

“ 鬼知道我为什么记得这些命令。——编程三分钟”
概述
awk同sed命令类似,只不过sed擅长取行,awk命令擅长取列。(根据了解awk是一种语言,不过我们只关注他处理文本的功能,用的好的话几乎可以取代excel)
原理:一般是遍历一个文件中的每一行,然后分别对文件的每一行进行处理
用法:
awk [可选的命令行选项] 'BEGIN{命令 } pattern{ 命令 } END{ 命令 }' 文件名
打印某几列
$ echo 'I love you' | awk '{print $3 $2 $1}'
youloveI
我们将字符串 I love you 通过管道传递给awk命令,相当于awk处理一个文件,该文件的内容就是I love you,默认通过空格作为分隔符(不管列之间有多少个空格都将当作一个空格处理)I love you就分割成三列了。
假如分割符号为.,可以这样用
$ echo '192.168.1.1' | awk -F "." '{print $2}'
168
条件过滤
我们知道awk的用法是这样的,那么pattern部分怎么用呢?
awk [可选的命令行选项] 'BEGIN{命令 } pattern{ 命令 } END{ 命令 }' 文件名
$ cat score.txt
tom 60 60 60
kitty 90 95 87
jack 72 84 99
$ awk '$2>=90{print $0}' score.txt
kitty 90 95 87
$2>=90 表示如果当前行的第2列的值大于90则处理当前行,否则不处理。说白了pattern部分是用来从文件中筛选出需要处理的行进行处理的,这部分是空的代表全部处理。pattern部分可以是任何条件表达式的判断结果,例如>,<,==,>=,<=,!=同时还可以使用+,-,*,/运算与条件表达式相结合的复合表达式,逻辑 &&,||,!同样也可以使用进来。另外pattern部分还可以使用 /正则/ 选择需要处理的行。
判断语句
判断语句是写在pattern{ 命令 }命令中的,他具备条件过滤一样的作用,同时他也可以让输出更丰富
$ awk '{if($2>=90 )print $0}' score.txt
kitty 90 95 87
$ awk '{if($2>=90 )print $1,"优秀"; else print $1,"良好"}' score.txt
tom 良好
kitty 优秀
jack 良好
BEGIN 定义表头
awk [可选的命令行选项] 'BEGIN{命令 } pattern{ 命令 } END{ 命令 }' 文件名
使用方法如下:
$ awk 'BEGIN{print "姓名 语文 数学 英语"}{printf "%-8s%-5d%-5d%-5d\n",$1,$2,$3,$4}' score.txt
姓名 语文数学英语
tom 60 60 60
kitty 90 95 87
jack 72 84 99
这里要注意,我为了输出格式好看,做了左对齐的操作(%-8s左对齐,宽8位),printf用法和c++类似。
不仅可以用来定义表头,还可以做一些变量初始化的工作,例如
$ awk 'BEGIN{OFMT="%.2f";print 1.2567,12E-2}'
1.26 0.12
这里OFMT是个内置变量,初始化数字输出格式,保留小数点后两位。
END 添加结尾符
和BEGIN用法类似
$ echo ok | awk '{print $1}END{print "end"}'
ok
end
数据计算
这个地方我要放大招了!上面的知识点你都记住了吗?
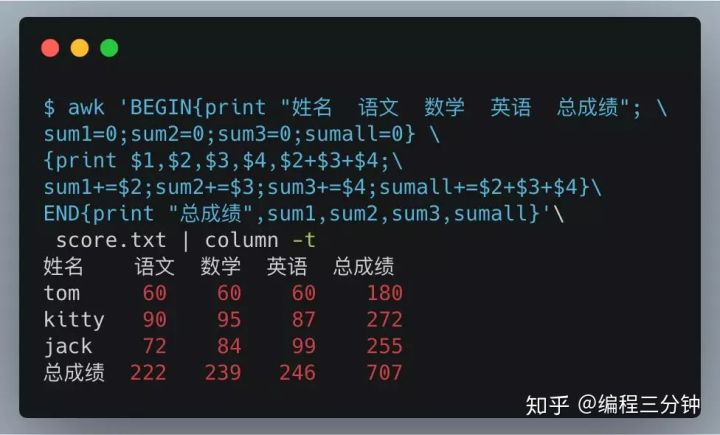
$ awk 'BEGIN{print "姓名 语文 数学 英语 总成绩"; \
sum1=0;sum2=0;sum3=0;sumall=0} \
{printf "%5s%5d%5d%5d%5d\n",$1,$2,$3,$4,$2+$3+$4;\
sum1+=$2;sum2+=$3;sum3+=$4;sumall+=$2+$3+$4}\
END{printf "%5s%5d%5d%5d%5d\n","总成绩",sum1,sum2,sum3,sumall}'\
score.txt
姓名 语文 数学 英语 总成绩
tom 60 60 60 180
kitty 90 95 87 272
jack 72 84 99 255
总成绩 222 239 246 707
因为命令太长,末尾我用\符号换行了。。
- BEGIN体里我输出了表头,并给四个变量初始化0
- pattern体里我输出了每一行,并累加运算
- END体里我输出了总统计结果
当然了,一个正常人在用linux命令的时候是不会输入那么多格式化符号来对齐的,所以新命令又来了column -t(鬼知道我为什么会记得这么多乱七八糟的命令。)
有用的内置变量
NF:表示当前行有多少个字段,因此$NF就代表最后一个字段
NR:表示当前处理的是第几行
FILENAME:当前文件名
OFMT:数字输出的格式,默认为%.6g。表示只打印小数点后6 位
$ awk -F ':' '{print NR ") " $1}' demo.txt
1) root
2) daemon
3) bin
4) sys
5) sync
内置函数
awk定义了很多内置函数,用awk来写shell脚本倒是一个不错的选择,但是大多数我们是用不上的,以下是常用函数
$ echo 1 2 | awk '{print $1+sqrt($2)}'
2.41421
随机数,先设置种子再随机
rand() 0 <= n < 1,srand([expr]) |将 rand 函数的种子值设置为 Expr 参数的值,或如果省略 Expr 参数则使用某天的时间。
$ echo 1 | awk 'BEGIN{srand()}{print rand()}'
0.929885
字符串

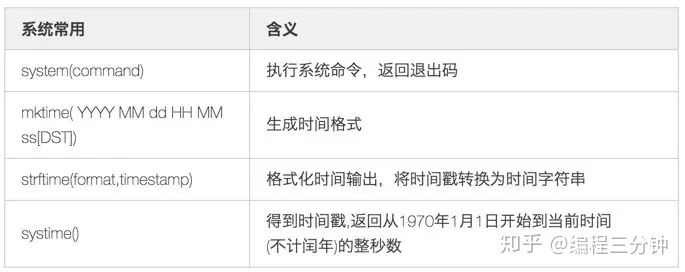
系统常用
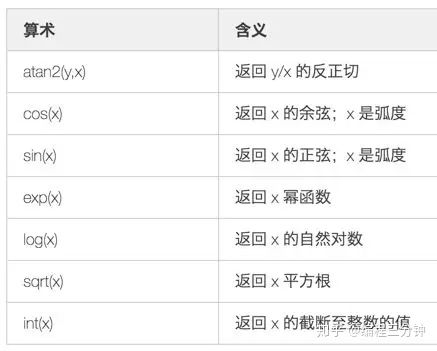
不常用算数:
推荐阅读
(点击标题可跳转阅读)

如果有帮助别忘了分享给朋友哦~
