

消息中间件/系统
中间件
中间件是一类连接软件组件和应用的计算机软件,它包括一组服务。以便于运行在一台或多台机器上的多个软件通过网络进行交互。
该技术所提供的互操作性,推动了一致分布式体系架构的演进,该架构通常用于支持并简化那些复杂的分布式应用程序,它包括 web服务器、事务监控器和消息队列软件。
消息队列
在计算机科学中,消息队列(英语:Message queue)是一种进程间通信或同一进程的不同线程间的通信方式,软件的贮列用来处理一系列的输入,通常是来自用户。
消息队列提供了异步的通信协议,每一个贮列中的纪录包含详细说明的数据,包含发生的时间,输入设备的种类,以及特定的输入参数,也就是说:消息的发送者和接收者不需要同时与消息队列交互。消息会保存在队列中,直到接收者取回它。
消息队列常常保存在链表结构中。拥有权限的进程可以向消息队列中写入或读取消息。
--以上来自 维基百科
让我们用快递员送快递的例子来理解。
最开始送上门,你有时候不在家,又只有等第二天,现在多了个菜鸟驿站,快递小哥只需要往里面放,你有快递自己去驿站拿就行了。
快递小哥也不用直接对接这么多的客户,有包裹往驿站丢就行,然后我们去驿站拿,就算有时候我们不空,也可以让包裹在驿站多放几天,这也就是它的堆积能力。
为什么我们要用消息队列
异步处理
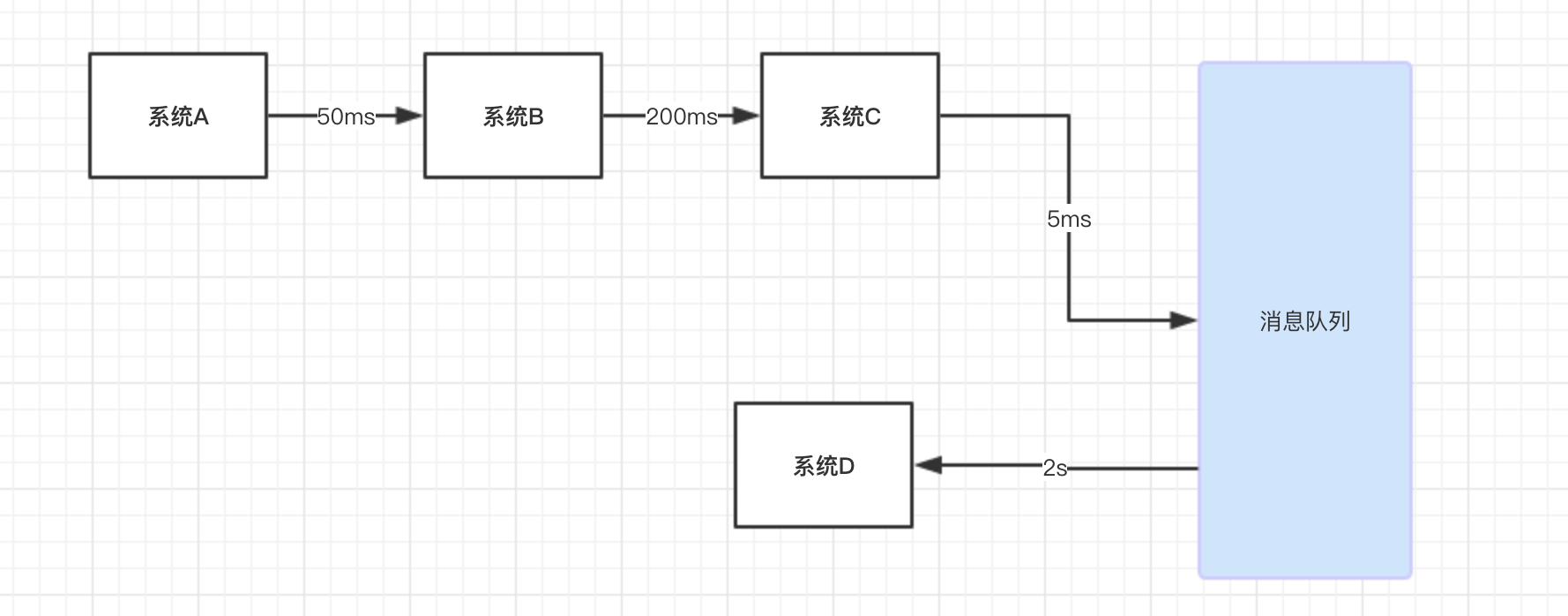
假设你有一个系统调用的链路,系统A 调用系统B 耗时 50ms,系统B 调用系统C 又需要200ms ,系统C 调用系统 D ,需要做比较超时的操作,需要 2s,如下图所示:

现在上面最大的问题在于:一个用户请求过来,整个链路的调用时间是 50ms + 200ms + 2000ms = 2250ms,也就是2秒多。
而事实上,调用链路中,系统A 调用系统 B,系统B 调用系统 C 总共加起来也才 250ms,但是系统C调用系统D 却用了 2S。
正是加入系统C调用系统D 这个链路,导致系统响应时间 从 250ms 增加到了 2250 ms,足足慢了 10倍。
如果说,我们把系统D 从链路中抽离出去,让 C 系统异步调用D,那么在 B系统调用 C,C 处理完成自己的逻辑,发送一个异步的请求去调用D系统,不用阻赛等到 D系统响应了再返回。这是不是好很多了呢?
