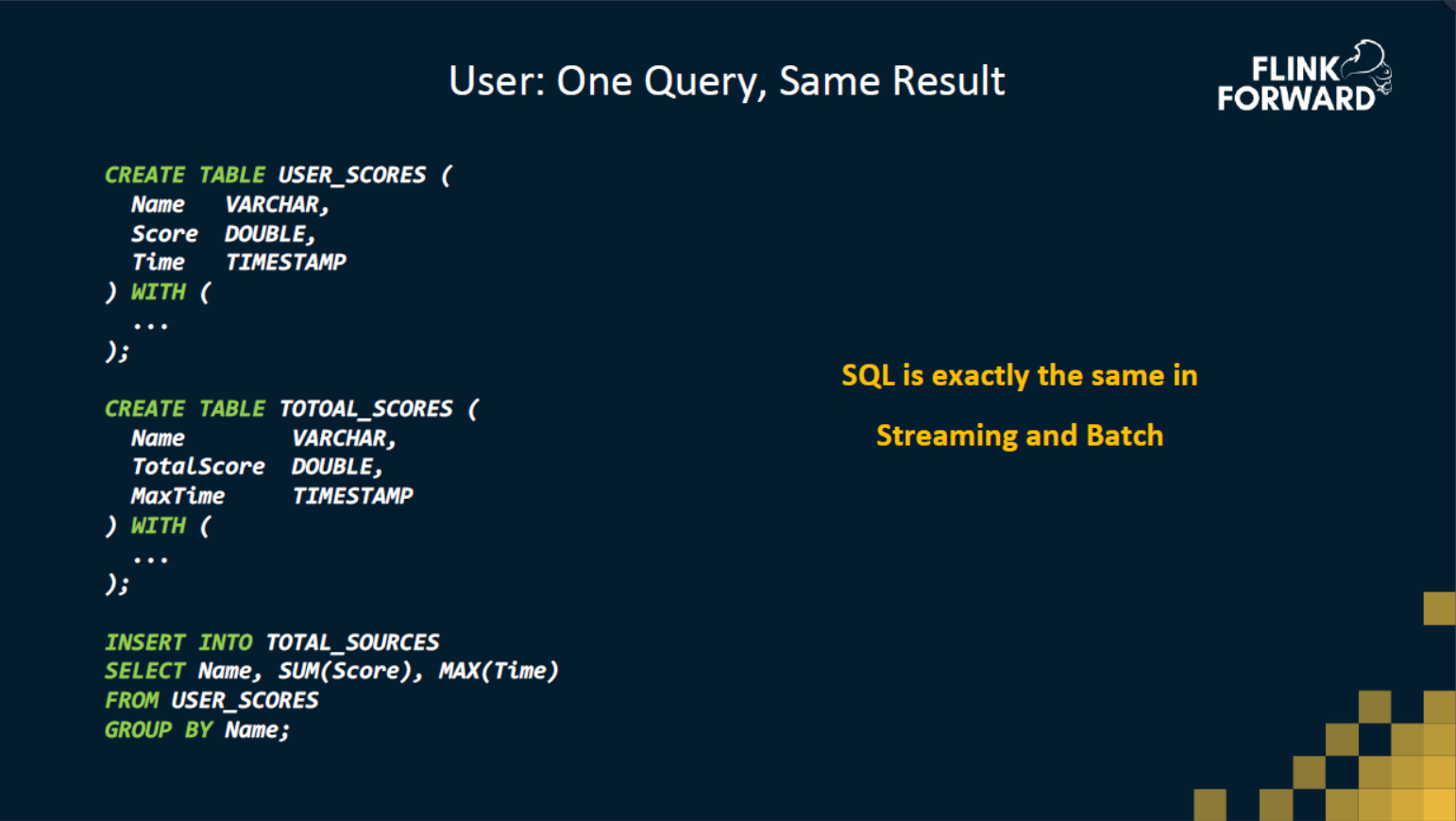
首先我们有一张用户的分数表 USER_SCORES,里面有用户的名字、得分和得分时间。通过这张表来做一个非常简单的统计,统计每个用户的总分,以及得到这个分数的最近时间是多少? 从流计算跟批处理的角度,不管是做一张离线报表,还是实时不断地产出计算结果,它们的SQL是完全一模一样的,就是一个简单的GroupBy分组,求和,求max。

如上图有一张源数据表,有名字,分数,事件时间。
对于批处理,通过这样一个SQL可以直接拿到最终的结果,结果只会显示一次,因为在数据消费完之后,才会输出结果。
对于流处理,SQL 也是一模一样的。假设流任务是从 12:01 开始运行的,这时候还没有收到任何消息,所以它什么结果都没输出。随着时间推移,收到了第一条 Julie 的得分消息,此时会输出 Julie 7 12:01。当到达12:04分时,输出的结果会更新成 Julie 8 12:03,因为又收到了一条 Julie 的得分消息。这个结果对于最终的结果来讲可能是不对的,但是至少在 12:04 这一刻,它是一个正确的结果。当时间推进到当前时间(假设是 12:08 分),所有已产生的消息都已消费完了,可以看到这时候的输出结果和批处理的结果是一模一样的。
这就是“一份代码,一个结果”。其实从用户的角度来讲,流计算跟批处理在结果正确性上并没有区别,只是在结果的时效性上有一些区别。
开发角度
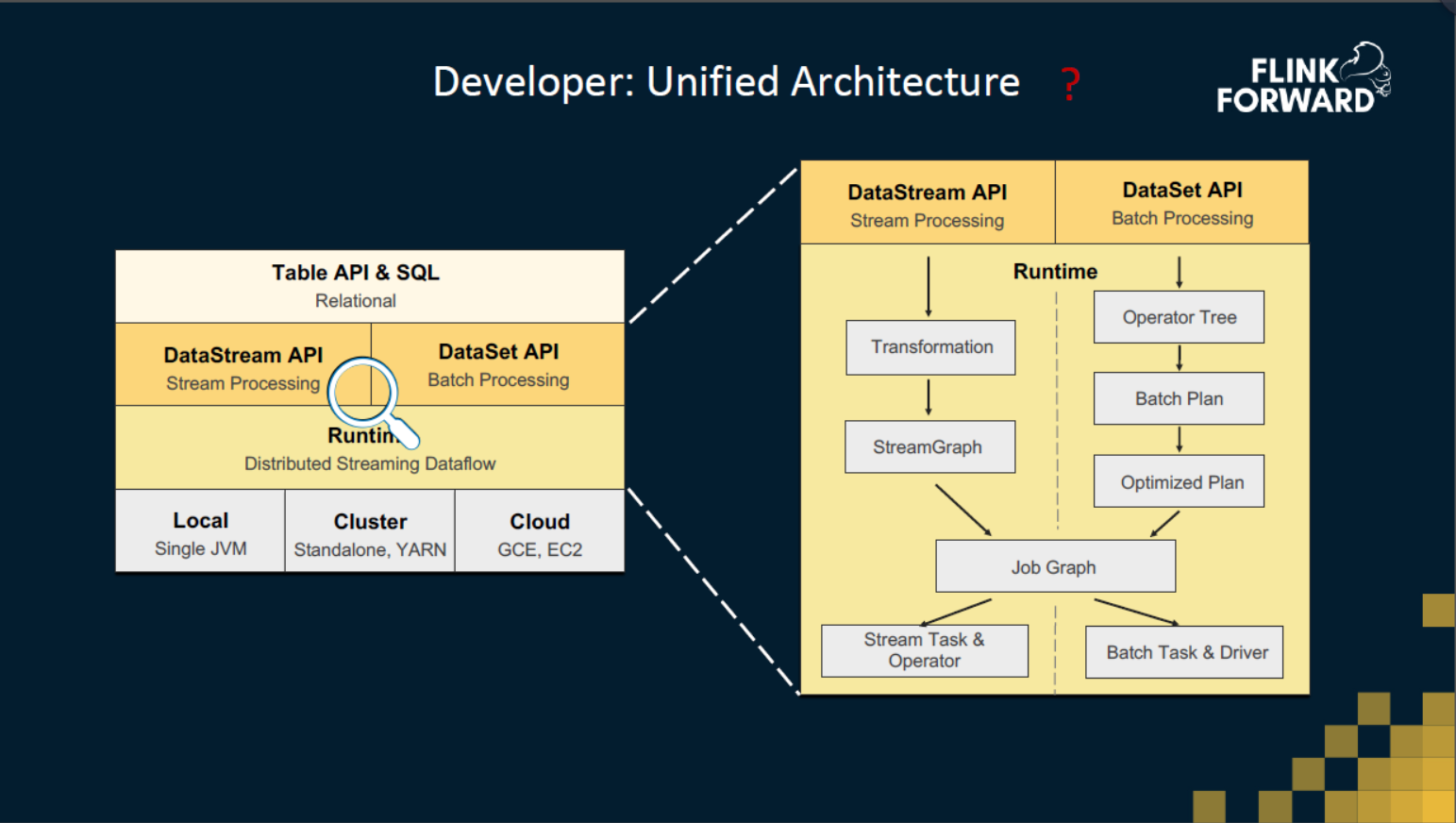
对于开发人员来说,引擎的统一又是意味着什么?这张图是目前Flink的架构图,最上层 Table API 与 SQL。在执行之前,会根据执行环境翻译成 DataSet 或 DataStream 的 API。这两个 API 之间还是有比较大的不同,我们可以放大之后看看。比如 DataSet API 是Flink批处理的API,它自己有一个优化器。 但是在DataStream API下,就是一些比较直观简单的翻译。然后在运行时,他们也是依托于不同的task。在 DataStream 这边,主要是运行Stream Task,同时在里面会运行各种各样的operator。 在批处理这边主要是运行 Batch Task 和 Driver。这个主要是执行模式的区别。

