

大约1年前,我的团队开始了一个新的项目。这次我们想使用我们之前项目的所有知识。其中一个决定就是:我们想将整个 model API 异步化。这将允许我们在不影响 APP 其余部分的情况下,改变整个 model 的实现。如果我们的 APP 可以去处理异步调用,那么我们就不需要关心是否与后端通信、是否缓存数据到数据库了(译者注:因为是异步调用,所以我们不用担心网络加载、缓存到数据库的操作阻塞了主线程)。它也能使我们实现并发。
作为开发者,我们必须去理解并行(parallelism)和并发(concurrency)的含义。否则,我们可能会犯一些很严重的错误。现在,让我们一起学习如何并发编程吧!
同步 vs 异步
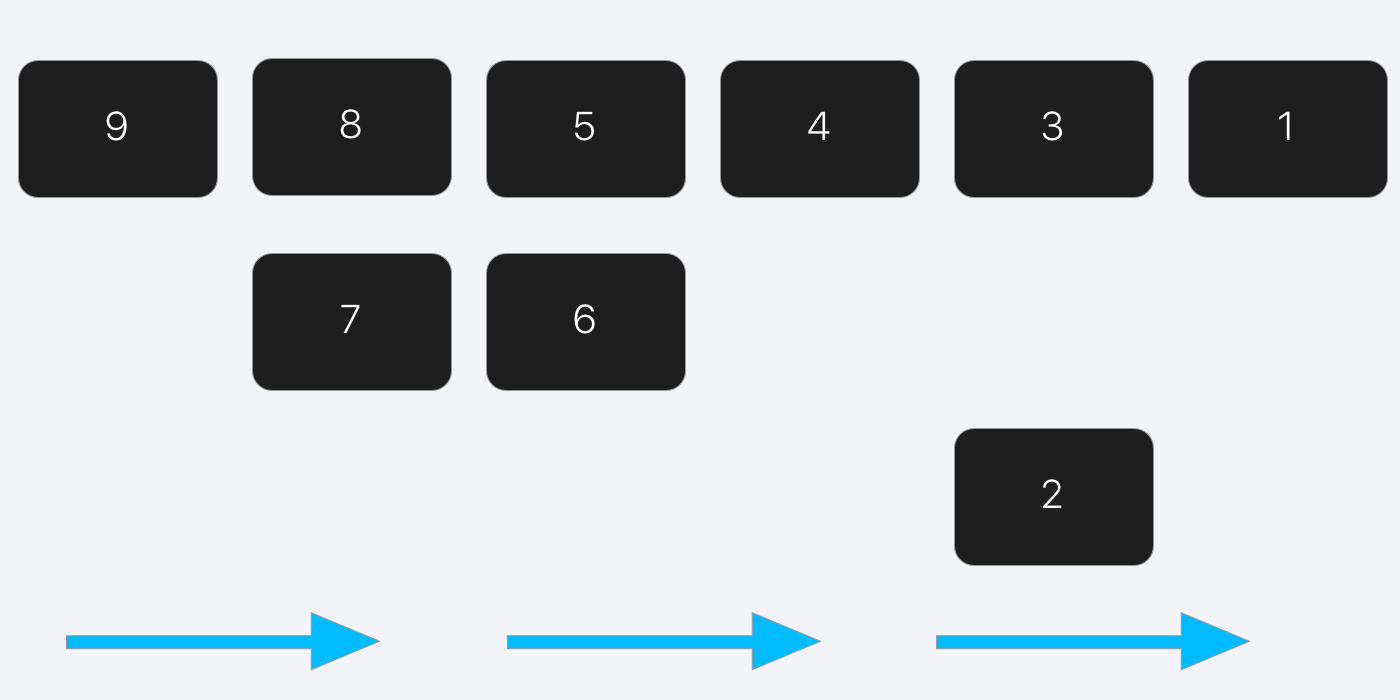
那么,同步和异步到底有什么不同之处呢?假设我们有一堆item,当对这些item进行同步处理的时候,我们先从第一个item开始,然后再完成第二个,以此类推。它的执行顺序和FIFO( First In,First Out )的队列是一样的,先进先出。

转换为代码:method1()的每个语句按顺序执行。
// 执行顺序 statement1() -> statement2() -> statement3() -> statement4()
func method1() {
statement1()
statement2()
statement3()
statement4()
}
所以,同步意味着:一次只能完成一个item。
相比之下,异步处理可以在同时处理多个item。例如:它会处理item1,然后暂停item1,处理item2,然后继续并完成item1。
用一个简单的callback来举个栗子,我们可以看到statement2会在执行callback之前执行。
