

首发于 Jenkins 中文社区

在本文中,我想讨论一种在云环境中为 Kubernetes 工作负载实现自动化端到端 CI/CD 的方法。 这里可能有其它解决方案,而像 AWS、Microsoft Azure 和 GCP 这样的云提供商也提供了自己的一套框架,以实现与 Kubernetes 相同的目标。
它的部署模型的核心是 Rancher,Rancher 负责为托管在不同云环境和裸机环境中的多个 Kubernetes 集群提供集中管理与运营的能力。 根据应用程序和业务需要,这里提到的工具可以替换为自己选择的工具。
在详细介绍之前,这里有张部署模型的快照:
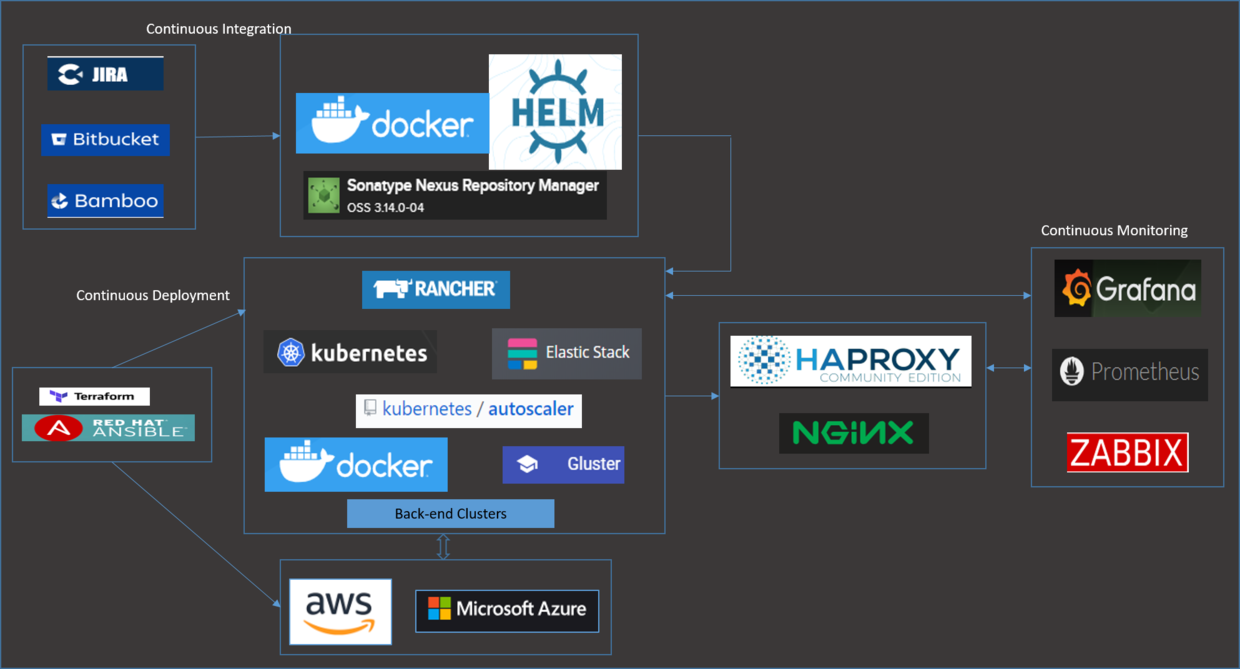
持续集成组件
我们使用 JIRA、BitBucket、Bamboo 和 Nexus 作为自动化持续集成组件。 需求和用户故事来自 JIRA ; 开发人员将他们的代码放进 BitBucket ; 代码被代码评审工具和静态分析工具构建与集成,Bamboo 生成的 Docker 镜像被推送到 Nexus。 这些镜像会经过特定的容器安全检查。
当你有许多微服务/应用程序需要构建时,那么处理 Kubernetes 集群工作负载的部署、升级和回滚可能会复杂。 版本控制是我们需要考虑的另一个挑战。 Helm 有助于克服这些大多数挑战,并使部署变得简单。
如果你想知道你是否需要有一个 chart 将所有 deployments 包含在其中, 或者允许每个应用程序和微服务都有一个单独的 chart , 那么我们希望将这些 charts 放到特定的应用程序或微服务的仓库中, 这样我们就不需要有单独的仓库来维护 Helm 制品。 这就省去了为实际的代码和 Helm 模板维护两个独立仓库的工作。 开发人员可以对任何应用程序代码更改所需的模板更改有更多的控制权。
Nexus 作为 Docker 镜像和 Helm chart(使用的是 Helm Nexus 插件)的仓库。 每次成功构建应用程序后,镜像和 chart 都是可用的并被推送到 Nexus 。
持续部署组件
为了实现与云无关的准备,我们选择了 Terraform ,因为它易于学习并易于部署。 我们发现对于准备后的配置管理/维护活动, Terraform 并不是非常有用,所以我们还放置了一些 Ansible 脚本。 我们也曾考虑 Ansible 用于准备,但是使用 Terraform 可以让我们更好地控制启动实例, 这些实例可以作为 Rancher Server/节点,并且可以被自动的添加到自动伸缩组中。 我们使用启动脚本功能实现了这一点。
我们认为可以将为 AWS 编写的大多数 Terraform 脚本重用到 Azure 中,但事实并非如此。 我们必须做出相当大的改变。
我们部署了一个运行在三个不同实例上的高可用的 Rancher Server ,前面有一个 NGINX Server 来为这三个实例做负载均衡。 部署是使用 Terraform 和启动脚本完成的。 脚本使用 RKE ( Rancher Kubenetes 引擎)和 Rancher API 调用来启动集群(高可用的 Rancher Server )。
Rancher 提供了各种选项来在不同的云提供商上添加 Kubernetes 集群。 您可以从选项中进行选择,使用托管的 Kubernetes 提供商,或者使用基础设施提供商的节点或自定义节点。 在这个场景中,我们选择使用 AWS 和 Azure 上的自定义节点,而不是托管的 Kubernetes 提供商。 这帮助我们向自动伸缩组添加一组工作节点,并使用集群自动伸缩器进行节点伸缩。
所有这些都是通过启动脚本和 Rancher API 调用自动完成的,因此任何通过 ASG (和自动伸缩器)添加的新节点都会自动注册为一个 Rancher/Kubernetes 节点。 通过启动脚本自动执行的一些活动包括:
- 安装和配置所需的 Docker 版本
- 在所有实例上安装和配置 Zabbix 代理(稍后将在监控中使用)
