

译自Bigtable_A Distributed Storage System for Structured Data 作者:Fay Chang, Jeffrey Dean, Sanjay Ghemawat, Wilson C.Hsieh, Deborah A. Wallach Mike Burrows, Tushar Chandra, Andrew Fikes, Robert E.Gruber
8 实际应用
截至2006年8月,Google内部共有388个非测试用Bigtable集群运行在各类服务器集群上,合计约为24500个Tablet服务器。表1为每个集群上Tablet服务器的大致分布情况。很多集群是用于开发环境的,因此会有一段时期比较空闲。观察一个由14个集群、8069个Tablet服务器组成的集群组可以发现,集群每秒的吞吐量超过了1200000次请求,发送到系统的RPC请求导致的网络负载达到741MB/s,系统发出的RPC请求网络负载约为16GB/s。

表2为一些目前正在使用的表的相关数据。有些表存储的是用户数据,有些存储的则是用于批处理的数据;表的总大小、每个数据项的平均大小、从内存中读取的数据的比例、表的Schema的复杂程度上都有很大的差别。本节主要介绍Bigtable在三个产品研发团队的应用情况。
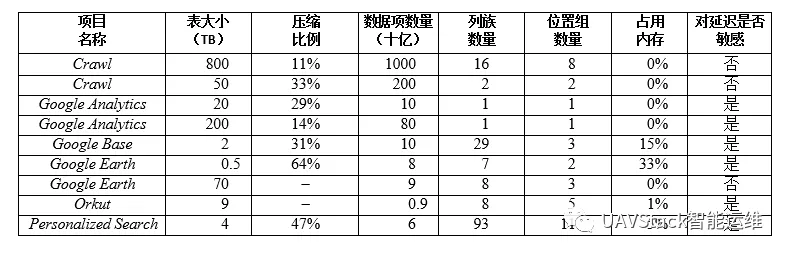
8.1 Google Analytics
Google Analytics用于帮助Web站点管理员分析其网站的流量特点,涉及整体状况的统计数据(如每天独立访问的用户数量、每天每个URL的浏览次数)及用户使用网站的行为报告(比如根据用户之前访问的某些页面,统计出几成的用户购买了商品)。
Web站点的管理员只需要在Web页面中嵌入一小段JavaScript脚本就可以使用Bigtable服务了。Javascript程序在页面被访问的时候调用,记录了Google Analytics需要使用的各种信息,比如用户标识、获取的网页相关信息。Google Analytics把汇总的这些数据提供给Web站点管理员。
我们简要介绍一下Google Analytics使用的两类表。RawClick表(大约有200TB数据)的每一行存放了一个终端用户的会话。行的名字是一个元组,包含Web站点名称及用户会话创建时间。这种模式保证了对同一个Web站点的访问会话是连续的,并按时间顺序分类。RawClick表可以压缩到原来大小的14%。
Summary表(大约有20TB的数据)包含了关于每个Web站点的各种预定义汇总信息。MapReduce定期任务根据RawClick表的数据生成 Summary表。每个MapReduce进程都从RawClick表中提取最新的会话数据。系统的整体吞吐量取决于GFS的吞吐量。Summary表能够压缩到原来大小的29%。
8.2 Google Earth
Google通过一组服务为用户提供高分辨率的地球表面卫星图像。用户可以通过基于Web的GoogleMaps访问接口(maps.google.com)或定制的客户端软件访问Google Earth。用户可以通过GoogleEarth浏览地球表面的图像,并在不同的分辨率下平移、查看和注释这些卫星图像。这个系统使用一个表存储预处理数据,使用另外一组表存储用户数据。
数据预处理环节使用一个表存储原始图像。在预处理过程中,图像被清除,图像数据合并到最终的服务数据中。这个表包含了大约70TB的数据,所以需要从磁盘读取数据。图像已经被高效压缩过了,因此存储在Bigtable后不需要再压缩了。
Imagery表中每行代表一个地理区域。行都有名称,确保毗邻的区域存储在一起。Imagery表中有一个列族用来记录每个区域的数据源。这个列族包含了大量的列:基本上每个列对应一个原始图片的数据。由于每个地理区域都是由几张图片构成的,因此这个列族非常稀疏。
数据预处理高度依赖MapReduce的数据传输。在运行某些MapReduce任务的时候,整个系统中每台Tablet服务器的数据处理速度大于1MB/s。
服务系统使用表来索引GFS中的数据。这个表相对较小(大约是500GB),但必须在保证较短的响应延时的前提下,每秒为每个数据中心处理几万个查询请求。因此,这个表存储在上百个Tablet服务器上,并且保护内存列族。
8.3 Personalized Search
PersonalizedSearch(www.google.com/psearch)是可选服务,记录用户的查询和点击,涉及Google的各种服务,比如Web查询、图像和新闻。用户可以浏览他们查询的历史,重复他们之前的查询和点击操作;也可以定制基于Google历史使用习惯模式的个性化查询结果。