在代码上能有多少能共用的呢?比如说要实现一个 INNER JOIN,以现在的代码距离,如果要在流上实现 INNER JOIN,首先会把两路输入变成两个DataStream,然后把两个输入 connect 起来,再进行 keyBy join key,最后实现一个 KeyedCoProcessOperator 来完成 join 的操作。但是在 DataSet 这边,你会发现 API 就不太一样了,原因是 DataSet 底下是有个优化器的。换句话说,DataSet 的 API 有些是声明式的,DataStream 的 API 是命令式的。从这个例子上来看,对于我们开发人员来说,在流计算或者是在批处理下实现 JOIN 所面对的 API 其实是比较不一样的,所以这也很难让我们去复用一些代码,甚至是设计上的复用。这个是API 上的区别,到了Runtime之后,比较大的不同是 Stream Task 跟 Batch Task 的区别。
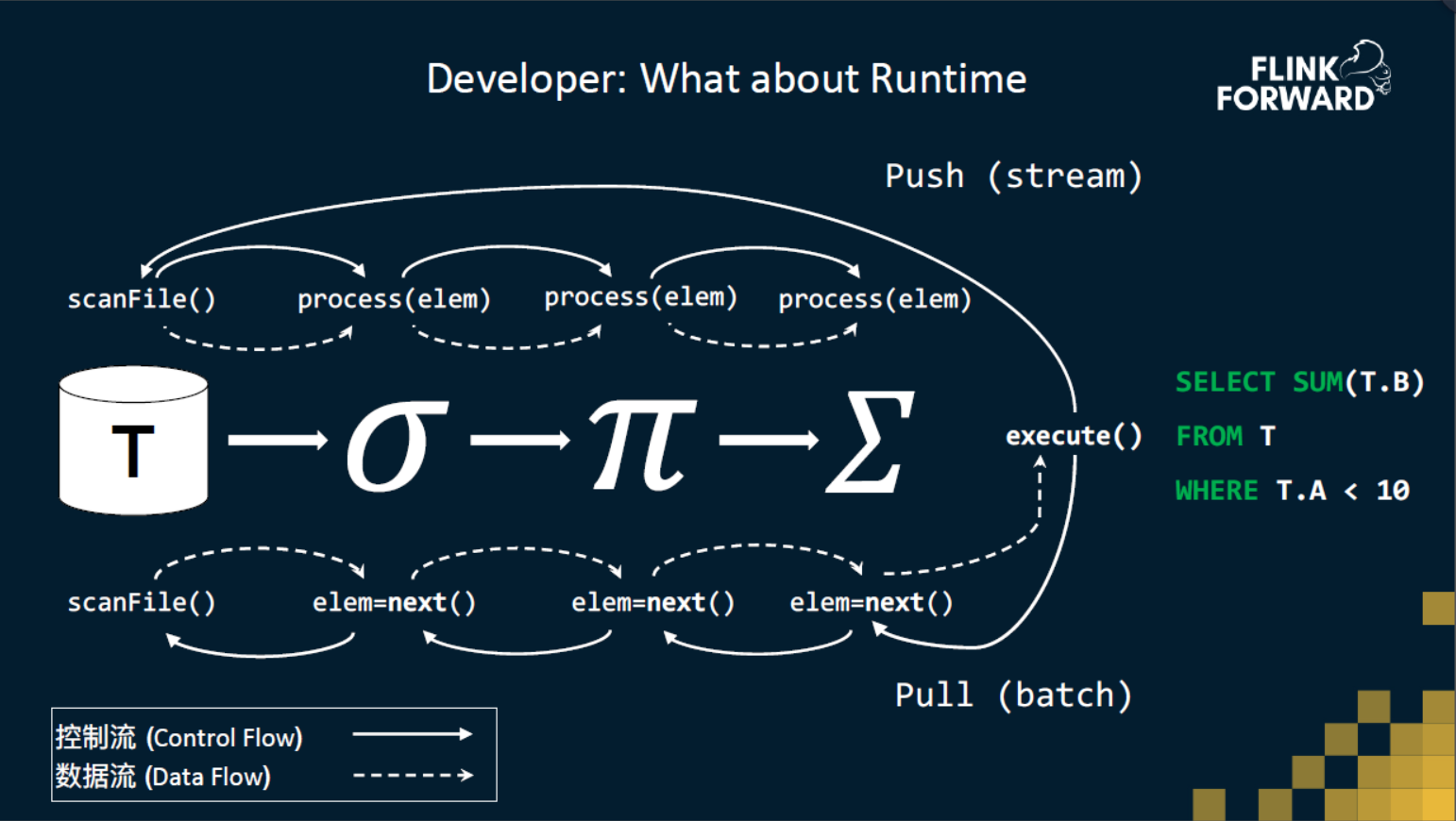
在一个经典的pull的模式下,首先会有执行器开始向执行的,可以理解为程序入口,它会向最后一个节点请求最终的结果。最后一个节点(求和节点)会向前一个节点(过滤节点)请求数据,然后再向前一个节点请求数据直到源节点。源节点就会自己去把数据读出来,然后一层层往下传递,最终最后一个节点计算完求和后返回给程序入口。这和函数调用栈非常相像。
在 push 模式下,在程序开始执行的时候,我们会直接找到 DAG 的头节点,所有的数据和控制消息都由这个头节点往下发送,控制流会跟数据流一起,相当于它同时做一个函数调用,并且把数据发送给下一个算子,最终达到求和的算子。
通过这个简单例子,大家可以体会一下,这两个在执行模式上有很大的不同,这会在 runtime 统一上带来很多问题,但其实他们完成的功能是类似的。
三、如何统一流和批
我们在深度统一流和批的道路上遇到了这么多挑战,那么是如何做到统一的呢?