func method2() {
statement1 {
callback1()
}
statement2
}
//译者注:如我们常用的URLSession
func requestData() {
URLSession.shared.dataTask(with: URL(string: "https://www.example.com/")!) { (data, response, error) in
DispatchQueue.main.async {
print("callback")
}
}.resume()
print("statement2")
}
requestData()
//打印顺序 statement2 callback
并发与并行 ( Concurrency vs Parallelism )
并发与并行通常可以互换使用(即使Wiki百科也有用错的地方。。),这就导致了一些问题,如果我们能清晰的知道两者的含义的话,我们就可以避免这些问题。让我们举例说明:
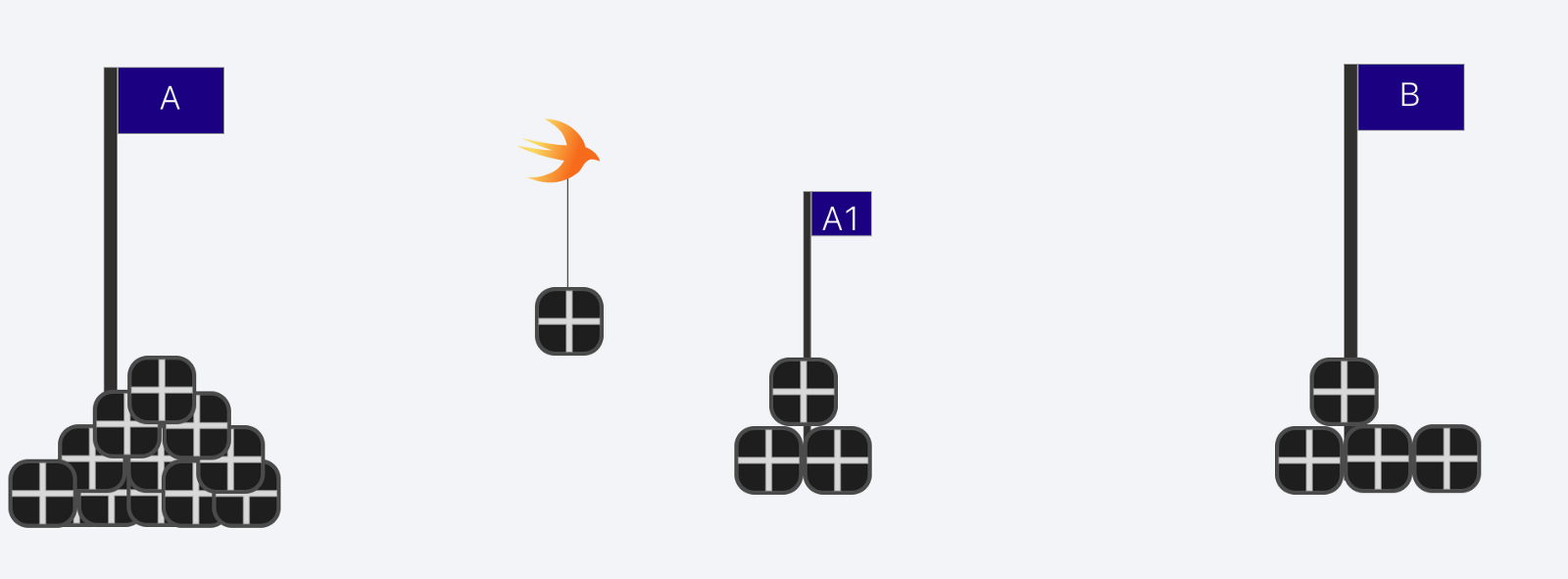
试想一下:我们有一堆盒子,需要从A点运送到B点。我们可以使用工人完成这项工作。在同步环境下,我们只能用1个工人去做这件事情,他从A点拿起一个盒子,到B点放下盒子。

如果我们要是同时能雇佣多个工人,他们将同时工作,从A点拿起一个盒子,到B点放下盒子。很明显,这将极大的提升我们的效率。只要至少2位工人同时运输盒子,他们就是在做并行处理。
并行就是同时进行工作。

如果我们只有一个工人,我们想让他多做几件事,那么发生什么呢?那么我们就应该考虑在处理状态下有多个盒子了。这就是并发的含义,它就好比把从 A 点到 B 点的距离分割为几步,工人可以从 A 点拿一个盒子,走到一半放下盒子,再回到 A 点去拿另一个盒子。
