

简介
Elasticsearch(简称ES)是一个分布式、可扩展、实时的搜索与数据分析引擎。ES不仅仅只是全文搜索,还支持结构化搜索、数据分析、复杂的语言处理、地理位置和对象间关联关系等。
ES的底层依赖Lucene,Lucene可以说是当下最先进、高性能、全功能的搜索引擎库。但是Lucene仅仅只是一个库。为了充分发挥其功能,你需要使用Java并将Lucene直接集成到应用程序中。更糟糕的是,您可能需要获得信息检索学位才能了解其工作原理,因为Lucene非常复杂——《ElasticSearch官方权威指南》。
鉴于Lucene如此强大却难以上手的特点,诞生了ES。ES也是使用Java编写的,它的内部使用Lucene做索引与搜索,它的目的是隐藏Lucene的复杂性,取而代之的提供一套简单一致的RESTful API。
总体来说,ES具有如下特点:
一个分布式的实时文档存储引擎,每个字段都可以被索引与搜索
一个分布式实时分析搜索引擎,支持各种查询和聚合操作
能胜任上百个服务节点的扩展,并可以支持PB级别的结构化或者非结构化数据
架构
节点类型
ES的架构很简单,集群的HA不需要依赖任务外部组件(例如Zookeeper、HDFS等),master节点的主备依赖于内部自建的选举算法,通过副本分片的方式实现了数据的备份的同时,也提高了并发查询的
ES集群的服务器分为以下四种角色:
master节点,负责保存和更新集群的一些元数据信息,之后同步到所有节点,所以每个节点都需要保存全量的元数据信息:
▫集群的配置信息
▫集群的节点信息
▫模板template设置
▫索引以及对应的设置、mapping、分词器和别名
▫索引关联到的分片以及分配到的节点
datanode:负责数据存储和查询
coordinator:
▫路由索引请求
▫聚合搜索结果集
▫分发批量索引请求
ingestor:
▫类似于logstash,对输入数据进行处理和转换
如何配置节点类型
一个节点的缺省配置是:主节点+数据节点两属性为一身。对于3-5个节点的小集群来讲,通常让所有节点存储数据和具有获得主节点的资格。
专用协调节点(也称为client节点或路由节点)从数据节点中消除了聚合/查询的请求解析和最终阶段,随着集群写入以及查询负载的增大,可以通过协调节点减轻数据节点的压力,可以让数据节点更多专注于数据的写入以及查询。
master选举
选举策略
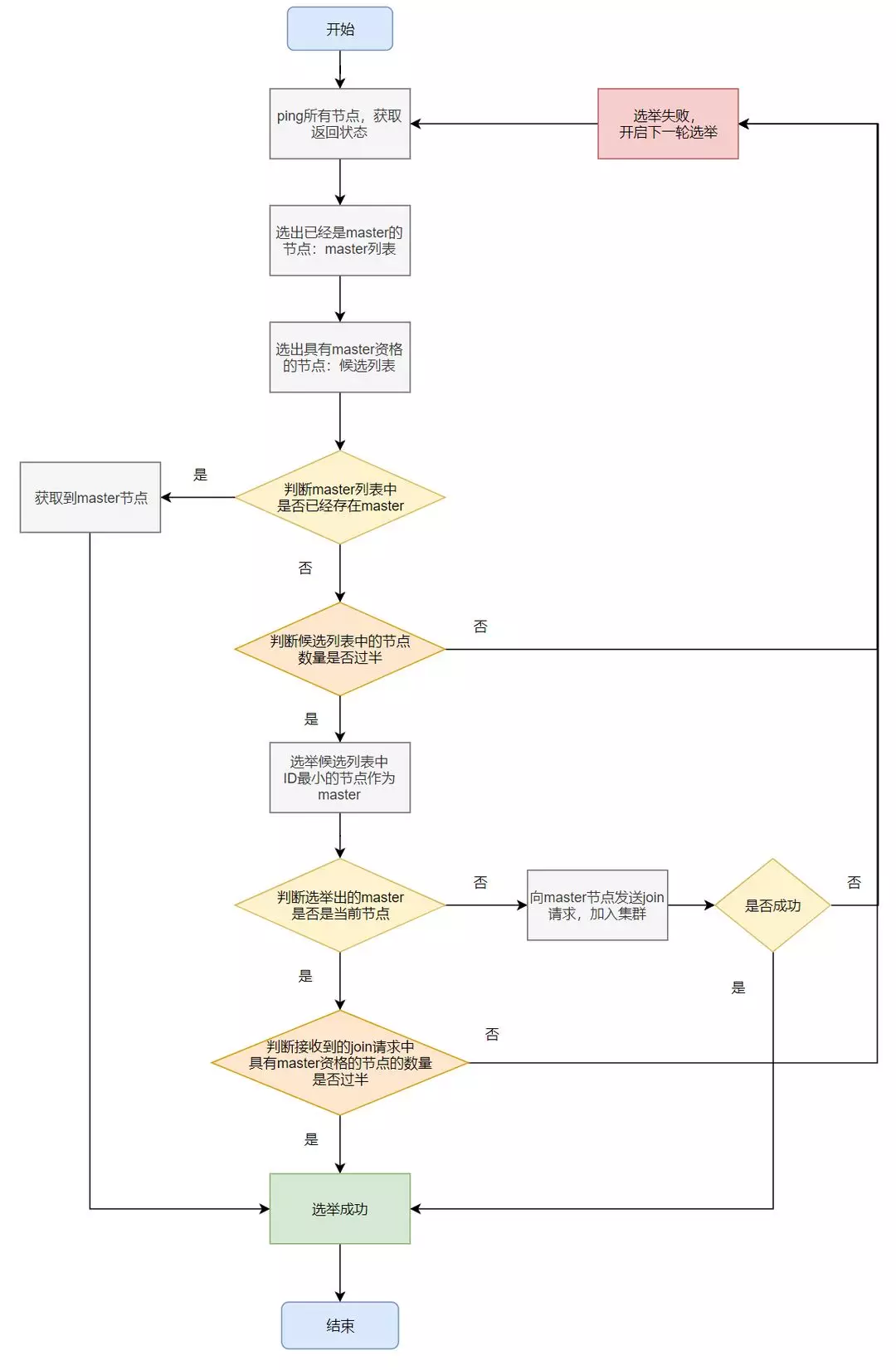
如果集群中存在master,认可该master,加入集群
如果集群中不存在master,从具有master资格的节点中选id最小的节点作为master
选举时机
