

翻译:疯狂的技术宅
从Call Stack,Global Memory,Event Loop,Callback Queue到 Promises 和 Async/Await 的 JavaScript引擎之旅!

你有没有想过浏览器是如何读取和运行 JavaScript 代码的吗?这看起来很神奇,但你可以学到一些发生在幕后的事情。让我们通过介绍 JavaScript 引擎的精彩世界在这种语言中尽情畅游。
在 Chrome 中打开浏览器控制台,然后查看“Sources”标签。你会看到一个有趣的命名:Call Stack(在Firefox中,你可以在代码中插入一个断点后看到调用栈):
什么是调用栈(Call Stack)?看上去像是有很多东西正在运行,即使是只执行几行代码也是如此。实际上,并不是在所有 Web 浏览器上都能对 JavaScript 做到开箱即用。
有一个很大的组件来编译和解释我们的 JavaScript 代码:它就是 JavaScript 引擎。最受欢迎的 JavaScript 引擎是V8,在 Google Chrome 和 Node.js 中使用,SpiderMonkey 用于 Firefox,以及 Safari/WebKit 所使用的 JavaScriptCore。
今天的 JavaScript 引擎是个很杰出的工程,尽管它不可能覆盖浏览器工作的方方面面,但是每个引擎都有一些较小的部件在为我们努力工作。
其中一个组件是调用栈,它与全局内存和执行上下文一起运行我们的代码。你准备好迎接他们了吗?
JavaScript 引擎和全局内存
我认为 JavaScript 既是编译型语言又是解释型语言。信不信由你,JavaScript 引擎在执行之前实际上编译了你的代码。
是不是听起来很神奇?这种魔术被称为 JIT(即时编译)。它本身就是一个很大的话题,即使是一本书也不足以描述 JIT 的工作原理。但是现在我们可以跳过编译背后的理论,专注于执行阶段,这仍然是很有趣的。
先看以下代码:
var num = 2;
function pow(num) {
return num * num;
}
如果我问你如何在浏览器中处理上述代码?你会说些什么?你可能会说“浏览器读取代码”或“浏览器执行代码”。
现实中比那更加微妙。首先不是浏览器而是引擎读取该代码片段。 JavaScript引擎读取代码,当遇到第一行时,就会将一些引用放入全局内存中。
**全局内存(也称为堆)**是 JavaScript 引擎用来保存变量和函数声明的区域。所以回到前面的例子,当引擎读取上面的代码时,全局内存中被填充了两个绑定:

即使例子中只有变量和函数,也要考虑你的 JavaScript 代码在更大的环境中运行:浏览器或在 Node.js 中。在这些环境中,有许多预定义的函数和变量,被称为全局。全局内存将比 num 和 pow 所占用的空间更多。记住这一点。
此时没有执行任何操作,但是如果尝试像这样运行我们的函数会怎么样:
var num = 2;
function pow(num) {
return num * num;
}
pow(num);
将会发生什么?现在事情变得有趣了。当一个函数被调用时,JavaScript 引擎会为另外两个盒子腾出空间:
- 全局执行上下文环境
- 调用栈
全局执行上下文和调用栈
在上一节你了解了 JavaScript 引擎是如何读取变量和函数声明的,他们最终进入了全局内存(堆)。
但是现在我们执行了一个 JavaScript 函数,引擎必须要处理它。怎么处理?每个 JavaScript 引擎都有一个基本组件,称为调用栈。
调用栈是一个栈数据结构:这意味着元素可以从顶部进入,但如果在它们上面还有一些元素,就不能离开栈。 JavaScript 函数就是这样的。
当函数开始执行时,如果被某些其他函数卡住,那么它无法离开调用堆栈。请注意,因为这个概念有助于理解“JavaScript是单线程”这句话。
但是现在让我们回到上面的例子。 当调用该函数时,引擎会将该函数压入调用堆栈中:

我喜欢将调用栈看作是一叠薯片。如果还没有先吃掉顶部的所有薯片,就吃不到到底部的薯片!幸运的是我们的函数是同步的:它是一个简单的乘法,可以很快的得到计算结果。
同时,引擎还分配了全局执行上下文,这是 JavaScript 代码运行的全局环境。这是它的样子:

想象一下全局执行环境作为一个海洋,其中 JavaScript 全局函数就像鱼一样在里面游泳。多么美好!但这只是故事的一半。如果函数有一些嵌套变量或一个或多个内部函数怎么办?
