

Author : Ali0th
Date : 20190514
最近用go语言写了个爬虫,爬了几百万条数据,存在 mysql 里,数据量较大,一个表就一两G的程度(mysql表一般不要超过2G)。
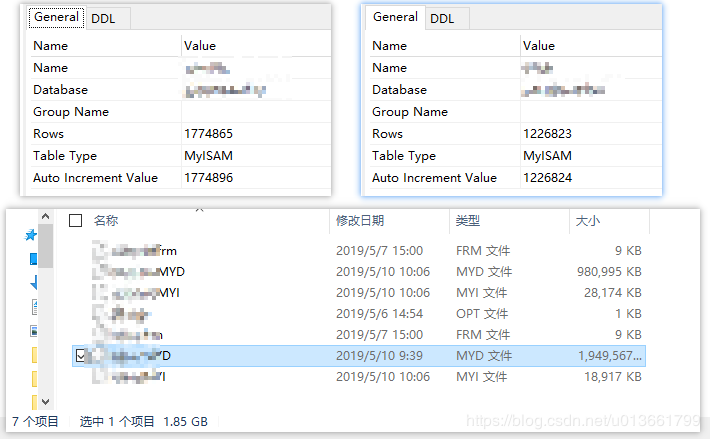
使用查询语句非常之慢,而且我要经常使用到"LIKE",一条语句返回结果耗时 10~30 秒,这可不行。所以决定把数据迁移到 ES。真的是踩坑了,本来只想简单搞搞,结果搞了好多天。
本文章介绍两种迁移方式:go-mysql-elasticsearch 和 logstash。以下是相关实践过程。
0.1. 先说go-mysql-elasticsearch
一开始发现了 go-mysql-elasticsearch 这个工具,也是go写的,不过对ES的支持版本比较旧。于是我就把ES换成了旧版本。(新的ES版本就用logstash方式吧)
0.1.1. 环境
# 主要组件
mysql : 5.5.3
elasticsearch : 5.6.16
go-mysql-elasticsearch
# 环境
windows 10
go : 1.11.2
同时也会用到 win 下 git 的命令行模式(可以运行 bash 命令)
go-mysql-elasticsearch对 mysql 和 ES 的要求为:
MySQL supported version < 8.0
ES supported version < 6.0
0.1.2. 部署
mysql 和 elasticsearch 安装很简单,这里就不说明了。这里主要说 go-mysql-elasticsearch 的安装过程。
go get github.com/siddontang/go-mysql-elasticsearch
cd到目录下,我的 go mod 不好用,所以我直接使用 go get 安装。
go get github.com/juju/errors
go get github.com/pingcap/check
go get github.com/siddontang/go/sync2
go get github.com/siddontang/go-mysql
go get github.com/pingcap/errors
go get github.com/shopspring/decimal
go get github.com/siddontang/go-log/log
修改代码中的一处错误。(应该是版本原因导致的)
文件:river/river.go
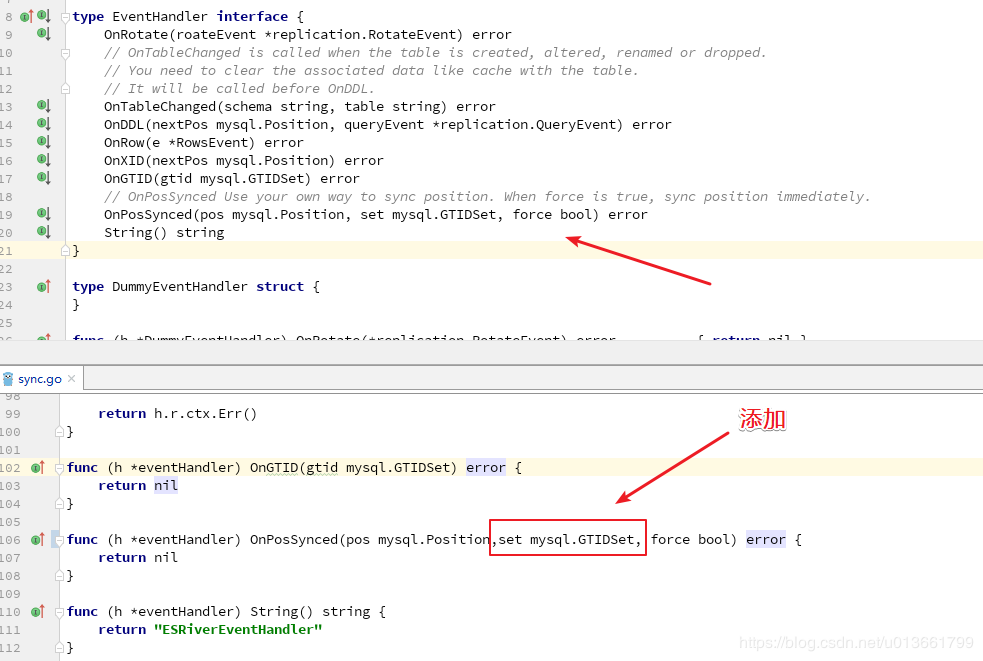
编译:
go build -o bin/go-mysql-elasticsearch ./cmd/go-mysql-elasticsearch