使用多个工人我们可以让他们都带有不同距离的盒子。这样我们可以异步处理这些盒子。如果我们有多个工人那么我们可以并行处理这些盒子。
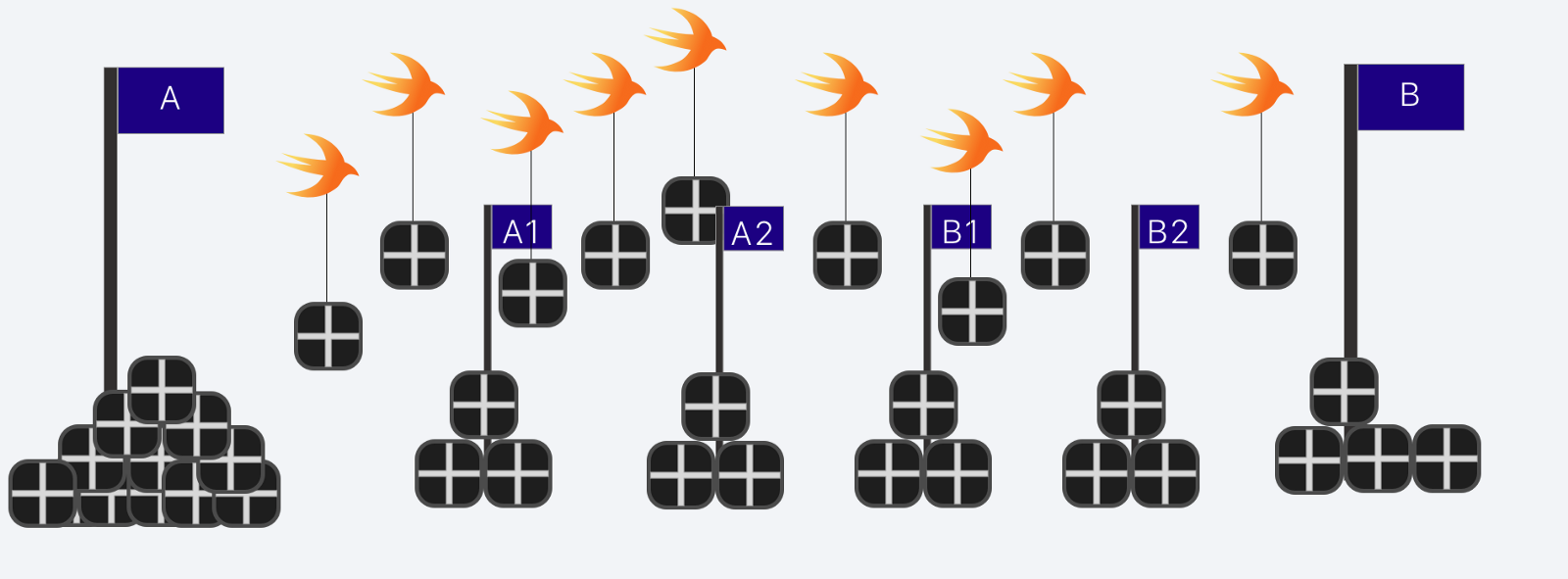
现在,并行和并发的区别就比较明了了。并行指的是同时进行工作;并发指的是同时工作的选择,它可以使并行,也可以不是。我们大多数的电脑和手机设备可以进行并行处理(取决于它是几核的),但是软件肯定是并发工作的。
并发机制
不同的操作系统提供不同的工具供你使用并发。在iOS,我们默认的工具: 进程和线程,由于OC的历史原因,也有 Dispatch Queues。
进程( Process )
进程是你 app 的实例。它包含执行你 App 所需的所有的东西,具体包含:你的栈、堆和所有的资源。
尽管 iOS 是一个多任务的 OS ,但是它不支持一个 App 使用多个进程,因此你只有一个进程。但是 MAC OS 不同,你可以使用 Process 类去创建新的子进程。 它们与父进程无关,但包含父进程创建子进程时父进程所拥有的所有信息。如果您正在使用macOS,这里是创建和执行进程的代码:
let task = Process()
task.launchPath = "/bin/sh" //executable you want to run
task.arguments = arguments //here is the information you want to pass
task.terminationHandler = {
// do here something in case the process terminates
}
task.launch()
线程 ( Thread )