01 动态表
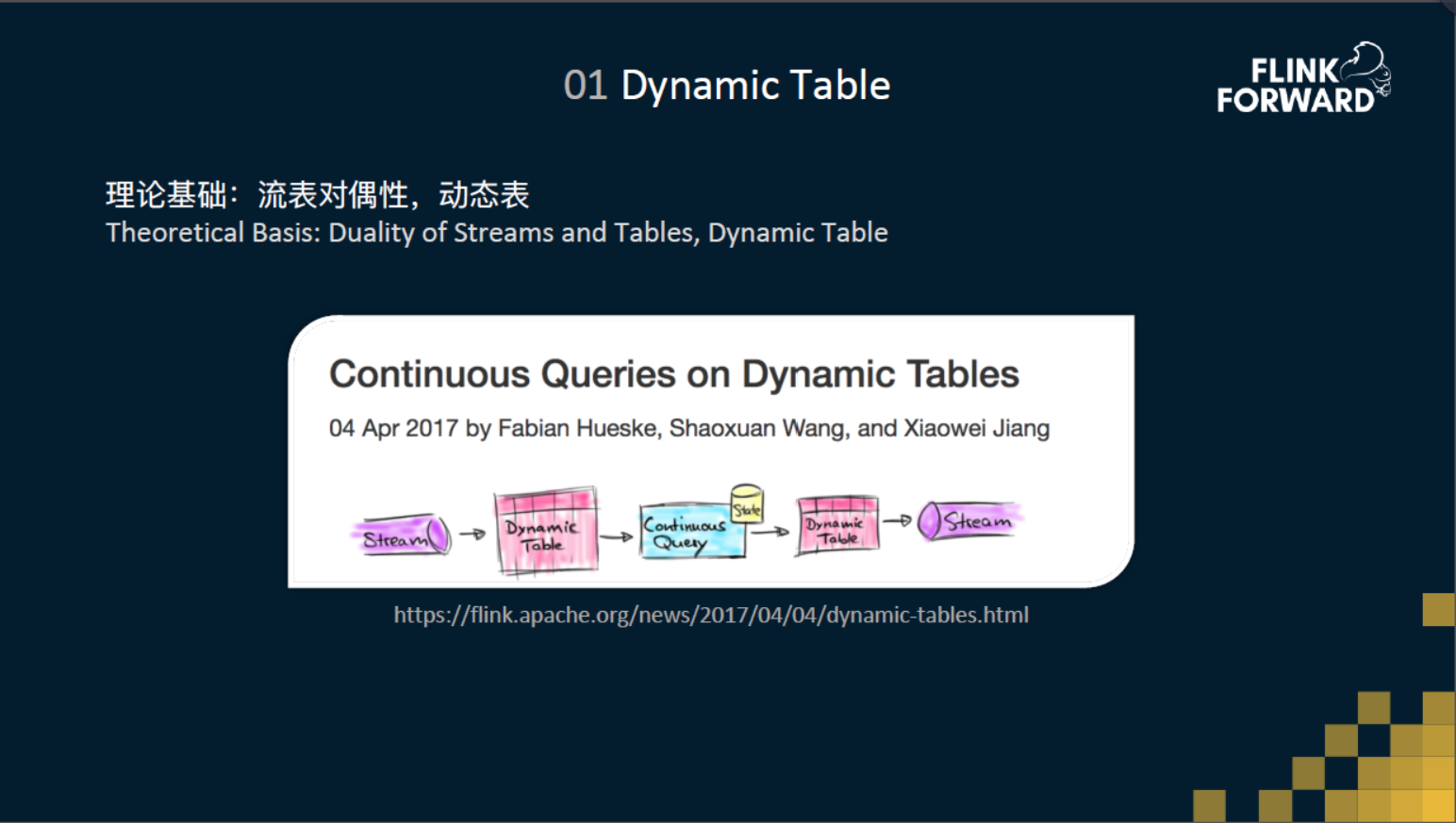
首先,大家已经越来越认同 SQL 是大数据处理的通用语言,不仅仅是因为 SQL 是一个非常易于表达的语言,还因为 SQL 是一个非常适合于流批统一的语言。但是在传统的 SQL 里面,SQL 是一直作用在“表”上的,不是作用在“流”上的。怎么样让 SQL 能够作用在流上,而且让流式 SQL 的语义、结果和批一样呢?这是我们遇到的第一个问题。为了解决这个问题,我们和社区提出了“流表对偶性”还有“动态表”的这两个理论基础。在这里,这个理论基础我们这里就不展开了,感兴趣的同学可以去官网上阅读下这篇文章。大家只需要知道只有在基于这两个理论的基础上,流式SQL的语义才能够保证和批的语义是一样的,结果是一样的。
02 架构改进
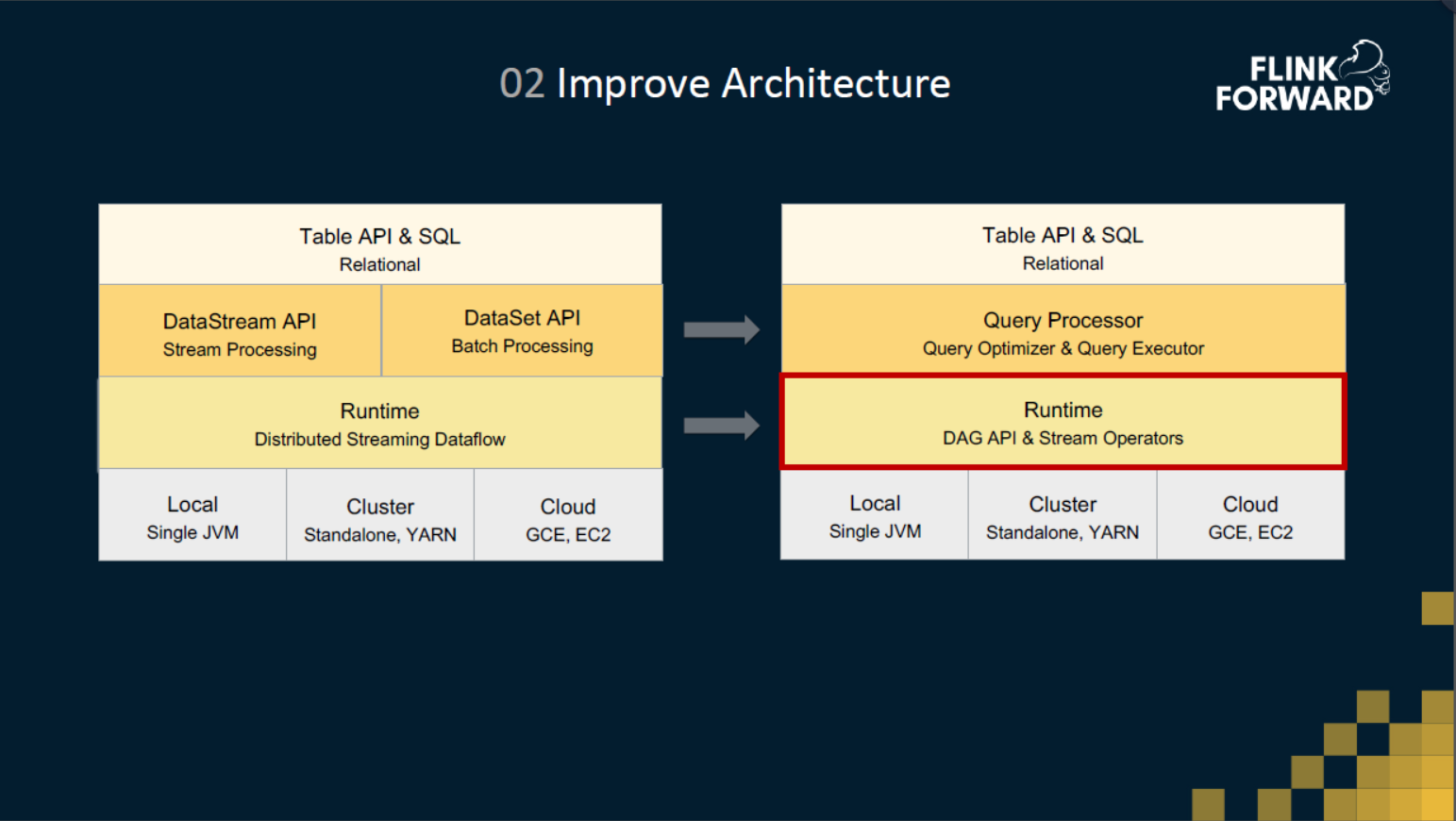
如图是对架构上的一些改进。架构的改进主要集中在中间两层,在 Runtime 层我们增强了现有的 Operator 框架,使得能支持批算子。在 Runtime 之上,我们提出了一个 Query Processor 层,包括查询优化和查询执行,Table API & SQL 不再翻译到 DataStream 和 DataSet ,而是架在 Query Processor 之上。
统一的 Operator 框架
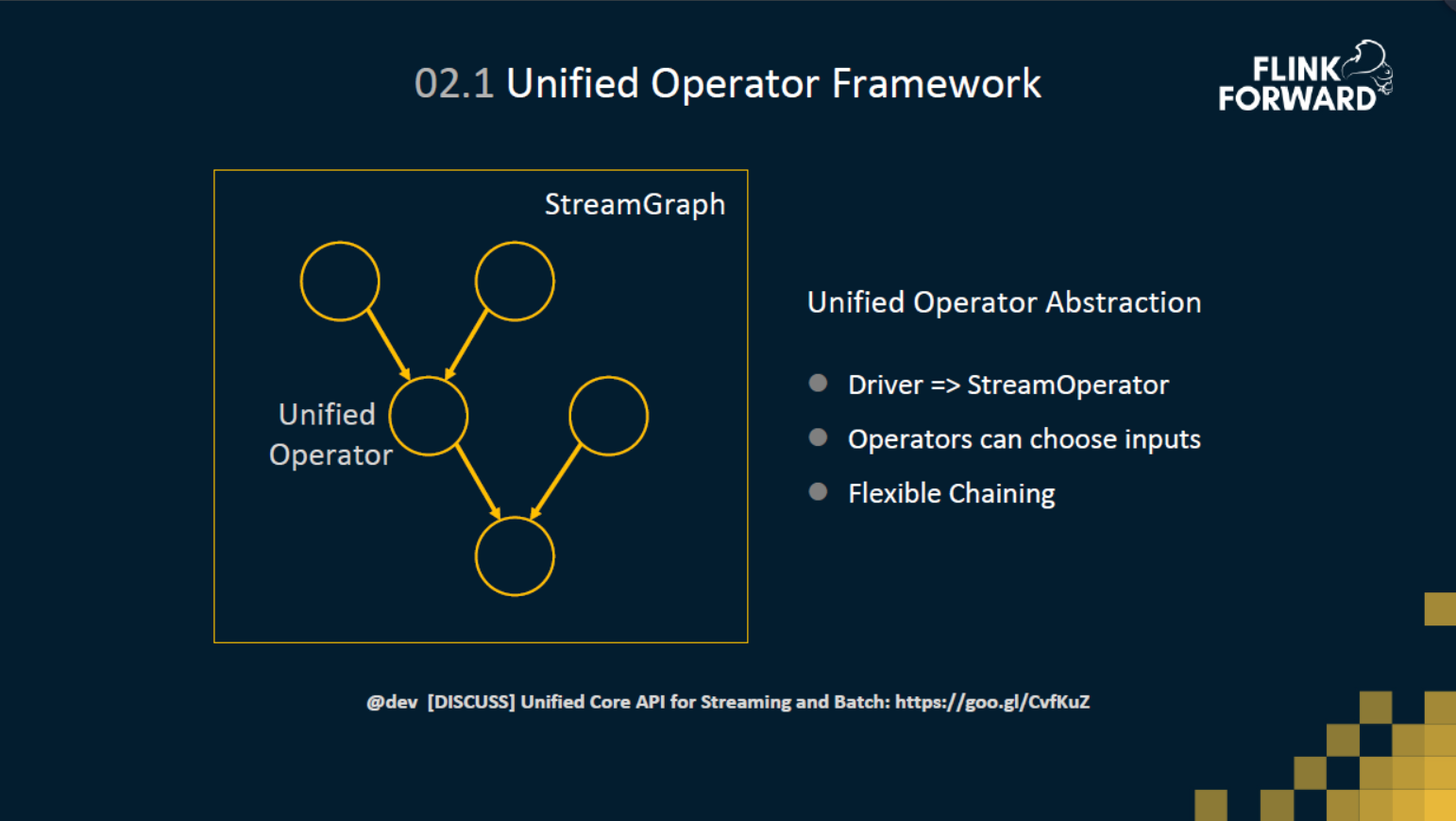
在 Runtime 层,首先实现的是 Runtime DAG 层的统一,基于统一的DAG层之上,再去构建流的算子和批的算子。为了统一流和批的最底层的API,引入了一个统一的Operator层抽象。批算子的实现不再基于 DataSet 底层 Deriver 接口实现,都基于 StreamOperator 接口来实现了。这样流和批都使用了统一的 Operator API 来实现。
除此之外,针对批的场景,我们对 Operator 框架做了些扩展使得批能获得额外的优化。