集群启动:后台启动线程去ping集群中的节点,按照上述策略从具有master资格的节点中选举出master
现有的master离开集群:后台一直有一个线程定时ping master节点,超过一定次数没有ping成功之后,重新进行master的选举
选举流程
避免脑裂
脑裂问题是采用master-slave模式的分布式集群普遍需要关注的问题,脑裂一旦出现,会导致集群的状态出现不一致,导致数据错误甚至丢失。
ES避免脑裂的策略:过半原则,可以在ES的集群配置中添加一下配置,避免脑裂的发生
#一个节点多久ping一次,默认1sdiscovery.zen.fd.ping_interval: 1s##等待ping返回时间,默认30sdiscovery.zen.fd.ping_timeout: 10s##ping超时重试次数,默认3次discovery.zen.fd.ping_retries: 3##选举时需要的节点连接数,N为具有master资格的节点数量discovery.zen.minimum_master_nodes=N/2+1注意问题
配置文件中加入上述避免脑裂的配置,对于网络波动比较大的集群来说,增加ping的时间和ping的次数,一定程度上可以增加集群的稳定性
动态的字段field可能导致元数据暴涨,新增字段mapping映射需要更新mater节点上维护的字段映射信息,master修改了映射信息之后再同步到集群中所有的节点,这个过程中数据的写入是阻塞的。所以建议关闭自动mapping,没有预先定义的字段mapping会写入失败
通过定时任务在集群写入的低峰期,将索引以及mapping映射提前创建好
负载均衡
ES集群是分布式的,数据分布到集群的不同机器上,对于ES中的一个索引来说,ES通过分片的方式实现数据的分布式和负载均衡。创建索引的时候,需要指定分片的数量,分片会均匀的分布到集群的机器中。分片的数量是需要创建索引的时候就需要设置的,而且设置之后不能更改,虽然ES提供了相应的api来缩减和扩增分片,但是代价是很高的,需要重建整个索引。
考虑到并发响应以及后续扩展节点的能力,分片的数量不能太少,假如你只有一个分片,随着索引数据量的增大,后续进行了节点的扩充,但是由于一个分片只能分布在一台机器上,所以集群扩容对于该索引来说没有意义了。
但是分片数量也不能太多,每个分片都相当于一个独立的lucene引擎,太多的分片意味着集群中需要管理的元数据信息增多,master节点有可能成为瓶颈;同时集群中的小文件会增多,内存以及文件句柄的占用量会增大,查询速度也会变慢。
数据副本
ES通过副本分片的方式,保证集群数据的高可用,同时增加集群并发处理查询请求的能力,相应的,在数据写入阶段会增大集群的写入压力。
