

前言
来掘进都有两年多了一直当个小透明,今天终于发一次文章了. 最近在看 Redis,感觉收获很多,写篇博客记录一下.
Redis 有五种基础数据结构:string,list,set,zset,hash.其中 string是最最最简单的也是最常用的.这个数据类型虽然简单但是内部的结构设计却很是精致.
基本介绍
相比于 Java,在 Redis 中 string 是可以修改的,是动态字符串(Simple Dynamic String 简称 SDS)他的内部结构更像是一个 ArrayList,维护一个字节数组并预分配冗余空间以减少内存的频繁分配.当字符串的长度小于 1MB时,每次扩容都是加倍现有的空间,如果字符串长度超过 1MB 时,每次扩容时只会扩展 1MB 的空间.
ps:字符串长度为最大长度 512MB.
> set name test
OK
> get name
"test"
> mset name1 test1 name2 test2
OK
> mget name1 name2
1) "test1"
2) "test2"
> del name
(integer) 1
上面是字符串的基本操作 命令mset 和 mget 可以对多个字符串读写 节省网络开销
不仅如此redis 的字符串还可以用来储存整数(更不像Java 的字符串了),并且可以自增操作.字符串保存整数类型的的范围在 至
如果保存的数大于这个取值范围就会变成普通字符类型 无法自增操作.这将由字符串编码格式决定.
字符串由多个字节组成,每个字节有 8bit.这样的数据结构还可以当做 bitmap 去使用.
> set foo 1
OK
> get foo
"1"
> incr foo
(integer) 2
> get foo
"2"
内部原理
基本实现

上图所示为字符串的基本结构,其中 content 里面保存的是字符串内容,和 c 一样用 0x\0作为结束字符.这个结束字符不会被计算len 中.代码如下:
struct SDS{
T capacity; //数组容量
T len; //实际长度
byte flages; //标志位,低三位表示类型
byte[] content; //数组内容
}
可以看到 capacity和len 都是泛型,为什么不直接使用 int 呢?因为 Redis 内部做了很多优化,为了减少内存的使用不同长度的字符串会使用不同的数据类型去表示.并且在创建字符串的时候 len 会和 capacity 一样大,没有冗余的空间,因为修改字符串的场景很少.(Redis 真的将内存优化到了极致)
编码格式
Redis 字符串编码格式有这么几种:int 编码、embstr编码和raw 编码 下面就详细介绍下这几种编码的区别.
在这之前先要说说RedisObject. Redis 的对象头,所有的 Redis 对象都有下面这个头部结构.
struct RedisObject{
int4 type; //数据类型 5 种
int4 encoding; //键值内部编码格式 int 或 embstr 等等
int24 lru; // 当内存超限时采用LRU算法清除内存中的对象
int32 refcount; //改键值被引用的数量
void *ptr; //对象内容
}
int 编码
当储存的值是64 位有符号整数类型的时候将会采用 int 编码,这时可以使用键值自增操作.Redis 在启动时会建立1w 个redisObject共享对象下文会讲到,值在[0,1000)之间.如果存入整数的值在[0,1000)中Redis将不会创建新的对象,而是直接指向共享对象,键值不额外占用空间.
使用 object encoding命令可以查看编码格式 使用 debug object命令可以查看更多信息
> set foo 1
OK
> object encoding foo
"int"
> set foo2 1
OK
> debug object foo
Value at:0x7f44b020aca0 refcount:2147483647 encoding:int serializedlength:2 lru:14691591 lru_seconds_idle:72588
> debug object foo2
Value at:0x7f44b020aca0 refcount:2147483647 encoding:int serializedlength:2 lru:14691591 lru_seconds_idle:72594
可以看到 foo 和 foo2 都在0x7f44b020aca0这里指向的是同一个对象
embstr 编码
当存储的字符串长度较短时(len<=44 字节),Redis将会采用 embstr 编码.embstr 即embedded string 嵌入式的字符串.将SDS结构体嵌入RedisObject对象中, 使用 malloc 方法一次分配内存地址是连续的.
如图所示:
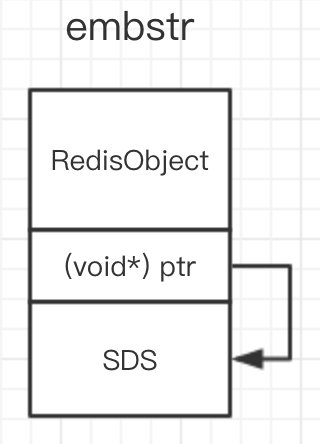
raw 编码
当存储的字符串长度较长时(len>44 字节),Redis 将会采用 raw 编码,和 embstr 最大的区别就是 RedisObject 和 SDS 不在一起了,内存地址不再连续了.
如图所示:

思考
为什么字符串会有两种格式 embstr 和格式和 raw分界线是 44 个字节?
Redis 默认的内存分配器jemalloc分配内存大小的单位是次方,为了容纳一个完整的 embstr 对象,最少会分配 32 字节的空间,再长些就是 64 字节,再之后就认为这是一个大字符串不适合用 embstr 存储,而改用 raw 编码了.
那么问题来了,64 字节的空间字符串长度是多少呢?答案就是 44 字节.
下图中 content 的长度为 45 字节减去结尾的 0x\0,就剩下 44 字节了.