thread 类似于轻量级的进程。相比于进程 ,线程在它们的父进程中共享它们的内存。这样就会导致一些问题,比如两个线程同时改变一个变量。当我们再次读取改变量的值得时候,我们会得到无法预知的值。在 iOS (或者其他符合 POSIX 的系统)中,线程是被限制的资源,一个进程同时最多有用64个线程。你可以像这样创建并执行线程:
class CustomThread: Thread {
override func main() {
do_something
}
}
let customThread = CustomThread()
customThread.start()
Dispatch Queues
由于我们只有一个进程并且最多只能使用64个线程,所以必须使用其他的方法去使代码进行并发处理。 Apple 的解决方案就是 dispatch queue 。你可以向 dispatch queue 中添加任务,然后期待在某一时刻被执行。 dispatch queue 有不同的类型:
- SerialQueue:串行队列,它会顺序执行该队列的任务。
- ConcurrentQueue:并发队列,它会并发执行该队列的任务。
这不是真正的并发,对吧?尤其是串行队列,我们的效率并没有任何的提高。并发队列也没有使任何事情变得容易。我们确实拥有线程,所以重点是什么?
让我们考虑一下,如果我们有多个队列会发生什么呢。我们可以在线程上运行多个队列,然后在我们需要的时候向其中一个队列添加任务。让我们开一下脑洞,我们甚至可以根据优先级和当前工作量来分发需要添加的任务,从而优化我们的系统资源。
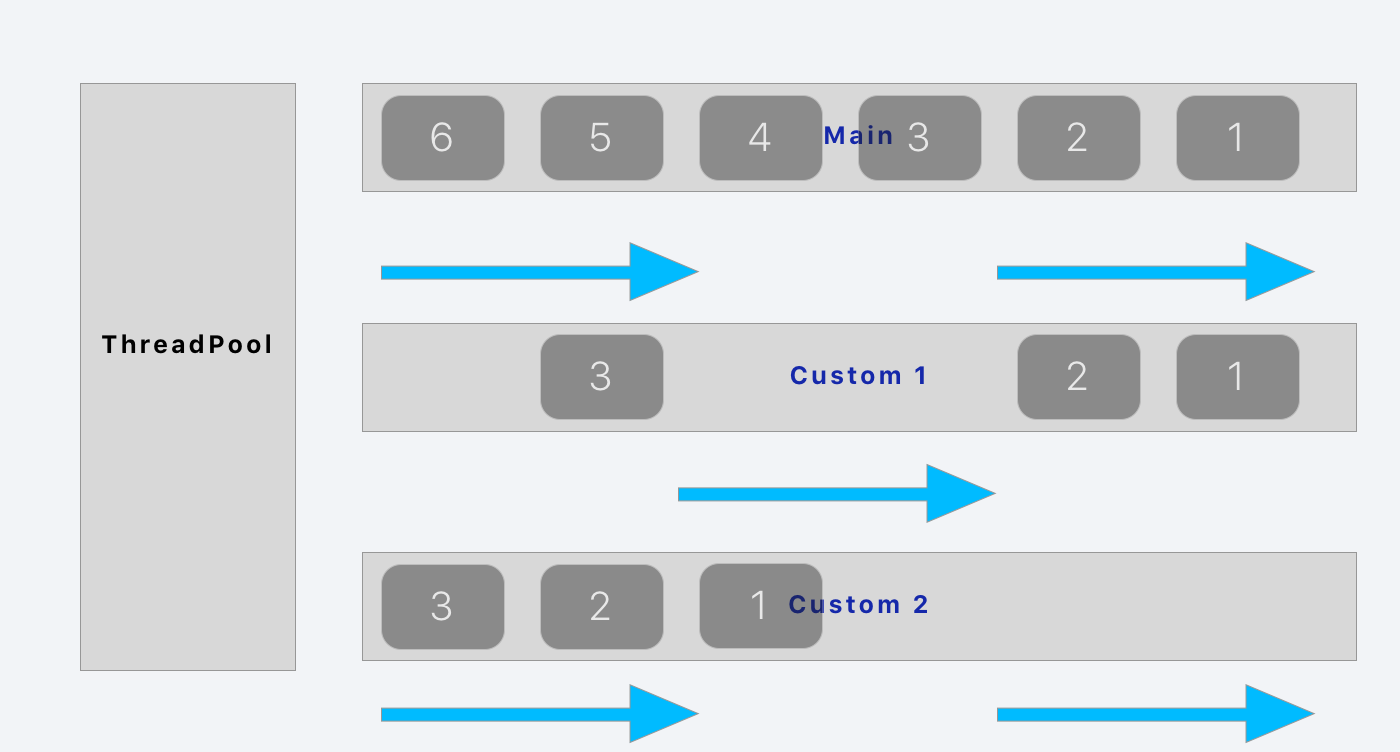
Apple 把上述的实现称为 Grand Central Dispatch ,简称 GCD 。在 iOS 它具体是如何操作呢?
