

本文在MIT在线课程《3.Data Analysis for Social Scientists》中Causality(因果关系)部分课程的课件基础上,补充了相关信息、增加了个人理解,详细介绍了因果关系的本质及其实践。
本篇是四篇系列文章的第一篇,主要解读因果关系定义与潜在结果分析框架。
什么是因果关系
我们经常做出的因果陈述(Causal Statements),比如:
▫ 因为她吃了药,所以她头疼好多了
▫ 因为她上了MIT,所以她找到了好工作
▫ 因为她是非裔美国人,所以她没有获得面试机会
这些因果陈述到底想表达什么意思呢?这些陈述中暗含着一个反事实(counterfactual)的世界(类似平行宇宙的想法)。不同的行为发生了,对应上面三个例子:
▫ (反事实)她没有吃药
▫ (反事实)她没有上MIT,她可能做了其它事情(可做了什么在陈述中并没有明确指出)
▫ (反事实)这里意思不完全清楚,是改变的她的种族?还是改变人们在做聘用决定时关于种族的看法?
总体来说,当我们思考因果关系时,我们考虑的是操作(干预)一个“因”的可能效果,假如我们干预或不干预这个“因”,然后什么会发生。
因果关系可以被证明吗?
在经济和社会科学领域,许多我们想回答的问题是因果问题:移民是否降低了本地工人的工资?贸易是否增加了不平等?在美国和墨西哥之间建立隔离墙是否能阻止移民?所以在社会科学领域的许多数据科学目标是回答“因”与“果”的问题。
但是,针对一些重要但非因果问题时,因果分析没什么用。例如,我们可能感兴趣识别在学校儿童存在危险的早期预兆信号,这样我们可以集中努力解决它们。谷歌会希望基于人们的搜索模式预测他们对什么东西感兴趣,从而向他们提供他们更可能感兴趣的广告。此时更关注的是相关关系。
统计学分析因果关系使用了因果推断(Causal Inference),提到推断就涉及证明问题,有学者认为统计学不能被“证明”因果,只有“相关”是可以被证明。
有一个很有名的例子,叫做 Yule-Simpson’s Paradox。有文献称,Karl Pearson 很早就发现了这个悖论——也许这正是他反对统计因果推断的原因。此悖论表明,存在如下的可能性:X和Y在边缘上正相关(处理效果为正),但是给定另外一个变量Z后,在Z的每一个取值上,X和Y都负相关。下表是一个数值的例子,处理对整个人群有 “正作用”,奇怪的是,处理对男性有 “负作用”,对女性也有 “负作用”。一个处理对男性和女性都有 “负作用”,但是他对整个人群却有 “正作用”:悖论产生了!
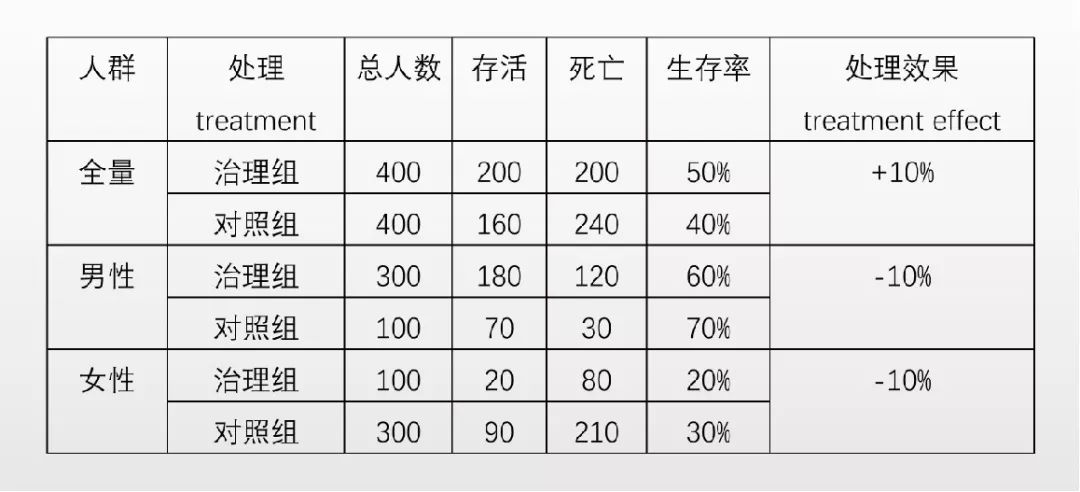
上面的例子是人工构造的,在现实中,也存在不少的实例正是 Yule-Simpson’s Paradox。比如,UC Berkeley 的著名统计学家 Peter Bickel 教授 1975 年在 Science 上发表文章,报告了 Berkeley 研究生院男女录取率的差异。他发现,总体上,男性的录取率高于女性,然而按照专业分层后,女性的录取率却高于男性(Bickel 等 1975)。
在统计上,这具有重要的意义—变量之间的相关关系可以完全的被第三个变量 “扭曲”。更严重的问题是,我们的收集的数据可能存在局限性,忽略潜在的“第三个变量” 可能改变已有的结论,而我们常常却一无所知,虽然对已知的可以通过实验设计以避免。鉴于 Yule-Simpson 悖论的潜在可能,不少人认为,统计不可能用来研究因果关系。
