

问题
一旦了解了基本知识,构建API就没那么复杂了。我们向服务器发送HTTP请求,它做一些工作,然后返回请求的数据。这个过程很简单。但是当请求需要完成超出其范围的工作时会发生什么呢?例如,当我提醒一个用户,系统需要向受影响的所有用户发送一个推送通知。在请求周期内处理这些通知将延迟最终的响应。随着我们的通知系统变得越来越复杂,很明显我们需要更多的等待时间。
处理通知然后推送通知需要调用数据库和外部api。该过程拆解如下:
- 发生需要生成通知的操作。
- 构造通知并将其插入数据库。
- 该通知被映射到将接收它的一组用户。
- 我们为需要通知的用户检索所有设备的列表。
- 我们向他们在我们这里注册的每台设备发送推送通知。
- 我们更新该通知的发送状态并删除无效的设备令牌。
这6个步骤中的每一个都至少有一个与之关联的数据库查询。当需要将单个通知发送到单个用户的设备时,这个过程可以非常快地完成,但是如果需要更长的时间,那么请求就有超时的风险。我们必须将这个逻辑分离出来,以便可以在请求/响应周期之外处理它。
任务队列
任务队列管理了一份需要在单独进程中完成的工作列表。一个系统将工作添加到队列的末尾,而另一个系统将工作项从顶部弹出。我们需要创建一个表示上述工作的任务对象,然后将其添加到任务队列中。在我们开始之前,我需要问几个基本问题。
1. 任务队列将位于何处?
我们已经在使用Redis作为缓存系统,所以当我开始寻找构建队列的方法时,Redis是一个显而易见的选择。它不仅能够很好地处理这种模式,而且有很多在线资源讨论它是如何构建的。对此还有许多其他选项,比如如果你正在使用谷歌应用程序引擎(GAE),你应该研究谷歌云任务队列,它提供了更多内置功能。
2. 我们如何知道何时将项添加到队列中?
我花了一点时间想弄明白。我不想每n毫秒轮询一次Redis来查找新作业。我发现了两种方法。第一个是Redis的发布/订阅系统。对于这个方法,我将有一个订阅通道并在其上接收消息的函数。这些消息将提醒我准备运行一个新任务。第二种方法是使用一个简单的Redis列表作为队列,使用阻塞列表pop原语(BLPOP),等待直到一个项目准备好并将其从队列中移除。
在这个方案的第一次迭代中,我们使用了Pub/Sub模式,但是它增加了一层不需要的复杂性。此外,当系统扩展时,我们必须做额外的工作来验证消息没有在多台机器上处理。因此,我们切换到List和BLPOP方法。
3.我们向任务队列插入什么?
“嗯,我们把任务对象插进去,嗯……”你可能会这么想,但是队列只支持添加字符串,所以我们不能真正插入一个对象。我们必须把关键值推到末端。这个问题困扰着我,主要是因为我不确定“最好”的方法是什么。键应该是数据库的主ID,还是对Redis中的某个对象的引用?我们应该在哪里画出这条线呢?我决定将events主键ID发送到队列,并允许任务决定如何处理它。例如,如果用户为一篇文章进行了upvote,我将把vote操作的ID推到vote_queue中,一旦它从队列中弹出,服务将知道如何处理它。
方案
好了,我已经描述这个问题,并回答了我的一些问题(希望这些问题也回答了你的一些问题),现在让我们看一下这将如何工作的,如图:
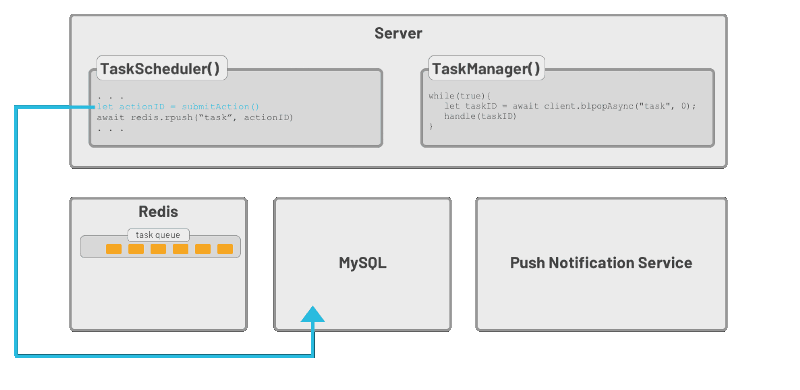
从图中可以看到,我们有两个服务在服务器上运行。TaskScheduler将创建一个新任务,将其添加到数据库,然后将任务的ID推到任务队列的末尾。TaskManager等待任务添加到队列后适当地处理它。
代码示例
TaskScheduler.js是一个基本的例子,演示了如何将任务添加到数据库中,然后将其推到任务队列的末尾。一旦将其推入队列,当TaskManager开始监听时,它将开始处理。
/// TaskScheduler.js is an example of how one would schedule tasks on the task queue.
var redis = require('redis');
var redisClient = redis.createClient();
const TaskScheduler = async function(work){
// If you're using MySQL we would add the "Task" to the database.
let task = await Database.query("INSERT INTO Task ...");
let taskID = task.insertId;
await redisClient.rpush("task_queue", taskID);
}
TaskQueue.js演示如何在NodeJS中使用async/await实现它的基本示例。
/// TaskQueue.js would be placed in your server and when it's launched
/// to begin listening for tasks. Or, it can be extracted out to a seperate service.
var redis = require("redis");
/// TaskManager for listening to the queue and running work.
const TaskManager = async function(redisClient){
while(true){
let task;
try{
task = await redisClient.blpopAsync("task_queue", 0);
} catch(error) {
// Redis connect could have closed. Handle those cases here.
process.exit(1);
}
try {
await HandleTask(task);
} catch (error) {
// Handling the task failed. Try rerunning it or adding it to a "Failure" queue.
}
}
}
/// Function that handles all the work for this task.
const HandleTask = async function(task){
// Do the work!
}
// Run the TaskManager function
(async function() {
// Initialize redis
let redisClient = redis.createClient();
await TaskManager(redisClient)
})()
改进
由于我给出的代码只是一个基本的示例,所以还有很多地方需要改进。你可能想问,TaskManager应该放在哪里?如果直接将其添加到服务器,则在高使用率期间可能会使系统过载,但这取决于你的任务执行的工作类型。在我们的系统中,我们将所有这些提取到一个新的微服务中,并使用一个简单的API来检查它的状态。
同样,在示例代码中,我们一次运行一个任务。这并不理想,因为长时间运行的任务可能得备份整个队列。因此,我们应该有一个运行任务池,根据需要添加和删除这些任务。一旦池被填满,while循环将等待一个新的空间。
概述
本文所描述的方法并不太复杂,但是它将业务逻辑与应用程序逻辑解耦。有了这个小的更改,我们就可以开始迭代系统的性能,并构建更健壮的队列和服务。我们还可以复制此方法来处理各种长时间运行的流程,如推荐系统、文本处理等。