- 安装所需的 GlusterFS 客户端组件
- 安装所需的 kubectl 客户端
- 后端数据库集群所需的任何其他自定义配置
- 自动挂载额外的 EBS 卷和 GlusterFS 卷
- 为 Rancher 代理/Kubernetes 节点运行 Docker 容器并附加特定的角色( etcd/controlplane/worker )
- 检查以确保 Rancher 代理可用、启动和运行。
GlusterFS 被考虑可以处理 EBS 和 Azure 中不可用的 ReadWriteMany 磁盘卷类型。 这对于我们部署的许多应用程序都是必需的。
一个 ELK stack ( ElasticSearch、Logstash 和 Kibana )使用 Helm charts 部署在 Kubernetes 上, 并被配置为通过 logstash 推送容器日志、审计和其他自定义日志。
HAProxy 和 NGINX 被用于两个不同的目的。 NGINX 是在 Rancher Server HA 设置期间所提供的默认 ingress controller 。 这用于三个 Rancher Server 的负载均衡。 我们在 Kubernetes 集群上部署了一个 HAProxy Ingress Controller, 这样我们就可以通过这些特定的节点(其 IPs 映射到特定的 FQDNs)暴露应用程序的 end points 。 HAProxy ingress controller 被部署为 daemonset ,因此对于任何额外的负载,节点的数量会基于自动伸缩组和自动伸缩器自动增加。
持续监控组件
我们部署了 Prometheus、Grafana 和 Alertmanager 套件,用于容量规划以及监控 Rancher/Kubernetes 集群的状态。 这再次通过 Rancher Helm Chart Provisioner 部署。 我们也可以通过常规的/稳定的 Helm charts 来部署它。 它确实有助于我们监控和收集开发环境中诸如 CPU、内存利用率和 IO 操作之类的指标,并据此为 staging 环境和生产环境进行容量规划。
我们还在集群上部署了 Zabbix Server,它用于为部署的所有节点监控各种操作系统级别的和应用程序特定的指标和警告。 这包括任何后端数据库集群节点、Kubernetes 节点、Rancher servers、文件服务器或通过 Terraform 提供的任何其他服务器。 Zabbix Server 被配置为节点/代理自动注册,以便通过自动缩放组或自动缩放器添加到集群中的任何新节点都可用于监控。
结论
这是我们为 Kubernetes 工作负载构建完整的 CI/CD 工具链所遵循的方法之一。 这个模型帮助我们自动化所有的三个环境的准备。 通过 Rancher ,我们能够提供一个开发环境,每个开发人员都可以使用这个项目概念。 每个开发人员都有一个节点和一个项目,它由 RBAC 控制,这样他们就可以部署和测试他们自己的更改。 没有人可以看到项目/节点的详细信息,也不会妨碍其他开发人员部署的 Kubernetes 工作负载。 由于节点自动注册到 Rancher Server,系统重新启动不会影响节点的可用性。 即使在最坏的情况下,如果节点丢失,也很容易在几分钟内打开一个新节点。 应用程序可以使用 Helm charts 进行部署,也可以使用 Rancher 提供的内置的 Helm charts 进行部署。
这些是我们部署的来管理整个环境的一些高级组件。 我们考虑的其他方面是高可用性集群环境,用于 Rancher servers、Kubernetes 集群、Gluster 文件服务器集群或任何其他后端集群。 在提出此方法时,需要考虑生产级环境所需的更改和更新。 还考虑了其他方面,例如对集群实例的安全访问、升级、备份和恢复,以及根据行业标准提出的分层体系结构建议。
希望本文为您提供一些参考,当您计划为多个云提供商提供生产级环境准备时,可以考虑这些参考。
译者:王冬辉

