

学习本篇文章前如果你是个算法的初学者,建议查看本篇文章的上一章数据结构与算法的重温之旅(一)——复杂度分析来初步的了解时间复杂度。本系列所有文章的代码都是用JavaScript实现,之所以用JavaScript实现是因为它可以直接在浏览器宿主中运行代码,即在浏览器中按f12打开控制台,选择console按钮,在下面空白的文本框把本例的代码黏贴上去回车即可运行。方便各位同学学习和调试。
本博客的作者与csdn里的Tank_in_the_street是同一作者,转载文章时需声明,谢谢合作。
一、前言
上一篇文章主要是初步的入门了复杂度分析,包括讲了大O表示法、时间复杂度、空间复杂度和他们的复杂程度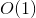 、
、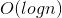 、
、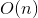 、
、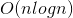 、
、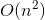 、
、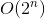 、
、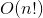 等,那么本章则进一步深入的时间复杂度里的最好情况时间复杂度(best case time complexity)、最坏情况时间复杂度(worst case time complexity)、平均情况时间复杂度(average case time complexity)和均摊时间复杂度(amortized time complexity)。
等,那么本章则进一步深入的时间复杂度里的最好情况时间复杂度(best case time complexity)、最坏情况时间复杂度(worst case time complexity)、平均情况时间复杂度(average case time complexity)和均摊时间复杂度(amortized time complexity)。
,而冒泡排序的时间复杂度是,但是如果数据是有序的情况下,快速排序的时间复杂度会去到,而冒泡排序的则会到,所以这个时候就要引入上面所说的概念。二、最好、最坏时间复杂度
在讲之前,我们先举个例子:
/**
* @param {string[]} arr
* @param {number} length
* @param {string} x
* @description length变量表示的是arr数组的长度,x则是一个字符串变量
**/
function test(arr, length, x) {
var i = 0
var pos = -1
for (; i < length; ++i) {
if (array[i] == x) {
pos = i
break
}
}
return pos
}
这个函数主要的功能就是遍历数组,直到找到数组内某个元素与变量x相等的时候则跳出循环。如果按照上一篇文章所说的,那它的时间复杂度则是,但是如果数组里第一个元素正好是和变量相等,则不需要遍历后面n-1个数据了,这时的时间复杂度就是,但是如果这个元素恰好在最后或者是根本都不在数组的时候,则要遍历完整个数组,这个时候的时间复杂度则是。所以本例进一步的阐述了上面所说的结论:不同情况下,相同代码的时间复杂度是不一样的。
有时候为了表示代码在不同情况下的不同时间复杂度,我们这里需要引入两个概念:最好情况时间复杂度和最坏情况时间复杂度。什么是最好情况时间复杂度,就是在最理想的情况下,执行代码的时间复杂度。上面所说的代码例子里最好情况的时间复杂度为。同理,最坏时间复杂度则是在最坏情况下,执行代码的时间复杂度。上面所说的代码例子里最坏情况的时间复杂度为。
三、平均时间复杂度
上面所说的最好时间复杂度和最坏时间复杂度都是极端情况下才会出现的情况,本身极端情况出现的概率并不是很大,所以为了更好地表示平均情况下的时间复杂度,这里引入一个概念叫平均情况时间复杂度,简称平均时间复杂度。
平均时间复杂度的分析是这样的,我们要查找与变量x相同的元素,总共有n+1种情况:在数组的0到n-1位置种和不在数组中,我们把每种情况给累加起来,最后除以总数n+1,即可得到需要遍历元素个数的平均值,公式如下:
首先说明一下这个公式,这个公式左边分子部分表示的是最好+最坏+剩余的普通情况,之所以后面才会加多一个n,是因为最坏情况有两种情况,一种是目标值刚好在数组最后,另一种情况则是不在数组的情况。
通过上一篇文章所说在复杂度分析中可以忽略掉常量、低阶和系数,得出来的时间复杂度则是O(n)。
虽然这条式子看起来没错,但是这里每种情况出现的概率是不一样的,首先这个与x相等的元素值可能不在这个数组,也有可能可能在数组种,所以在数组种和不在数组中的概率是1/2。另外假设该元素在数组0到n-1中的概率是相同的,则概率为1/n,所以我们可得当前目标值在数组任意位置的概率是1/2n,因此经过充分考虑后,我们的公式是这样子的:
这个值就是概率论中的加权平均值,也叫做期望值,所以平均时间复杂度的全称也叫加权平均时间复杂度或者期望时间复杂度。利用刚刚讲的去掉常量和系数之后,得到的时间复杂度仍然为O(n)。
四、均摊时间复杂度