在做因果关系研究时,经常用到假设检验、P值以及推导出的统计学意义。一般认为P≤0.05或者P≤0.01就有显著性差异,研究就有统计意义。但,最新一期2019年3月份的Nature杂志发表了三位统计学家的一封公开信,他们号召科学家放弃追求“统计学意义”,并且停止用统计学中常见的P值作为判断标准。统计学上无显著的结果并不能“证明”零假设;统计上显著的结果也没有“证明”某些其他假设。标题犹如战斗檄文一样令人振奋。在文章发出不到24小时,就有250多人签名支持,一周之内吸引了超过800名研究人员共同反对。

文中总结并不是要抛弃P值与相关的统计方法,而是要彻底理解统计因果分析的内涵,从而在证明因果方面的保持谨慎。研究人员可以从教育自己对统计的误解开始,最重要的是在每项研究中从多个角度考虑不确定性。
在大数据时代,之前大家过于关注易于被证明的相关关系而忽略了因果,关于因果关系和相关关系的讨论,业内已经进行很久,但是因果对于洞察和预测的价值更大,现在在大数据领域,对于因果应该被重新重视起来,了解因果分析对大家正确理解各种研究结果与数据分析也非常有帮助。
因果分析关系框架:潜在结果框架
潜在结果框架(Potential Outcome Framework)这个模型由哈佛统计学家Donald Rubin提出。在思考随机对照试验(Randomized Controlled Trials, RCT)和更一般的因果关系时非常有用。这不是在社会科学中思考因果关系的唯一(或最普遍的)方式,在社会科学中SEM(结构方程模型Structural Equation Modeling)更普遍。但是潜在结果框架越来越普及,并且越熟悉它,越能在两者之间切换。
潜在结果框架又称为Rubin因果模型(Rubin causal model, RCM)或者Neyman–Rubin因果模型。
(参考:https://en.wikipedia.org/wiki/Rubin_causal_model)
Rubin Causal Model分析框架有三个基本的要素:
潜在结果(Potential Outcome)
个体处理稳定性假设(Stable Unit Treatment Value Assumption,SUTVA)
分配机制(Assignment Mechanism)。
(参考: https://zhuanlan.zhihu.com/p/33299957)
潜在结果与因果效应定义
01、潜在结果
潜在结果:给定一个单元,和一系列动作,我们把一个“动作-单元”确定为一个潜在结果。“潜在(potential)”这个词表达的意思是我们并不总是能在现实中观察到这个结果(outcome),但原则上它们可能发生。
考虑“潜在结果”这个术语迫使我思考“反事实”(counterfactual),因为我们想知道在那个空间(Space)定义潜在的结果,从而帮助我们提出良好定义的因果问题,或判断怎样才是良好定义的因果问题。针对开头的三个因果关系陈述的例子:
第一个例子是个比较相对清晰的例子:吃了药对应的反事实是没吃药,有时我们把“没吃药”作为“控制组”并且把“吃了药(control group)”作为“实验组(treatment group)”;
第二个例子相对有一点不清楚:她不去大学的替代选择是什么呢?
第三个例子更不清楚:如果她是另一个种族什么会发生,那是什么呢?有哪些不同的方式?