即使在下面的简单变体中,JavaScript 引擎也会创建本地执行上下文:
var num = 2;
function pow(num) {
var fixed = 89;
return num * num;
}
pow(num);
请注意,我在函数 pow 中添加了一个名为 fixed 的变量。在这种情况下,本地执行上下文中将包含一个用于保持固定的框。我不太擅长在小方框里画更小的框!你现在必须运用自己的想象力。
本地执行上下文将出现在 pow 附近,包含在全局执行上下文中的绿色框内。 你还可以想象,对于嵌套函数中的每个嵌套函数,引擎都会创建更多的本地执行上下文。这些框可以很快的到达它们该去的地方。
单线程的JavaScript
我们说 JavaScript 是单线程的,因为有一个调用栈处理我们的函数。也就是说,如果有其他函数等待执行,函数是不能离开调用栈的。
当处理同步代码时,这不是什么问题。例如,计算两个数字的和就是同步的,并且以微秒做为运行单位。但是当进行网络通信和与外界的互动时呢?
幸运的是 JavaScript引擎被默认设计为异步。即使他们一次可以执行一个函数,也有一种方法可以让外部实体执行较慢的函数:在我们的例子中是浏览器。我们稍后会探讨这个话题。
这时,你应该了解到当浏览器加载某些 JavaScript 代码时,引擎会逐行读取并执行以下步骤:
- 使用变量和函数声明填充全局内存(堆)
- 将每个函数调用送到调用栈
- 创建一个全局执行上下文,其在中执行全局函数
- 创建了许多微小的本地执行上下文(如果有内部变量或嵌套函数)
到此为止,你脑子里应该有了一个 JavaScript 引擎同步机制的全景图。在接下来的部分中,你将看到异步代码如何在 JavaScript 中工作以及为什么这样工作。
异步JavaScript,回调队列和事件循环
全局内存、执行上下文和调用栈解释了同步 JavaScript 代码在浏览器中的运行方式。然而我们还错过了一些东西。当有异步函数运行时会发生什么?
我所指的异步函数是每次与外界的互动都需要一些时间才能完成的函数。例如调用 REST API 或调用计时器是异步的,因为它们可能需要几秒钟才能运行完毕。 现在的 JavaScript 引擎都有办法处理这种函数而不会阻塞调用堆栈,浏览器也是如此。
请记住,调用堆栈一次只可以执行一个函数,**甚至一个阻塞函数都可以直接冻结浏览器。**幸运的是,JavaScript 引擎非常智能,并且能在浏览器的帮助下解决问题。
当我们运行异步函数时,浏览器会接受该函数并运行它。考虑下面的计时器:
setTimeout(callback, 10000);
function callback(){
console.log('hello timer!');
}
你肯定多次见到过 setTimeout ,但是你可能不知道它不是一个内置的 JavaScript 函数。即当 JavaScript 诞生时,语言中并没有内置的 setTimeout。
实际上 setTimeout 是所谓的 Browser API 的一部分,它是浏览器提供给我们的便利工具的集合。多么体贴!这在实践中意味着什么?由于 setTimeout 是一个浏览器 API,该函数由浏览器直接运行(它会暂时出现在调用栈中,但会立即删除)。
然后 10 秒后浏览器接受我们传入的回调函数并将其移动到回调队列。此时我们的 JavaScript 引擎中还有两个框。请看以下代码:
var num = 2;
function pow(num) {
return num * num;
}
pow(num);
setTimeout(callback, 10000);
function callback(){
console.log('hello timer!');
}
可以这样画完成我们的图:
