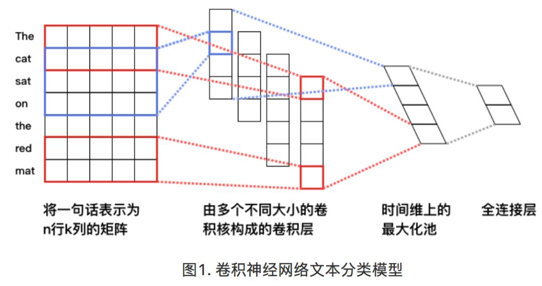
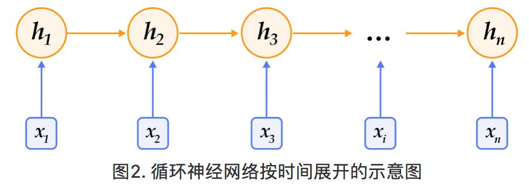
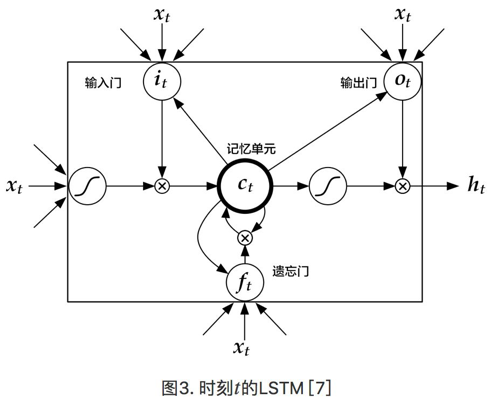
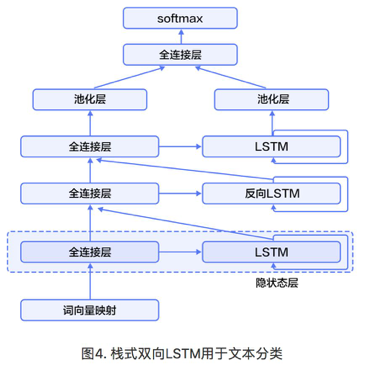
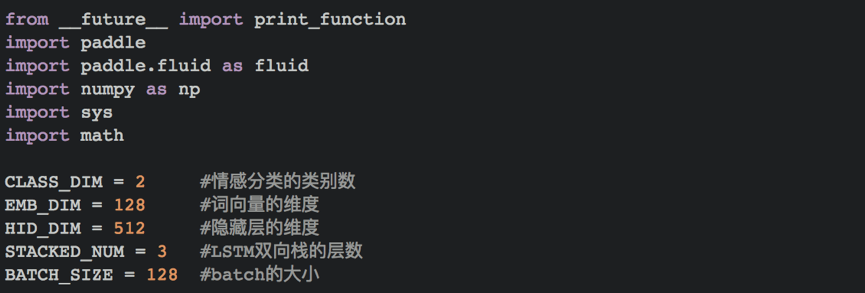
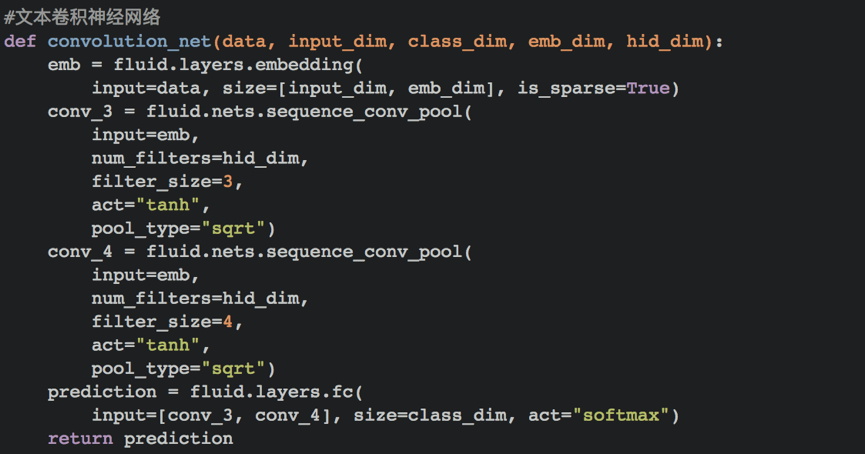
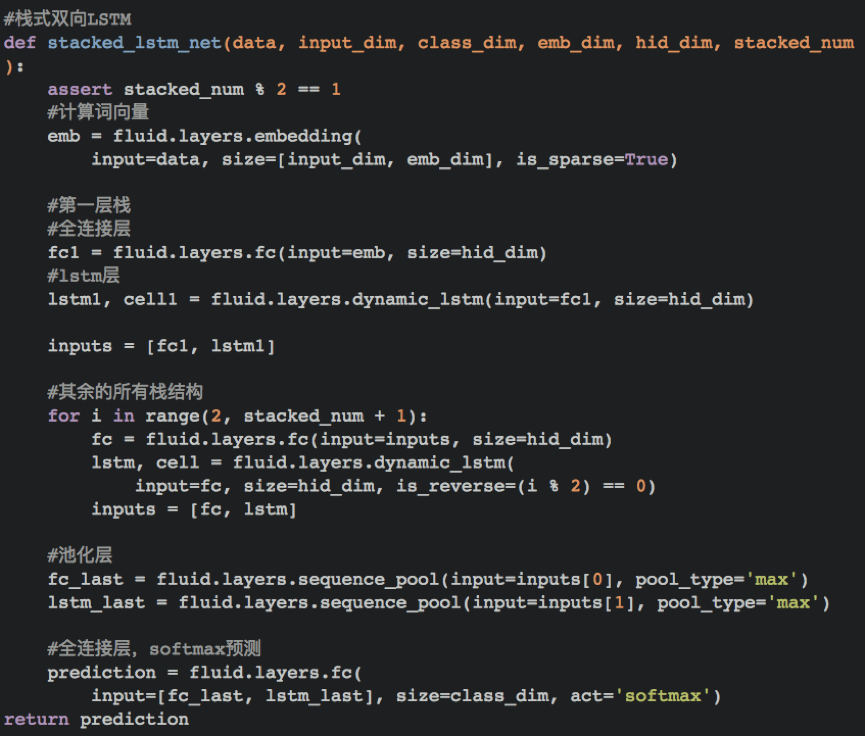
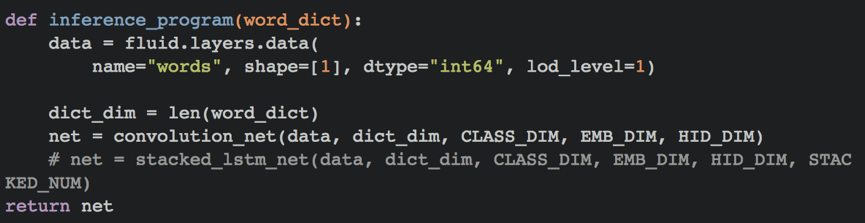
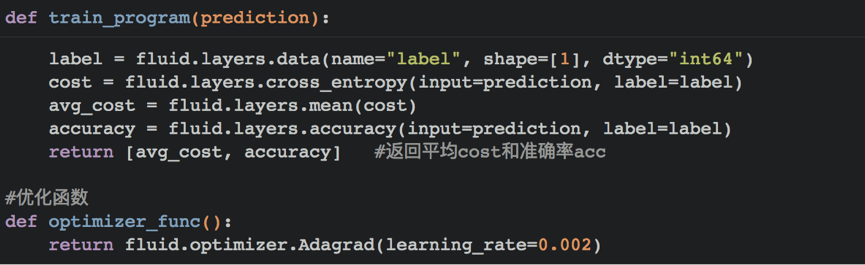
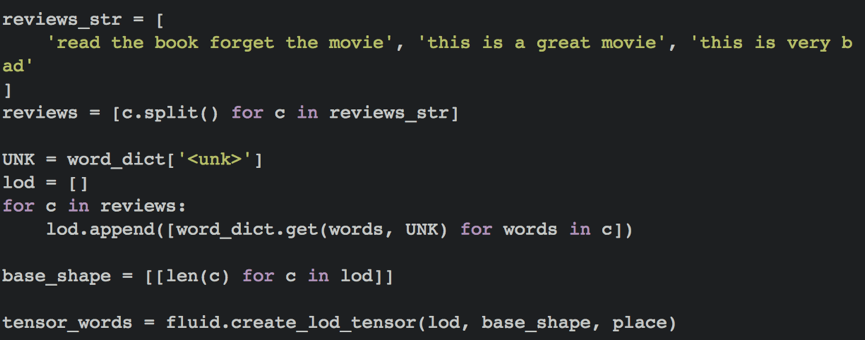
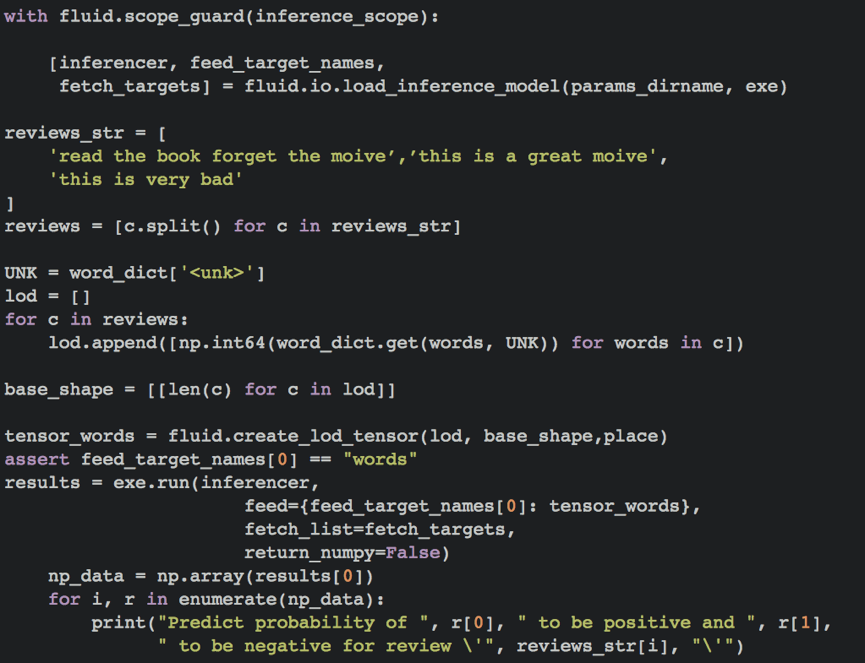
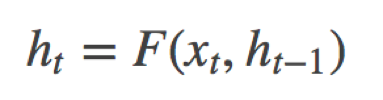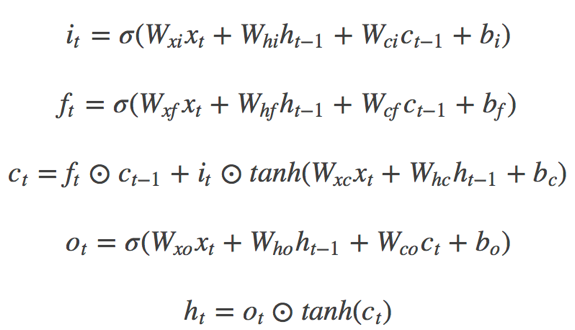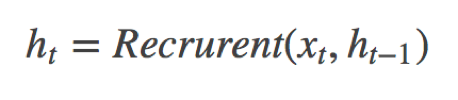循环神经网络是一种能对序列数据进行精确建模的有力工具。实际上,循环神经网络的理论计算能力是图灵完备的[4]。自然语言是一种典型的序列数据(词序列),近年来,循环神经网络及其变体(如long short term memory[5]等)在自然语言处理的多个领域,如语言模型、句法解析、语义角色标注(或一般的序列标注)、语义表示、图文生成、对话、机器翻译等任务上均表现优异甚至成为目前效果最好的方法。