第一点是 Operator 可以自主的选择输入边,例如hashjoin,批的hashjoin一般先会把build端处理完,把哈希表先build起来,然后再去处理另外一边的probe端。
第二点是更加灵活的 Chaining 的策略。StreamOperator 的默认 Chaining 策略只能将单输入的 operator chain在一起。但是在批的一些场景,我们希望能够对多输入的Operator也进行Chaining。比如说两个 Join Operator,我们希望也能够 Chaining 在一起,这样这两个 Join Operator 之间的数据shuffle 就可以省掉。
关于统一的 Operator 框架,我们已经在社区里面展开了讨论,感兴趣的同学可以关注一下这个讨论链接。
统一的查询处理
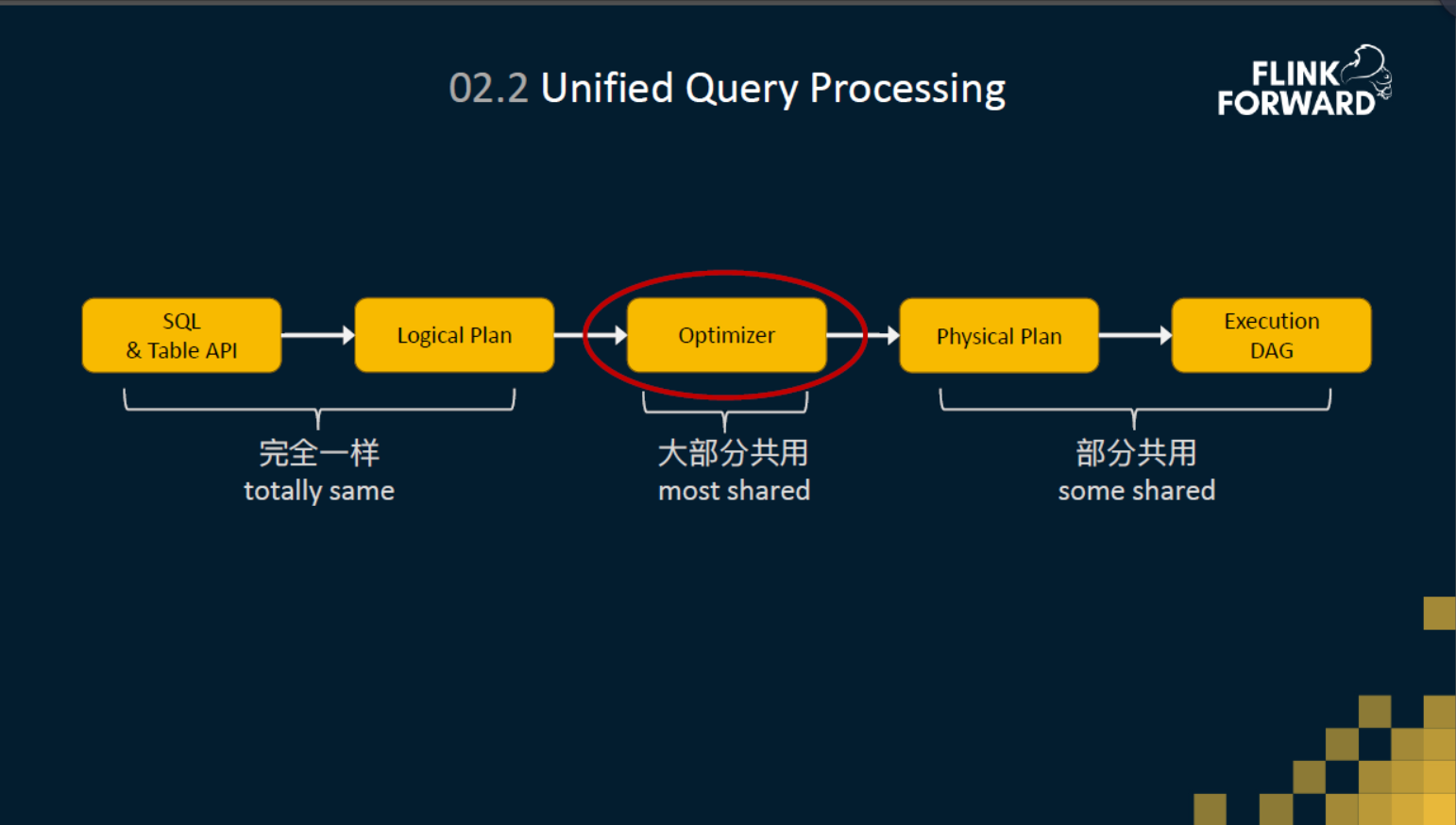
然后讲一下统一的Query Processor 层,不管是流计算还是批处理的SQL,他们都将沿着相同的解析和优化的路径往前走。在解析层,也就是将 SQL 和 Table API 代码解析成逻辑计划,这里流和批完完全全复用了一样的代码。然后在优化层流和批也使用了相同的优化器来实现,在优化器里面,所有的优化的规则都是可插拔的。流和批共用了绝大部分的优化的规则,只有少部分的规则是流特有的,或者是批特有的。然后在优化之后,得到了一个物理计划,物理的计划会经过翻译成最终的Execution DAG,也就是我们刚刚讲的Stream Operator算子,最后会分布式地运行起来。
03 优化器的统一

在优化器这一层,很符合二八定律,也就是80%的优化规则都是流和批是共享的,比如说列裁剪、分区裁剪、条件下推等等这些都是共享的。还有20%的优化规则是流批特有的,经过我们的研究发现比较有意思的一个规律。
批这边优化规则,很多都是跟sort相关相关的,因为流现在不支持sort,所以 sort 可以理解是批特有的,比如说一些sort merge join 的优化、sort agg的优化。