讲到现在,上面讲到的三种方法是比较常用的时间复杂度分析方法,下面则要讲的是更加进阶的概念:均摊时间复杂度。在讲本例之前先举个代码例子:
var array = new Array(10)
var count = 0
function insert(val) {
if (count == array.length) {
var sum = 0;
for (var i = 0; i < array.length; ++i) {
sum = sum + array[i];
}
array[0] = sum;
count = 1;
}
array[count] = val;
++count;
}
我先来解释一下这段代码。这段代码实现了一个往数组中插入数据的功能。当数组满了之后,也就是代码中的 count == array.length 时,我们用 for 循环遍历数组求和,将求和之后的 sum 值放到数组的第一个位置,然后再将新的数据插入。但如果数组一开始就有空闲空间,则直接将数据插入数组。
那本程序的时间复杂度是多少呢?理想情况下就是count不等于array.length的情况,这个时候的时间复杂度则是O(1),最坏的情况则是count等于array.length的时候,时间复杂度为O(n)。那平均时间复杂度是多少呢,答案是O(1)。下面论证来说明:
假设数组的长度为n,根据数组插入的位置的不同,我们可以分为n种情况,每种情况的时间复杂度为O(1),除此之外,还有一个额外情况就是count等于array.length的情况时,时间复杂度为O(n)。并且这n+1种情况发生的概率都一样,都是1/(n+1),所以通过加权平均,得到的公式如下:
这里通过之前所说忽略掉常数和系数,则平均时间复杂度为O(1)。其实在这里可以通过另一种逻辑方法来分析平均时间复杂度,我们先对比本篇文章的两个函数,一个test函数一个insert函数。
首先test函数在极端情况下时间复杂度才为O(1),而insert函数在大多数情况的时间复杂度都为O(1),只有极端情况下当count等于array.length时才会执行一次循环累加操作。其次就是不同的地方。对于 insert(函数来说,O(1) 时间复杂度的插入和 O(n) 时间复杂度的插入,出现的频率是非常有规律的,而且有一定的前后时序关系,一般都是一个 O(n) 插入之后,紧跟着 n-1 个 O(1) 的插入操作,循环往复。
针对这种特殊场景,我们引入了一种更加简单的分析方法:均摊分析法。通过均摊分析法得到的时间复杂度叫做均摊时间复杂度。那究竟如何使用摊还分析法来分析算法的均摊时间复杂度呢?
我们还是继续看在数组中插入数据的这个例子。每一次 O(n) 的插入操作,都会跟着 n-1 次 O(1) 的插入操作,所以把耗时多的那次操作均摊到接下来的 n-1 次耗时少的操作上,均摊下来,这一组连续的操作的均摊时间复杂度就是 O(1)。这就是均摊分析的大致思路。
对一个数据结构进行一组连续操作中,大部分情况下时间复杂度都很低,只有个别情况下时间复杂度比较高,而且这些操作之间存在前后连贯的时序关系,这个时候,我们就可以将这一组操作放在一块儿分析,看是否能将较高时间复杂度那次操作的耗时,平摊到其他那些时间复杂度比较低的操作上。而且,在能够应用均摊时间复杂度分析的场合,一般均摊时间复杂度就等于最好情况时间复杂度。我个人认为:均摊时间复杂度是一种特殊的时间复杂度。
五、总结
通过上面所讲的最好时间复杂度、最坏时间复杂度、平均时间复杂度和均摊时间复杂度,之所以会用到这四个概率,是因为同一段代码,在不同输入的情况下,复杂度量级有可能是不一样的。最后通过今天的学习,我们来分析一下下面代码的各种时间复杂度:
// 全局变量,大小为 10 的数组 array,长度 len,下标 i。
var array = new Array(10)
var len = 10;
var i = 0;
// 往数组中添加一个元素
function add(element) {
if (i >= len) { // 数组空间不够了
// 重新申请一个 2 倍大小的数组空间
var new_array = new Array(len*2);
// 把原来 array 数组中的数据依次 copy 到 new_array
for (var j = 0; j < len; ++j) {
new_array[j] = array[j];
}
// new_array 复制给 array,array 现在大小就是 2 倍 len 了
array = new_array;
len = 2 * len;
}
// 将 element 放到下标为 i 的位置,下标 i 加一
array[i] = element;
++i;
}
这里我们可以看出,最好时间复杂度肯定是O(1),即i小于len的时候,最坏时间复杂度是O(n),即i大于等于len的时候。平均时间复杂度是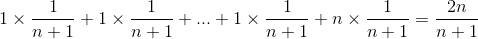 ,这里跟上面的insert函数例子类似。均摊时间复杂度也是O(1),因为n-1次情况下都是时间复杂度为O(1),只有n时才是时间复杂度为O(n)。
,这里跟上面的insert函数例子类似。均摊时间复杂度也是O(1),因为n-1次情况下都是时间复杂度为O(1),只有n时才是时间复杂度为O(n)。
上一篇文章:数据结构与算法的重温之旅(一)——复杂度分析
下一篇文章:数据结构与算法的重温之旅(三)——数组