DispatchQueue.main.async {
// execute async on main thread
}
GCD 最大的优点就是:它改变了并发编程的思维模型。你使用它的时候不需要考虑 thread ,你只需要把你需要执行的任务添加到不同的队列中,这使并发编程变得更加容易。
Operation Queues
Operation Queue 是 Cocoa 对 GCD 的更高一级的抽象。你可以创建 operation 而不是一些 block 块。它将把 operation 添加到队列中,然后按照正确的顺序执行它们。关于队列分别有以下类型:
- main queue:主队列,在主线程执行。
- custom queue:自定义队列,不在主线程执行。
let operationQueue: OperationQueue = OperationQueue()
operationQueue.addOperations([operation1], waitUntilFinished: false)
你可以通过 block 或者子类的方式来创建 operation 。如果你使用子类的方式创建,不要忘记调用 finish ,如果忘记调用,则 operation 将会一直执行。
class CustomOperation: Operation {
override func main() {
guard isCancelled == false else {
finish(true)
return
}
// Do something
finish(true)
}
}
operation 的优势就是你可以使用依赖,如果 A 依赖于 B 的结果,那么在得到 B 的结果之前, A 不会被执行。
//execute operation1 before operation2
operation2.addDependency(operation1)
Run Loops
Run Loop 跟队列类似。系统队列运行所有的工作,然后在开始的时候重启,例如:屏幕重绘,通过 Run Loop 完成。这里我们需要注意一点,它们不是真正的并发方法,它们是在一个线程上运行的。它可以使你的代码异步执行,同时减去你考虑并发的负担。不是每个线程都有 Run Loop ,主线程的 Run Loop 是默认开启的,子线程的 Run Loop 需要手动创建。
当你使用 Run Loop 的时候,你需要考虑在不同 mode 下的情况。举个栗子,当你滑动你的设备的时候,主线程的 Run Loop 会改变并延时所有进入的事件,当你停止滑动的时候, Run Loop 将会切换为默认的 mode ,然后处理事件。input source 对 Run Loop 来说是必要的,否则,每个执行操作都会立刻结束。所以不要忘了这个点。
Lightweight Routines
关于真正轻量级的线程有一个新的想法,但是它还没有被 Swift 实现。详情可以点击这里。
控制并发的选项 (Options to control Concurrency)
