

1、volatile关键字的作用和应用场景
① volatile保证可见性 ,即它会保证修改的值立即被更新到主存中,当有其他线程需要读取时,它会去内存中读取新值
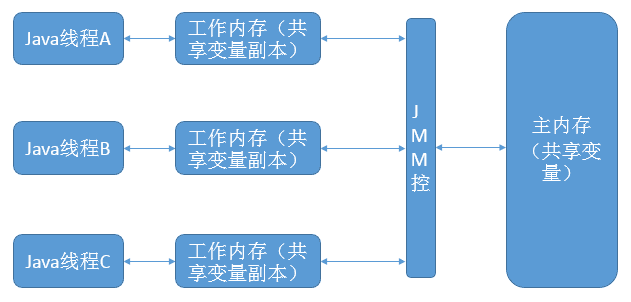
(Java 内存模型规定了 所有的变量都存储在主内存中,每条线程还有自己的工作内存,线程的工作内存中保存了被该线程所使用的到的变量,线程对变量的操作都必须在工作内存中进行,不同线程之间也无法直接访问对方工作内存中的变量,线程间变量值的传递需要通过主内存来完成)
② 禁止进行指令重排序
使用volatile 必须具备以下2个条件:
-
对变量的写操作不依赖当前值
-
该变量没有包含在具有其他变量的不变式中
2、谈谈对线程池的理解
线程池的优势:
① 降低系统资源消耗,通过重用已存在的线程,降低线程创建和销毁造成的消耗;
② 提高系统响应速度,当有任务到达时,无需等待新线程的创建便能立即执行;
③ 方便线程并发数的管控,线程若是无限制的创建,不仅会额外消耗大量系统资源,更是占用过多资源而阻塞资源或oom等状况,从而降低系统的稳定性,线程池有效管控线程,统一分配、调优,提供资源使用率;
线程池关闭方式:
① shutdown() : 将线程池设置成shutdown状态,然后中断所有没有正在执行任务的线程。
② sutdownNow(): 将线程池设置成stop状态, 然后中断所有任务(包括正在执行的任务)的线程,并返回等待执行任务的列表。
Java中有四种不同功能的线程池:
1、newFixedThreadPool : 该线程池锁容纳的最大线程数就是所设置的核心线程数,如果线程池中的线程处于空闲状态,它们不会被回收,除非是这个线程池被关闭了,如果所有的线程都处于活动状态,新任务就会处于等待状态,直到有线程空闲出来。优势:能够更快速响应外界请求。
2、newCachedThreadPool : 该线程池中核心线程数为0,最大线程数为Integer.Max_Value,当线程池中的线程都处于活动状态的时候,线程池就会创建一个新的线程来处理任务,该线程池中的线程超时时长为60秒,,所以当线程处于闲置状态超过60秒的时候就会被回收
3、newScheduledThreadPool : 核心线程数是固定的,当非核心线程处于限制状态时会立即被回收,常用于执行定时任务。
4、newSingleThreadExecutor : 该线程池只有一个核心线程,对于任务队列没有大小限制,也就意味着这一任务处于活动状态时,其他任务都会在任务队列中排队等候依次执行。
3、Java中的锁有哪些? 以及区别?