而流这边所特有的一些规则,都是跟state相关的。为什么呢?因为目前流作业在生产中跑一个 SQL 的作业,一般会选择使用 RocksDB 的 StateBackend。RocksDB StateBackend,它有一个很大的瓶颈,就是你每一次的操作,都会涉及到序列化和反序列化,所以说 State 操作会成为一个流作业的瓶颈。所以如何去优化一个流作业,很多时候是思考如何节省State操作,如何减小State的size,如何避免存储重复的State数据。这些都是目前流计算任务优化的立竿见影的方向。
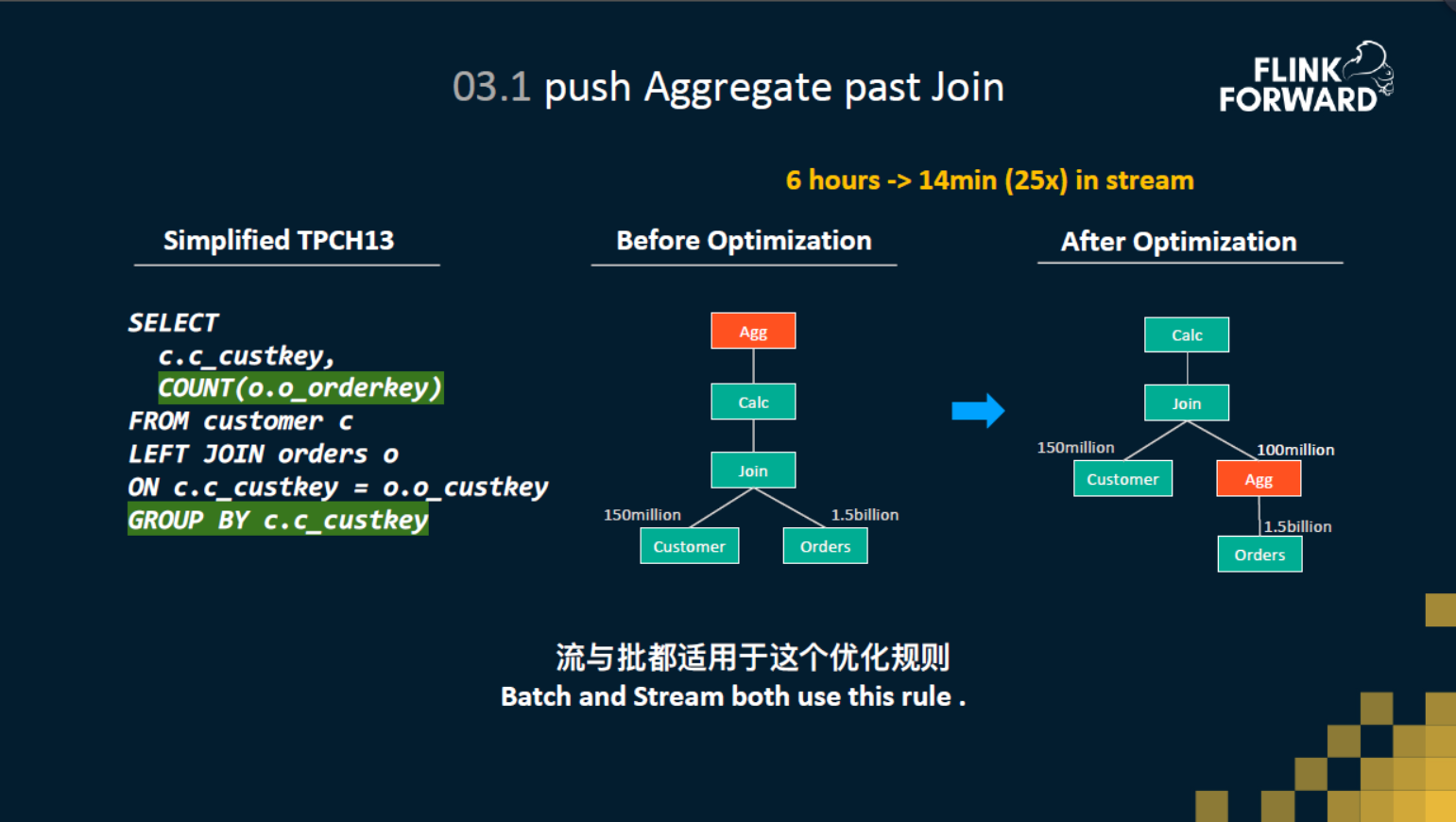
这里介绍一个流和批共用的高级一点的优化规则。大家可以先看一下上图左边这个query,这是一个经过简化之后的TBCH13的query,有一张用户表customer,还有一张订单表 orders,customer 表会根据 custkey 去 join 上 orders 这张表,然后 join 之后,再根据 custkey 来进行分组,统计出现过的订单的数量。
梳理一下就是要统计每个客户下的订单数,但是订单的数据是存在orders表里面的,所以就需要去join这个orders表。这个query经过解析之后,得到的逻辑计划就是中间这个图。可以看到customer表和orders表进行了join,join之后做了一个agg。但是这里有一个问题,就是customer表和orders表都是两张非常大的表,都是上亿级别的。在批处理下,为这个join去build哈希表的时候,要用到大量的buffer,甚至还需要落盘,这就可能导致这个join性能比较差。 在流处理下也是类似的,需要把customer表和orders表所有的数据都存到state里面去。state越大,流处理性能也就越差。