在下一个单元介绍随机对照试验(RCT)设计时会第二和第三例子如何定义更易于实验的潜在结果与具体的RCT设计。
02、因果效应的定义
对于任何一个单元,“处理(treatment)”与“不处理(without treatment)”这两个潜在结果之间的差别就是处理的因果效用(Causal Effect),或者说处理效果(Treatment Effect)。
因果效应定义为:(处理)-(不处理),表达式中括弧内的是干预动作,Y表示这个动作的效果。
头疼的例子中存在四种可能性(possibilities):(下面表达式中括弧内的是干预动作,Y表示这个动作的效果,等号后面为效果的值)
Y(吃了阿司匹林)=不头疼;Y(没吃阿司匹林)=头疼
Y(吃了阿司匹林)=头疼;Y(没吃阿司匹林)=头疼
Y(吃了阿司匹林)=不头疼;Y(没吃阿司匹林)=不头疼
Y(吃了阿司匹林)=头疼;Y(没吃阿司匹林)=不同头疼
对应的治疗效果是:
使头疼消失了(即有效,证明因果关系陈述成立)
没有效果
没有效果
阻止头疼消失(反效果、负效果,虽然不常见但原则上存在这种可能性)
03、因果推断的基础问题
“因果推断的基础问题”(Holland, 1986)是对于同一个单元最多只有一个潜在结果被实现而能被观测到,总有一个缺失值。因果效应(Causal Effect)是在同一个时间(处理后)对同一个单元的对比,处理效果(Treatment Effect)的计算依赖于所有的潜在结果(Potential Outcomes)而不仅仅依赖于实际观测到的结果。
因此,对于处理效果的估计(Estimation),未来对我们观测到的结果进行对比,我们将需要许多个单元的数据。(在这个讨论中对同一个人不同时间的两次不同测量是两个不同的单元)
了解(或假设)一些潜在结果(而不是其它的结果)被实现的方式是非常关键的,这个方式会在下一单位分配机制中马上就会被讨论。
个体处理稳定性假设(SUTVA)
01、引入多个单元后存在的问题
当考虑多于一个单元时,事情会很快变得复杂。假设Esther和David都在一个办公室,并且都在为这门课准备教案。两个人可能同时头疼,并且两个都可以选择吃(或不吃)阿司匹林。现在每个人都有四种潜在结果:
Y(EA, DN), Y(EA,DA), Y(EN, DN), Y(EN, DA)。
(E指Esther,D指David,A指吃阿司匹林,N指不吃阿司匹林)
在这种情形下,就有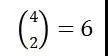 种不同的比较,针对以上四种潜在结果的两两比较。当我们添加更多的单元时,我们就添加了更多的潜在比较:我们将永远不会获得足够的数据去估计我们想要的东西。
种不同的比较,针对以上四种潜在结果的两两比较。当我们添加更多的单元时,我们就添加了更多的潜在比较:我们将永远不会获得足够的数据去估计我们想要的东西。
Esther与David各有四种潜在结果和6种比较,两个人需要被分别编码,这里Y只是关于一个人的,比如Esther,也就是说会有一个表达式(比如Z替换Y)是关于David的。
为什么是四种潜在结果?为什么两个人的行为要一起考察呢?是因为两者的行为存在可能的相互影响。同时这个影响因素不仅仅是因为治疗效果,如果仅仅因为治疗效果影响另一个人是否采取吃药的行动,那就可以减少(状态的)维度了,只进行Esther是否吃药的比较就可以了。影响的因素可能是,David说“对不起,我头疼做不了教案了”,那么我(Esther)要做更多的工作所以我就头疼了;或者,他(David)说他头疼,他抱怨,于是就让我头疼了。
“我们将永远不会获得足够的数据去估计我们想要的东西”,这里表达是当引入更多单元后情况变得更糟糕了。具体是,当只有(Esther)一个人时,只需要进行一个人两个潜在结果(吃药与不吃药)的一个比较,并可以观测到一个数据点(一个人的一个实现),情况就是有1个数据点的1个比较,当然数据也是不够的;当增加另外一个人后,就需要进行4个潜在结果的6种比较,实际可以观测到两个数据点(两个人的各一个实现),所以情况变成是有2个数据点的6种比较,数据就更不够了,引入更多单元后情况没有改善。我们需要解决这个问题,我们解决这个问题的方式是用一个假设(SUTVA)。
02、个体处理稳定性假设
也许在头疼例子中自然的假设是:David的头疼不影响Esther,所以自然的假设是:任何单元的潜在结果(potential outcomes)不会随分配给其它单元的处理(treatment)而变化; 并且,对于每个单元,没有导致不同(潜在)结果的一个处理单元的不同形式或版本,即个体处理稳定性假设(Stable Unit Treatment Value Assumption, SUTVA)。
具体就是,首先,排除(在经济学中被称为的)外部效应或溢出效应,即该效应一个人的处理(treatment)状态直接影响另一个人;其次,处理(treatment)被良好的定义,反事实(counterfactual)被良好的定义,例如种族的例子就不符合。如果处理A有三种形式,那么处理(treatment)应该被重新定义为A、B、C三种处理而不是一种。