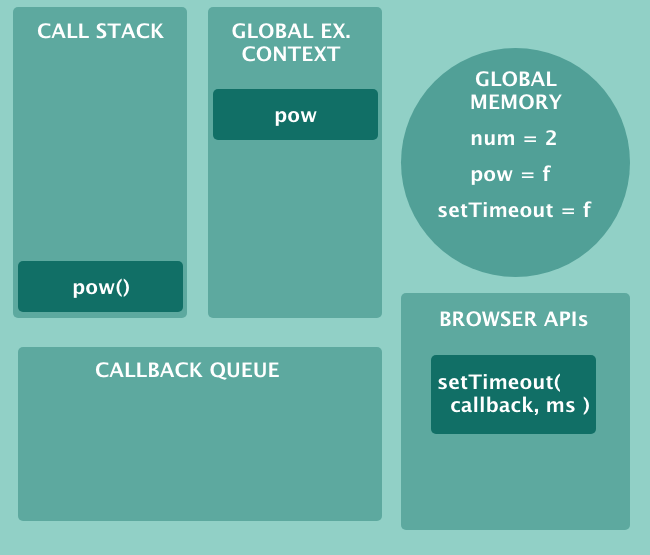
如你所见 setTimeout 在浏览器上下文中运行。 10秒后,计时器被触发,回调函数准备好运行。但首先它必须通过回调队列。回调队列是一个队列数据结构,顾名思义是一个有序的函数队列。
每个**异步函数在被送入调用栈之前必须通过回调队列。**但谁推动了这个函数呢?还有另一个名为 Event Loop 的组件。
Event Loop 现在只做一件事:它应检查调用栈是否为空。如果回调队列中有一些函数,并且如果调用栈是空闲的,那么这时应将回调送到调用栈。在完成后执行该函数。
这是用于处理异步和同步代码的 JavaScript 引擎的大图:
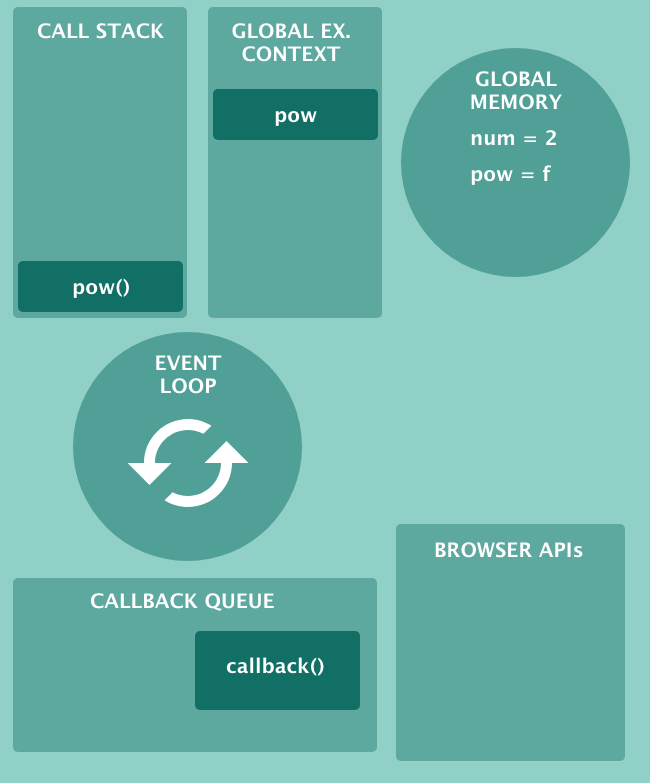
想象一下,callback() 已准备好执行。当 pow() 完成时,**调用栈为空,事件循环推送 **callback()。就是这样!即使我简化了一些东西,如果你理解了上面的图,那么就可以理解 JavaScript 的一切了。
请记住:Browser API、回调队列和事件循环是异步 JavaScript 的支柱。
如果你喜欢视频,我建议去看 Philip Roberts 的视频:事件循环是什么。这是关于时间循环的最好的解释之一。
youtube: www.youtube.com/embed/8aGhZ…
坚持下去,因为我们还没有使用异步 JavaScript。在后面的内容中,我们将详细介绍 ES6 Promises。
回调地狱和 ES6 的 Promise
JavaScript 中的回调函数无处不在。它们用于同步和异步代码。例如 map 方法:
function mapper(element){
return element * 2;
}
[1, 2, 3, 4, 5].map(mapper);
mapper 是在 map 中传递的回调函数。上面的代码是同步的。但要考虑一个间隔:
function runMeEvery(){
console.log('Ran!');
}
setInterval(runMeEvery, 5000);
该代码是异步的,我们在 setInterval 中传递了回调 runMeEvery。回调在 JavaScript 中很普遍,所以近几年里出现了一个问题:回调地狱。
JavaScript中的回调地狱指的是编程的“风格”,回调嵌套在嵌套在…...其他回调中的回调中。正是由于 JavaScript 的异步性质导致程序员掉进了这个陷阱。
说实话,我从来没有碰到过极端的回调金字塔,也许是因为我重视代码的可读性,并且总是试着坚持这个原则。如果你发现自己掉进了回调地狱,那就说明你的函数太多了。
我不会在这里讨论回调地狱,如果你很感兴趣的话,给你推荐一个网站: callbackhell.com 更深入地探讨了这个问题并提供了一些解决方案。我们现在要关注的是 ES6 Promise。 ES6 Promise 是对 JavaScript 语言的补充,旨在解决可怕的回调地狱。但 Promise 是什么?
JavaScript Promise 是未来事件的表示。Promise 能够以 success 结束:用行话说就是它已经 resolved(已经完成)。但如果 Promise 出错,我们会说它处于rejected状态。 Promise 也有一个默认状态:每个新Promise都以 pending 状态开始。
创建和使用 Promise
要创建新的 Promise,可以通过将回调函数传给要调用的 Promise 构造函数的方法。回调函数可以使用两个参数:resolve 和 reject。让我们创建一个新的 Promise,它将在5秒后 resolve(你可以在浏览器的控制台中尝试这些例子):
