

最近项目中的一个关键服务,由于业务的特殊性引发了一系列GC问题。经过不短时间的追踪和尝试,最终完美解决。以下记录一下过程及收获。
背景简介
该服务是为了提供商品排序功能,业务要求如下:
- 商品是分国家的,每个国家的商品不同.
- 每个商品有主键字段
goodsId,且有一个一维特征矩阵,保存为一个长度128的一维float数组。 - 排序时,提供查询条件的特征矩阵
A,和一批备选商品的goodsId(最多5000个),然后拿输入的矩阵A和所有备选商品的特征矩阵相乘,得到每个商品的匹配度分值,返回。 - 商品集合需要定时更新,且每个国家的商品集合单独更新。
这里可以看到此服务的特殊性了吧:每个请求最大需要查到 5000 个float[128]数组!这个数据怎么存还真是个问题。
我们采用的方案是在内存中建立一个大map,结构是一个 Map<String, Map<String, float[128]>。外层保存国家到商品集合的映射,内部的Map则是goodsId到其特征矩阵的映射。我们计算了一下数据量,粗略的估计是单个内层Map所占的内存约 350M,整个外部大Map的内存要占到约 2GB.
为确保理解,map的简单图示如下:
nation1:
goodsId1: 特征矩阵1
goodsId2: 特征矩阵2
...
nation2:
goodsId1: 特征矩阵1
goodsId2: 特征矩阵2
...
看官到这里一定会问,为什么我们不用Redis等集中式缓存,而是直接把数据放到内存中?
嗯,写这篇文章之前,我做了一轮压测,发现Redis的性能真的没那么强。比如官方一直宣称的单实例OPS 100000+,确实能达到,但这个数字意味着什么呢?意味着一个get请求需要0.01ms,那一个1000大小的MGET就需要10ms!这还是没有网络延时的情况下。我在本地实测(server和client分别在本地物理机和虚拟机)的MGET 5000 个key,延时在40 - 60ms之间 (本场景下value还不是太大,1kB左右,还没有造成性能的显著下降)。这里贴一篇文章:Redis 的性能幻想与残酷现实
还有个思路是使用Redis加上本地缓存。但是本场景中上百万条数据,又没有热点,本地缓存也很难有效。
言归正传。有了这个map,服务的主接口就好办了:
- 输入:接受一个
nation参数,一组goodsId,和一个查询条件的特征矩阵A,也是float[128] - 根据
nation和goodsId查到商品特征矩阵,然后和A相乘,得到该商品的匹配度分值。
第一版效果: 正常QPS下,平均延时10ms以内。
背景已交代完。下面噩梦要开始了~
出现GC问题
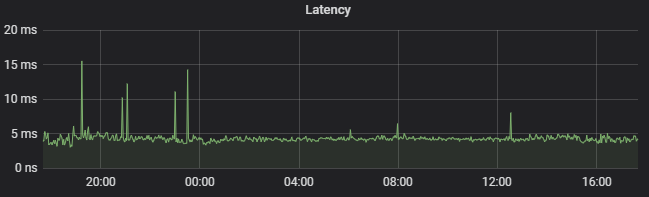
上线后一切都很完美。然而运行了一段时间后,上游服务开始不定期地出现超时甚至熔断,每次持续时间很短。一番调查后我们注意到问题发生时这个服务的TP99指标会有尖峰,如下图所示:
响应时间有时会飙升到接近1秒!在日志没什么异常的情况下只能怀疑是GC在作祟了,于是找来GC日志一探究竟。
观察GC日志
以下为JVM 参数取 -Xmx4g -Xmx4g 时的一段gc日志, Java版本:OpenJDK 1.8.0_212
{Heap before GC invocations=393 (full 5):
PSYoungGen total 1191936K, used 191168K [0x000000076ab00000, 0x00000007c0000000, 0x00000007c0000000)
eden space 986112K, 0% used [0x000000076ab00000,0x000000076ab00000,0x00000007a6e00000)
from space 205824K, 92% used [0x00000007b3700000,0x00000007bf1b0000,0x00000007c0000000)
to space 205824K, 0% used [0x00000007a6e00000,0x00000007a6e00000,0x00000007b3700000)
ParOldGen total 2796544K, used 2791929K [0x00000006c0000000, 0x000000076ab00000, 0x000000076ab00000)
object space 2796544K, 99% used [0x00000006c0000000,0x000000076a67e750,0x000000076ab00000)
Metaspace used 70873K, capacity 73514K, committed 73600K, reserved 1114112K
class space used 8549K, capacity 9083K, committed 9088K, reserved 1048576K
4542.168: [Full GC (Ergonomics) [PSYoungGen: 191168K->167781K(1191936K)] [ParOldGen: 2791929K->2796093K(2796544K)] 2983097K->2963875K(3988480K), [Metaspace: 70873K->70638K(1114112K)], 2.9853595 secs] [Times: user=11.28 sys=0.00, real=2.99 secs]
Heap after GC invocations=393 (full 5):
PSYoungGen total 1191936K, used 167781K [0x000000076ab00000, 0x00000007c0000000, 0x00000007c0000000)
eden space 986112K, 0% used [0x000000076ab00000,0x000000076ab00000,0x00000007a6e00000)
from space 205824K, 81% used [0x00000007b3700000,0x00000007bdad95e8,0x00000007c0000000)
to space 205824K, 0% used [0x00000007a6e00000,0x00000007a6e00000,0x00000007b3700000)
ParOldGen total 2796544K, used 2796093K [0x00000006c0000000, 0x000000076ab00000, 0x000000076ab00000)