PersonalizedSearch使用Bigtable存储每个用户的数据。每个用户都有一个唯一的用户id,每个用户id与一个列名绑定。不同类型的行为存储在单独的列族中(比如,有的列族用来存储所有的Web查询)。每个数据项都被用作Bigtable的时间戳,记录了相应的用户行为发生的时间。PersonalizedSearch通过MapReduce任务生成用户数据图表,用于个性化当前的查询结果。
Personalized Search的数据会复制到几个Bigtable集群上,这样就增强了数据可用性,同时减少了由客户端与Bigtable集群之间的“距离”造成的延时。PersonalizedSearch的开发团队最初建立了一个基于Bigtable的“客户侧”复制机制,确保所有复制节点的一致性。当前系统则使用了内建的复制子系统。
PersonalizedSearch存储系统允许其它团队在自己的列中加入新的用户数据,因此很多Google服务使用PersonalizedSearch存储系统保存用户级的配置参数和设置,这样便产生了大量的列族。为了更好地支持数据共享,我们增加了简单的配额机制,限制用户在共享表中使用的空间,同时也为使用PersonalizedSearch系统存储用户级信息的产品团体提供了隔离机制。
9 经验教训
在设计、实现、维护和支持Bigtable的过程中,我们积累了很多有用的经验教训。
比如,我们发现,很多类型的错误都会导致大型分布式系统受损,这些错误不仅仅是常见的网络中断或很多分布式协议中设想的fail-stop类型的错误。我们遇到的错误类型包括内存数据损坏、网络中断、时钟偏差、机器挂起、扩展的非对称网络分区、其它系统的Bug(比如Chubby)、GFS配额溢出、计划内和计划外的硬件维护。基于经验积累,我们学会了通过修改协议来解决这些问题。我们在RPC机制中使用了校验和。设计系统功能时,不对其它功能做任何假设。例如,我们不再假设一个特定的Chubby操作只返回错误码集合中的一个值。
另外,要在全面了解一个新功能的潜在用途后,再决定是否开发这一功能。比如,根据最初的计划,我们的API支持常见事务处理。但考虑到暂时还用不到这个功能,因此没有去实现。现在,Bigtable上已经有了很多实际应用。经过观察,我们发现大多数应用程序只需要单个行上的事务功能。有些应用需要分布式事务功能,用于维护二级索引,我们通过特殊机制来满足这一需求。新机制的通用性虽然比分布式事务差很多,但更有效(特别是对于涉及上百行数据的更新操作时),而且非常符合跨数据中心复制方案的优化策略。
我们还发现,系统级的监控对Bigtable非常重要(比如,监控Bigtable自身及使用Bigtable的客户端程序)。我们扩展了RPC系统,因此一个RPC调用的例子可以详细记录代表RPC调用的很多重要操作。通过这个功能,我们可以检测修正很多问题,比如Tablet数据结构上的锁的内容;在修改操作提交时对GFS的写入非常慢的问题;以及在METADATA表的Tablet不可用时,对METADATA表的访问挂起的问题。每个Bigtable集群都在Chubby中注册了,通过监控,我们可以了解集群的状态、大小、集群运行的软件版本、集群流入数据的流量以及是否有导致集群高延时的潜在因素。
最宝贵的经验是简单设计的价值。考虑到系统现有的代码量(约100000行生产代码)、未来新增代码以各种计划外情况,我们认为简洁的设计和编码能够极大地便利维护和调试工作。以Tablet服务器成员协议为例。我们第一版的协议很简单:Master服务器定期与Tablet服务器签订租约,租约过期时Tablet服务器Kill掉自己的进程。不过出现网络问题时,协议的可用性会大大降低,Master服务器恢复时间也会延长。为此,我们们多次重新设计了该协议。不过最终的协议过于复杂,且依赖了其他应用很少用到的Chubby功能。但调试Bigtable代码和Chubby代码的过程中浪费了大量时间。最后,我们只好废弃了这个协议,重新制订了一个只使用Chubby常用功能的简单协议。
10 相关工作
Boxwood项目的有些组件在某些方面与Chubby、GFS及Bigtable类似,也支持分布式协议、锁、分布式Chunk存储以及分布式B-tree存储。但Boxwood的组件提供更底层的服务,目的在于提供创建类似文件系统、数据库等高级服务的基础构件,而Bigtable则直接支持客户端程序的数据存储。