举一个例子,就以我们平常点外卖为例:
我们平常点完餐,付完款,系统然后平给账户扣款、创建订单、通知商家准备菜品。
接着,是不是需要找个骑手给你送餐?那这个找骑手的过程,是需要一套复杂算法来实现调度的,比较耗时。
那么我们是不是就可以把找骑手给你送餐的这个步骤从链路中抽离出去,做成异步化的,哪怕延迟个几十秒,但是只要在一定时间范围内给你找到一个骑手去送餐就可以了。
这样是不是就可以让你下订单点外卖的速度变得超快?支付成功之后,直接创建好订单、账户扣款、通知商家立马给你准备做菜就ok了,这个过程可能就几百毫秒。然后后台异步化的耗费可能几十秒通过调度算法给你找到一个骑手去送餐,但是这个步骤不影响我们快速下订单。
所以上面的链路也是同理,如果业务流程支持异步化的话,是不是就可以考虑把系统C对系统D的调用抽离出去做成异步化的,不要放在链路中同步依次调用。
整个过程如下:
消息解耦
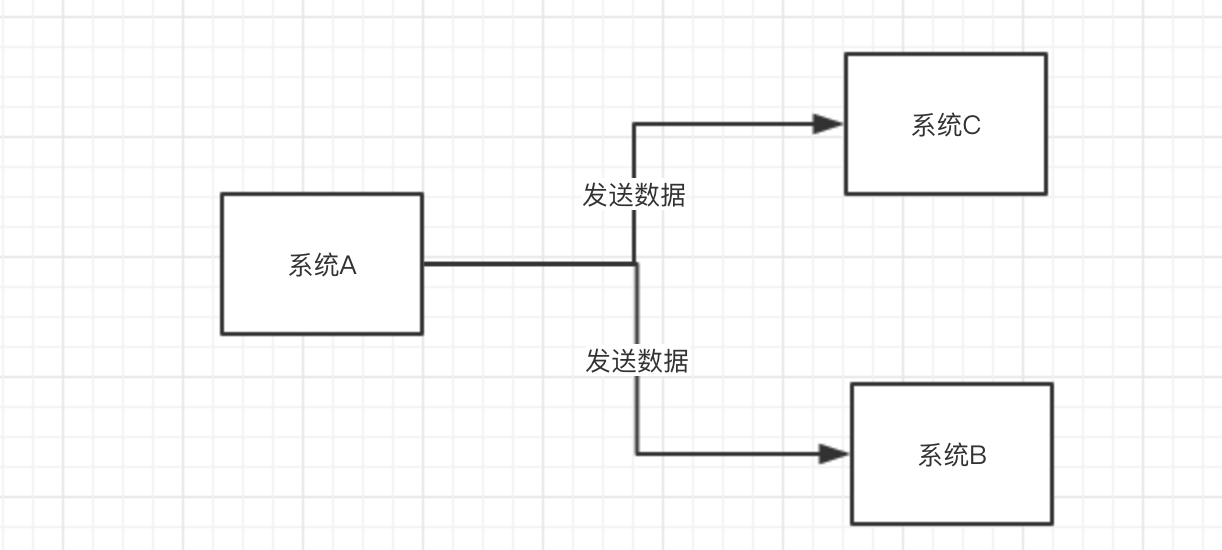
假如你现在系统A,这个系统会产出一个核心数据,下游系统 B和 C 都需要这个数据。
那么我们平常做的就是直接调用系统 B 和系统 C,发送数据过去。
过程如下:
过几天,其他的业务系统D、E 也需要这个数据,然后成了这样
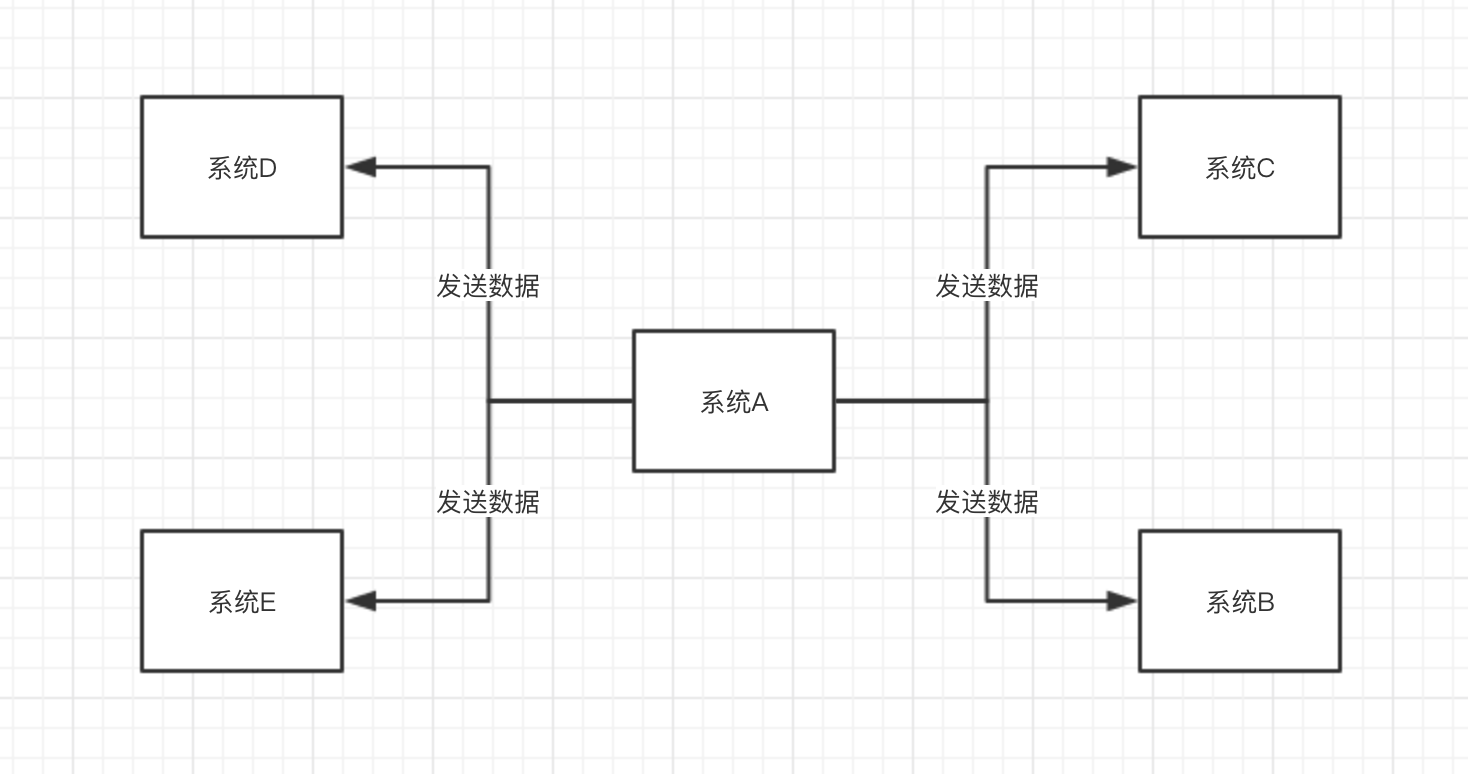
如果后续还有系统要呢?你不该代码改死。。。
这种情况系统耦合非常的严重,如果你发送一个系统的调用失败了怎么整?