数据写入的过程中,首先被路由到主分片,写入成功之后,将数据发送到副本分片,为了保证数据不丢失,最好保证至少一个副本分片写入成功以后才返回客户端成功。
相关配置
5.0之前通过consistency来设置
consistency参数的值可以设为 :
one :只要主分片状态ok就允许执行写操作
all:必须要主分片和所有副本分片的状态没问题才允许执行写操作
quorum:默认值为quorum,即大多数的分片副本状态没问题就允许执行写操作,副本分片数量计算方式为int( (primary + number_of_replicas) / 2 ) + 1
5.0之后通过wait_for_active_shards参数设置
索引时增加参数:?wait_for_active_shards=3
给索引增加配置:index.write.wait_for_active_shards=3
数据写入
写入过程
几个概念:
内存buffer
translog
文件系统缓冲区
refresh
segment(段)
commit
flush
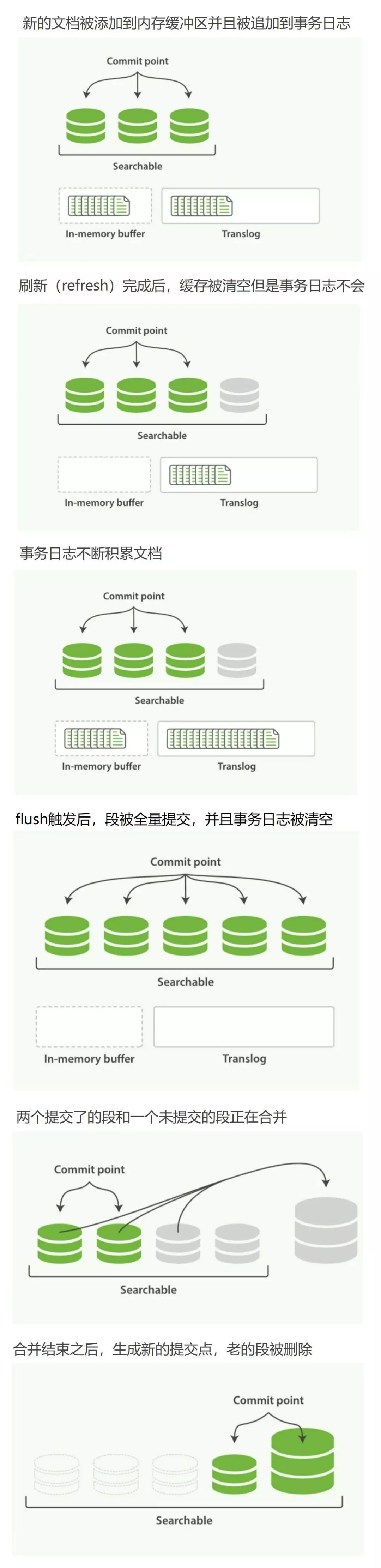
translog
写入ES的数据首先会被写入translog文件,该文件持久化到磁盘,保证服务器宕机的时候数据不会丢失,由于顺序写磁盘,速度也会很快。
同步写入:每次写入请求执行的时候,translog在fsync到磁盘之后,才会给客户端返回成功
异步写入:写入请求缓存在内存中,每经过固定时间之后才会fsync到磁盘,写入量很大,对于数据的完整性要求又不是非常严格的情况下,可以开启异步写入
refresh
经过固定的时间,或者手动触发之后,将内存中的数据构建索引生成segment,写入文件系统缓冲区
commit/flush
超过固定的时间,或者translog文件过大之后,触发flush操作:
内存的buffer被清空,相当于进行一次refresh
文件系统缓冲区中所有segment刷写到磁盘
将一个包含所有段列表的新的提交点写入磁盘
启动或重新打开一个索引的过程中使用这个提交点来判断哪些segment隶属于当前分片
删除旧的translog,开启新的translog
merge
上面提到,每次refresh的时候,都会在文件系统缓冲区中生成一个segment,后续flush触发的时候持久化到磁盘。所以,随着数据的写入,尤其是refresh的时间设置的很短的时候,磁盘中会生成越来越多的segment:
segment数目太多会带来较大的麻烦。 每一个segment都会消耗文件句柄、内存和cpu运行周期。
更重要的是,每个搜索请求都必须轮流检查每个segment,所以segment越多,搜索也就越慢。