- 公平锁/非公平锁
- 公平锁是指多个线程按照申请锁的顺序来获取锁的
- 非公平锁是指多个线程获取锁的顺序并不是按照申请锁的顺序,有可能后申请的线程比先申请的线程优先获取锁。有可能会造成优先级反转后者饥饿现象。
- 可重入锁
- 可重入锁又名递归锁,是指在同一个线程在外层方法获取锁的时候,在进入内层方法会自动获取锁。 eg:
synchronized void setA() throws Exception() { Thread.sleep(1000); setB(); } synchronized void setB() throws Exception() { Thread.sleep(1000); } - 独享锁/共享锁
- 独享锁是指该锁一次只能被一个线程所持有
- 共享锁是指该锁可被多个线程持有
- 互斥锁/读写锁
- 互斥锁:一次只能一个线程拥有互斥锁,其他线程只有等待
- 读写锁:多个读者可以同时进行,写者优于读者,写者必须互斥。
- 乐观锁/悲观锁
- 悲观锁:当一个线程被挂起的时候,加入到阻塞队列,在一定的时间或条件下,再通过notify(), notifyAll() 唤醒,在某个资源不可用时,就将cpu让出,把当前等待线程切换为阻塞状态,等到资源可用了,就将线程唤醒,让他进入runnable状态等待cpu调度。
- 乐观锁:每次不加锁而是假设修改数据之前其他线程一定不会修改,如果因为修改过产生冲突而失败就重试,直到成功为止。
- 分段锁
- 分段锁是一种锁的设计,并不是具体的一种锁,对于ConcurrentHashMap而言,其并发的实现就是通过分段锁的形式来实现高效的并发操作。ConcurrentHashMap 中的分段锁成为Segment,它类似于HashMap 的结构,即内部拥有一个Entry数组,数组中的每个元素又是一个链表;当需要put元素时,并不是对整个hashmap进行加锁,而是先通过hashCode来指导它要放在哪个分段中,然后对这个分段进行加锁,所以当多线程put的时候,只要不是放在一个分段中,就实现了真正的并行插入。但是在统计size 的时候,可就是获取hashMap 全局信息的时候,就需要获取所有的分段锁才能统计。
4、Java内存区域与内存模型
一、Java 内存区域
- 方法区(公有):用户存储已被虚拟机加载的类信息、常量、静态常量,即时编译器编译后的代码等数据
- 堆(公有):是JVM所管理的内存中最大的一块,唯一的目的就是存放实力对象,Java堆是垃圾收集器管理的主要区域,因此很多时候也被称为GC堆。
- 虚拟机栈(线程私有):Java方法执行的内存模型,每个方法在执行时都会创建一个栈帧,用户局部变量表,操作数栈,动态连接,方法出口等信息,每个方法从调用直至完成的过程,都对应着一个栈帧在虚拟机栈中入栈到出栈的过程。
- 本地方法栈(线程私有):本地方法栈为虚拟机使用到的Native方法服务。
- 程序计数器(线程私有):一块较小的内存,当前线程所执行的字节码的行号指示器,字节码解释器工作时,就是通过改变这个计数器的值来选取下一条需要执行的字节码指令。
二、Java 内存模型
Java 内存模型规定了所有的变量都存储到主内存中,每条线程还有自己的工作内存,线程的工作内存中保存了被该线程使用到的变量,线程对变量的所有操作都必须在工作内存执行,不同线程之间也无法直接访问对方工作内存中的变量,线程间变量值的传递需要通过主内存来完成。
5、Java类加载机制及类加载器
① 类加载机制定义:把描述类的数据从Class文件加载到内存,并对数据进行校验、转换解析和初始化,最终形成可以被虚拟机直接使用的Java类型。