const myPromise = new Promise(function(resolve){
setTimeout(function(){
resolve()
}, 5000)
});
如你所见,resolve 是一个函数,我们调用它使 Promise 成功。下面的例子中 reject 将得到 rejected 的 Promise:
const myPromise = new Promise(function(resolve, reject){
setTimeout(function(){
reject()
}, 5000)
});
请注意,在第一个示例中,你可以省略 reject ,因为它是第二个参数。但是如果你打算使用 reject**,就不能省略 resolve**。换句话说,以下代码将无法工作,最终将以 resolved 的 Promise 结束:
// Can't omit resolve !
const myPromise = new Promise(function(reject){
setTimeout(function(){
reject()
}, 5000)
});
现在 Promise 看起来不是那么有用。这些例子不向用户打印任何内容。让我们添加一些数据。 resolved 的和rejected 的 Promises 都可以返回数据。这是一个例子:
const myPromise = new Promise(function(resolve) {
resolve([{ name: "Chris" }]);
});
但我们仍然看不到任何数据。 要从 Promise 中提取数据,你还需要一个名为 then 的方法。它需要一个回调(真是具有讽刺意味!)来接收实际的数据:
const myPromise = new Promise(function(resolve, reject) {
resolve([{ name: "Chris" }]);
});
myPromise.then(function(data) {
console.log(data);
});
作为 JavaScript 开发人员,你将主要与来自外部的 Promises 进行交互。相反,库的开发者更有可能将遗留代码包装在 Promise 构造函数中,如下所示:
const shinyNewUtil = new Promise(function(resolve, reject) {
// do stuff and resolve
// or reject
});
在需要时,我们还可以通过调用 Promise.resolve() 来创建和解决 Promise:
Promise.resolve({ msg: 'Resolve!'})
.then(msg => console.log(msg));
所以回顾一下,JavaScript Promise 是未来发生的事件的书签。事件以挂起状态开始,可以成功(resolved,fulfilled)或失败(rejected)。 Promise 可以返回数据,通过把 then 附加到 Promise 来提取数据。在下一节中,我们将看到如何处理来自 Promise 的错误。
ES6 Promise 中的错误处理
JavaScript 中的错误处理一直很简单,至少对于同步代码而言。请看下面的例子:
function makeAnError() {
throw Error("Sorry mate!");
}
try {
makeAnError();
} catch (error) {
console.log("Catching the error! " + error);
}
输出将是:
Catching the error! Error: Sorry mate!
