

本套技术专栏是作者(秦凯新)平时工作的总结和升华,通过从真实商业环境抽取案例进行总结和分享,并给出商业应用的调优建议和集群环境容量规划等内容,请持续关注本套博客。QQ邮箱地址:1120746959@qq.com,如有任何学术交流,可随时联系。
1 Dokcer网络模型

2 Kubernetes网络模型
2.1 Flannel如何控制同一水平网络
-
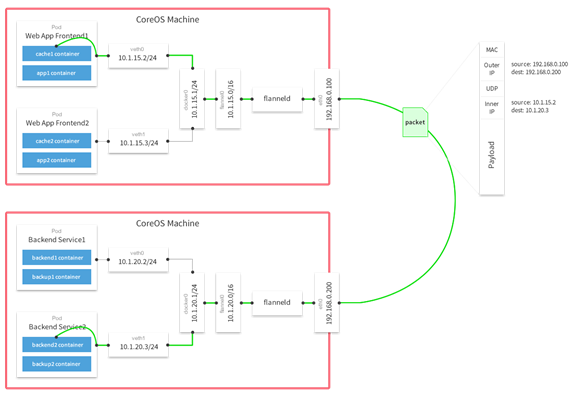
Flannel是如何做到为不同Node上的Pod分配IP且不产生冲突的?因为Flannel使用集中的etcd服务管理这些地址资源信息,它每次分配的地址段都在同一个公共区域获取,这样自然能随时协调,避免冲突了。在Flannel分配好地址段后,接下来的工作就转交给Docker完成了。Flannel通过修改Docker的启动参数将分配给它的地址段传递进去。
--bip=172.17.18.1/24通过这些操作,Flannel就控制了每个Node节点上的docker0地址段的地址,也能保障所有Pod的IP地址在同一水平的网络中且不产生冲突了
2.1.1 Flannel内核原理
- flannel利用Kubernetes API或者etcd用于存储整个集群的网络配置,其中最主要的功能为:设置整个集群的网络地址空间段。例如,设定整个集群内所有容器的IP都取自网段“10.1.0.0/16”。
- flannel在每个物理主机中运行flanneld作为agent,它会为所在主机从集群的网络地址空间中(网段“10.1.0.0/16”),获取一个小的网段subnet,本主机内所有容器的IP地址都将从中分配(如:分配主机1网段:10.1.1.0/24,主机2网段:10.1.2.0/24)
- flanneld再将本主机获取的subnet以及用于主机间通信的Public IP,同样通过kubernetes API或者etcd存储起来。
- flannel利用各种backend mechanism,例如udp,vxlan,hostgw等等,跨主机转发容器间的网络流量,完成容器间的跨主机通信。
2.1.2 Flannel使用VXLAN协议网络原理
-
每台物理主机都安装有flannel,假设k8s定义的flannel网络为10.0.0.0/16,各主机的flannel从这个网络申请一个子网。pod1所在的主机的flannel子网为10.0.13.1/24,pod2所在主机的flannel子网为10.0.14.1/24。
-
每台主机有cni0和flannel.1虚拟网卡。cni0为在同一主机pod共用的网桥,当kubelet创建容器时,将为此容器创建虚拟网卡vethxxx,并桥接到cni0网桥。flannel.1是一个tun虚拟网卡,接收不在同一主机的POD的数据,然后将收到的数据转发给flanneld进程。
2.1.3 Pod1与Pod2不在同一台主机网络传输过程数据包流向:
-
- pod1(10.0.14.15)向pod2(10.0.5.150)发送ping,查找pod1路由表,把数据包发送到cni0(10.0.14.1)
-
- cni0查找host1路由,把数据包转发到flannel.1
-
- flannel.1虚拟网卡再把数据包转发到它的驱动程序flannel
-
- flannel程序使用VXLAN协议封装这个数据包,向api-server查询目的IP所在的主机IP,称为host2(不清楚什么时候查询)
-
- flannel向查找到的host2 IP的UDP端口8472传输数据包
-
- host2的flannel收到数据包后,解包,然后转发给flannel.1虚拟网卡