object space 2796544K, 99% used [0x00000006c0000000,0x000000076aa8f6d8,0x000000076ab00000)
Metaspace used 70638K, capacity 73140K, committed 73600K, reserved 1114112K
class space used 8514K, capacity 9016K, committed 9088K, reserved 1048576K
}
从日志中可以得到的一些信息:
- JDK 8 若不指定gc方式,默认采用的是Parallel Scavenge + Parallel Old的组合。竟然不是CMS。
- 本次Full GC的原因是老年代满了,STW停顿了3秒钟……
调整gc策略
既然出现了GC问题,那必须要调整一波了。下面是我做过的一些尝试:
- 垃圾收集器换成CMS
- 既然老年代空间不够,那就多给它空间呗!将整个堆调大,把老年代内存调大。
以下是实验结果和结论:
- 换成CMS也没什么卵用,反而更差了。猜测原因是CMS比较依赖CPU内核数量,而我们在docker环境中,将核数限制的很低,导致CMS的并行处理提高不明显。甚至有时候由于老年代内存吃紧,还会出现
Concurrent Mode Failure,进入线性Full GC兜底,消耗时间更长。 - 堆内存增大后,发生普通GC和Full GC的次数减少了,但单次的GC却更慢了。无法解决问题。
再附上一起CMS车祸现场:
[GC (CMS Initial Mark) [1 CMS-initial-mark: 4793583K(5472256K)] 4886953K(6209536K), 0.0075637 secs] [Times: user=0.01 sys=0.00, real=0.00 secs]
[CMS-concurrent-mark-start]
03:05:50.594 INFO [XNIO-2 task-8] c.shein.srchvecsort.filter.LogFilter ---- GET /prometheus?null took 3ms and returned 200
{Heap before GC invocations=240 (full 7):
par new generation total 737280K, used 737280K [0x0000000640000000, 0x0000000672000000, 0x0000000672000000)
eden space 655360K, 100% used [0x0000000640000000, 0x0000000668000000, 0x0000000668000000)
from space 81920K, 100% used [0x0000000668000000, 0x000000066d000000, 0x000000066d000000)
to space 81920K, 0% used [0x000000066d000000, 0x000000066d000000, 0x0000000672000000)
concurrent mark-sweep generation total 5472256K, used 4793583K [0x0000000672000000, 0x00000007c0000000, 0x00000007c0000000)
Metaspace used 66901K, capacity 69393K, committed 69556K, reserved 1110016K
class space used 8346K, capacity 8805K, committed 8884K, reserved 1048576K
[GC (Allocation Failure) [ParNew: 737280K->737280K(737280K), 0.0000229 secs][CMS[CMS-concurrent-mark: 1.044/1.045 secs] [Times: user=1.36 sys=0.05, real=1.05 secs]
(concurrent mode failure): 4793583K->3662044K(5472256K), 3.8206326 secs] 5530863K->3662044K(6209536K), [Metaspace: 66901K->66901K(1110016K)], 3.8207144 secs] [Times: user=3.82 sys=0.00, real=3.82 secs]
Heap after GC invocations=241 (full 8):
par new generation total 737280K, used 0K [0x0000000640000000, 0x0000000672000000, 0x0000000672000000)
eden space 655360K, 0% used [0x0000000640000000, 0x0000000640000000, 0x0000000668000000)
from space 81920K, 0% used [0x0000000668000000, 0x0000000668000000, 0x000000066d000000)
to space 81920K, 0% used [0x000000066d000000, 0x000000066d000000, 0x0000000672000000)
concurrent mark-sweep generation total 5472256K, used 3662044K [0x0000000672000000, 0x00000007c0000000, 0x00000007c0000000)
Metaspace used 66901K, capacity 69393K, committed 69556K, reserved 1110016K
class space used 8346K, capacity 8805K, committed 8884K, reserved 1048576K
}
这里顺便提一下过程中遇到的一些坑,主要是docker/k8s环境的限制,有些尚未解决。后面有机会再具体讲讲吧。
- jstat 由于Java 进程为0,无法指定进程。
- OOM crash dump似乎不好收集。
- VisualVM不好连接。
如何避免GC问题
思考:问题在哪里?