现在不少项目已经实现了在广域网上的分布式数据存储或者高级服务,通常是 “Internet规模”的,例如CAN、Chord、Tapestry和Pastry项目关于分布式Hash表的研究。这些系统应对的问题主要包括不同的传输带宽、不可信的协作者及频繁的更改配置等。另外,Bigtable也不关注去中心化和Byzantine灾难冗余。
就提供给应用程序开发者的分布式数据存储模型而言,分布式B-Tree和分布式Hash表提供的Key-value对模型有很大的局限性。Key-value对模型非常有用,但我们还应该为开发者提供更多组件。我们的模型提供的组件支持稀疏的半结构化数据。另外,这些组件也非常简单,能够高效地处理平面文件;且足够透明(通过位置组),允许用户调整系统的重要行为。
有些数据库厂商已经开发出了并行数据库系统,能够存储海量数据。Oracle的RAC使用共享磁盘存储数据(Bigtable使用 GFS),并配有分布式锁管理系统(Bigtable 使用 Chubby)。IBMDB2并行版基于类似于Bigtable但不共享任何信息的架构。每个DB2的服务器负责处理存储在关系型数据库中的表中某个行的子集。这些产品都提供了具有事务功能的完整关系模型。
Bigtable的位置组提供了基于列的存储方案,实现了出色的压缩和磁盘读取性能。类似产品包括C-Store、商业产品SybaseIQ、SenSage、KDB+及MonetDB/X100的ColumnDM存储层。AT&T的Daytona数据库在平面文件中提供垂直和水平数据分区,且数据压缩性能良好。位置组不支持Ailamaki系统在CPU缓存级别的优化功能。
Bigtable通过memtable和SSTable存储对表的更新,这一点与Log-StructuredMerge Tree存储索引数据更新的方法类似。在两个系统中,排序数据在写入磁盘前都先存放在内存中,读取操作必须从内存和磁盘中合并数据。
C-Store和Bigtable比较相似:两者都采用Shared-nothing架构;都有两种不同的数据结构,一种用于当前的写操作,另外一种存放“长时间使用”的数据;并且提供两个存储结构间的数据搬运机制。但两个系统在API接口函数方面差异很大:C-Store的操作更像关系型数据库;而Bigtable则提供了低层次的读写操作接口,且设计目标是能够支持每台服务器每秒数千次操作。C-Store同时也是“读性能优化的关系型数据库”,而Bigtable对于读写密集型应用都具备良好的性能。
Bigtable也需要解决所有的Shared-nothing数据库所面对的负载和内存均衡方面的问题。我们的问题在某种程度上简单一些:(1)我们不需要考虑同一份数据可能有多个拷贝的问题,即同一份数据可能由于视图或索引的原因以不同的形式呈现出来;(2)我们让用户决定哪些数据应该放在内存里、哪些放在磁盘上;(3)我们的系统中没有复杂的查询执行或优化工作。
11 结论
Bigtable集群从2005年4月开始已经投入使用。截至目前,我们用了约7人年来设计和实现这个系统。截至2006年4月,已经有60多个项目在使用Bigtable。我们的用户对Bigtable提供的高性能和高可用性表示满意。用户可以根据自身系统对资源的需求,通增加机器,扩展系统的承载能力。
由于Bigtable提供的编程接口并不常见,用户适应新的接口有一定难度。新用户开始确实不熟悉Bigtable接口的使用方法,但最终都能熟练掌握。事实证明,我们的设计在实践中行之有效。
我们现在正在设计新功能,比如支持二级索引、支持多Master节点的跨数据中心复制的Bigtable的基础构件。我们现在已经开始将Bigtable部署为服务,供其它产品团队使用。这样产品团队就不再需要维护自己的Bigtable集群。随着服务集群的扩展,我们需要在Bigtable系统内部处理更多关于资源共享的问题。
最后,我们发现,开发Google自己的存储解决方案具有很多优点。为Bigtable设计自己的数据模型后,我们的系统变得更加灵活。另外,由于我们决定着Bigtable的实现过程及其使用的Google的其他基础构件,因此在系统遇到瓶颈或效率低下时,能够快速解决这些问题。
参考资料
- Fay Chang, Jeffrey Dean, Sanjay Ghemawat, Wilson C.Hsieh, Deborah A. Wallach Mike Burrows, Tushar Chandra, Andrew Fikes and Robert E.Gruber. Bigtable_A Distributed Storage System for Structured Data
- Yan Wei. Google Bigtable中文版
