起源
我们都知道 (不知道也没关系),接口测试就是验证接口响应结果符不符合预期的一个验证过程。其中接口测试又分为人工测试和自动化测试。人工测试是使用工具/程序先去发送接口请求,然后用肉眼去验证接口的返回结果。而自动化测试则是完全由程序去执行并验证结果。

笔者在自动化测试的实践中发现,当接口返回数据因业务实际需求变动时 (一般是业务初期,啥都不确定),测试工程师需要花大量时间去修改接口响应结果的验证数据。而当返回数据频繁变动时,这就让人比较崩溃了。
举个极端栗子:
确定的需求:
接口1-1返回: {'greeting': '你好,欢迎你来到智能测试平台,希望你过得开心!'}
接口1-1校验: assert_true(greeting == '你好,欢迎你来到智能测试平台,希望你过得开心!')
这时候需求变了:
接口1-2返回: {'greeting': '您好,欢迎你来到智能测试平台,希望你过得开心!'}
(于是)接口1-2校验: assert_true(greeting == '您好,欢迎你来到智能测试平台,希望你过得开心!')
这时候需求又变了:
接口1-3返回: {'greeting': '您好,欢迎您来到智能测试平台,希望您过得开心!'}
接口1-3校验(os:谁知道他什么时候又要改回去,那么是时候上正则了):
regex = re.compile('你|您好,欢迎你|您来到智能测试平台,希望你|您过得开心!')
assert_not_none(re.match(regex, greeting))
这时候需求再次变更:
接口1-4返回: {'greeting': 'XXX先生/女士,欢迎您来到我的智能测试平台,希望您今天过得开心!'}
接口1-4校验: ???

这时候,一个想法闪过了我的脑海,既然接口微调前和微调后的返回结果很可能在表达上是相似的,那么有没有可能使用 文本相似度 去校验结果是否符合预期呢?
这有什么不可能的?于是笔者开始了行动。
实现
模型选择
这还用问,当然是选择开源的模型啦,笔者选择了谷歌最强NLP模型BERT。
下载地址
https://storage.googleapis.com/bert_models/2018_11_03/chinese_L-12_H-768_A-12.zip
下载server&client:
pip install bert-serving-server # server
pip install bert-serving-client # client, independent of `bert-serving-server`
启动模型:
bert-serving-start -model_dir C://Users/Admin/Downloads/chinese_L-12_H-768_A-12/ -num_worker=4
最佳实践:
运行代码:
from bert_serving.client import BertClient
bc = BertClient()
test = bc.encode(['你好', '您好'])
print(test)
控制台输出:
[[ 0.28940186 -0.13572685 0.07591164 ... -0.14091228 0.5463005
-0.3011805 ]
[ 0.22952817 0.15336302 -0.18656345 ... -0.40034887 0.12984493
-0.34498438]]
Process finished with exit code 0
相似度算法
好的,既然我们已经能够成功将中文文本转化成了 向量 ,那么我们接下来可以使用 余弦夹角 来求得文本之间的相似度。
笔者作为数学爱好者,当然得 从头证明且实现一遍 给读者看。
首先我们先利用三角形得出一个关于三角形三边与夹角的关系式:

然后根据上式求得两个向量间的夹角与向量之间的关系式:
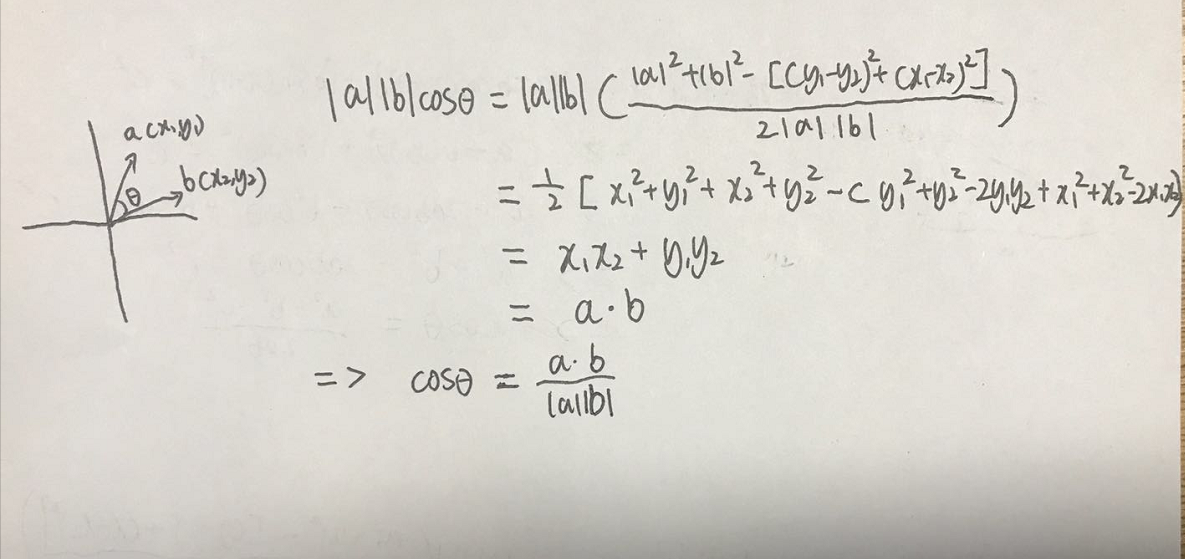
然后我们就可以通过这个公式求得两个向量之间的 余弦夹角 啦

简易代码实现
import numpy as np
class Nlper:
def __init__(self, bert_client):
self.bert_client = bert_client
def get_text_similarity(self, base_text, compaired_text, algorithm='cosine'):
if isinstance(algorithm, str) and algorithm.lower() == 'cosine':
arrays = self.bert_client.encode([base_text, compaired_text])