错误在 catch 块中被捕获。现在让我们尝试使用异步函数:
function makeAnError() {
throw Error("Sorry mate!");
}
try {
setTimeout(makeAnError, 5000);
} catch (error) {
console.log("Catching the error! " + error);
}
由于 setTimeout,上面的代码是异步的。如果运行它会发生什么?
throw Error("Sorry mate!");
^
Error: Sorry mate!
at Timeout.makeAnError [as _onTimeout] (/home/valentino/Code/piccolo-javascript/async.js:2:9)
这次输出是不同的。错误没有通过 catch块。它可以自由地在栈中传播。
那是因为 try/catch 仅适用于同步代码。如果你感到好奇,可以在 Node.js 中的错误处理中得到该问题的详细解释。
幸运的是,Promise 有一种处理异步错误的方法,就像它们是同步的一样。
const myPromise = new Promise(function(resolve, reject) {
reject('Errored, sorry!');
});
在上面的例子中,我们可以用 catch 处理程序错误,再次采取回调:
const myPromise = new Promise(function(resolve, reject) {
reject('Errored, sorry!');
});
myPromise.catch(err => console.log(err));
我们也可以调用 Promise.reject() 来创建和 reject Promise:
Promise.reject({msg: 'Rejected!'}).catch(err => console.log(err));
ES6 Promise 组合器:Promise.all,Promise.allSettled,Promise.any和它们的小伙伴
Promise 并不是在孤军奋战。 Promise API 提供了一系列将 Promise 组合在一起的方法。其中最有用的是Promise.all,它接受一系列 Promise 并返回一个Promise。问题是当任何一个Promise rejected时,Promise.all 就会 rejects 。
Promise.race 在数组中的一个 Promise 结束后立即 resolves 或 reject。如果其中一个Promise rejects ,它仍然会rejects。
较新版本的 V8 也将实现两个新的组合器:**Promise.allSettled **和 Promise.any。 Promise.any 仍处于提案的早期阶段:在撰写本文时,还不支持。
Promise.any 可以表明任何 Promise 是否 fullfilled。与 Promise.race 的区别在于 Promise.any 不会 reject,即使是其中一个Promise 被 rejected。
最有趣的是 Promise.allSettled。它仍然需要一系列的 Promise,但如果其中一个 Promise rejects 的话 ,它不会被短路。当你想要检查 Promise 数组中是否全部已解决时,它是有用的。可以认为它总是和 Promise.all 对着干。
ES6 Promise 和 microtask 队列
如果你还记得前面的章节**,JavaScript 中的每个异步回调函数都会在被推入调用栈之前在回调队列中结束**。但是在 Promise 中传递的回调函数有不同的命运:它们由微任务队列处理,而不是由回调队列处理。
你应该注意一个有趣的现象:微任务队列优先于回调队列。当事件循环检查是否有任何新的回调准备好被推入调用栈时,来自微任务队列的回调具有优先权。
Jake Archibald 在任务、微任务、队列和时间表一文中更详细地介绍了这些机制,这是一篇很棒的文章。
异步的进化:从 Promise 到 async/await
JavaScript 正在快速发展,每年我们都会不断改进语言。Promise 似乎是到达了终点,但 **ECMAScript 2017(ES8)的新语法诞生了:async / await **。
async/await 只是一种风格上的改进,我们称之为语法糖。 async/await 不会以任何方式改变 JavaScript(请记住,JavaScript 必须向后兼容旧浏览器,不应破坏现有代码)。
它只是一种基于 Promise 编写异步代码的新方法。让我们举个例子。之前我们用 then 的 Promise:
const myPromise = new Promise(function(resolve, reject) {
resolve([{ name: "Chris" }]);
});
myPromise.then((data) => console.log(data))
现在使用async/await,我们可以从另一个角度看待用同步的方式处理异步代码。我们可以将 Promise 包装在标记为 async 的函数中,然后等待结果:
const myPromise = new Promise(function(resolve, reject) {
resolve([{ name: "Chris" }]);
});
async function getData() {
const data = await myPromise;
console.log(data);
}
getData();
现在有趣的是异步函数将始终返回 Promise,并且没人能阻止你这样做:
async function getData() {
const data = await myPromise;
return data;
}
getData().then(data => console.log(data));
怎么处理错误呢? async/await 提供的一个好处就是有机会使用 try/catch。 (参见异步函数中的异常处理及测试方法 )。让我们再看一下Promise,我们使用catch处理程序来处理错误:
const myPromise = new Promise(function(resolve, reject) {
reject('Errored, sorry!');
});
myPromise.catch(err => console.log(err));
使用异步函数,我们可以重构以下代码:
async function getData() {
try {
const data = await myPromise;
console.log(data);
// or return the data with return data
} catch (error) {
console.log(error);
}
}
getData();
不是每个人都会用这种风格。 try/catch 会使你的代码混乱。虽然用 try/catch还有另一个问题要指出。请看以下代码,在try块中引发错误:
async function getData() {
try {
if (true) {
throw Error("Catch me if you can");
}
} catch (err) {
console.log(err.message);
}
}
getData()
.then(() => console.log("I will run no matter what!"))
.catch(() => console.log("Catching err"));
哪一字符串会打印到控制台?请记住,try/catch是一个同步构造,但我们的异步函数会产生一个 Promise。他们在两条不同的轨道上行驶,就像两列火车。但他们永远不会碰面!也就是说,throw 引发的错误永远不会触发 getData() 的 catch 处理程序。运行上面的代码将导致 “抓住我,如果你可以”,然后“不管怎样我都会跑!”。
实际上我们不希望 throw 触发当前的处理。一种可能的解决方案是从函数返回 Promise.reject():
async function getData() {
try {
if (true) {
return Promise.reject("Catch me if you can");
}
} catch (err) {
console.log(err.message);
}
}
现在错误将按预期处理:
getData()
.then(() => console.log("I will NOT run no matter what!"))
.catch(() => console.log("Catching err"));
"Catching err" // output
除此之外 async/await 似乎是在 JavaScript 中构建异步代码的最佳方式。我们可以更好地控制错误处理,代码看起来更清晰。
我不建议把所有的 JavaScript 代码都重构为 async/await。这必须是与团队讨论之后的选择。但是如果你自己工作的话,无论你使用简单的 Promise 还是 async/await 都是属于个人偏好的问题。
总结
JavaScript 是一种用于Web的脚本语言,具有先被编译然后再由引擎解释的特性。在最流行的 JavaScript 引擎中,有 Google Chrome 和 Node.js 使用的V8,为网络浏览器 Firefox 构建的 SpiderMonkey,由Safari使用的 JavaScriptCore。
JavaScript 引擎有很多部分组成:调用栈、全局内存、事件循环和回调队列。所有这些部分在完美的调整中协同工作,以便在 JavaScript 中处理同步和异步代码。
JavaScript 引擎是单线程的,这意味着只有一个用于运行函数的调用堆栈。这种限制是 JavaScript 异步性质的基础:所有需要时间的操作必须由外部实体(例如浏览器)或回调函数负责。
为了简化异步代码流程,ECMAScript 2015 给我们带来了 Promises。 Promise 是一个异步对象,用于表示异步操作的失败或成功。但改进并没有止步于此。 2017年 async/await诞生了:它是 Promise 的一种风格上的弥补,可以用来编写异步代码,就好像它是同步的一样。
欢迎关注前端公众号:前端先锋,获取前端工程化实用工具包。

