

1、Spring Cloud Sleuth介绍
Spring Cloud Sleuth是Spring Cloud体系下的日志追踪服务,它实现了Zipkin的采集器,可以与Zipkin配合使用。
项目中只需要引入spring-cloud-starter-zipkin,然后配置好zipkin的地址即可:
spring.zipkin.baseUrl: https://192.168.99.100:9411/
在官方文档中说了Spring Cloud Sleuth可以兼容OpenTracing协议:
具体请参考:cloud.spring.io/spring-clou…
2、Spring Cloud Sleuth兼容Jaeger
jaeger 是CNCF成员,是对opentracing 规范的实现,也实现了对zipkin采集数据的兼容,并且是Istio官方推荐的实现。我们可以利用Spring Cloud Sleuth兼容Jaeger。具体做法如下:
- maven中引入依赖
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-zipkin</artifactId>
</dependency>
<dependency>
<groupId>io.opentracing.brave</groupId>
<artifactId>brave-opentracing</artifactId>
</dependency>
<dependency>
<groupId>io.opentracing.contrib</groupId>
<artifactId>opentracing-spring-jaeger-cloud-starter</artifactId>
<version>2.0.0</version>
</dependency>
- 将zipkin的地址改为jaeger的collector地址
spring.zipkin.baseUrl: https://jaeger:9411/
- 【测试】用feign进行服务间调用后,在jaeger的查询页面上就可以出现调用链路了:
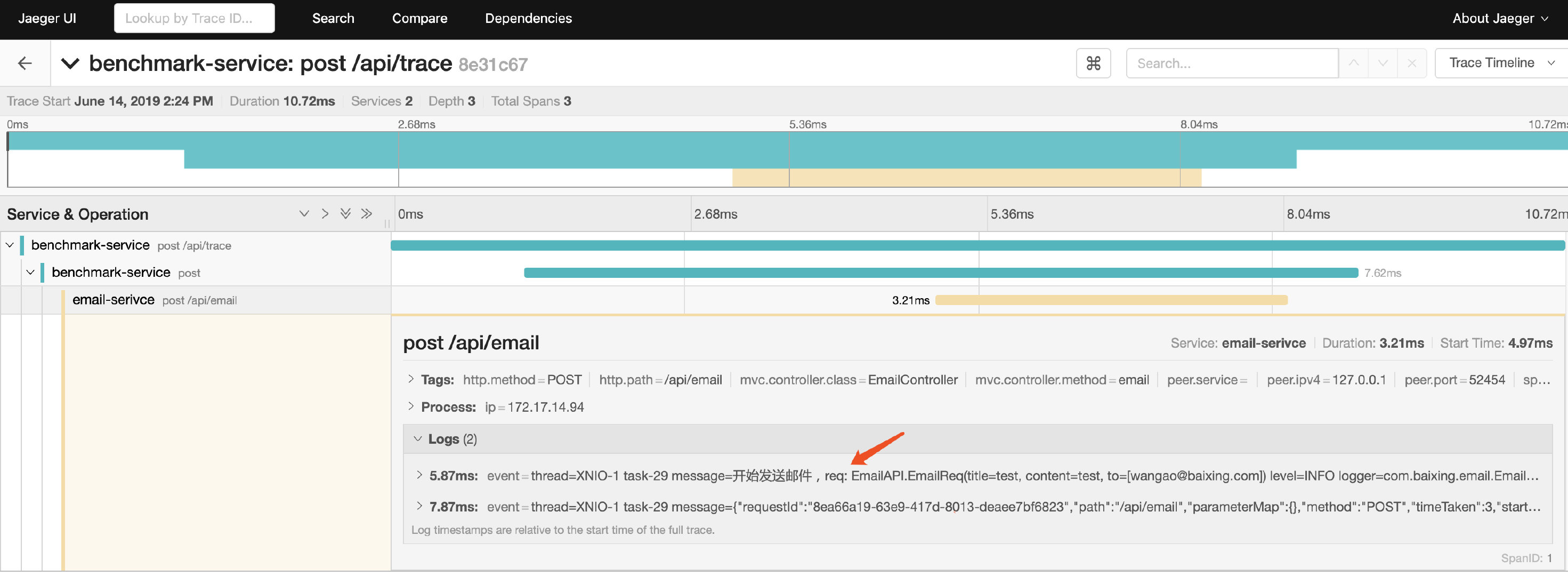
- 【结论】相比于zipkin,jaeger可以在查询链路的同时把log也一起显示出来,非常方便
3、去除Sping Cloud Sleuth
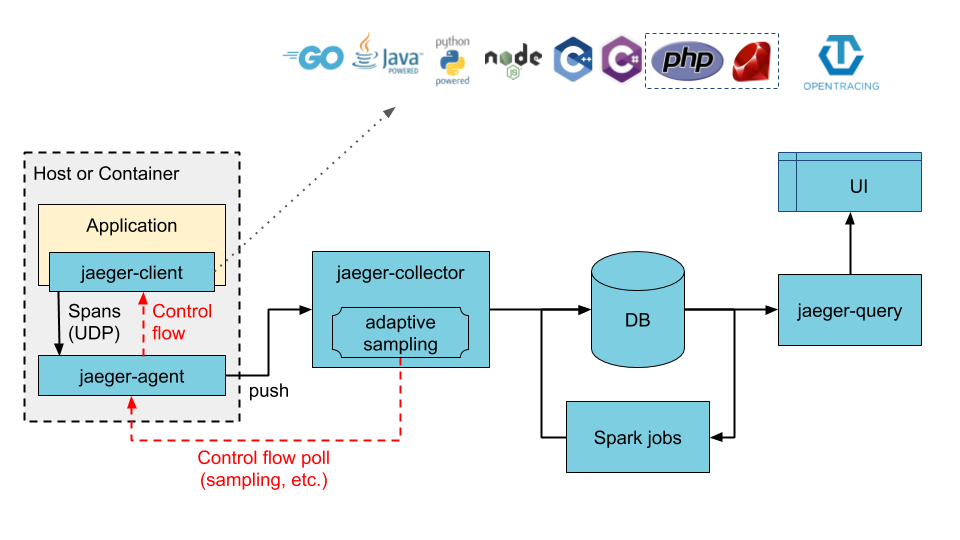
利用Spring Cloud Sleuth最大的优点是对于现有系统的兼容性,但是采集数据是用HTTP协议发送到jaeger的collector端口上,在产线数据量大的情况下会出现明显的性能问题。jaeger官方推荐的做法是利用agent方式进行数据采集,可参考官方架构图和说明文档:www.jaegertracing.io/docs/1.8/ar…
- 去除Spring Cloud Sleuth依赖,只保留
opentracing-spring-jaeger-cloud-starter
<dependency>
<groupId>io.opentracing.contrib</groupId>
