

欢迎关注公众号:【爱编码】 如果有需要后台回复2019赠送1T的学习资料哦!!

哨兵模式
背景
当主服务器宕机后,需要手动把一台从服务器切换为主服务器,这就需要人工干预,费事费力,还会造成一段时间内服务不可用。这不是一种推荐的方式,更多时候,我们优先考虑哨兵模式。
定义
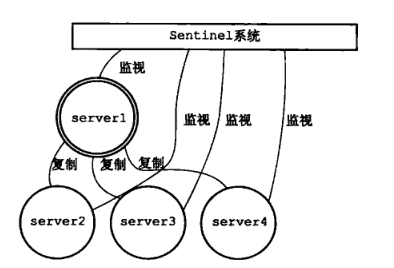
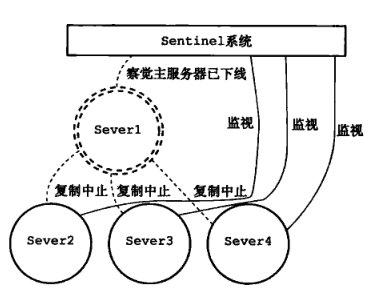
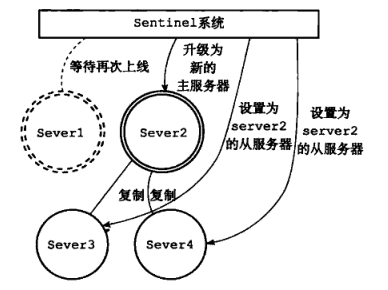
Sentinel(哨兵)是Redis 的高可用性解决方案:由一个或多个Sentinel 实例 组成的Sentinel 系统可以监视任意多个主服务器,以及这些主服务器属下的所有从服务器,并在被监视的主服务器进入下线状态时,自动将下线主服务器属下的某个从服务器升级为新的主服务器。
实战配置
1.首先配置Redis的主从服务器,修改redis.conf文件如下
# 使得Redis服务器可以跨网络访问
bind 0.0.0.0
# 设置密码
requirepass "123456"
# 指定主服务器,注意:有关slaveof的配置只是配置从服务器,主服务器不需要配置
slaveof 192.168.11.128 6379
# 主服务器密码,注意:有关slaveof的配置只是配置从服务器,主服务器不需要配置
masterauth 123456
上述内容主要是配置Redis服务器,从服务器比主服务器多一个slaveof的配置和密码。
- 配置3个哨兵,每个哨兵的配置都是一样的。在Redis安装目录下有一个sentinel.conf文件,copy一份进行修改
# 禁止保护模式
protected-mode no
# 配置监听的主服务器,这里sentinel monitor代表监控,mymaster代表服务器的名称,可以自定义,192.168.11.128代表监控的主服务器,6379代表端口,2代表只有两个或两个以上的哨兵认为主服务器不可用的时候,才会进行failover操作。
sentinel monitor mymaster 192.168.11.128 6379 2
# sentinel author-pass定义服务的密码,mymaster是服务名称,123456是Redis服务器密码
# sentinel auth-pass <master-name> <password>
sentinel auth-pass mymaster 123456
- 有了上述的修改,我们可以进入Redis的安装目录的src目录,通过下面的命令启动服务器和哨兵
# 启动Redis服务器进程
./redis-server ../redis.conf
# 启动哨兵进程
./redis-sentinel ../sentinel.conf
注意启动的顺序。首先是主机(192.168.11.128)的Redis服务进程,然后启动从机的服务进程,最后启动3个哨兵的服务进程。
参考文章: www.jianshu.com/p/06ab9daf9…
集群
搭建集群工作需要以下三个步骤:
1.准备节点
Redis集群一般由多个节点组成,节点数量至少为6个才能保证组成完整高可用的集群。每个节点需要开启配置cluster-enabled yes,让Redis运行在集群模式下。建议为集群内所有节点统一目录,一般划分三个目录:conf、data、log,分别存放配置、数据和日志相关文件。把6个节点配置统一放在conf目录下
#节点端口
port 6379
# 开启集群模式
cluster-enabled yes
# 节点超时时间,单位毫秒
cluster-node-timeout 15000
# 集群内部配置文件
cluster-config-file "nodes-6379.conf"
其他配置和单机模式一致即可,配置文件命名规则redis-{port}.conf,准备好配置后启动所有节点,命令如下
redis-server conf/redis-6379.conf
redis-server conf/redis-6380.conf
redis-server conf/redis-6381.conf
redis-server conf/redis-6382.conf
redis-server conf/redis-6383.conf
redis-server conf/redis-6384.conf
2.节点握手
节点握手是指一批运行在集群模式下的节点通过Gossip协议彼此通信,达到感知对方的过程。节点握手是集群彼此通信的第一步,由客户端发起命令:cluster meet{ip}{port}
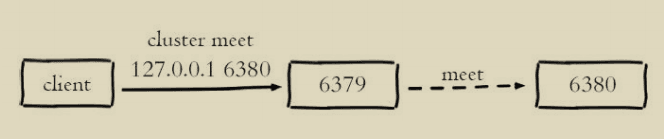
图中执行的命令是:cluster meet127.0.0.16380让节点6379和6380节点进 行握手通信。cluster meet命令是一个异步命令,执行之后立刻返回。内部发起与目标节点进行握手通信。