无报错,并看到有 bin/go-mysql-elasticsearch 文件即成功。
0.1.3. mysql 配置
文件:my.ini
添加以下配置并重启。
# Binary Logging
server-id=1
log_bin = mysql-bin
binlog_format = ROW
0.1.4. river.toml配置
文件:etc/river.toml
其中有两个关键的配置Source和rule。
[[rule]]
schema = "mysql_es" # Mysql数据库名
table = "test_table" # Mysql表名
index = "test_index" # ES中index名
type = "doc" # 文档类型
这一部分看官方示例就很清楚了 river.toml 和 Elasticsearch最佳实践从Mysql到Elasticsearch
0.1.5. mysqldump 配置
etc/river.toml 中有一处对于mysqldump的配置,只要把 mysql 的 bin 目录加到环境变量就可以了。但我这里还是找不到mysqldump,所以我就直接到mysqldump.exe拷贝到go-mysql-elasticsearch目录下就可以了。
0.1.6. 启动
./bin/go-mysql-elasticsearch -config=./etc/river.toml
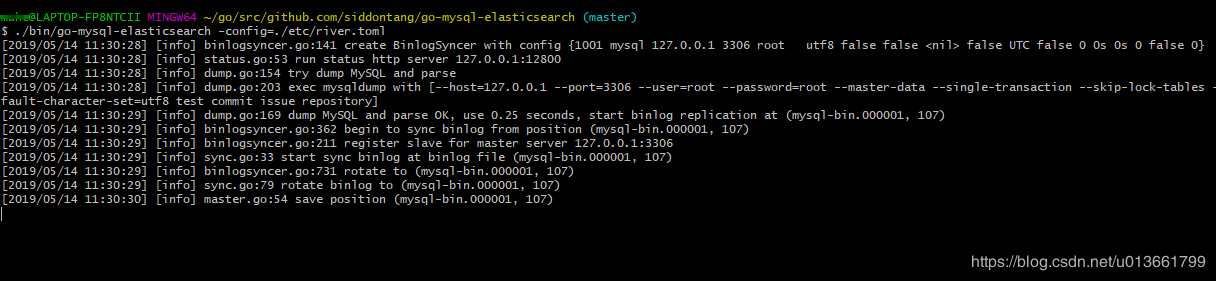
如上即为正常运行。
0.1.7. es查询数据量
# 查询各索引情况
curl -X GET "localhost:9200/_cat/indices?v"
# 查询数量
curl -X GET "localhost:9200/_cat/count?v"
# 查询某index的文档数量
curl -X GET "localhost:9200/_cat/count/index_name?v"
# 查询前1000条数据
curl -X GET "localhost:9200/test/_search?size=1000"
0.2. 使用 Logstash 进行数据迁移
ES : 7.0.1
Kibana : 7.0.1
Logstash : 7.0.1
我的 ES/Kibana 在windows 下,logstash 在centos下。
因为我在 windows 启动 logstash 后一直报错,[2019-05-15T11:55:00,183][ERROR][logstash.inputs.jdbc ] Failed to load C:/setup/mysql-connector-java-5.1.47/mysql-connector-java-5.1.47-bin.jar ,各种尝试最后报错依然存在,只好换用centos部署 logstash了。