<artifactId>opentracing-spring-jaeger-cloud-starter</artifactId>
<version>2.0.0</version>
</dependency>
- 配置jaeger的地址
opentracing:
jaeger:
enabled: true
log-spans: true
const-sampler:
decision: true
udp-sender:
host: localhost
port: 6831
- 【测试】用feign进行服务间调用后,在jaeger的查询页面上就可以出现调用链路了:
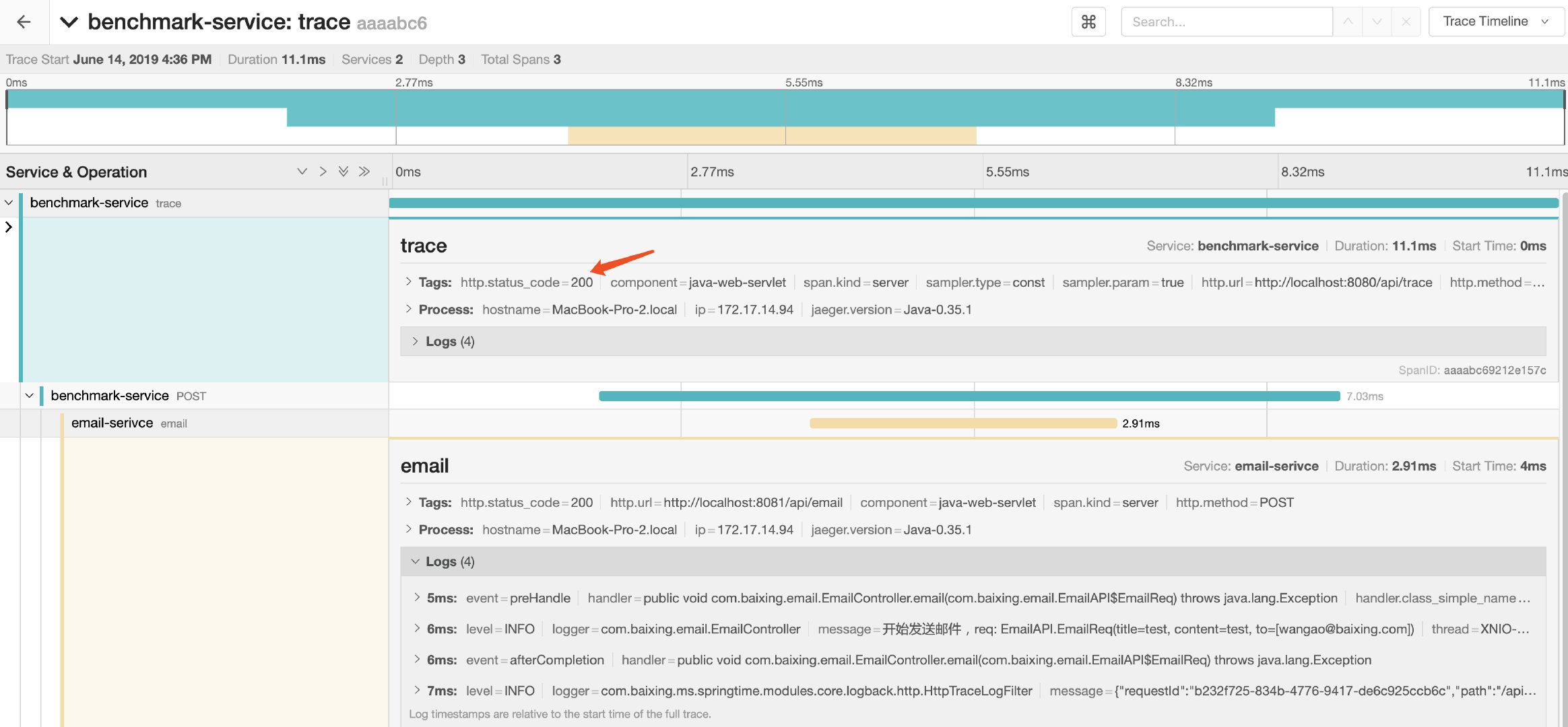
- 【结论】相比于
Spring Cloud Sleuth,opentracing默认的tags更为合理和直观
4、引发的问题
去除了Spring Cloud Sleuth之后,随之会带来两个问题:
- 1、日志中的traceId和spanId无法显示了
Spring Cloud Sleuth默认将traceId和spanId绑定到了slf4j的MDC中,这样在日志打印的时候可以很方便的知道当前日志的traceId。在ELK的中央日志架构下,可以用traceId很方便的将当前请求的调用链日志筛选出来。

- 2、无法利用Spring Cloud Sleuth传递自定义的值
Spring Cloud Sleuth提供了很便捷的借口来传递用户自定义的链路数据(比如requestId等)

关于如何解决以上两个问题,下一篇文章会给出解决方案()