Kim Y. Convolutional neural networks for sentence classification[J]. arXiv preprint arXiv:1408.5882, 2014.
Kalchbrenner N, Grefenstette E, Blunsom P. A convolutional neural network for modelling sentences[J]. arXiv preprint arXiv:1404.2188, 2014.
Yann N. Dauphin, et al. Language Modeling with Gated Convolutional Networks[J] arXiv preprint arXiv:1612.08083, 2016.
Siegelmann H T, Sontag E D. On the computational power of neural nets[C]//Proceedings of the fifth annual workshop on Computational learning theory. ACM, 1992: 440-449.
Hochreiter S, Schmidhuber J. Long short-term memory[J]. Neural computation, 1997, 9(8): 1735-1780.
Bengio Y, Simard P, Frasconi P. Learning long-term dependencies with gradient descent is difficult[J]. IEEE transactions on neural networks, 1994, 5(2): 157-166.
Graves A. Generating sequences with recurrent neural networks[J]. arXiv preprint arXiv:1308.0850, 2013.
Cho K, Van Merriënboer B, Gulcehre C, et al. Learning phrase representations using RNN encoder-decoder for statistical machine translation[J]. arXiv preprint arXiv:1406.1078, 2014.
Zhou J, Xu W. End-to-end learning of semantic role labeling using recurrent neural networks[C]//Proceedings of the Annual Meeting of the Association for Computational Linguistics. 2015.