所以说怎样去节省和避免数据量是这个查询优化的方向。我们注意到customer它本身就带了一个主键就是custkey,最后的agg也是针对 custkey 进行聚合统计的。那么其实我们可以先对orders表做一个聚合统计,先统计出每个用户每个custkey它下一个多少的订单,然后再和customer表做一个join,也就是说把agg进行下推,下推到了join之前,这样子,orders表就从原来的15亿的数据量压缩到了一个亿,然后再进行join。这个对于流和批都是巨大的性能优化。我们在流场景下测试发现从原先耗时六个小时提升到了14分钟。
讲这个例子目的是想说明 SQL 已经发展了几十年了,有非常多的牛人在这个领域耕耘多年,已经有了非常多成熟的优化。这些优化,基于流批统一的模型,很多事可以直接拿过来给流用的。我们不需要再为流在开发、研究一套优化规则,做到事半功倍的效果。
04 基本数据结构的统一
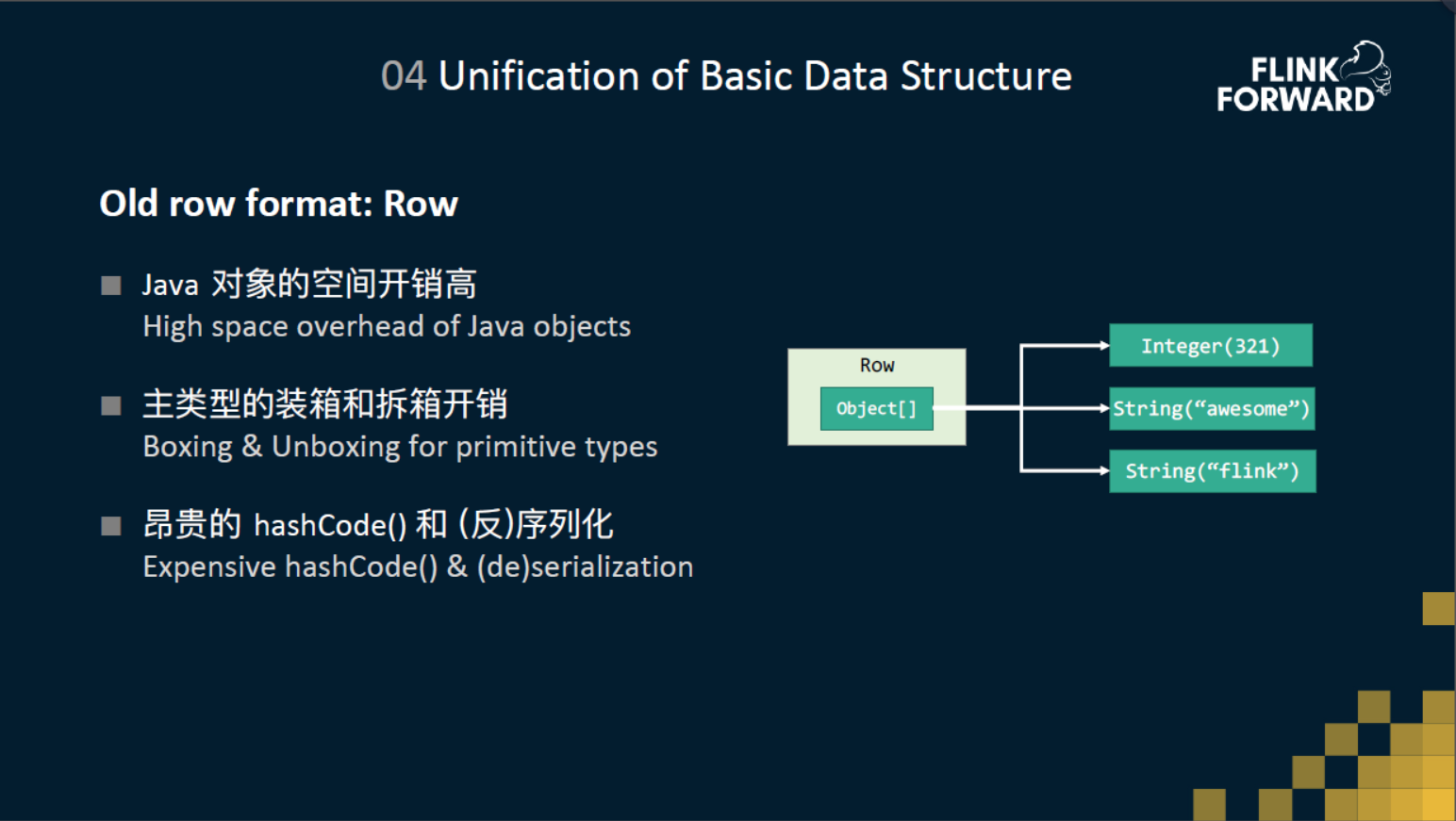
原先在 Flink 中不管流还是批,具体干活的算子之间传递的都是一种叫 Row 的数据结构。 但是Row有这么几个比较典型的问题。
-
Row结构很简单,里面就存了一个Object数组,比如说现在有一行数据,第一个是整形,另两个是字符串。那么row里面就会有一个Int,还有两个String。但是我们知道Java在对象上,它会有一些额外的空间的一些开销。
-
另外对于主类型的访问,会有装箱和拆箱的开销。
-
还有在算Row的hashcode、序列化、反序列化时,需要去迭代Row里面数组的每一个元素的hashcode方法、反序列化方法、序列化方法,这就会涉及到很多额外的虚函数调用的开销。
-
最后一点是对于一些稍微高级一点的数据结构,比如说排序器 sort,还有agg join中的一些hashtable,hashmap的这种二进制的数据结构,基于Row的这种封装,很难去做到极致的效率。
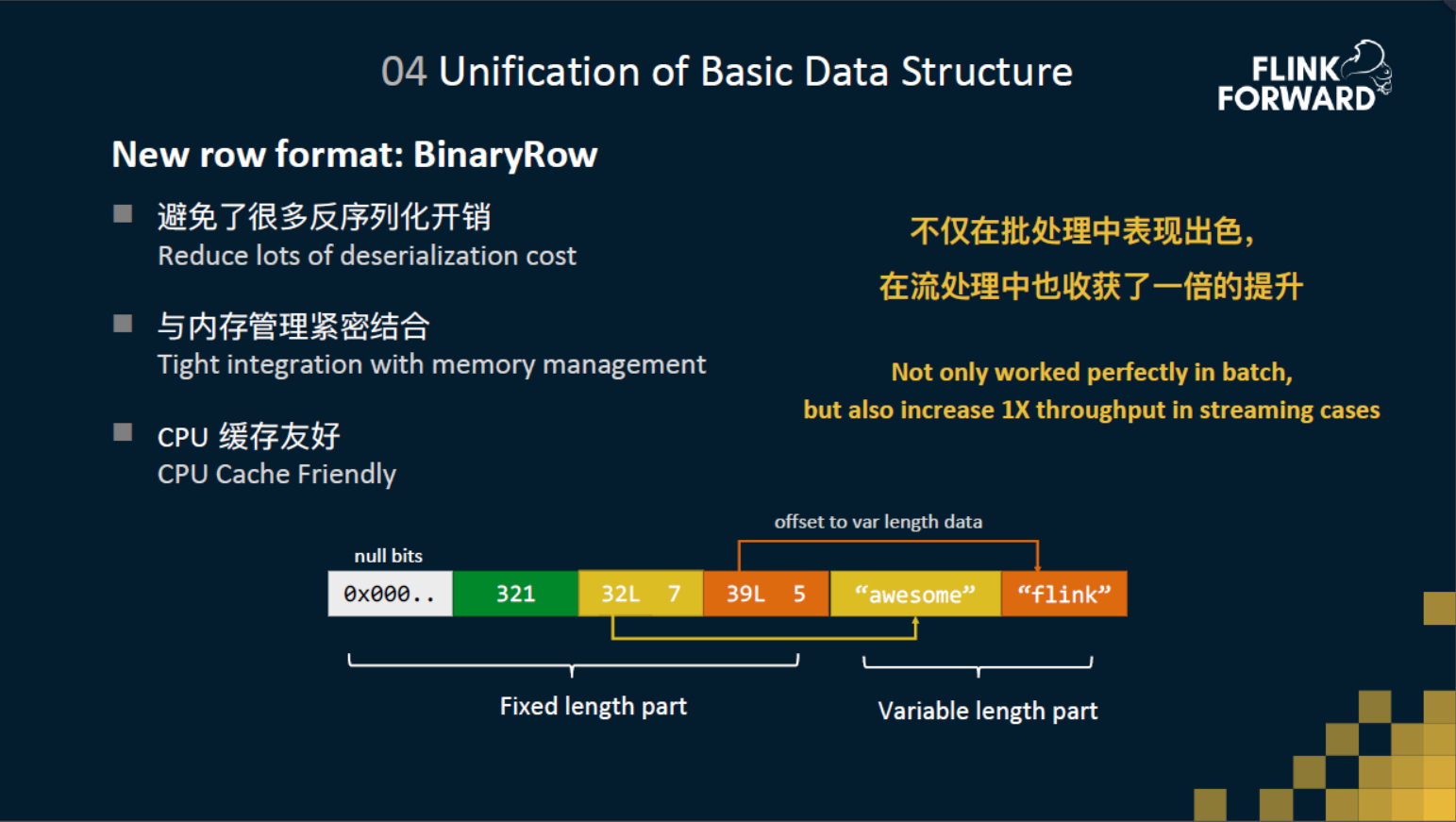