我们研究了由操作系统提供的所有不同的元素,这些元素可以创建并发。但是如上所述,这也会造成很多问题。最容易碰到的同时也是最难识别的问题就是:多个并发任务同时访问同一资源。如果没有机制去处理这些访问,则可能一个任务写入一个值。当第一个任务读取这个值的时候,它期待的是自己写入的那个值,而不是其他任务写入的值。所以,默认的方法是锁住资源的访问来阻止其他线程在资源锁定的时候来访问它。
优先级反转 (Priority Inversion)
在了解各种锁机制之间的不同之处之前,我们需要先了解一下线程优先级。正如你所想的,线程可以设置高优先级和低优先级,这意味着高优先级的会比低优先级的先执行。当一个低优先级的线程锁住一个资源的时候,如果一个高优先级的线程来访问该资源,高优先级的线程必须等解锁,这样低优先级的线程的优先级就会增加。这就叫做优先级反转,但这会导致高优先级的线程一直等待,因为它永远不会被执行。所以我们需要注意避免造成这种情况。
想象一下,你现在有两个高优先级的线程1、线程2和一个低优先级的线程3。如果线程3阻塞线程1访问资源,线程1必须去等待。因为线程2有更高的优先级,它的任务会被先执行完。在没有结束的情况下,线程3将不会被执行,因此线程1将被无限期地阻塞。
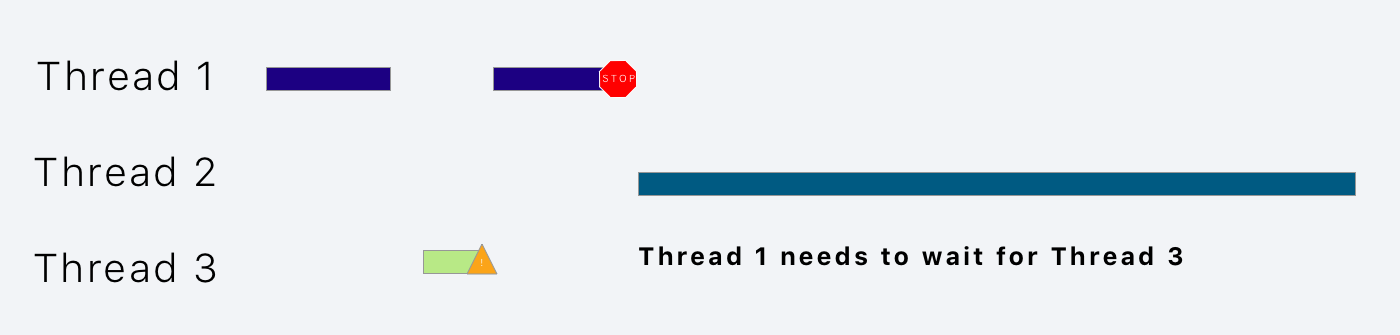
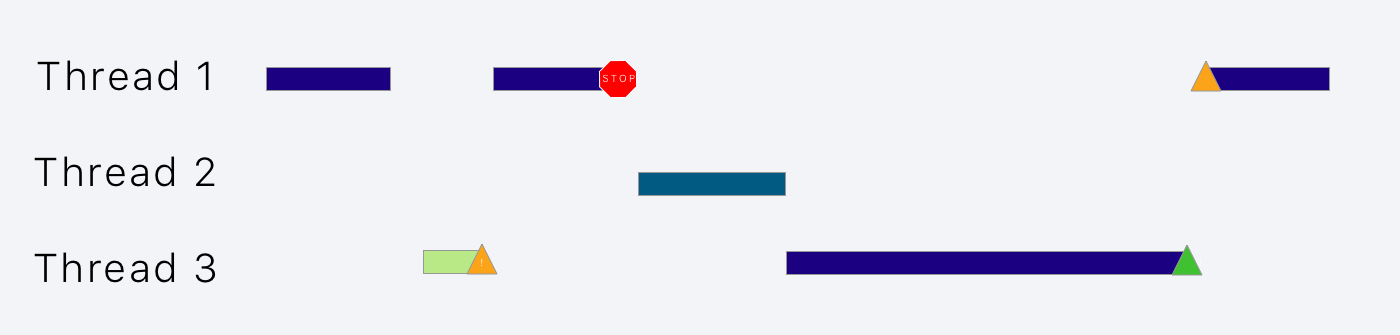
优先级继承
优先级反转的解决方案是优先级继承。在这种情况下,如果线程1被线程3阻塞,它会将自己的优先级交给线程3。所以线程3和线程2都有高优先级,可以一起执行(依赖于OS)。当线程3解锁资源的时候,再将优先级还给线程1,这样线程1将会继续原来的操作。
原子性 (Atomic)
原子性包含和数据库上下文中的事务相同的思想。你想一次性写入一个值,作为一个操作。32位编译的应用程序,在使用int64_t而没有原子性时,可能会有奇怪的行为。让我们详细看看发生了什么:
int64_t x = 0
Thread1:
x = 0xFFFF
Thread2:
x = 0xEEDD
非原子性的操作会造成在线程1中写入x,但是因为我们在32位系统上工作,我们不得不将写入的x分割成 0xFF。
当线程2决定在同一时间写入x的时候,会发生下面的操作进行:
Thread1: part1
Thread2: part1
Thread2: part2
Thread1: part2
最后我们会得到:
x == 0xEEFF
既不是 0xFFFF 也不是 0xEEDD。
使用原子性,我们创建一个单独的事务,会产生以下的行为:
Thread1: part1
Thread1: part2
Thread2: part1
Thread2: part2
结果是,x包含线程2设置的值。 Swift 本身没有实现 atomic 。你可以在这里添加一个建议,但是现在,你必须自己实现它。
锁
锁是一种简单的方法,用来阻止多个线程访问同一资源。首先检查线程是否可以进入被保护的部分,如果可以进入,它将锁住被保护的资源,然后进行该线程操作。等线程的操作执行完,它会解锁该资源。如果进入的线程碰到锁住的部分,它会等待解锁。这有点类似于睡眠和唤醒,以检查资源是否被锁。
在 iOS ,可以通过 NSLock 来实现这种机制。需要注意一点:你解锁的线程和你锁住的线程必须是同一线程。
let lock = NSLock()
lock.lock()
//do something
lock.unlock()