merge的过程大致描述如下:
磁盘上两个小segment:A和B,内存中又生成了一个小segment:C
A,B被读取到内存中,与内存中的C进行merge,生成了新的更大的segment:D
触发commit操作,D被fsync到磁盘
创建新的提交点,删除A和B,新增D
删除磁盘中的A和B
删改操作
segment的不可变性的好处
segment的读写不需要加锁
常驻文件系统缓存(堆外内存)
查询的filter缓存可以常驻内存(堆内存)
删除
磁盘上的每个segment都有一个.del文件与它相关联。当发送删除请求时,该文档未被真正删除,而是在.del文件中标记为已删除。此文档可能仍然能被搜索到,但会从结果中过滤掉。当segment合并时,在.del文件中标记为已删除的文档不会被包括在新的segment中,也就是说merge的时候会真正删除被删除的文档。
更新
创建新文档时,Elasticsearch将为该文档分配一个版本号。对文档的每次更改都会产生一个新的版本号。当执行更新时,旧版本在.del文件中被标记为已删除,并且新版本在新的segment中写入索引。旧版本可能仍然与搜索查询匹配,但是从结果中将其过滤掉。
版本控制
通过添加版本号的乐观锁机制保证高并发的时候,数据更新不会出现线程安全的问题,避免数据更新被覆盖之类的异常出现。
使用内部版本号:删除或者更新数据的时候,携带_version参数,如果文档的最新版本不是这个版本号,那么操作会失败,这个版本号是ES内部自动生成的,每次操作之后都会递增一。
PUT /website/blog/1?version=1 { "title": "My first blog entry", "text": "Starting to get the hang of this..."}使用外部版本号:ES默认采用递增的整数作为版本号,也可以通过外部自定义整数(long类型)作为版本号,例如时间戳。通过添加参数version_type=external,可以使用自定义版本号。内部版本号使用的时候,更新或者删除操作需要携带ES索引当前最新的版本号,匹配上了才能成功操作。但是外部版本号使用的时候,可以将版本号更新为指定的值。
PUT /website/blog/2?version=5&version_type=external{ "title": "My first external blog entry", "text": "Starting to get the hang of this..."}由于文章详细,篇幅较长,为了更好的阅读体验,本文将分为上下两个部分。下半部分请查看今日推送的《技术专栏丨从原理到应用,Elasticsearch详解(下)》