norm_1 = np.linalg.norm(arrays[0])
norm_2 = np.linalg.norm(arrays[1])
dot_product = np.dot(arrays[0], arrays[1])
similarity = round(0.5 + 0.5 * (dot_product / (norm_1 * norm_2)), 2)
return similarity
这里实现了一个简单的Nlper类,初始化Nlper对象时传入bert模型,然后通过get_text_similarity方法即可求得两个文本之间的相似度。方法内部实现使用了非常方便的numpy库,最后返回结果前将余弦区间 [-1,1] 映射至了 [0,1] 。
最佳实践
运行代码
if __name__ == '__main__':
from bert_serving.client import BertClient
bc = BertClient()
nlper = Nlper(bert_client=bc)
similarity = nlper.get_text_similarity('你好', '您好')
print(similarity)
控制台输出
0.83
Process finished with exit code 0

平台集成
后面的工作就是将这套算法集成到测试平台上咯。过程就不在这赘述了,我们直接演示一下具体使用。

我们直接拿本机的登录接口进行一次演示,首先我们得创建一条用例:
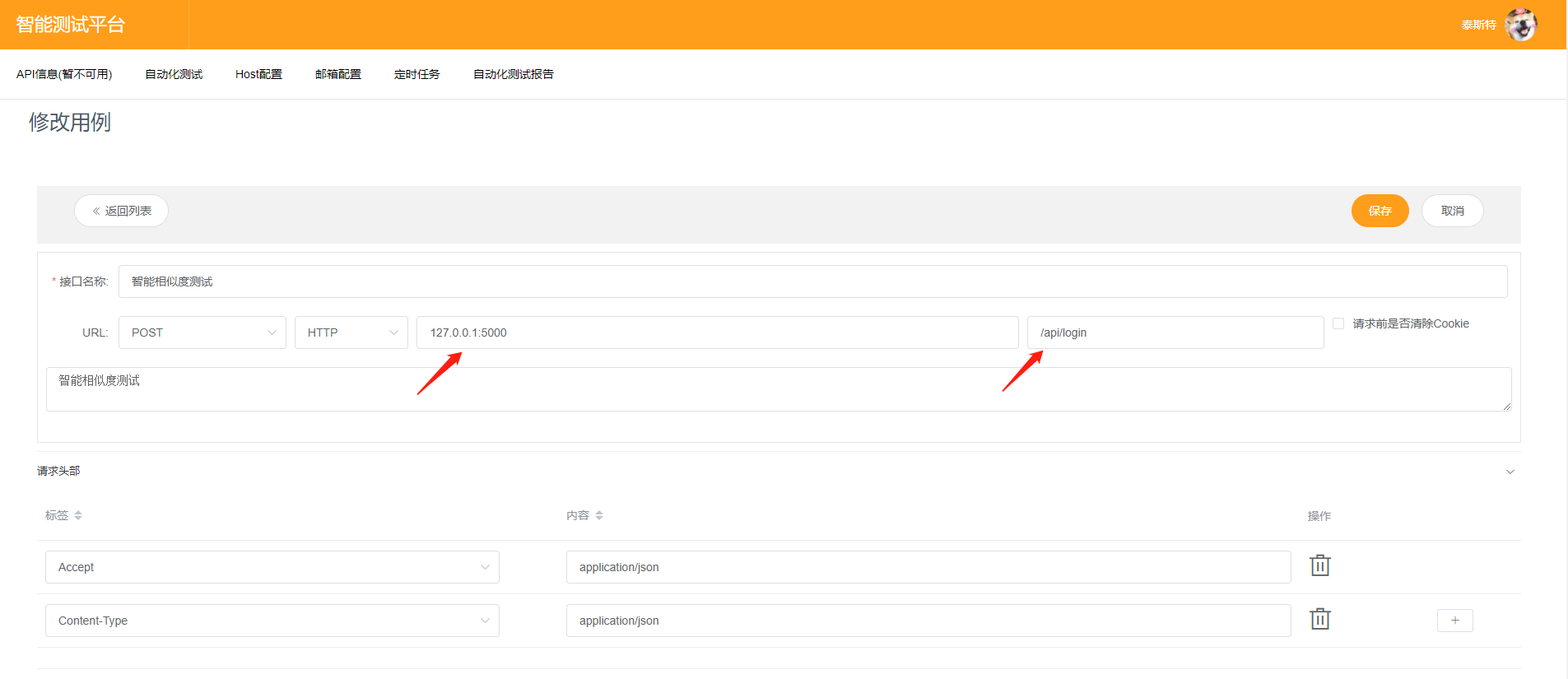
然后输入错误的用户名以及密码进行一次测试,于是成功获取到了接口返回的数据结构:

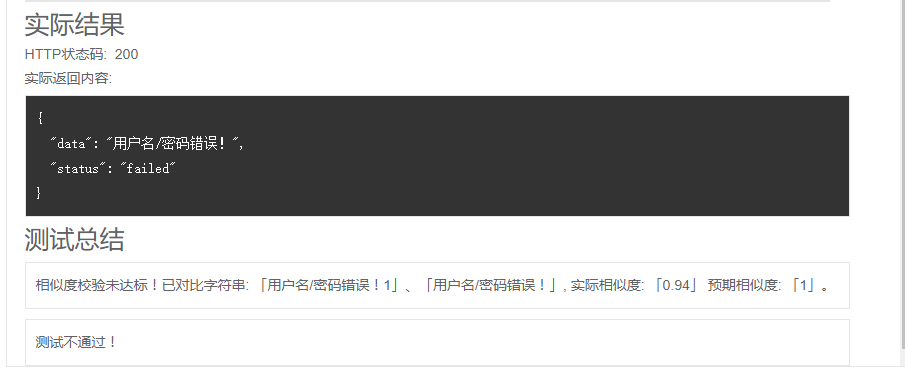
然后我们再次进入用例修改页面,将接口返回中的data抽取为全局变量,然后点击 『智能相似度校验』,在文本一中填入 ${data}1,文本二中填入 ${data} , 目标相似度中填入: 1。(强行把他变成了一个永远无法通过的用例)
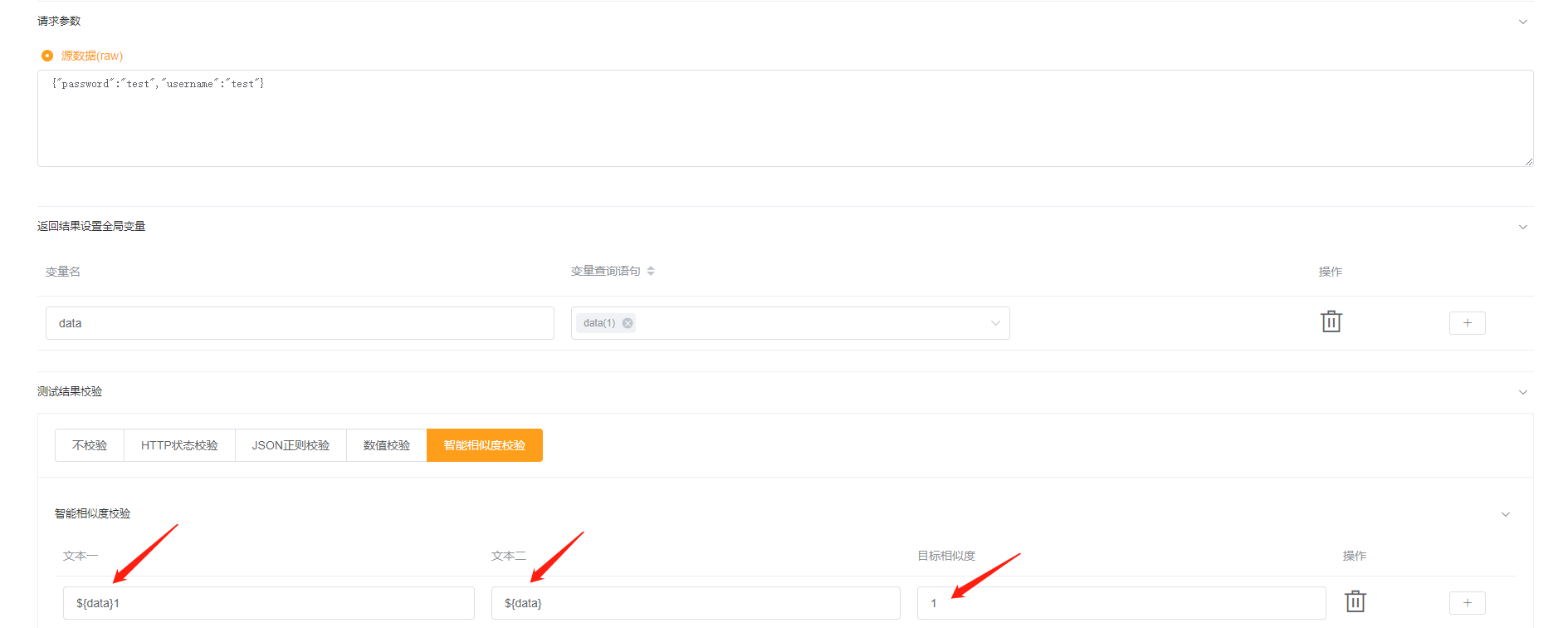
然后我们点击测试,可以发现测试并没有通过 (能通过就有鬼了哦) ,可以在下图看到算法计算出来的文本相似度为 0.94。嗯,合理。
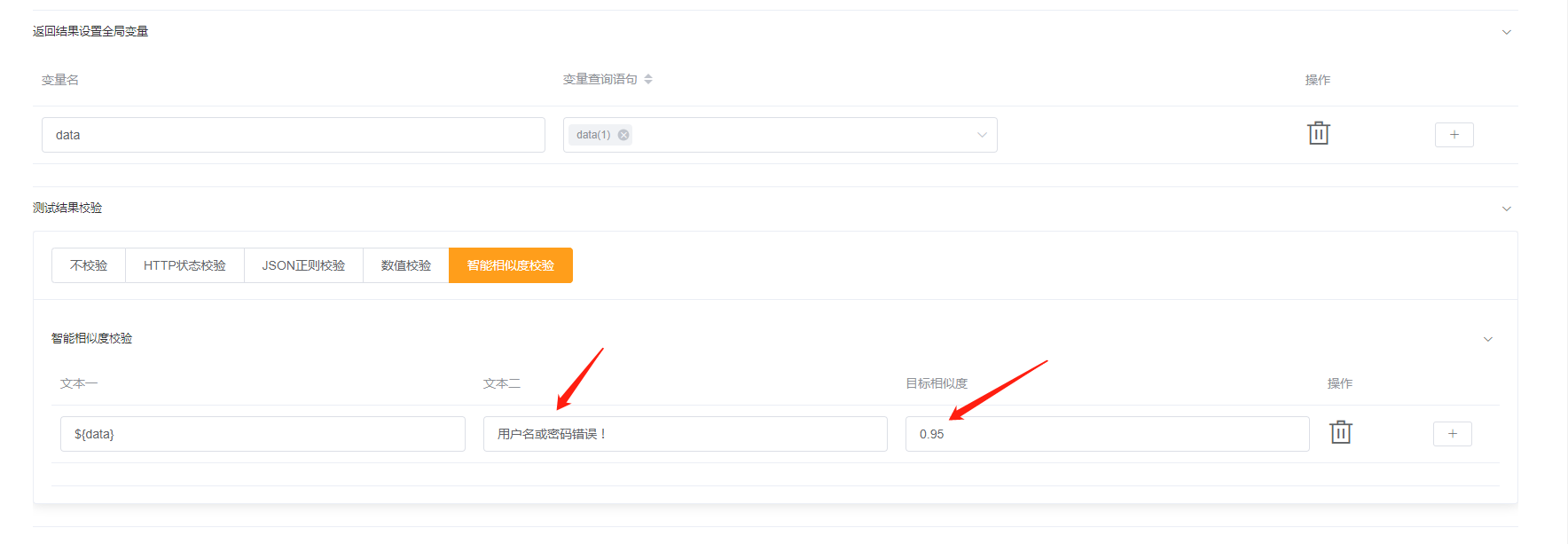
我们再次修改用例,(已知接口正确返回的数据为 「用户名/密码错误!」),将文本二改为 「用户名或密码错误!」、目标相似度调整为 0.95
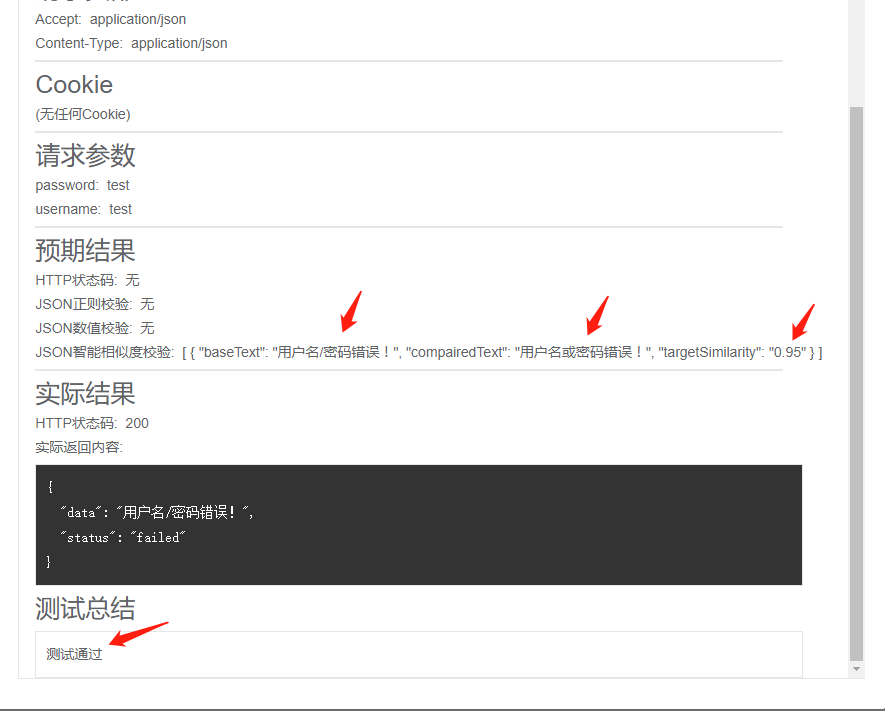
执行测试后我们可以看到测试已通过,说明两个文本的相似度达到了0.95以上。
至此目前的一个小成果就演示完毕啦。
虽然说这不一定真的能够给测试带来特别显著的提升,但是至少在不断尝试创新的过程中笔者慢慢感受到人工智能是能够影响测试、给予测试更多可能性的。

结尾
欢迎大家扫码关注我的公众号「智能自动化测试」,回复:测试进阶教程,即可免费获得 进阶教程 ~