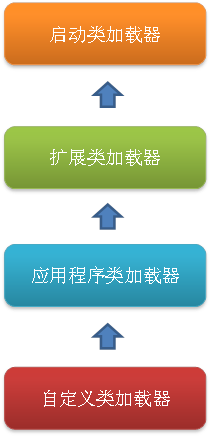
②双亲委派模型:如果一个类加载器收到了类加载的请求,它首先不会自己去尝试加载这个类,而是把请求委托给父加载器去完成,依次向上,因此,所有的类加载请求最终都应该被传递到顶层的启动类加载器(Bootstrap ClassLoader)中。只有当父加载器在它的搜索范围内没有找到所需的类时,子加载器才会尝试自己去加载该类。
这样的好处是不同层次的类加载器具有不同优先级,比如所有Java对象的超级父类Object,位于rt.jar,无论哪个类加载器加载该类,最终都是由启动加载器进行加载,保证安全,如果开发者自己编写一个Object类放入程序中,虽能正常编译,但不会被加载运行,保证不会出现混乱。
6、JVM中垃圾收集算法
-
标记-清除算法 ① 首先标记出所有需要回收的对象 ② 在标记完成后统一回收所有被标记的对象
缺点:标记和清除两个过程效率不高,标记清除之后产生大量不连续的内存碎片,空间碎片太多可能会导致运行过程中需要分配较大对象时,无法找到足够的连续内存而不得不提前触发另一次垃圾收集动作
-
复制算法
将可用内存按照容量大小划分为大小相等的两块,每次只使用其中的一块,当一块内存使用完了,就将还存活着的对象复制到另一块上面,然后把使用过的内存空间一次清理掉,这样使得每次都是对整个半区进行内存回收,内存分配时也不用考虑内存碎片等复杂情况。
缺点:将内存缩小为原来的一半。
-
标记-整理算法 复制收集算法在对象存活率比较高时,就要进行比较多的复制操作,效率就会变低; 标记过程仍然与 “标记-清除”算法一样,但是后续步骤不是直接对可回收对象进行清理,而是让所有存活的对象都向一端移动,然后直接清理掉边界以外的内存。
-
分代收集算法 一般把Java堆分为新生代和老生代, 这样就可以根据各个年代的特点采用最适合的收集算法。
在新生代中,每次垃圾收集时都发现有大批对象死去,只有少量存活,那就选用复制算法。
在老生代中,因为对象存活率高,没有额外空间对它进行分配担保,就必须采用“标记-清除”或“标记-整理”算法来进行回收。
7、JVM怎么判断对象是否已死?
一、引用计数法
给对象添加一个引用计数器,每当有一个地方引用它时,计数器值就加1,当引用失效时,计数器值就减1;任何时刻计数器为0的对象就是不可能被再使用的。
主流的JVM里面没有选用引用计数法来管理内存,其中最主要的原因就是它很难解决对象间的互循环引用的问题。
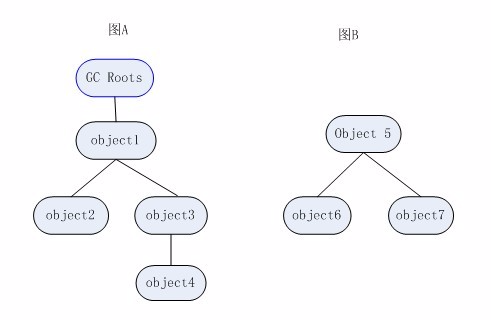
二、可达性分析算法
通过一些称为“GC Roots”的对象作为起始点,从这些节点开始向下搜索,搜索所走过的路径称为引用连,当一个对象到GC Roots没有任何引用连相连时,证明此对象是不可用的,所以它们会被判定为可回收对象。如图B的对象是不可达的
在Java中,可以作为GC Roots的对象包括下面几种:
虚拟机栈(栈帧中的本地变量表)中引用的对象
方法区中静态属性引用的对象
方法区中常量引用的对象
本地方法栈JNI(一般说的Native方法)引用的对象
- 如果对象在进行可达性分析后发现没有与GC Roots相连接的引用链,那它将会被第一次标记并且进行一次筛选,筛选的条件是此对象是否有必要执行finalize()方法。当对象没有覆盖finalize()方法,或者finalize()方法已经被虚拟机调用过,虚拟机将这两种情况都视为没有必要执行。
