

本文是MapReduce论文的学习笔记。MapReduce框架需要使用者提供map和reduce函数,map函数将一个键/值输入转换成一组中间键/值,然后reduce函数将所有具有相同键的中间键值对进行合并,而其他的任务调度、文件分割、容错处理等工作都由框架来完成。
编程模型
MapReduce框架用户需要提供两个函数map和reduce:
- Map:将输入的一对键值对转换为一组中间键值对。
- Reduce:将所有键相同的中间键值对合并,得到关于那个键的结果。
简单的例子
初看很难体会到MapReduce的设计初衷,而MapReduce最经典的例子就是单词计数任务,单词计数任务的两个函数定义如下:
func map(filename string, contents string) []mapreduce.KeyValue {
words := strings.FieldsFunc(contents, func(r rune) bool {
return !unicode.IsLetter(r)
})
var res []mapreduce.KeyValue
for _, word := range words {
res = append(res, mapreduce.KeyValue{ Key:word, Value:"1" })
}
return res
}
func reduce(key string, values []string) string {
result := 0
for _, value := range values {
count, _ := strconv.Atoi(value)
result += count
}
return strconv.Itoa(result)
}
上述例子中map函数输入键为文件名,输入值为文件内容,map函数将文件内容分割为多个单词,中间键值对为单词和单词出现次数“1”,而reduce函数将某个单词所有出现的次数相加。
更多的例子
除了最简单的单词统计以外,还有很多的问题都可以套用MapReduce的模型解决。
- 分布式grep:Map函数在某一行匹配成功之后产生一个中间键值对,reduce函数将匹配结果简单合并。
- URL访问统计:Map函数根据每一条访问日志产生一个中间键值对
<URL,1>,reduce函数将URL的所有中间键值对的值相加,产生结果<URL,访问次数>。 - 反向网页链接图:当来源网页中出现一次目标链接,map函数产生一个中间键值对
<目标,来源>。Reduce函数合并相同目标的中间值,产生<目标,list(来源)>。 - 反向索引:Map函数解析文档后,产生如
<单词,文档编号>的中间键值对,然后reduce函数合并中间键值对,产生结果<单词,list(文档编号)>。最终结果组成一个反向索引,可以用于查询单词出现的文档。 - 分布式排序:Map函数根据每一条记录中参与排序的键取出,产生中间结果
<键,记录>,reduce函数则原样输出中间键值对即可。
系统实现
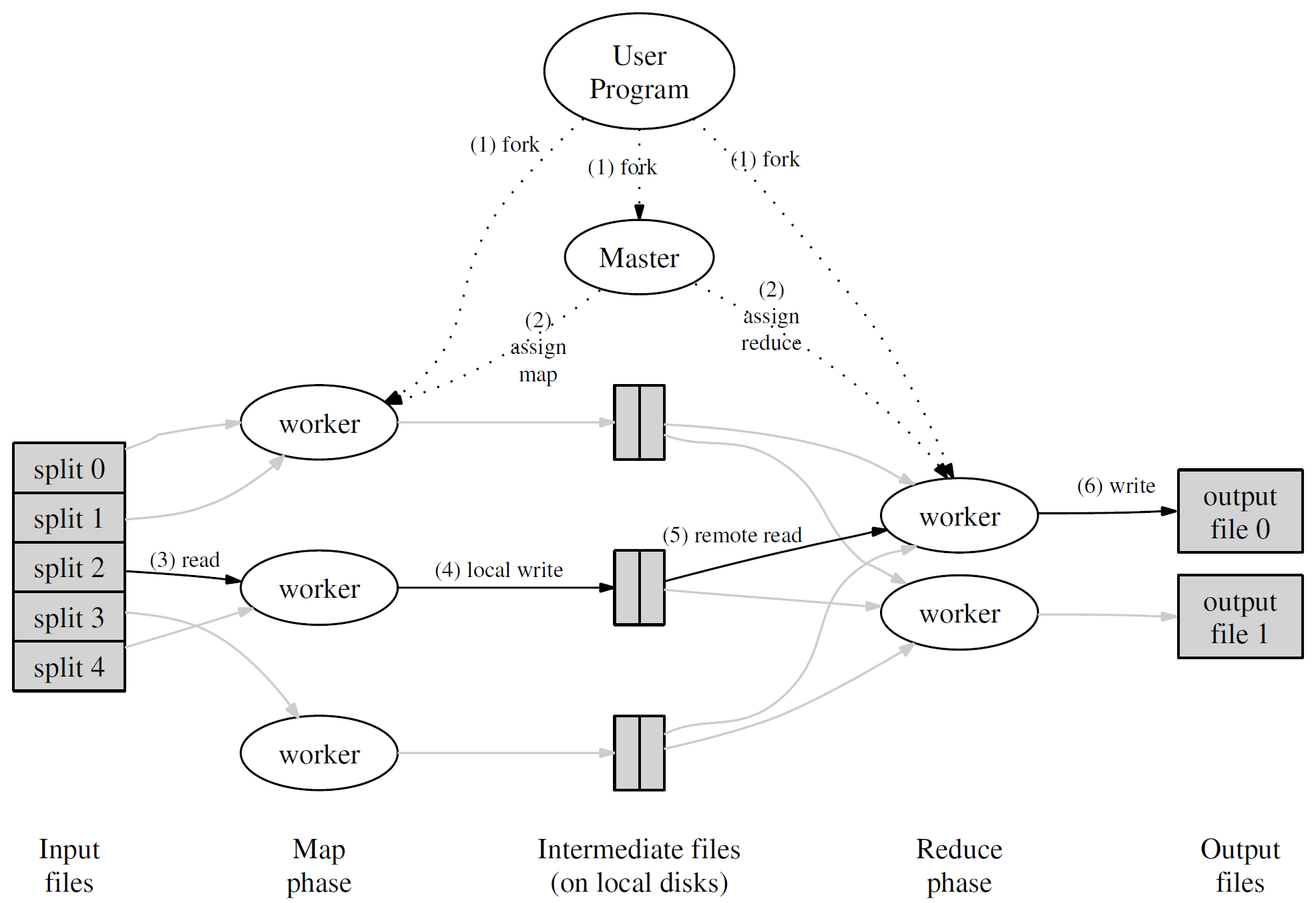
运行流程
MapReduce需要处理的数据会被事先分割为M片段,中间数据被分配给R个片段,分割过程由分割函数hash(键) mod R,分片数M和R以及哈希函数都由用户定义。