此次的GC问题其实原因很明显:由于业务的特殊性,我们在内存中持有了几个很大的map对象,毫无疑问它们会进入老年代。然而这些对象又并非长生不死!每隔一段时间,由于数据需要更新,又会有一些新的map对象被创建出来,旧的map对象失去引用,需要被GC回收掉。由于老年代内存大量增长,不得不进行Major GC,且一次性要释放掉大量内存,这个时间很难降到特别低。
既然问题出在大map对象,那解决思路自然是:避免使用大map对象,或者更准确地说——不要把这么大的数据放到堆内存中。
数据不放到堆内存中,那要么放堆外(进程内直接内存),要么放进程外。
进程外方案显然就是各种数据库了;进程内的方案呢?则有进程内数据库(如Berkeley DB)和堆外缓存两种。而数据库对我来说又太重了,其实我想要的只是一个map的功能。因此便决定进一步研究堆外缓存。
另:关于Java缓存的方案这里不再赘述,引用《跟开涛学架构》中的缓存一节:
Java缓存类型
- 堆缓存:使用java堆内存来存储对象,好处是不需要序列化/反序列化,速度快,缺点是受GC影响。可以使用Guava Cache、Ehcache 3.x、MapDB实现。
- 堆外缓存:缓存数据存储在堆外,突破了JVM的枷锁,读取数据时需要序列化/反序列化,比对堆内缓存慢很多。可以使用Ehcache 3.x、MapDB实现。
- 磁盘缓存:在JVM重启时数据还在,而堆缓存/堆外缓存数据会丢失,需要重新加载。可以使用Ehcache 3.x、MapDB实现。
- 分布式缓存:没啥好说的了,Redis…
堆外缓存
直接贴上两篇文章吧:
简单总结一下:
- 堆内缓存在数据量巨大时会造成GC性能问题。堆外缓存可解。
- 堆外缓存的实现原理就是
Unsafe类直接操作进程内存,那么就需要自己控制内存回收,以及和Java对象之间的序列化/反序列化,因为到了堆外只认识字节,不认识Java对象。 - 这么有用而又不易实现的功能当然最好求诸框架。支持的框架有mapdb,ohc,ehcache3等。ehcache3收费,ohc则最快。
综上,决定采用ohc。官网地址在此。
代码设计
思路:
- 灵活性考虑,采用策略模式。参考上文你所不知道的堆外缓存文末。
- 既然还是当作map用,那就让封装的工具类继承Map接口。ohc的一个
OHCache对象代表一块堆外缓存,我将它封装为一个map,存放一个国家的数据。自然,程序中会有多个OHCache。 - 此外,注意到
OHCache类本身是继承Closeable接口的,也就是调用其Close()方法可以释放其资源,即回收内存。因此封装的工具类也需要继承Closeable,并在更新国家数据的时候,调用被替换的原map对象的Close()方法,释放内存。经测试可行。 - 既然是在Spring Boot中使用,又是个缓存框架,自然希望将它适配到Spring的缓存体系中来。目前尚未实施。
效果
下图为改进之前,使用堆内map时,在刷新数据时更新map导致的GC情况:
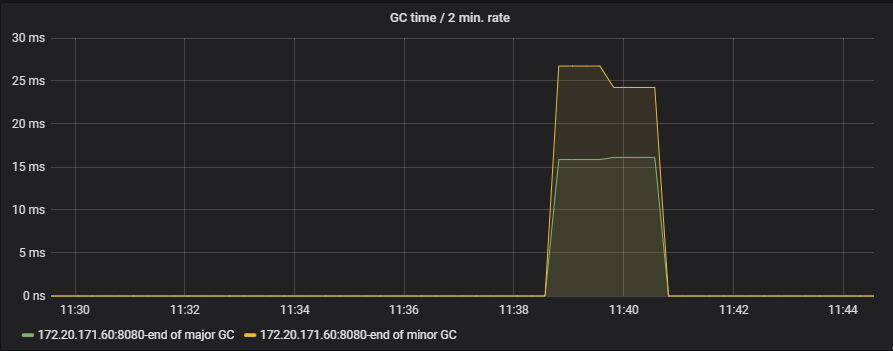
使用堆外内存改进后,我将JVM堆内存改小,为堆外留够内存,效果:
- 效果居然是一样啊。。。仍然会有Major GC问题!图我就不贴了。
- 平均延时由原来的10ms变成了40ms……
更进一步
这里就不(xie)卖(bu)关(xia)子(qu)了,直接说问题原因吧。
坑一:读取大文件
这次升级还做了一项改动:更新map所用的数据源由数据库改成了s3上的文件,而这些文件会有大几百MB。而我们使用了CommonsIO的readLines()方法。嗯,它会把整个文件内容加载到堆中,不GC才怪!
