

Kafka是什么
Kafka是一个分布式流处理平台,一般用作分布式消息中间件
架构
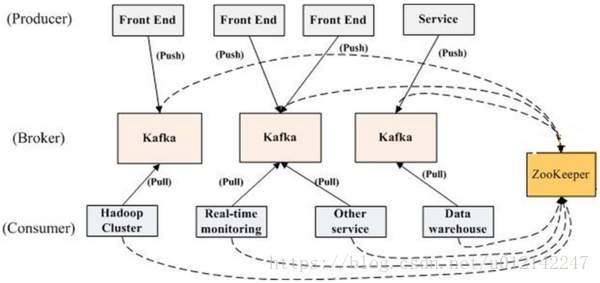
以消息系统的角度来看,Kafka是基于发布-订阅模型,Producer主动发起push,将一条消息推到Broker(Kafka服务端的一个节点),Consumer主动通过pull操作去Broker拿消息,另外还有zookeeper作为一个协调系统去协调建立连接,记录offset等分布式的操作。题外话:Kafka已经在慢慢地把很多操作由zk移到自己的broker上
Topic和Partition
Kafka里以Topic作为发布,订阅的类别,类似数据库的表,一个topic可以被多个producer,consumer发布,订阅。每一个topic都有自己的partition划分,一条消息从发布到消费只会经过一个partition,所以消息在partition内是有序的,这个有序还需要其他机制的支持,后面会说到
另外,Kafka也可以作为存储系统,因为Kafka跟其他的消息队列不一样,Kafka的消息是持久化到磁盘的,并且不是消费完就删除。事实上往broker发布一条消息,broker仅仅持久化消息,等到consumer主动发起pull,告诉broker一个offset,broker把offset对应的消息返回给consumer。因此consumer是可以通过offset回溯消费。Kafka的性能在数据大小方面实际上是恒定的,所以可以长时间存储数据。当然消息在磁盘中会越来越多,可以设置只保留多久的消息
生产者
producer比较好理解,和broker建立连接后,producer自己指定partition,把消息推给broker就好了,并没有什么复杂的概念。
消费者和消费者组
上面提到,一个topic可以有多个consumer,我们的分布式系统都是有多台实例,如果都订阅了这个topic,岂不是重复消费了?因此Kafka有一个消费组的概念,订阅的时候是以消费组为单位,一个partition只能被同个消费组下的一个消费者实例消费,但是一个消费者实例可以消费多个partition,这样保证了在同一个消费组下不会重复消费
消费者实例可以是不同机器也可以是不同的进程,消费者建立Kafka连接时通过指定消费组名称标记自己。一般我们就把一个分布式服务作为消费组,服务下的机器作为消费者实例
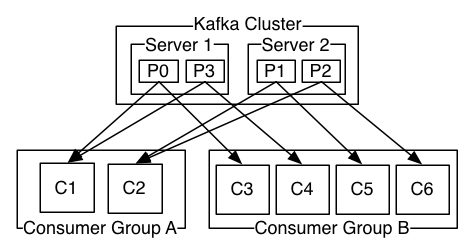
例如上图有4个partition,消费组B有4个消费者实例,Kafka会负载均衡给每个实例指定一个分区。如果B组有五个实例,第五个实例是不会消费的,直到前四个实例有一个挂了。所以工作的消费者的实例数最多跟分区数一样,所以设置分区数会影响我们Kafka的消费速率