127.0.0.1:6379>cluster meet 127.0.0.1 6381
127.0.0.1:6379>cluster meet 127.0.0.1 6382
127.0.0.1:6379>cluster meet 127.0.0.1 6383
127.0.0.1:6379>cluster meet 127.0.0.1 6384
最后执行cluster nodes命令确认6个节点都彼此感知并组成集群
127.0.0.1:6379> cluster nodes
4fa7eac4080f0b667ffeab9b87841da49b84a6e4 127.0.0.1:6384 master - 0 1468073975551
5 connected
cfb28ef1deee4e0fa78da86abe5d24566744411e 127.0.0.1:6379 myself,master - 0 0 0 connected
be9485a6a729fc98c5151374bc30277e89a461d8 127.0.0.1:6383 master - 0 1468073978579
4 connected
40622f9e7adc8ebd77fca0de9edfe691cb8a74fb 127.0.0.1:6382 master - 0 1468073980598
3 connected
8e41673d59c9568aa9d29fb174ce733345b3e8f1 127.0.0.1:6380 master - 0 1468073974541
1 connected
40b8d09d44294d2e23c7c768efc8fcd153446746 127.0.0.1:6381 master - 0 1468073979589
2 connected
节点建立握手之后集群还不能正常工作,这时集群处于下线状态,所有的数据读写都被禁止。
3.分配槽
Redis集群把所有的数据映射到16384个槽中。每个key会映射为一个固定的槽,只有当节点分配了槽,才能响应和这些槽关联的键命令。通过cluster addslots命令为节点分配槽。这里利用bash特性批量设置槽(slots)
redis-cli -h 127.0.0.1 -p 6379 cluster addslots {0...5461}
redis-cli -h 127.0.0.1 -p 6380 cluster addslots {5462...10922}
redis-cli -h 127.0.0.1 -p 6381 cluster addslots {10923...16383}
关于集群伸缩、故障转移、节点通信等知识。 可参考《Redis开发与运维》
缓存设计
穿透优化
缓存穿透是指查询一个根本不存在的数据,缓存层和存储层都不会命中,通常出于容错的考虑,如果从存储层查不到数据则不写入缓存层。 整个过程分为如下3步
1.缓存层不命中。 2.存储层不命中,不将空结果写回缓存。 3.返回空结果
解决办法
1.缓存空对象 存储层不命中后,仍然将空对象保留到缓存层中,之后再访问这个数据将会从缓存中获取,这样就保护了后端数据源。
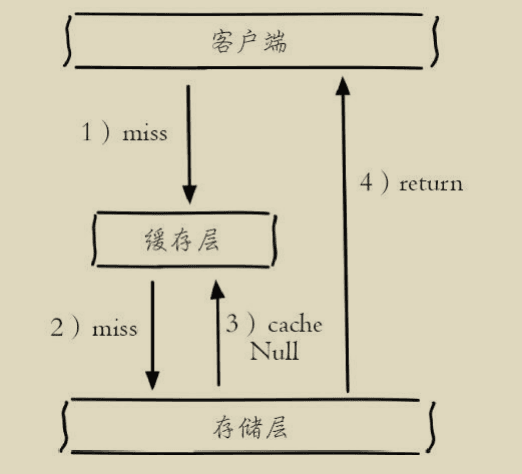
缓存空对象会有两个问题: 第一,空值做了缓存,意味着缓存层中存了更多的键,需要更多的内存空间(如果是攻击,问题更严重),比较有效的方法是针对这类数据设置一个较短的过期时间,让其自动剔除。
第二,缓存层和存储层的数据会有一段时间窗口的不一致,可能会对业务有一定影响。例如过期时间设置为5分钟,如果此时存储层添加了这个数据,那此段时间就会出现缓存层和存储层数据的不一致,此时可以利用消息系统或者其他方式清除掉缓存层中的空对象。
类似代码实现如下:
String get(String key) {
// 从缓存中获取数据
String cacheValue = cache.get(key);
// 缓存为空
if (StringUtils.isBlank(cacheValue)) {
// 从存储中获取
String storageValue = storage.get(key);
cache.set(key, storageValue);
// 如果存储数据为空,需要设置一个过期时间(300秒)
if (storageValue == null) {
cache.expire(key, 60 * 5);
}
return storageValue;
} else {
// 缓存非空
return cacheValue;
}
}
2.布隆过滤器拦截
bloomfilter就类似于一个hash set,用于快速判某个元素是否存在于集合中,其典型的应用场景就是快速判断一个key是否存在于某容器,不存在就直接返回。布隆过滤器的关键就在于hash算法和容器大小,下面先来简单的实现下看看效果,我这里用guava实现的布隆过滤器:
<dependencies>
<dependency>
<groupId>com.google.guava</groupId>
<artifactId>guava</artifactId>
<version>23.0</version>
</dependency>
</dependencies>
public class BloomFilterTest {
private static final int capacity = 1000000;
private static final int key = 999998;
private static BloomFilter<Integer> bloomFilter = BloomFilter.create(Funnels.integerFunnel(), capacity);
static {
for (int i = 0; i < capacity; i++) {
bloomFilter.put(i);
}
}
public static void main(String[] args) {
/*返回计算机最精确的时间,单位微妙*/
long start = System.nanoTime();
if (bloomFilter.mightContain(key)) {
System.out.println("成功过滤到" + key);
}
long end = System.nanoTime();
System.out.println("布隆过滤器消耗时间:" + (end - start));
int sum = 0;
for (int i = capacity + 20000; i < capacity + 30000; i++) {
if (bloomFilter.mightContain(i)) {
sum = sum + 1;
}
}
System.out.println("错判率为:" + sum);
}
}
成功过滤到999998
布隆过滤器消耗时间:215518
错判率为:318
可以看到,100w个数据中只消耗了约0.2毫秒就匹配到了key,速度足够快。然后模拟了1w个不存在于布隆过滤器中的key,匹配错误率为318/10000,也就是说,出错率大概为3%,跟踪下BloomFilter的源码发现默认的容错率就是0.03:
public String getByKey(String key) {
// 通过key获取value
String value = redisService.get(key);
if (StringUtil.isEmpty(value)) {
if (bloomFilter.mightContain(key)) {
value = userService.getById(key);
redisService.set(key, value);
return value;
} else {
return null;
}
}
return value;
}
更多知识可参考文章: blog.csdn.net/fanrenxiang…
雪崩优化
由于缓存层承载着大量请求,有效地保护了存储层,但是如果缓存层由于某些原因不能提供服务,于是所有的请求都会达到存储层,存储层的调用量会暴增,造成存储层也会级联宕机的情况。缓存雪崩的英文原意是stampeding herd(奔逃的野牛),指的是缓存层宕掉后,流量会像奔逃的野牛一样,打向后端存储。
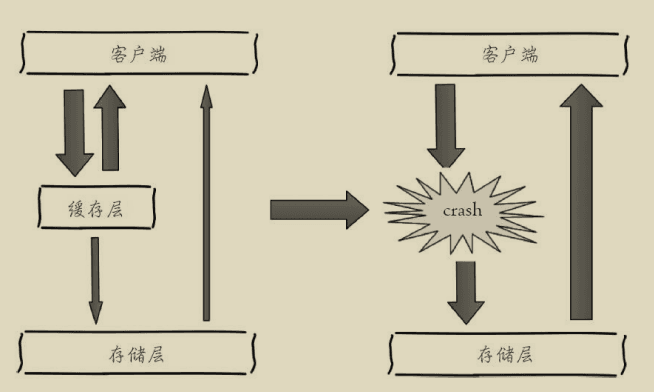
预防和解决缓存雪崩问题,可以从以下三个方面进行着手
1.保证缓存层服务高可用性。 和飞机都有多个引擎一样,如果缓存层设计成高可用的,即使个别节点、个别机器、甚至是机房宕掉,依然可以提供服务,例如前面介绍过的Redis Sentinel和Redis Cluster都实现了高可用
2.依赖隔离组件为后端限流并降级。
无论是缓存层还是存储层都会有出错的概率,可以将它们视同为资源。作为并发量较大的系统,假如有一个资源不可用,可能会造成线程全部阻塞(hang)在这个资源上,造成整个系统不可用。降级机制在高并发系统中是非常普遍的:比如推荐服务中,如果个性化推荐服务不可用,可以降级补充热点数据,不至于造成前端页面是开天窗。 推荐一个Java依赖隔离工具Hystrix
3. 提前演练。 在项目上线前,演练缓存层宕掉后,应用以及后端的负载情况以及可能出现的问题,在此基础上做一些预案设定。
总结
Redis的学习到此为止。以后会总结一下Redis的面试篇。 接下来会学习netty相关知识,敬请期待。
最后
如果对 Java、大数据感兴趣请长按二维码关注一波,我会努力带给你们价值。觉得对你哪怕有一丁点帮助的请帮忙点个赞或者转发哦。 关注公众号**【爱编码】,回复2019**有相关资料哦。