- 如果这个对象呗判定为有必要执行finalize()方法,那么这个对象将会放置在一个叫做F-Queue队列之中,并在稍后由一个虚拟机自动建立的、低优先级的Finalizer线程去执行它。finalize()方法是对象逃脱死亡命运的最后一次机会,稍后GC将对F-Queue 中的对象进行第二次小规模的标记,如果对象要在finalize()中成功拯救自己,只要重新与引用链上的任何一个对象建立关联即可,那在第二次标记时它将会被移除出即将回收的集合;如果对象这时候还没有逃脱,那基本上它就真的被回收了。
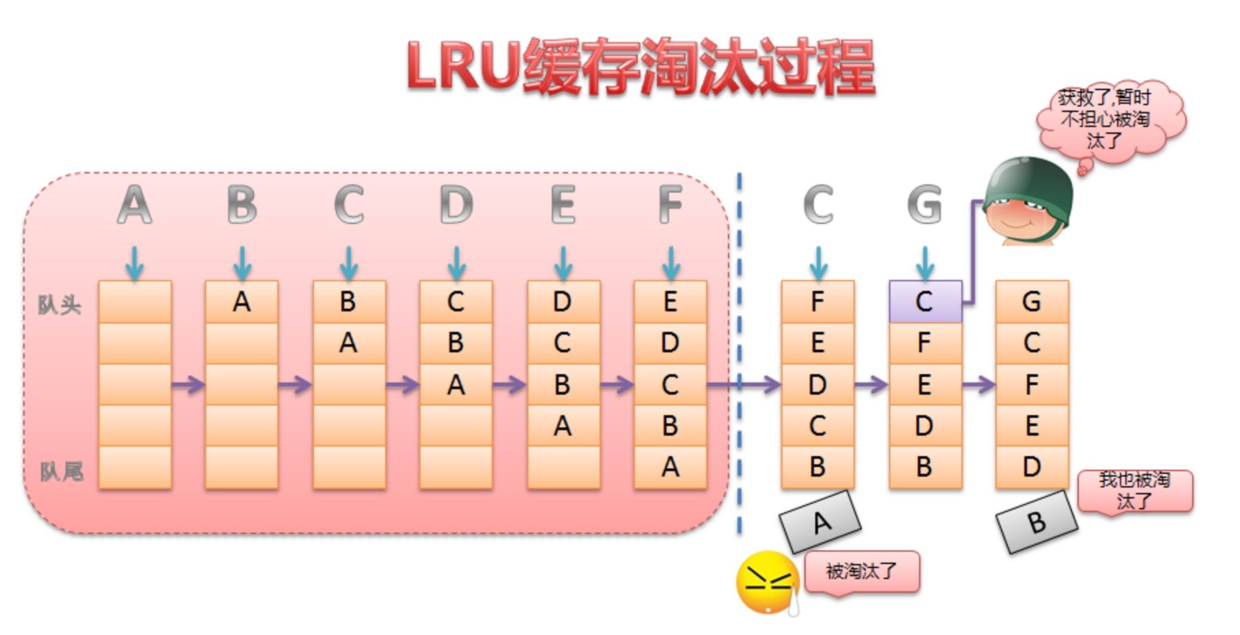
8、LruCache 原理解析
LruCache的核心思想就是要维护一个缓存对象列表,其中对象列表的排列方式是按照访问顺序实现的,即一直没访问的对象,放在队尾,即将被淘汰,而最近访问的对象放在对头,最后被淘汰。 如图所示:
这个队列是由LinkedHashMap来维护的,而LinkedHashMap是由数组+双向链表 的数据结构来实现的,其中双向链表的结构可以实现访问顺序和插入顺序,使得LinkedHashMap中的key,value对按照一定顺序排列起来。
通过下面构造函数来指定LinkedHashMap中双向链表的结构是访问顺序还是插入顺序。
public LinkedHashMap(int initialCapacity,
float loadFactor,
boolean accessOrder) {
super(initialCapacity, loadFactor);
this.accessOrder = accessOrder;
}
其中accessOrder设置为true 则为访问顺序,为false,则为插入顺序。 以具体的例子解释,当设置为true 时
public static final void main(String[] args) {
LinkedHashMap<Integer, Integer> map = new LinkedHashMap<>(0, 0.75f, true);
map.put(0, 0);
map.put(1, 1);
map.put(2, 2);
map.put(3, 3);
map.put(4, 4);
map.put(5, 5);
map.put(6, 6);
map.get(1);
map.get(2);
for (Map.Entry<Integer, Integer> entry : map.entrySet()) {
System.out.println(entry.getKey() + ":" + entry.getValue());
}
}
输出结果:
0:0
3:3
4:4
5:5
6:6
1:1
2:2
即最近访问的最后输出,那么就正好满足的LRU缓存算法的思想,可见LruCache巧妙实现,就是利用了LinkedHashMap的这种数据结构。 下面我们在LruCache源码中具体查看,怎么应用LinkedHashMap来实现缓存的添加,获得和删除的。
/**
* @param maxSize for caches that do not override {@link #sizeOf}, this is
* the maximum number of entries in the cache. For all other caches,
* this is the maximum sum of the sizes of the entries in this cache.