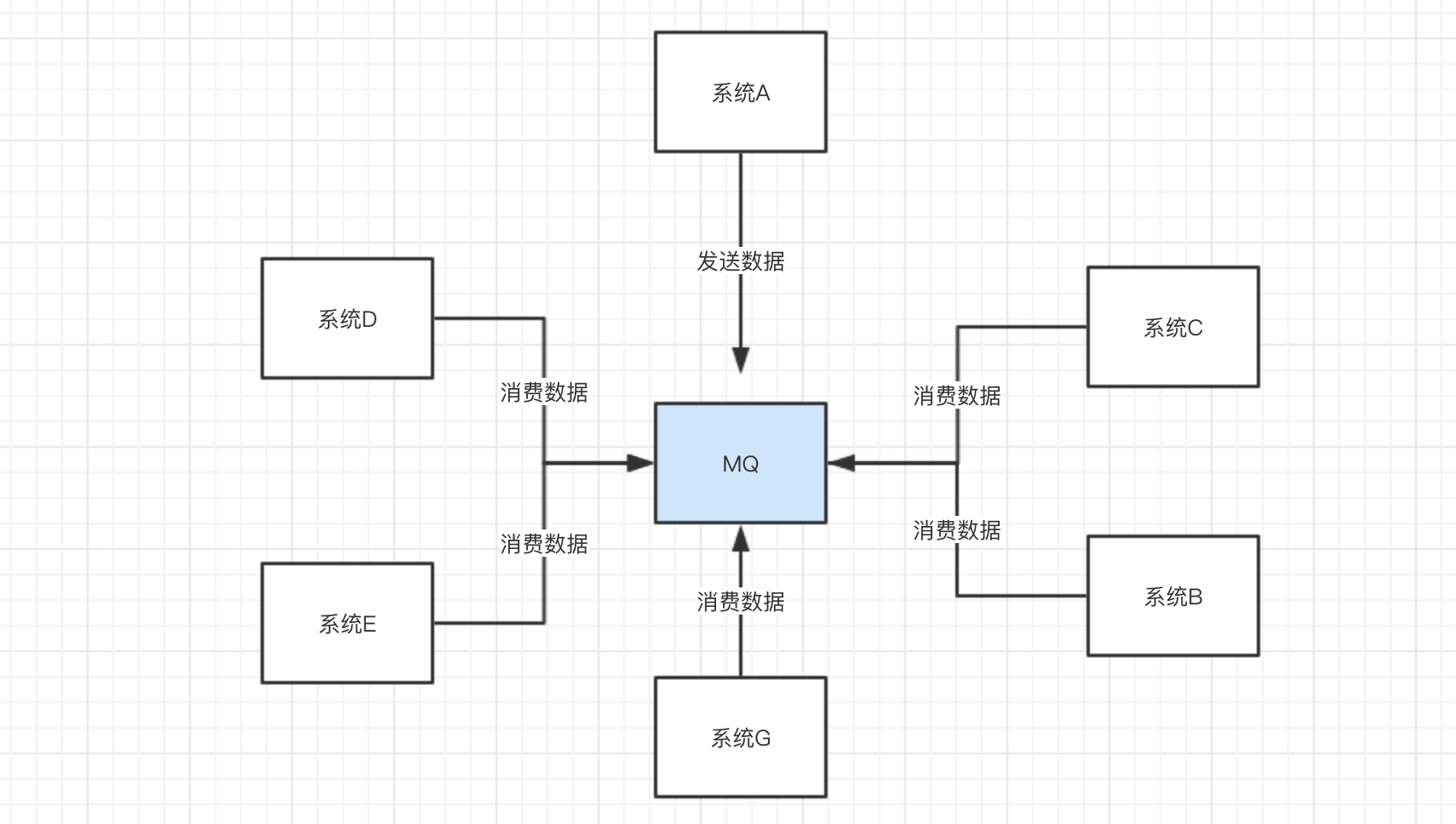
针对上面的问题,我们可以使用消息队列来实现系统解藕。
系统A 把数据发送到消息队列中,其他的系统,谁需要,自己去 消息队列 取就完了。
流量消峰&日志收集
假设你有一个系统,平时正常的时候每秒可能就几百个请求,系统部署在8核16G的机器的上,正常处理都是ok的,每秒几百请求是可以轻松抗住的。
但是如下图所示,在高峰期一下子来了每秒钟几千请求,瞬时出现了流量高峰,此时你的选择是要搞10台机器,抗住每秒几千请求的瞬时高峰吗?