改用行枚举器后,GC问题终于消失了。不再有Major GC。
下图中正在发生map替换:
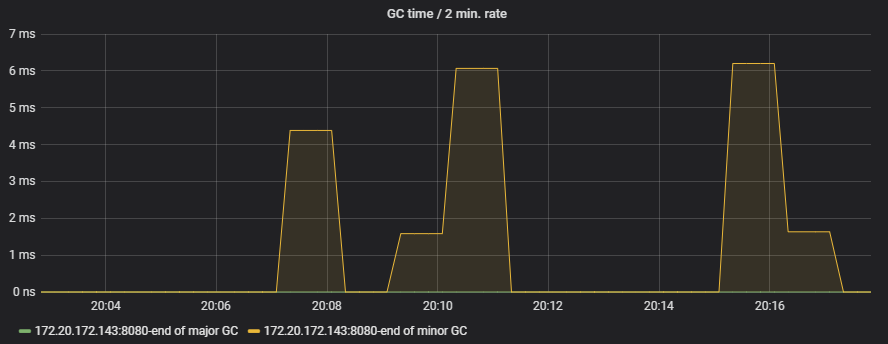
Major GC次数是零哦!

坑二:序列化
ohc需要你提供key和value的序列化方式,传入一个ByteBuffer。由于年少无知,我再一次使用了Apache的序列化工具,将对象按JDK序列化方式转变成堆内字节数组后,再拷贝到ByteBuffer中。
解决方案是直接操作ByteBuffer,自定义序列化方式。修改之后,延时问题也解决了。
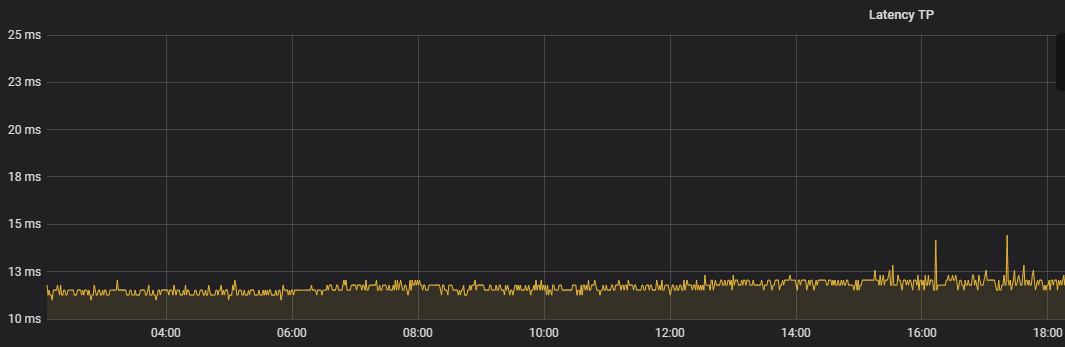
最终效果
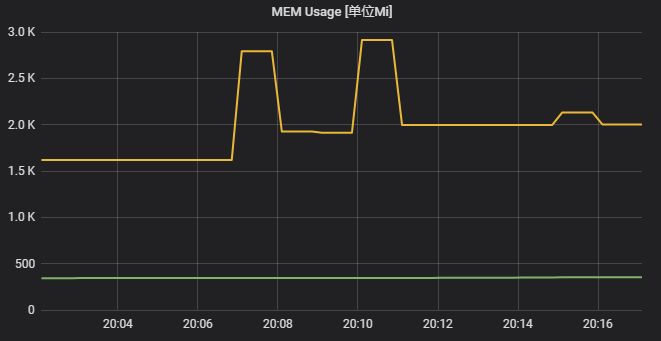
再附上替换map时进程总内存的变化:
感谢观看!
后记
使用ohc在线上完美的运行了几个月,没有出过问题。然而最近开始出现很多线上告警,一番追查下来,原来是我使用了固定capacity,然后默认的loadFactor是0.75。随着存放的商品索引越来越多(商品总数随着上架越来越多),居然超过了我预设的capacity,然后……有部分索引就被覆盖了。 这是一个值得注意的坑,特此记录下来。从根本来说,在生产中使用组件还是要尽量了解其各个方面。