*/
public LruCache(int maxSize) {
if (maxSize <= 0) {
throw new IllegalArgumentException("maxSize <= 0");
}
this.maxSize = maxSize;
this.map = new LinkedHashMap<K, V>(0, 0.75f, true);
}
从LruCache的构造函数中可以看到正是用了LinkedHashMap的访问顺序。
put()方法
/**
* Caches {@code value} for {@code key}. The value is moved to the head of
* the queue.
*
* @return the previous value mapped by {@code key}.
*/
public final V put(K key, V value) {
if (key == null || value == null) {
throw new NullPointerException("key == null || value == null");
}
V previous;
synchronized (this) {
putCount++;
size += safeSizeOf(key, value);
previous = map.put(key, value);
if (previous != null) {
size -= safeSizeOf(key, previous);
}
}
if (previous != null) {
entryRemoved(false, key, previous, value);
}
trimToSize(maxSize);
return previous;
}
可以看到put()方法并没有什么难点,重要的就是在添加过缓存对象后,调用 trimToSize()方法,来判断缓存是否已满,如果满了就要删除近期最少使用的算法。
trimToSize()方法
/**
* Remove the eldest entries until the total of remaining entries is at or
* below the requested size.
*
* @param maxSize the maximum size of the cache before returning. May be -1
* to evict even 0-sized elements.
*/
public void trimToSize(int maxSize) {
while (true) {
K key;
V value;
synchronized (this) {
if (size < 0 || (map.isEmpty() && size != 0)) {
throw new IllegalStateException(getClass().getName()
+ ".sizeOf() is reporting inconsistent results!");
}
if (size <= maxSize || map.isEmpty()) {
break;
}
Map.Entry<K, V> toEvict = map.entrySet().iterator().next();
key = toEvict.getKey();
value = toEvict.getValue();
map.remove(key);
size -= safeSizeOf(key, value);
evictionCount++;
}
entryRemoved(true, key, value, null);
}
}
trimToSize()方法不断地删除LinkedHashMap中队尾的元素,即近期最少访问的,直到缓存大小小于最大值。
当调用LruCache的get()方法获取集合中的缓存对象时,就代表访问了一次该元素,将会更新队列,保持整个队列是按照访问顺序排序。这个更新过程就是在LinkedHashMap中的get()方法中完成的。
先看LruCache的get()方法
public final V get(K key) {
//key为空抛出异常
if (key == null) {
throw new NullPointerException("key == null");
}
V mapValue;
synchronized (this) {
//获取对应的缓存对象
//get()方法会实现将访问的元素更新到队列头部的功能
mapValue = map.get(key);
if (mapValue != null) {
hitCount++;
return mapValue;
}
missCount++;
}
其中LinkedHashMap的get()方法如下:
public V get(Object key) {
LinkedHashMapEntry<K,V> e = (LinkedHashMapEntry<K,V>)getEntry(key);
if (e == null)
return null;
//实现排序的关键方法
e.recordAccess(this);
return e.value;
}
调用recordAccess()方法如下:
void recordAccess(HashMap<K,V> m) {
LinkedHashMap<K,V> lm = (LinkedHashMap<K,V>)m;
//判断是否是访问排序
if (lm.accessOrder) {
lm.modCount++;
//删除此元素
remove();
//将此元素移动到队列的头部
addBefore(lm.header);
}
}
由此可见LruCache中维护了一个集合LinkedHashMap,该LinkedHashMap是以访问顺序排序的。当调用put()方法时,就会在结合中添加元素,并调用trimToSize()判断缓存是否已满,如果满了就用LinkedHashMap的迭代器删除队尾元素,即近期最少访问的元素。当调用get()方法访问缓存对象时,就会调用LinkedHashMap的get()方法获得对应集合元素,同时会更新该元素到队头。
整理了最近一段时间的学习要点,做一个归纳总结,后续还会再做更新。。。。