-
- flannel.1虚拟网卡查找host2路由表,把数据包转发给cni0网桥,cni0网桥再把数据包转发给pod2
2.2 Calico 工作原理
-
Calico把每个操作系统的协议栈认为是一个路由器,然后把所有的容器认为是连在这个路由器上的网络终端,在路由器之间跑标准的路由协议——BGP的协议,然后让它们自己去学习这个网络拓扑该如何转发。所以Calico方案其实是一个纯三层的方案,也就是说让每台机器的协议栈的三层去确保两个容器,跨主机容器之间的三层连通性。
-
对于控制平面,它每个节点上会运行两个主要的程序,一个是Felix,它会监听ECTD中心的存储,从它获取事件,比如说用户在这台机器上加了一个IP,或者是分配了一个容器等。接着会在这台机器上创建出一个容器,并将其网卡、IP、MAC都设置好,然后在内核的路由表里面写一条,注明这个IP应该到这张网卡。绿色部分是一个标准的路由程序,它会从内核里面获取哪一些IP的路由发生了变化,然后通过标准BGP的路由协议扩散到整个其他的宿主机上,让外界都知道这个IP在这里,你们路由的时候得到这里来。
-
由于Calico是一种纯三层的实现,因此可以避免与二层方案相关的数据包封装的操作,中间没有任何的NAT,没有任何的overlay,所以它的转发效率可能是所有方案中最高的,因为它的包直接走原生TCP/IP的协议栈,它的隔离也因为这个栈而变得好做。因为TCP/IP的协议栈提供了一整套的防火墙的规则,所以它可以通过IPTABLES的规则达到比较复杂的隔离逻辑。
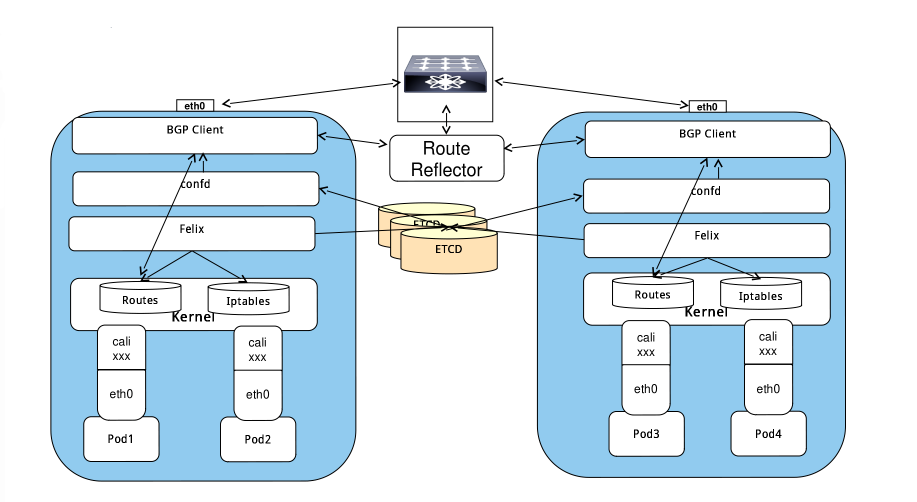
- 每个主机上都部署了calico/node作为虚拟路由器,并且可以通过calico将宿主机组织成任意的拓扑集群。当集群中的容器需要与外界通信时,就可以通过BGP协议将网关物理路由器加入到集群中,使外界可以直接访问容器IP,而不需要做任何NAT之类的复杂操作。
-
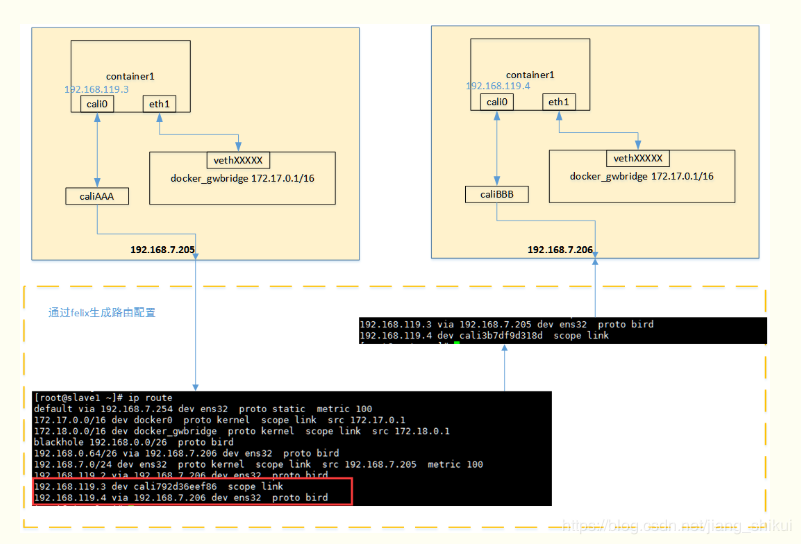
从上图可以看出,当容器创建时,calico为容器生成veth pair,一端作为容器网卡加入到容器的网络命名空间,并设置IP和掩码,一端直接暴露在宿主机上,并通过设置路由规则,将容器IP暴露到宿主机的通信路由上。于此同时,calico为每个主机分配了一段子网作为容器可分配的IP范围,这样就可以根据子网的CIDR为每个主机生成比较固定的路由规则。
当容器需要跨主机通信时,主要经过下面的简单步骤:
- 容器流量通过veth pair到达宿主机的网络命名空间上。
- 根据容器要访问的IP所在的子网CIDR和主机上的路由规则,找到下一跳要到达的宿主机IP。 流量到达下一跳的宿主机后,根据当前宿主机上的路由规则,直接到达对端容器的veth pair插在宿主机的一端,最终进入容器。
- 跨主机通信时,整个通信路径完全没有使用NAT或者UDP封装,性能上的损耗确实比较低。
-
calico目前只支持TCP、UDP、ICMP、ICMPv6协议,如果使用其他四层协议(例如NetBIOS协议),建议使用weave、原生overlay等其他overlay网络实现。 基于三层实现通信,在二层上没有任何加密包装,因此只能在私有的可靠网络上使用。 流量隔离基于iptables实现,并且从etcd中获取需要生成的隔离规则,有一些性能上的隐患
总结
Kubernetes网络解决方案为大规模集群部署提供化多为一的网络,本文结合作者在大规模IOT物联网大数据支撑平台的实践经验,进行总结,此文尚不完善,请持续关注凯新云技术社区
秦凯新