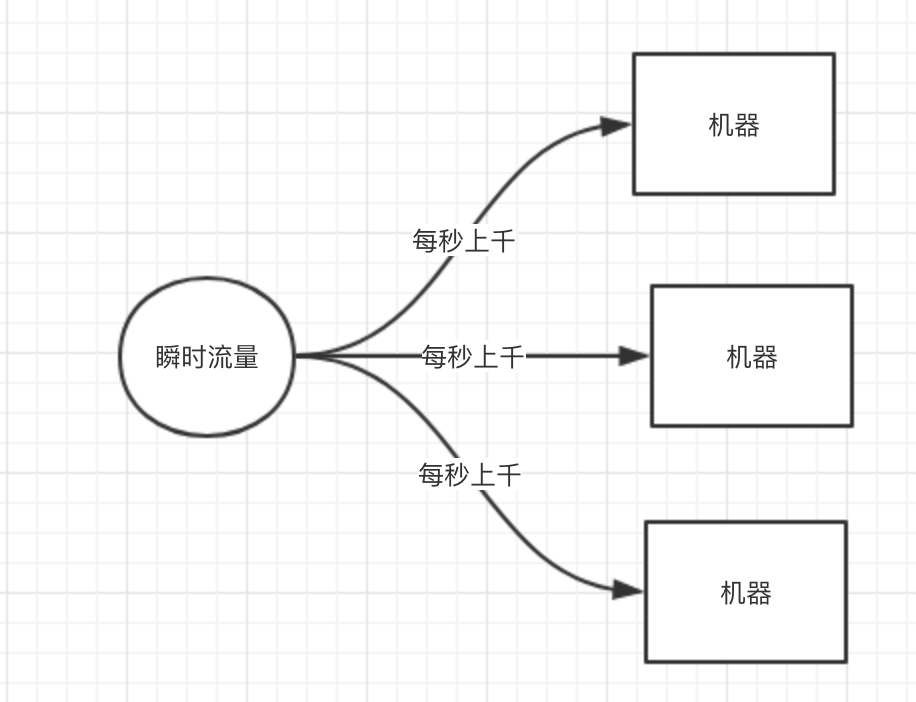
那如果瞬时高峰每天就那么半个小时,接着直接就降低为了每秒就几百请求,如果你线上部署了很多台机器,那么每台机器就处理每秒几十个请求就可以了,这不是有点浪费机器资源吗?
大部分时候,每秒几百请求,一台机器就足够了,但是为了抗那每天瞬时的高峰,硬是部署了10台机器,每天就那半个小时有用,别的时候都是浪费资源的。
此时我们就可以使用消息队列来帮忙了,进行消峰。所有机器前面部署一层MQ,平时每秒几百请求大家都可以轻松接收消息。
一旦到了瞬时高峰期,一下涌入每秒几千的请求,就可以积压在MQ里面,然后那一台机器慢慢的处理和消费。
等高峰期过了,再消费一段时间,MQ里积压的数据就消费完毕了。
如下图:
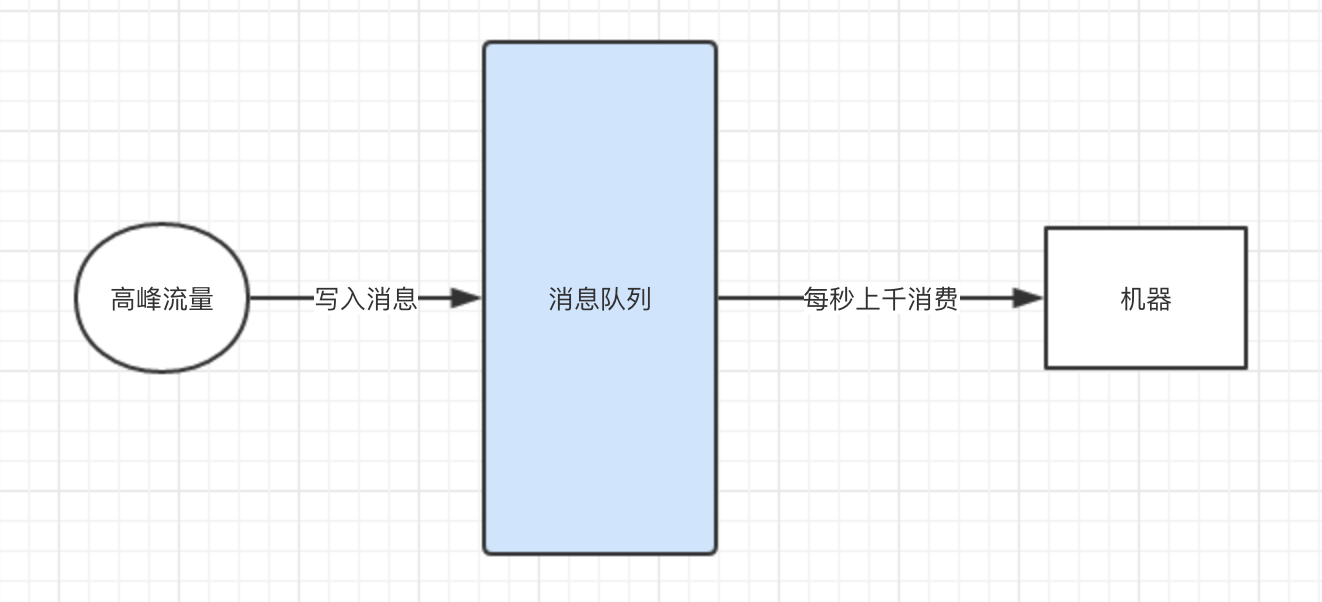
以上内容来自于【石杉的架构笔记】,图是自个画的,算是自己的一些理解吧。
要了解他的更多内容,移步 juejin.cn/user/208432…
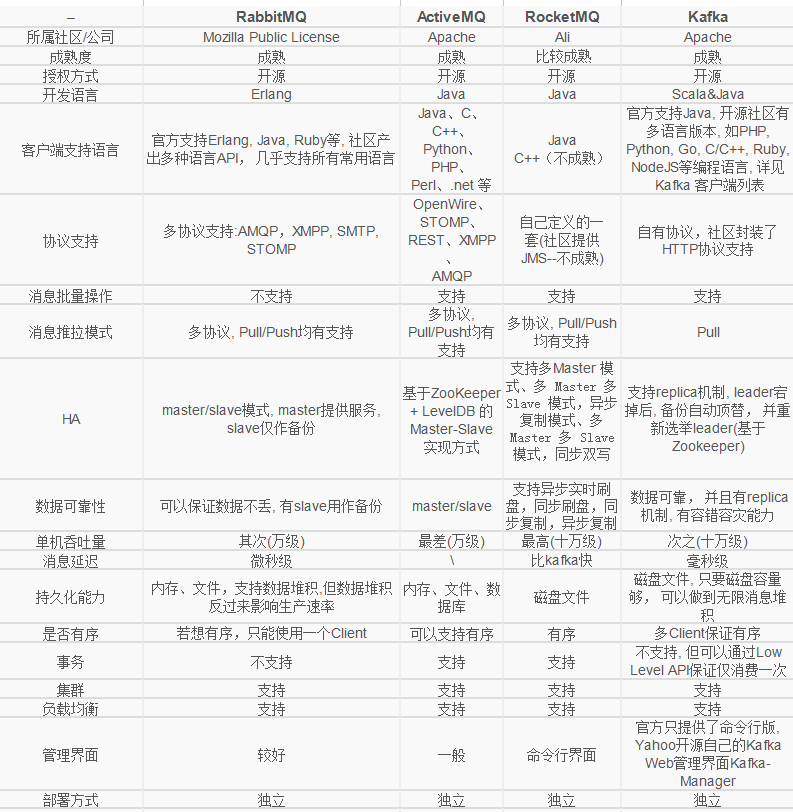
消息队列有哪些
四种常用的消息队列 ActiveMQ、RabbitMQ、RocketMQ、Kafka
Kafka 是什么
Kafka是一种高吞吐量的分布式发布订阅消息系统,使用Scala编写。
对于熟悉JMS(Java Message Service)规范的同学来说,消息系统已经不是什么新概念了(例如ActiveMQ,RabbitMQ等)。
Kafka拥有作为一个消息系统应该具备的功能,但是确有着独特的设计。可以这样来说,Kafka借鉴了JMS规范的思想,但是确并没有完全遵循JMS规范。
kafka是一个分布式的,分区的消息(官方称之为commit log)服务。它提供一个消息系统应该具备的功能,但是确有着独特的设计。首先,让我们来看一下基础的消息(Message)相关术语:
- Topic: Kafka按照Topic分类来维护消息
- Producer: 我们将发布(publish)消息到Topic的进程称之为生产者(producer)
- Consumer: 我们将订阅(subscribe)Topic并且处理Topic中消息的进程称之为消费者(consumer)
- Broker: Kafka以集群的方式运行,集群中的每一台服务器称之为一个代理(broker)。
因此,从一个较高的层面上来看,producers 通过网络发送消息到Kafka集群,然后consumers来进行消费,如下图:
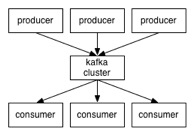
服务端(brokers)和客户端(producer、consumer)之间通信通过TCP协议来完成。我们为Kafka提供了一个Java客户端,但是也可以使用其他语言编写的客户端。
Kafka的架构图
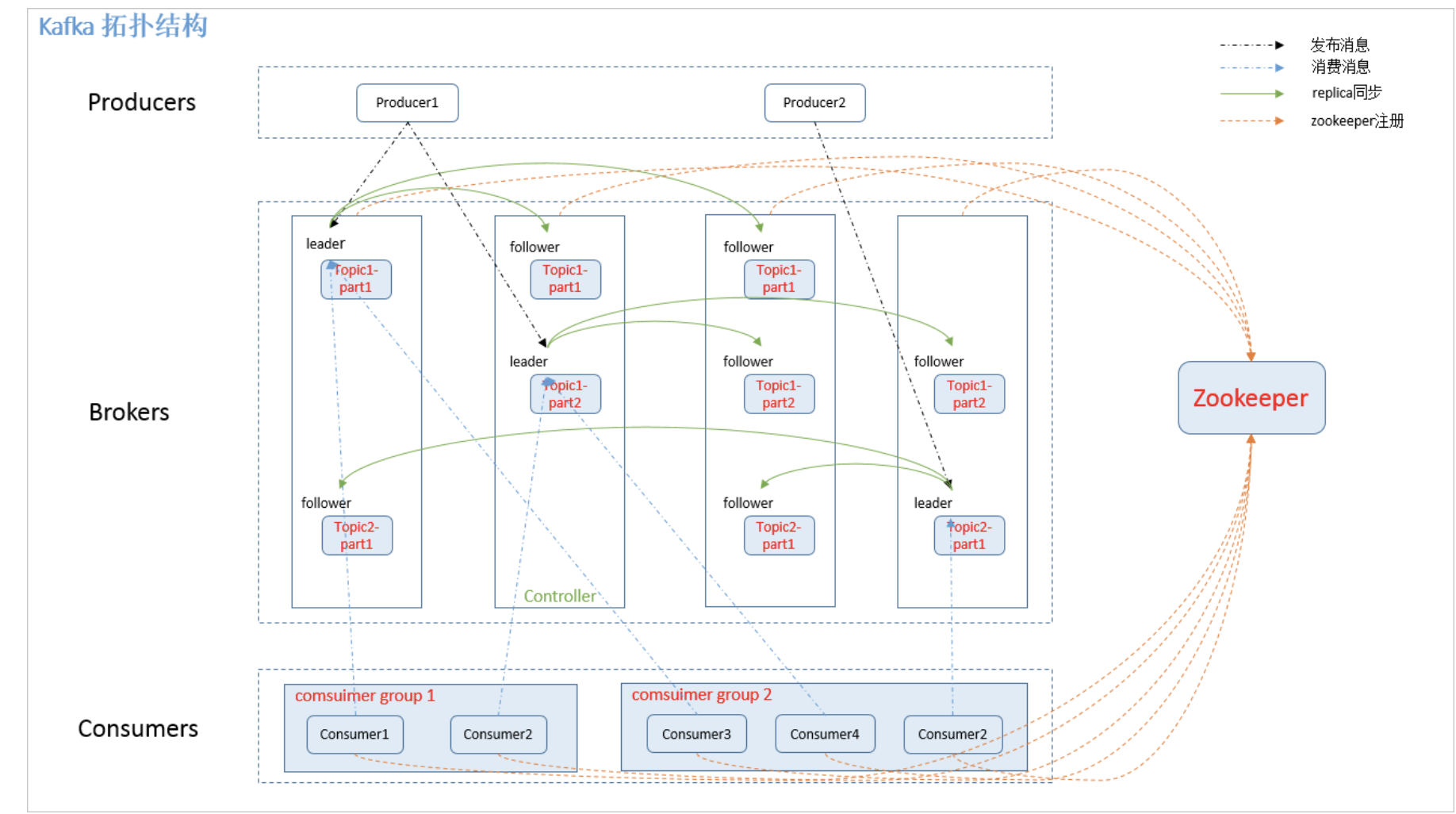
Kafka的核心概念
Topic 和 Log
让我们首先深入理解Kafka提出一个高层次的抽象概念 --Topic。
可以理解Topic是一个类别的名称,所有的message发送到Topic下面。对于每一个Topic,kafka集群按照如下方式维护一个分区(Partition,可以就理解为一个队列Queue)日志文件:
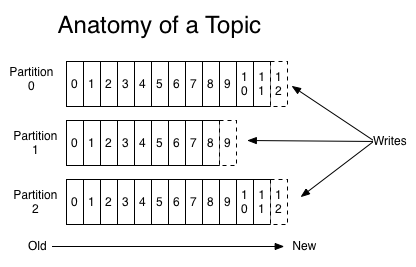
partition 是一个有序的 message 序列,这些 message 按顺序添加到一个叫做 commit log 的文件中。每个 partition 中的消息都有一个唯一的编号,称之为 offset,用来唯一标示某个分区中的message。