所以针对这些问题,我们也提出了一个全新的数据结构BinaryRow,然后它是完全基于二进制的结构来设计的。BinaryRow 分成了定长区和变长区,在定长区开头是一个null bit的一个区间,用来记录每个字段是否是null值。然后像int,long,double这种定长的数据类型,我们会直接把这个直接存在定长区里面,然后string这种变长形的数据,我们会把他的变长的数据存在变长区,然后把他的指针还有他的长度存在定长区。在存放数据的时候,BinaryRow 中每一个数据块都是八字节对齐的。 为什么八字节对齐?一方面是为了更快的 random access,查找字段时不需要从头遍历,直接就能定位到字段的位置。另一方面是能够做到更好的cpu的缓存。
BinaryRow 有一个比较重要的优点:延迟反序列化。例如从网络过来的二进制数据、从state拿到的二进制数据,不会马上反序列化出来,而是会 wrap 成 BinaryRow,当需要的时候才进行反序列化,这能节省很多不必要的反序列化操作,从而提升性能。经过测试,这个数据结构不仅在批处理中表现的非常优秀,在流处理中也得到了一倍的性能提升。
05 实现Runtime共享
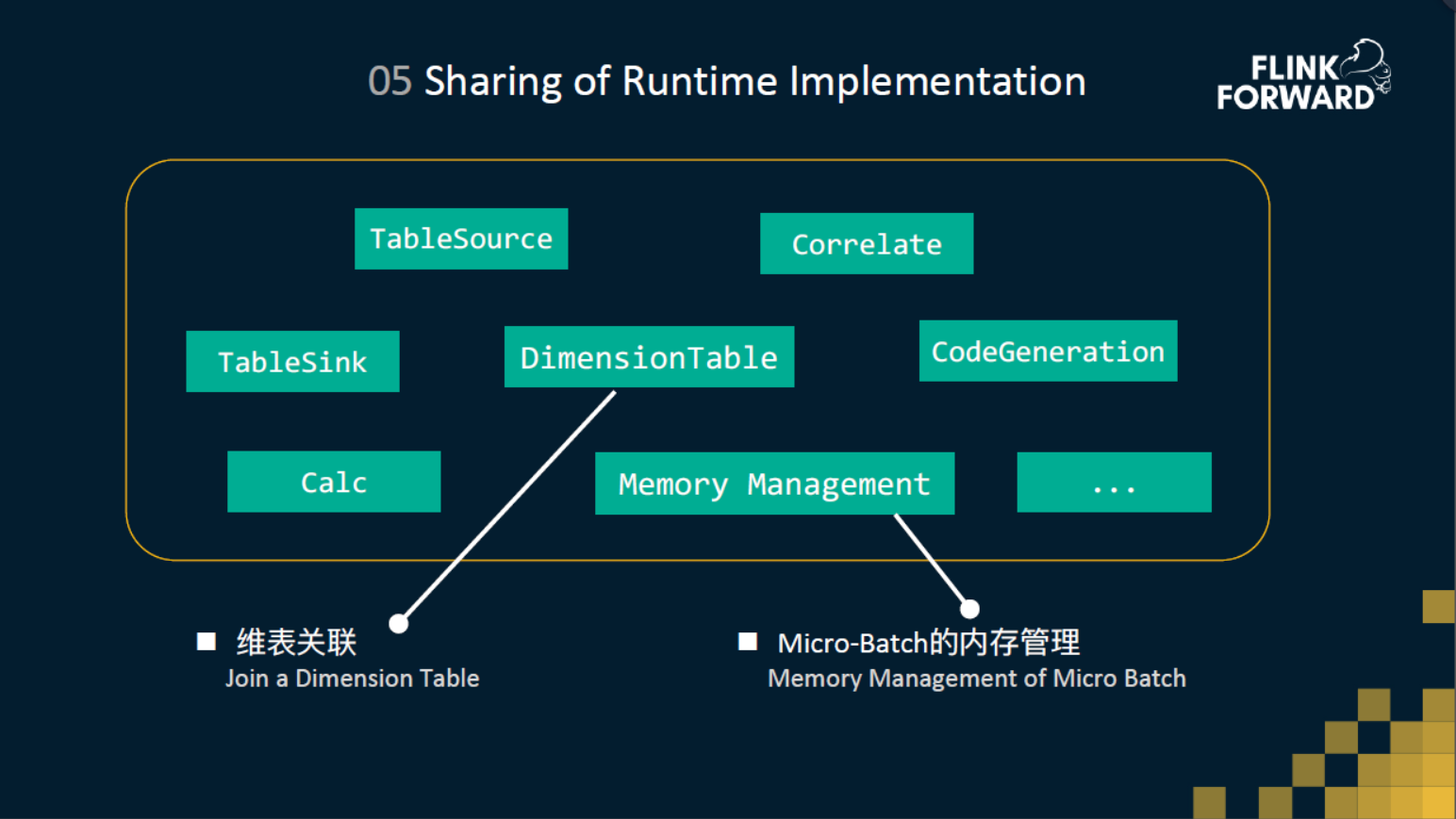
1 维表关联
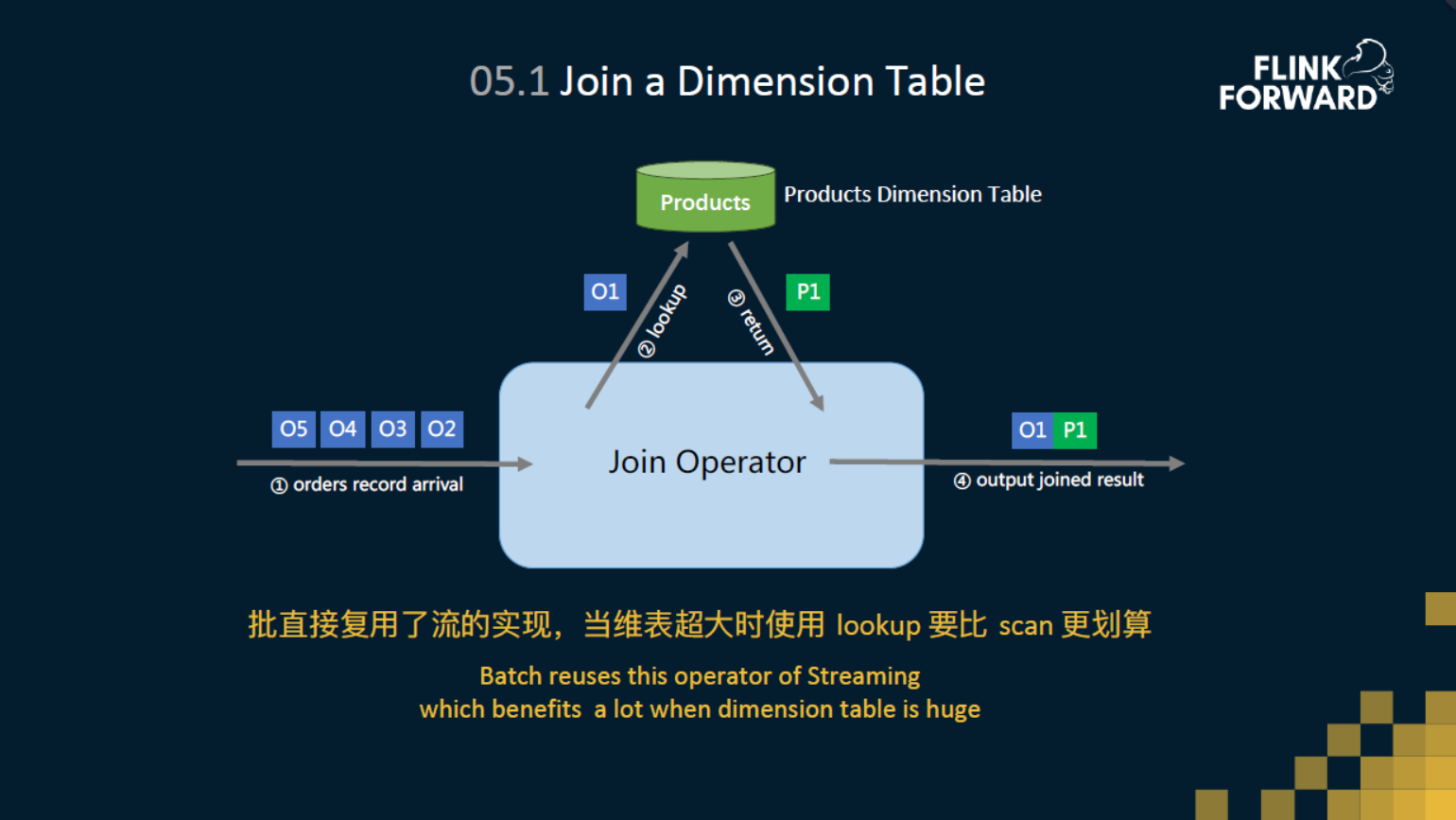
维表关联,大家应该都比较了解,就是一个流要去join一个存在外部的数据库。我们会拿流数据的 ID 去 lookup 维表,这个lookup的过程,我们会实现成同步的模式或者是异步的模式。 我们知道 DataStream 上支持了异步IO接口,但是DataSet是没有的。不过由于我们统一了Operator层,所以说批可以直接复用流的 operator 实现。虽然在传统的批处理中,如果要查询维表,会先把维表scan下来再做 JOIN。但如果说维表特别大,probe端特别小,这样可能是不划算的,使用lookup的方式可能会更高效一些,所以说这也是弥补了批在某些场景的一个短板。