- MapReduce将输入文件分割为M个片段。
- 计算集群由一个master和多个worker组成,master负责将map或者reduce任务分配给worker完成。
- 分配到map任务的worker读取输入文件片段,从片段中解析出键值对传递给用户定义的map函数得到一组中间键值对保存到内存中。
- 内存中的中间键值对会被周期性地写入本地磁盘,然后被分割为R个片段,将片段的保存位置通知master用于reduce任务。
- 分配到reduce任务的worker读取来自map任务worker磁盘的中间键值对。当读取完全部的中间数据之后,将所有的键值对按照键顺序排序,将键值相同的值合为一组。
- 执行reduce任务的worker将相同键的中间值集合传递给用户定义的reduce函数,将输出添加到当前reduce任务对应的片段中。
- 当全部的map和reduce操作完成之后,MapReduce通知用户程序处理输出文件。
MapReduce处理结果通常会被保存到R个文件片段中,文件片段通常不需要被合并,直接用于其他的分布式任务。
容错处理
Worker错误
Master会不断ping各个worker,如果某个worker产生错误,那么会被重置到可调度状态。发生错误的时候,已经完成的map任务需要被重新执行,因为map的结果保存到本地磁盘中,而已完成的reduce任务不需要被重新执行,因为reduce任务的结果被写入全局文件系统,
Master错误
可以让master定期将状态保存到磁盘,崩溃后直接利用保存的状态恢复。另外,也可以考虑直接在master奔溃的时候终止MapReduce任务。
系统优化
在实现MapReduce实现中,由很多的技巧可以提高系统的运行效率。
- 局部性:如果MapReduce的输入文件保存在分布式文件系统(例如GFS)中,那么可以结合分布式文件系统,将map任务分配给保存有输入文件分片的worker,或者退而求其次选择里文件分片保存位置最近的worker。
- 细粒度:输入文件分割数目M通常要比worker大很多,这样方便系统进行更加合理地调度,原文中建议每个分割大小为16MB到64MB, 但是现在已经是快15年后了。
- 备份任务:在执行MapReduce任务时,会有一些worker由于各种原因导致任务执行非常慢。因此,当MapReduce任务快要结束的时候,系统将那些尚未完成的任务分配给其他worker同时执行,来加快完成速度。
- 合并函数:在单词统计任务中,我们知道单词是符合Zipf分布的,因此
会有大量的例如
<the,1>这样常用词产生的中间数据传递给某个reduce任务的worker,这会给某个worker带来巨大的负担。解决的方法就是让map执行完成后调用合并函数处理一编中间数据。合并函数和reduce函数通常是一样的,只是调用场景不同。
参考文献
- Dean, Jeffrey, and Sanjay Ghemawat. "MapReduce: simplified data processing on large clusters." Communications of the ACM 51.1 (2008): 107-113.