partition 支持消息位移读取,消息位移有消费者自身管理,比如下图:
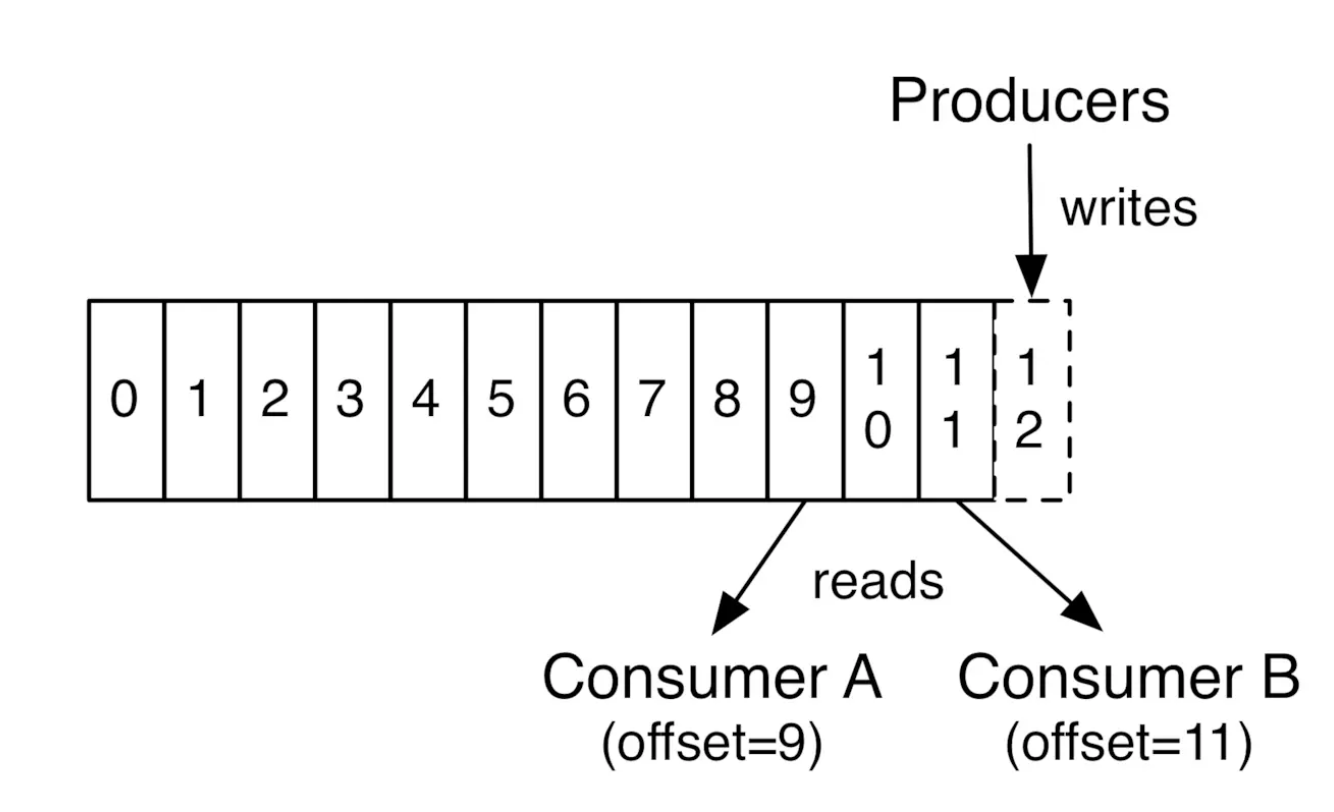
由上图可以看出,不同消费者对同一分区的消息读取互不干扰,消费者可以通过设置消息位移(offset)来控制自己想要获取的数据,比如:可以从头读取,最新数据读取,重读读取等功能。
Distribution
log 的 partitions 分布在 kafka 集群中不同的 broker 上,每个 broker 可以请求备份其他broker 上 partition 上的数据。kafka 集群支持配置一个 partition 备份的数量。针对每个partition,都有一个 broker 起到“leader”的作用,0个多个其他的 broker 作为“follwers”的作用。
leader 处理所有的针对这个 partition 的读写请求,而 followers 被动复制 leader 的结果。如果这个 leader 失效了,其中的一个 follower 将会自动的变成新的 leader。
每个 broker 都是自己所管理的 partition 的 leader,同时又是其他 broker 所管理 partitions 的 followers,kafka 通过这种方式来达到负载均衡。
Producers
生产者将消息发送到topic中去,同时负责选择将message发送到topic的哪一个partition中。通过round-robin做简单的负载均衡。也可以根据消息中的某一个关键字来进行区分。通常第二种方式使用的更多。
Consumers
传统的消息传递模式有2种:队列( queuing)和( publish-subscribe)。