2 流的微批处理
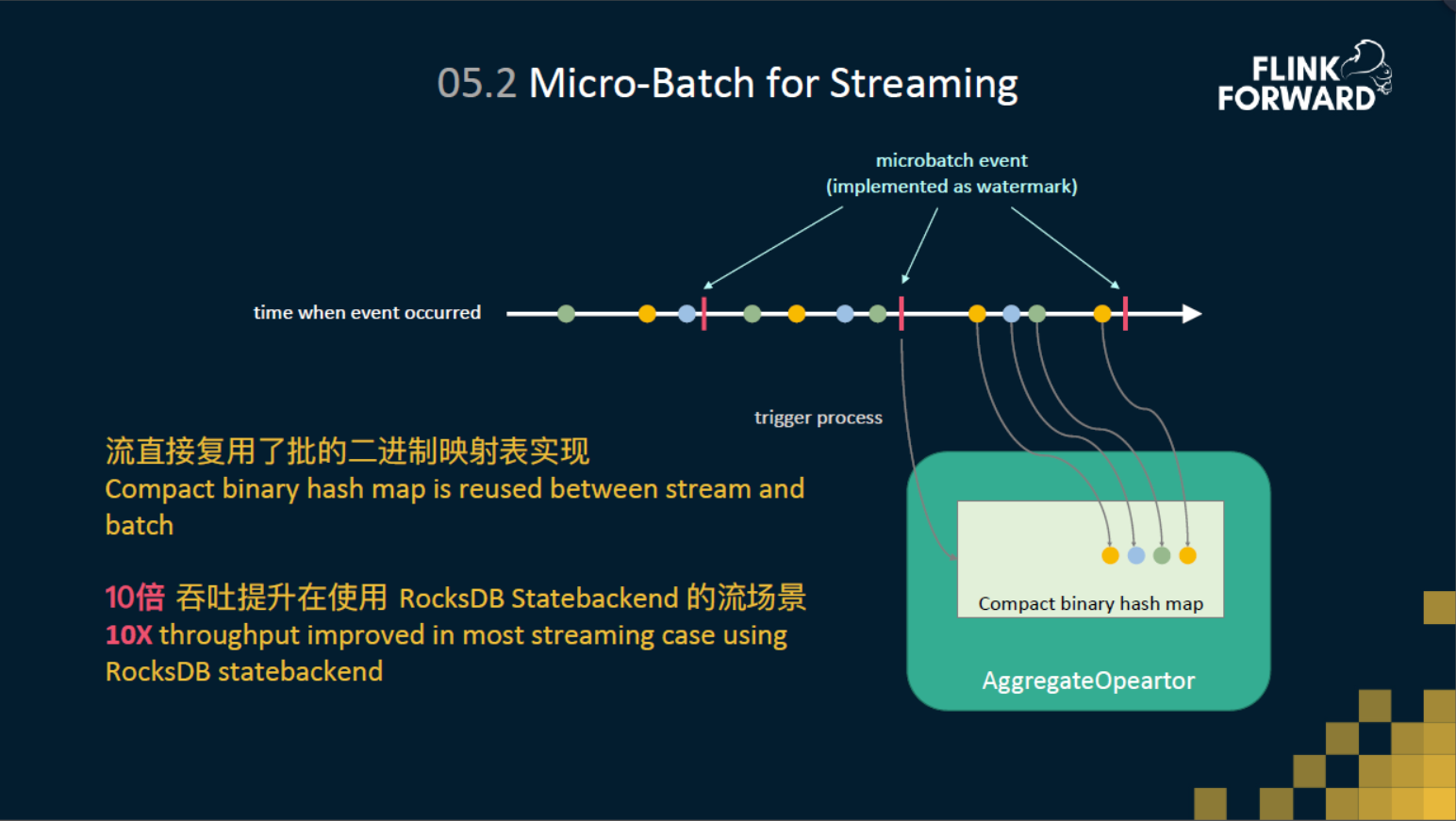
为了避免对state的频繁操作,我们在流上引入了Micro-Batch 机制。实现方式就是在数据流中插入了一些 micro-batch 的事件。然后在Aggregate的Operator里面,收到数据的时候,我们就会把它存到或直接聚合到二进制的哈希表里面(缓存到内存中)。然后当收到 micro-batch 事件的时候,再去触发二进制的映射表(BinaryHashMap),将缓存的结果刷到 state 中,并将输出最终结果。 这里 BinaryHashMap 是完全和批这边复用的。流这边没有去重新造一套,在性能上也得到了十倍的提升。
四、性能表现
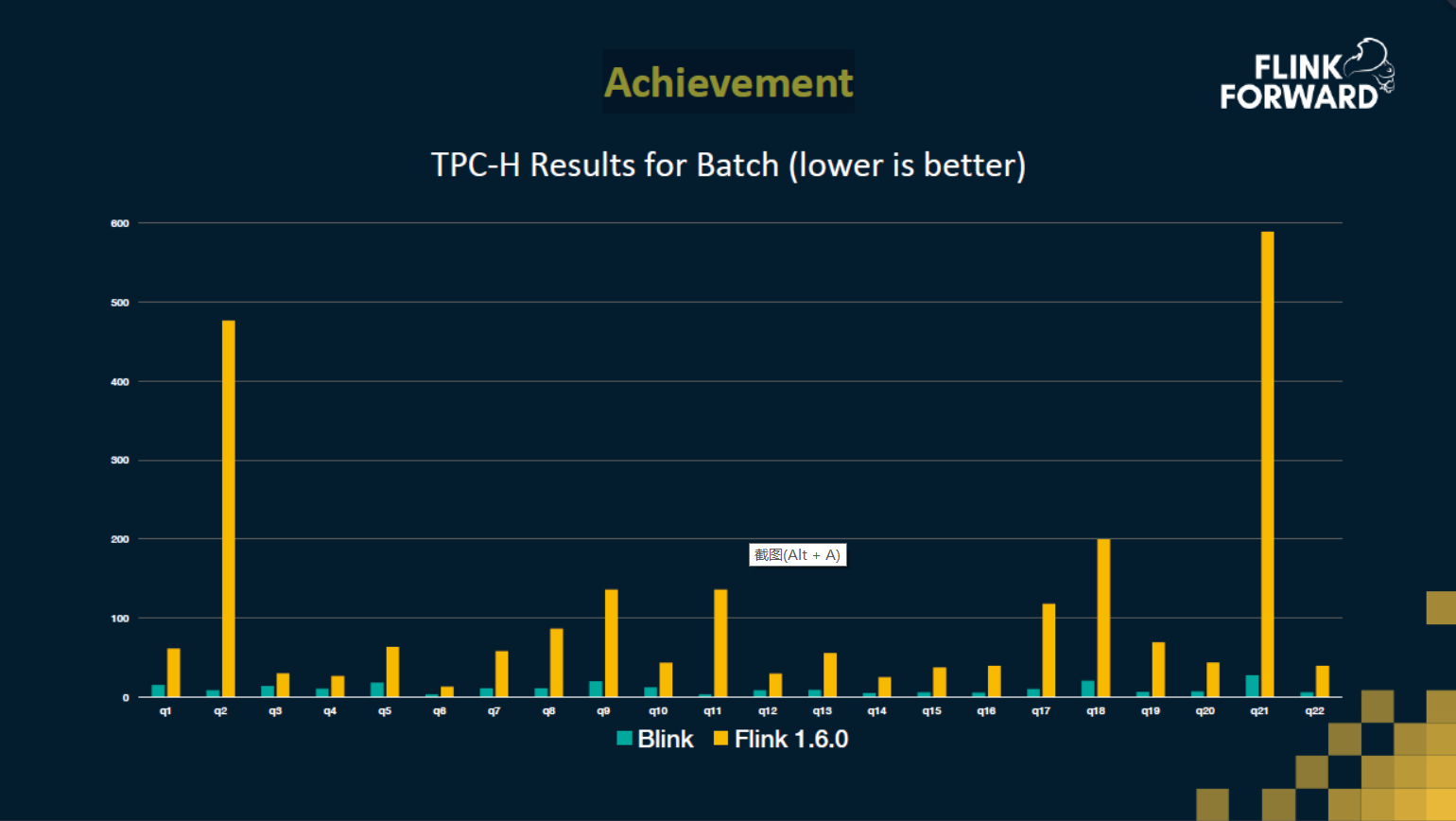
我们先测试了一个批的性能,拿的是TPC-H去做一个测试。我们与Flink1.6.0进行了比较,这个图是在1T的数据量下每个query的一个耗时的对比,所以说耗时越小,它的性能也就越好。可以看出每一个query,Blink都会比Flink1.6 要优秀很多。 平均性能上要比Flink1.6要快十倍。另外借助统一的架构,流也成功的攻克了所有的TBCH的query。值得一提的是,这是目前其他引擎做不到的。还有在今年的天猫双11上流计算,达到了17亿的TPS这么大的一个吞吐量。能达到这么高的性能表现,离不开我们今天聊的统一流批架构。

五、未来计划
我们会继续探索流和批的一些结合,因为流和批并不是非黑即白的,不是说批就是批作业,流就是流作业,流和批之间还有很多比较大的空间值得我们去探索。比如说一个作业,他可能一部分是一个一直运行的流作业,另一部分是一个间隔调度的批作业,他们之间是融合运行着的。再比如一个批作业运行完之后,怎么样能够无缝地把它迁移成一个流作业,这些都是我们未来尝试去做的一些研究的方向。
更多资讯请访问 Apache Flink 中文社区网站