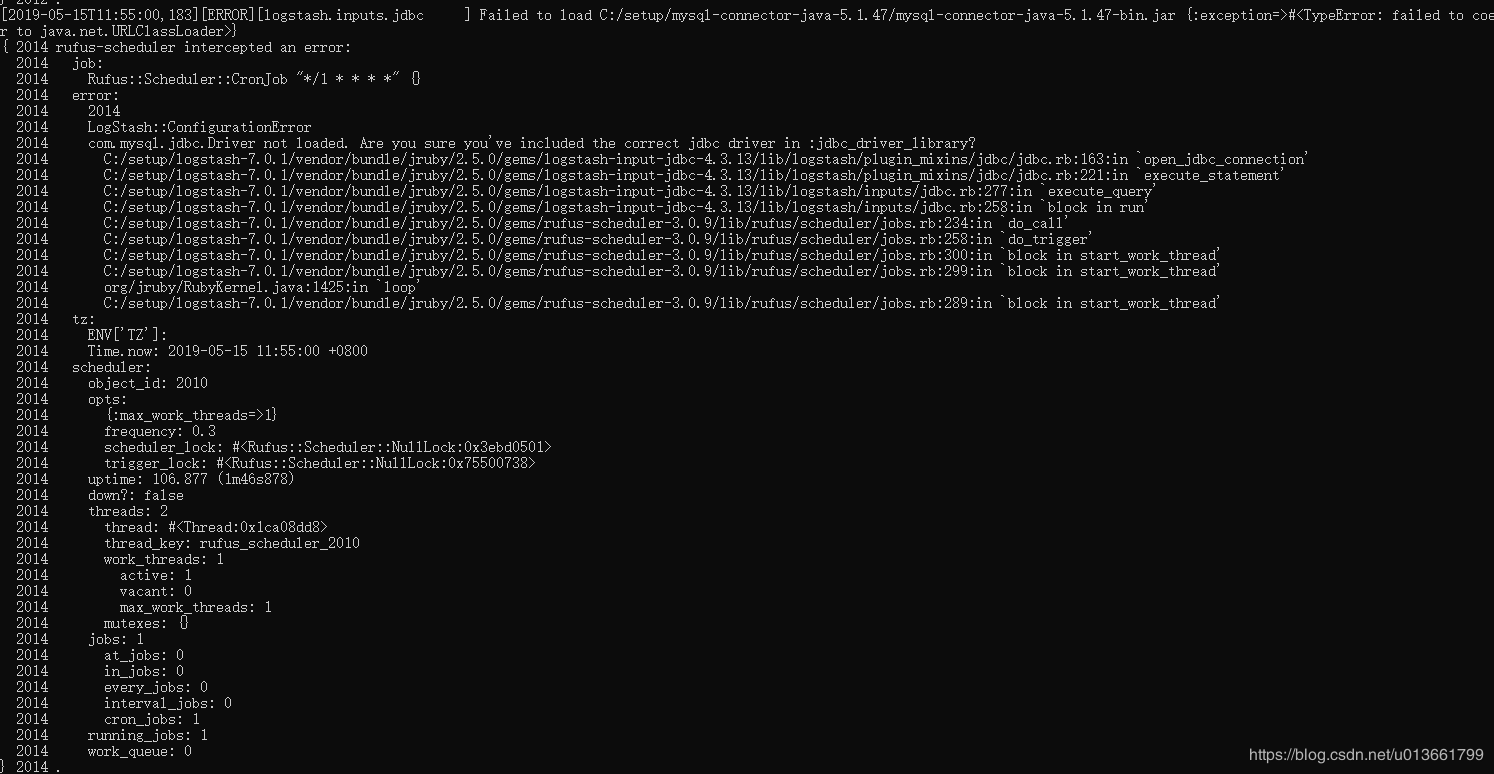
0.2.1. 安装部署
安装 jdbc 和 elasticsearch 插件
./bin/logstash-plugin install logstash-input-jdbc
./bin/logstash-plugin install logstash-output-elasticsearch
获取 jdbc mysql 驱动
0.2.2. 配置
配置jdbc.conf,使用时自行把下面注释去掉。
input {
stdin {
}
jdbc {
# mysql相关jdbc配置
jdbc_connection_string => "jdbc:mysql://192.168.31.134:3306/test"
jdbc_user => "root"
jdbc_password => "root123"
# jdbc连接mysql驱动的文件目录,可去官网下载:https://dev.mysql.com/downloads/connector/j/
jdbc_driver_library => "/home/mt/Desktop/mysql-connector-java-5.1.47/mysql-connector-java-5.1.47-bin.jar"
# the name of the driver class for mysql
jdbc_driver_class => "com.mysql.jdbc.Driver"
jdbc_paging_enabled => "true"
jdbc_page_size => "50000"
# mysql文件, 也可以直接写SQL语句在此处,如下:
# statement => "SELECT * from Table_test;"
# statement_filepath => "C:/setup/logstash-7.0.1/config/myconfig/jdbc.sql"
statement => "SELECT * FROM table WHERE id >= :sql_last_value"
# 这里类似crontab,可以定制定时操作,比如每10分钟执行一次同步(分 时 天 月 年)
schedule => "*/1 * * * *"
type => "jdbc"
# 是否记录上次执行结果, 如果为真,将会把上次执行到的 tracking_column 字段的值记录下来,保存到 last_run_metadata_path 指定的文件中
record_last_run => "true"