在queuing模式中,多个consumer从服务器中读取数据,消息只会到达一个consumer。
在 publish-subscribe 模型中,消息会被广播给所有的consumer。
Kafka基于这2种模式提供了一种consumer的抽象概念:consumer group
每个consumer都要标记自己属于哪一个consumer group。发布到topic中的message中message会被传递到consumer group中的一个consumer 实例。consumer实例可以运行在不同的进程上,也可以在不同的物理机器上。
如果所有的consumer都位于同一个consumer group 下,这就类似于传统的queue模式,并在众多的consumer instance之间进行负载均衡。
如果所有的consumer都有着自己唯一的consumer group,这就类似于传统的publish-subscribe模型。
更一般的情况是,通常一个topic会有几个consumer group,每个consumer group都是一个逻辑上的订阅者( logical subscriber )。每个consumer group由多个consumer instance组成,从而达到可扩展和容灾的功能。这并没有什么特殊的地方,仅仅是将publish-subscribe模型中的运行在单个进程上的consumers中的consumer替换成一个consumer group。如下图所示:
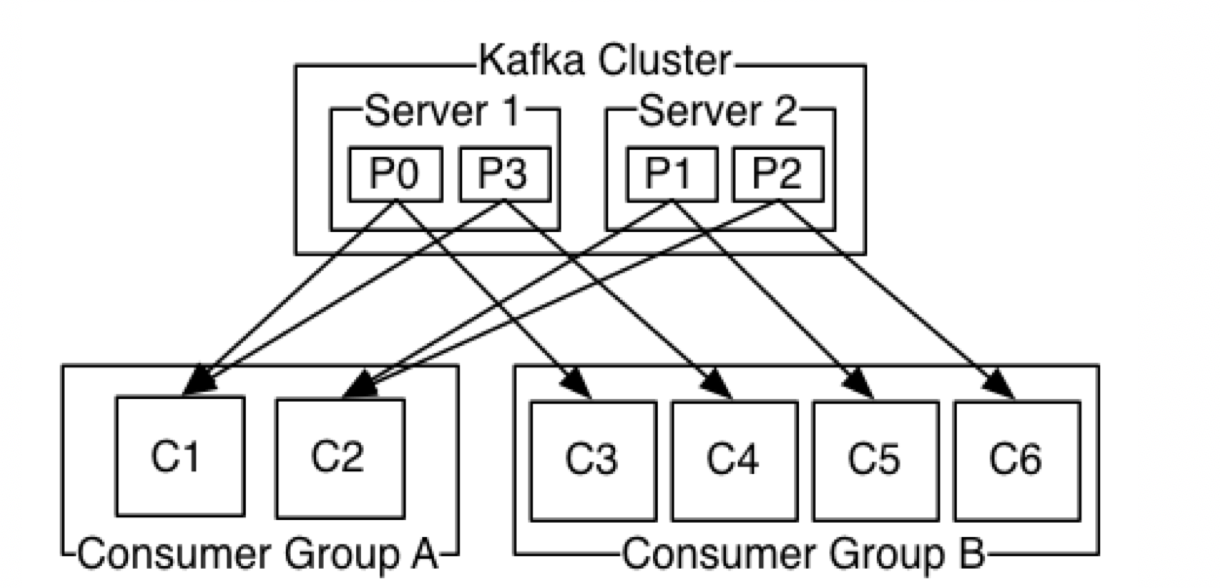
说明:由2个broker组成的kafka集群,总共有4个Parition(P0-P3)。这个集群由2个Consumer Group, A有2个 consumer instances ,而B有四个.