注:SUTVA超出了独立的概念。
https://en.wikipedia.org/wiki/Rubin_causal_model#Stable_unit_treatment_value_assumption_(SUTVA)
分配机制的重要性
从现在开始假设SUTVA成立。那么阿司匹林的例子对David和Esther就简化为两种情况:每个人吃或不吃阿司匹林与另一个人做什么是不相关的。这个可以扩展到多个单元,从而可以做下面的定义:
假设有一个人群,人数为N,被编号为i,取值1~N;
Wi代表第i个人被处理(treatment)还是不处理(without treatment),值为1表示被处理,值为0表示不处理;
Yi代表第i个人的效果,上标obs表示实际被观察到,上标miss表示实际没有被观察到;
那么第i个人的效果存在下面四种可能:
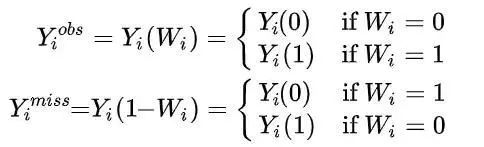
同时,依定义对于第i个人因果效应为:
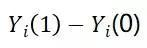
如果他在被处理组(treatment),Wi = 1,那么他这个个体不被处理情况的效果不会被观察到,即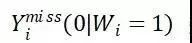 数据缺失;反之,如果他在不处理组(controled),Wi = 0,那么他这个个体被处理情况的效果不会被观察到,即
数据缺失;反之,如果他在不处理组(controled),Wi = 0,那么他这个个体被处理情况的效果不会被观察到,即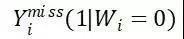 数据缺失;所以对于单个个体的因果效应定义
数据缺失;所以对于单个个体的因果效应定义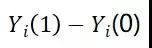 中总有一项数据会缺失,也就是同一个人只有一种情况被观察到。
中总有一项数据会缺失,也就是同一个人只有一种情况被观察到。
缺少数据的问题:我们只观察到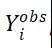 ,所以我们不能对一个人计算他的处理效果(treatment effect),我们需要设法从我们观测到的数据中推断关于的一些信息,但是为了做到这一点,了解分配机制的原理是非常必要的,即为什么一些人被处理而另一些人没有?
,所以我们不能对一个人计算他的处理效果(treatment effect),我们需要设法从我们观测到的数据中推断关于的一些信息,但是为了做到这一点,了解分配机制的原理是非常必要的,即为什么一些人被处理而另一些人没有?
下篇预告:
在下一个单元中,首先将详细介绍如何基于观察数据构建处理效应估计以及估计中存在的选择性偏差原理,然后介绍如何通过随机化解决选择性问题以及RCT类型,并进一步说明本单元开头三个例子的RCT具体如何进行设计。
参考资料汇总:
[1]https://prod-edxapp.edx-cdn.org/assets/courseware/v1/6b6442916a97d7afc3e9f40801085486/asset-v1:MITx+14.310x+1T2019+type@asset+block/14310x_Lecture14_New_ToUpload.pdf
[2] https://en.wikipedia.org/wiki/Rubin_causal_model
[3] https://en.wikipedia.org/wiki/Rubin_causal_model#Stable_unit_treatment_value_assumption_(SUTVA)
[4] 因果推断,选择偏误与随机试验https://zhuanlan.zhihu.com/p/33299957
[5] 因果推断简介https://cosx.org/2012/03/causality1-simpson-paradox/
[6] 大学统计学白上了?800多科学家联名反对“统计学意义”,P值该废了
https://mp.weixin.qq.com/s?__biz=MzI3MTA0MTk1MA%3D%3D&chksm=f1219b03c65612150ff28a7564a8a0e738e93aea401a02858feac8e0fe0d035cb6aed52b607c&idx=2&mid=2652041202&scene=0&sn=e077f6cfa985caab7e99ebab4a15113a&xtrack=1#rd
[7]https://www.nature.com/articles/d41586-019-00857-9?from=singlemessage&isappinstalled=0#ref-CR4
注:封面图来源于网络,如有侵权,请联系删除