# 是否需要记录某个column 的值,如果record_last_run为真,可以自定义我们需要 track 的 column 名称,此时该参数就要为 true. 否则默认 track 的是 timestamp 的值.
use_column_value => "true"
# 如果 use_column_value 为真,需配置此参数. track 的数据库 column 名,该 column 必须是递增的. 一般是mysql主键
tracking_column => "id"
last_run_metadata_path => "/home/mt/Desktop/logstash-7.0.1/myconf/last_id"
# 是否清除 last_run_metadata_path 的记录,如果为真那么每次都相当于从头开始查询所有的数据库记录
clean_run => "false"
# 是否将 字段(column) 名称转小写
lowercase_column_names => "false"
columns_charset => {
"message"=> "UTF-8"
"name"=> "UTF-8"
}
}
}
# 此处我不做过滤处理,如果需要,也可参考elk安装那篇
filter {}
output {
# 输出到elasticsearch的配置
# 注意这里对type判断,若加载多个配置文件,要有这个判断才不会互相影响
if[type] == "jdbc" {
elasticsearch {
hosts => ["192.168.31.45:9200"]
index => "test"
# 将"_id"的值设为mysql的autoid字段
# 注意这里的id,如果多个表输出到同一个index,它们的id有重复的,则这里的 document_id 要修改成不重复的,否则会覆盖数据
document_id => "%{id}"
template_overwrite => true
}
}
# 这里输出调试,正式运行时可以注释掉
stdout {
codec => json_lines
}
}
启动:
./bin/logstash -f ./myconf/jdbc.conf
0.2.3. 问题与解决
问题:编码错误
[2019-05-15T21:38:10,051][ERROR][logstash.outputs.elasticsearch] An unknown error occurred sending a bulk request to Elasticsearch. We will retry indefinitely {:error_message=>"\"\\xE8\" from ASCII-8BIT to UTF-8", :error_class=>"LogStash::Json::GeneratorError", :backtrace=>["/home/mt/Desktop/logstash-7.0.1/logstash-core/lib/logstash/json.rb:27:in `jruby_dump'", "/home/mt/Desktop/logstash-7.0.1/vendor/bundle/jruby/2.5.0/gems/logstash-output-elasticsearch-10.0.2-java/lib/logstash/outputs/elasticsearch/http_client.rb:119:in `block in bulk'", "org/jruby/RubyArray.java:2577:in `map'", "/home/mt/Desktop/logstash-7.0.1/vendor/bundle/jruby/2.5.0/gems/logstash-output-elasticsearch-10.0.2-java/lib/logstash/outputs/elasticsearch/http_client.rb:119:in `block in bulk'", "org/jruby/RubyArray.java:1792:in `each'", "/home/mt/Desktop/logstash-7.0.1/vendor/bundle/jruby/2.5.0/gems/logstash-output-elasticsearch-10.0.2-java/lib/logstash/outputs/elasticsearch/http_client.rb:117:in `bulk'", "/home/mt/Desktop/logstash-7.0.1/vendor/bundle/jruby/2.5.0/gems/logstash-output-elasticsearch-10.0.2-java/lib/logstash/outputs/elasticsearch/common.rb:286:in `safe_bulk'", "/home/mt/Desktop/logstash-7.0.1/vendor/bundle/jruby/2.5.0/gems/logstash-output-elasticsearch-10.0.2-java/lib/logstash/outputs/elasticsearch/common.rb:191:in `submit'", "/home/mt/Desktop/logstash-7.0.1/vendor/bundle/jruby/2.5.0/gems/logstash-output-elasticsearch-10.0.2-java/lib/logstash/outputs/elasticsearch/common.rb:159:in `retrying_submit'", "/home/mt/Desktop/logstash-7.0.1/vendor/bundle/jruby/2.5.0/gems/logstash-output-elasticsearch-10.0.2-java/lib/logstash/outputs/elasticsearch/common.rb:38:in `multi_receive'", "org/logstash/config/ir/compiler/OutputStrategyExt.java:118:in `multi_receive'", "org/logstash/config/ir/compiler/AbstractOutputDelegatorExt.java:101:in `multi_receive'", "/home/mt/Desktop/logstash-7.0.1/logstash-core/lib/logstash/java_pipeline.rb:235:in `block in start_workers'"]}
解决:
对各个字段设置字符集:
columns_charset => {
"message"=> "UTF-8"
"name"=> "UTF-8"
"payload"=> "UTF-8"
}
问题:加载多个配置文件进行数据迁移,有重复id
0.2.4. 加载多个配置文件
运行多个实例
创建一个配置文件的文件夹,使用-f命令加载此文件即可。
./bin/logstash -f ./myconf/
0.2.5. 长期运行的 logstash
想要维持一个长期后台运行的 logstash,你需要同时在命令前面加 nohup,后面加 &。
0.3. 资料
logstash mysql 准实时同步到 elasticsearch
logstash-input-jdbc同步mysql数据到elasticsearch
discuss.elastic.co/t/filter-er…
discuss.elastic.co/t/character…