还有其他类型的锁,比如递归锁 (recursive lock) 。它可以多次锁住同一资源,并且必须在锁定的时候释放它。在这整个过程中,其它线程是被排除在外的。
还有一个就是读写锁 (read-write lock),对于需要大量线程读取,而不需要大量线程写入的大型 App ,这是很有效的一种机制。只要没有线程写入,则所有线程都可访问。只要有线程想写入,它将锁定所有线程的资源。在解锁之前所有线程都不能读取。
在进程级别,还有一个分布式锁 (distributed lock) 。不同之处在于,如果进程被阻止,它只会将其报告给进程,并且进程可以决定如何处理这种情况。
自旋锁( Spinlock )
锁由多个操作组成,这些操作使线程处于休眠状态,直到线程再次启动为止。这会导致 CPU 的上下文更改 (推送注册等等,去存储线程的状态)。这些改变需要很多计算时间,如果你有真正很小型的操作去保护,你可以使用自旋锁。它的基本思想就是只要线程在等待,就让它轮询锁( poll the lock )。这比休眠一个线程需要更多的资源。同时,它绕过了上线文的改变,所以在小型操作上更加快。
这个理论上听着不错,但是 iOS 总是出人意料。 iOS 有一个概念叫做 Quality of Service (QoS)。使用它,可能造成低优先级的线程根本不会执行的情况。在这样的线程上设置一个自旋锁,当一个更高优先级的线程试图访问它的时候,会造成高优先级的线程覆盖低优先级的线程,因此,无法解锁所需资源,从而导致阻塞自己。所以,自旋锁在 iOS 是非法的。
互斥 (Mutex)
互斥跟锁比较像,不同之处在于,它可以访问进程而不仅仅是访问线程。悲催的是你不得不自己实现它,Swift 不支持互斥。你可以使用 C 的pthread_mutex。
var m = pthread_mutex_t()
pthread_mutex_lock(&m)
// do something
pthread_mutex_unlock(&m)
信号量 (Semaphore)
信号量是一种支持线程同步中的互斥性的一种数据结构。它由计数器组成,是一个先进先出的队列,有wait()和signal()函数。
每当线程想要进入一个被保护部分的时候,它将会调用信号量的wait()。信号量将会减少它的计数,只要计数不为0,线程就可以继续。反之,它会将线程存储在它的队列里。当被保护部分离开一个线程的时候,它会调用signal()来通知信号量。信号量首先会检查,是否在队列中有等待的线程,如果有,它将唤醒线程,让它继续。如果没有,它将会再次增加它的计数。
在 iOS 中,我们可以使用 DispatchSemaphors 来实现这种行为。比起默认信号量,它更倾向于使用 DispatchSemaphors ,因为它们只在真正需要时才会下降到内核级别。否则,它的运行速度会快得多。
let s = DispatchSemaphore(value: 1)
_ = s.wait(timeout: DispatchTime.distantFuture)
// do something
s.signal()
有人认为二进制的信号量(计数为1的信号量)和互斥是一样的。但互斥是一种锁的机制,信号量是一种信号的机制。这个解释并没有什么帮助,所以它们到底有什么不同呢?