消费顺序
Kafka比传统的消息系统有着更强的顺序保证。在传统的情况下,服务器按照顺序保留消息到队列,如果有多个consumer来消费队列中的消息,服务器 会接受消息的顺序向外提供消息。
但是,尽管服务器是按照顺序提供消息,但是消息传递到每一个consumer是异步的,这可能会导致先消费的 consumer获取到消息时间可能比后消费的consumer获取到消息的时间长,导致不能保证顺序性。
这表明,当进行并行的消费的时候,消息在多个 consumer之间可能会失去顺序性。
消息系统通常会采取一种“ exclusive consumer”的概念,来确保同一时间内只有一个consumer能够从队列中进行消费,但是这实际上意味着在消息处理的过程中是不支持并行的。
Kafka在这方面做的更好。通过Topic中并行度的概念,即partition,Kafka可以同时提供顺序性保证和多个consumer同时消费时的负载均衡。实现的原理是通过将一个topic中的partition分配给一个consumer group中的不同consumer instance。
通过这种方式,我们可以保证一个partition在同一个时刻只有一个consumer instance在消息,从而保证顺序。
虽然一个topic中有多个partition,但是一个consumer group中同时也有多个consumer instance,通过合理的分配依然能够保证负载均衡。
需要注意的是,一个consumer group中的consumer instance的数量不能比一个Topic中的partition的数量多。如果多了,它将分配不上分区消息。
Kafka只在partition的范围内保证消息消费的局部顺序性,不能在同一个topic中的多个partition中保证总的消费顺序性。通常来说,这已经可以满足大部分应用的需求。
但是,如果的确有在总体上保证消费的顺序的需求的话,那么我们可以通过将topic的partition数量设置为1,将consumer group中的consumer instance数量也设置为1。
但是这样做,Kafka 的吞吐量就会下降。
kafka的安装与使用
安装前的环境准备
由于Kafka是用Scala语言开发的,运行在JVM上,因此在安装Kafka之前需要先安装JDK。
# yum install java-1.8.0-openjdk* -y
kafka依赖zookeeper,所以需要先安装zookeeper
# wget http://mirror.bit.edu.cn/apache/zookeeper/stable/zookeeper-3.4.12.tar.gz
# tar -zxvf zookeeper-3.4.12.tar.gz
# cd zookeeper-3.4.12
# cp conf/zoo_sample.cfg conf/zoo.cfg 启动zookeeper
# bin/zkServer.sh start
# bin/zkCli.sh
# ls / #查看zk的根目录相关节点
第一步:下载安装包
下载1.1.0 release版本,并解压:
# wget https://archive.apache.org/dist/kafka/1.1.0/kafka_2.11-1.1.0.tgz
# tar -xzf kafka_2.11-1.1.0.tgz
# cd kafka_2.11-1.1.0
第二步:启动服务
现在来启动kafka服务: 启动脚本语法:kafka-server-start.sh [-daemon] server.properties
可以看到,server.properties的配置路径是一个强制的参数,-daemon表示以后台进程运行,否则ssh客户端退出后,就会停止服务。(注意,在启动kafka时会使用linux主机名关联的ip地址,所以需要把主机名和linux的ip映射配置到本地host里,用vim /etc/hosts)
# bin/kafka-server-start.sh -daemon config/server.properties
我们进入zookeeper目录通过zookeeper客户端查看下zookeeper的目录树
# bin/zkCli.sh
# ls / #查看zk的根目录kafka相关节点
# ls /brokers/ids #查看kafka节点
第三步:创建主题
现在我们来创建一个名字为“test”的Topic,这个topic只有一个partition,并且备份因子也设置为1:
# bin/kafka-topics.sh --create --zookeeper localhost:2181 --replication-factor 1 --partitions 1 --topic test
现在我们可以通过以下命令来查看kafka中目前存在的topic
# bin/kafka-topics.sh --list --zookeeper localhost:2181
除了我们通过手工的方式创建Topic,我们可以配置broker,当producer发布一个消息某个指定的Topic,但是这个Topic并不存在时,就自动创建。
第四步:发送消息
kafka自带了一个producer命令客户端,可以从本地文件中读取内容,或者我们也可以以命令行中直接输入内容,并将这些内容以消息的形式发送到kafka集群中。在默认情况下,每一个行会被当做成一个独立的消息。
首先我们要运行发布消息的脚本,然后在命令中输入要发送的消息的内容:
# bin/kafka-console-producer.sh --broker-list localhost:9092 --topic test
>this is a msg
>this is a another msg
第五步:消费消息
对于consumer,kafka同样也携带了一个命令行客户端,会将获取到内容在命令中进行输出:
# bin/kafka-console-consumer.sh --zookeeper localhost:2181 --topic test --from-beginning #老版本
# bin/kafka-console-consumer.sh --bootstrap-server localhost:9092 --consumer-property group.id=testGroup --consumer-property client.id=consumer-1 --topic test #新版本
如果你是通过不同的终端窗口来运行以上的命令,你将会看到在producer终端输入的内容,很快就会在consumer的终端窗口上显示出来。
Kafka实操的一些命令
启动zk
bin/zkServer.sh start
启动kafka
bin/kafka-server-start.sh config/server.properties &
停止kafka 如果不管用 就是用kill -9
bin/kafka-server-stop.sh
1.创建主题
bin/kafka-topics.sh --create --zookeeper localhost:2181 --replication-factor 1 --partitions 1 --topic test
2.列出主题
bin/kafka-topics.sh --list --zookeeper localhost:2181
3.生产消息
bin/kafka-console-producer.sh --broker-list localhost:9092 -topic test
4.消费消息
bin/kafka-console-consumer.sh --zookeeper localhost:2181 -topic test --from-beginning
5.删除主题
1. 删除 kafka 主题
bin/kafka-topics.sh --delete --zookeeper localhost:2181 --topic sceniccenter-base-ticket
2. 在kafka 数据目录删除主题文件夹
3. 删除 zookeeper 上的 记录
1)登录zookeeper客户端:命令:./zkCli.sh
2)找到topic所在的目录:ls /brokers/topics
3)找到要删除的topic,执行命令:rmr /brokers/topics/【topic name】即可,此时topic被彻底删除。
另外被标记为 marked for deletion 的topic你可以在zookeeper客户端中通过命令获得: ls /admin/delete_topics/【topic name】
总结 彻底删除topic:
1、删除kafka存储目录(server.properties文件log.dirs配置,默认为"/tmp/kafka-logs")相关topic目录
2、如果配置了delete.topic.enable=true直接通过命令删除,如果命令删除不掉,直接通过 zookeeper-client 删除掉broker下的topic即可。
6.查看toplic 的分区等情况
bin/kafka-topics --describe --zookeeper hadoop1:2181 --topic wwcc1
Topic:wwcc1 PartitionCount:3 ReplicationFactor:3 Configs:
Topic: wwcc1 Partition: 0 Leader: 127 Replicas: 127,128,129 Isr: 127,128,129
Topic: wwcc1 Partition: 1 Leader: 128 Replicas: 128,129,127 Isr: 128,129,127
Topic: wwcc1 Partition: 2 Leader: 129 Replicas: 129,127,128 Isr: 129,127,128
一些学习地址
系统架构中为什么要用消息中间件-中华石杉:juejin.cn/post/684490…
官方地址:kafka.apache.org/
中文教程: orchome.com/kafka/index
消息中间件MQ详解:blog.51cto.com/leexide/210…