锁机制是关于保护和管理一个资源的访问,所以它会阻止多个线程同时访问一个资源。信号系统更像是"Hey 我完事了,继续!"。举个栗子:如果你拿你的手机正在听歌,这时候来了一个电话。当你通完电话,它将会给你的 player 发送一个通知让它继续。这是一个在互斥上考虑信号量的情况。
译者注:我猜测,放歌和听音乐是互斥的,因为你不可能接电话的时候还听着歌。在通话完成后,手机给player发送一个信号让它继续放歌,这是一个信号量的操作。
假如你有一个低优先级的线程1在受保护的区域,你还有一个高优先级的线程2被信号量调用wait()使其等待。此时线程2处于休眠状态等待信号量将其唤醒。此时,我们有一个线程3,优先级高于线程1。线程3会联合 Qos 来阻止线程1去通知信号量,因此而覆盖其他线程。所以 iOS 中的信号量并没有优先级继承。
同步 ( Synchronized )
在 OC 中,有一个@synchronized的关键字。这是创建互斥的简单方法。由于 Swift 不支持,我们不得不用更底层的方法:objc_sync_enter。
let lock = self
objc_sync_enter(lock)
closure()
objc_sync_exit(lock)
因为我在网上看到这个问题很多次,所以让我们回答一下。据我所知,这不是一个私有方法,所以使用它不会被 App Store 拒审。
并发队列派发 ( Concurrency Queues Dispatching )
由于 Swift 中没有 metux ,而且 synchornized 也被移除,所以使用 DispatchQueues 成了 Swift 开发者的黄金法则。当用它实现同步的时候,它与 metux 有相同的行为。因为所有操作都在同一队列中排队。这可以防止同时执行。

它的缺点是它的时间消耗大,它必须经常分配和改变上下文。如果你的 App 不需要任何高计算能力,这就无关紧要了。但是如果遇到帧丢失等问题,你可能就需要考虑别的方案了(例如 Mutex)。
Dispatch Barriers
如果你使用 GCD,你有很多办法来同步代码。其中一个就是 Dispatch Barriers。通过它,我们可以创建需要一起执行的被保护部分的 block 。我们也可以异步执行这些代码,这听起来很奇怪,但是假想一下,你有一个耗时的操作,它可以被分割为几个小任务。这些小任务可以被异步执行,当小任务都执行完,Dispatch Barriers 在去同步这些小任务。
译者注:比如将一张大图分割为几张小图异步下载,等小图都异步下载完,再同步为一张大图。
Trampoline
它并不是操作系统提供的一种机制。它是一种模式:用来确保方法在正确的线程被调用。它的思路很简单,在开始检查方法是否在正确的线程上,如果不在,它会在正确的线程上调用它自己并返回。有时,你需要使用上面锁的机制来实现等待程序。只有在调用方法有返回值的时候才会发生这种情况。否则,你可以简单的返回。
func executeOnMain() {
if !Thread.isMainThread {
DispatchQueue.main.async(execute: {() -> Void in
executeOnMain()
return
})
}
// do something
}
不要经常使用这种模式。虽然它可以确保你在正确的线程,但同时,它会使你的同事困惑。他们可能不理解你到处改变线程。某些时候,它会使你的代码 like shit,并且浪费你的时间去整理代码。
总结
Wow,这真是一篇工作量很大的文章。这里有如此多的技术可以实现并发编程,这篇文章只是浅尝辄止。当我在讨论并发的时候,大家都厌烦我,但是并发编程真的很重要,同事们也在慢慢的认可我。今天,我不得不修复一个数组异步的问题,我们知道 Swift 不支持原子性操作。你猜怎么着?这造成了一个崩溃。如果我们更加了解并发,可能就不会出现这个问题。但说实话,我之前也不知道这个。
我能给你最好的建议就是:知己知彼,百战不殆。综合上文所述,我希望你可以开始学习并发,能找到一种方法用来解决遇到的问题。一旦你更加深入,你就会越来越明了。Good Luck!
