

在服务数量增多到一定程度,出问题的可能性越来越大,现在各种常见的架构手段,高可用手段都是为了提升系统的可用性,给用户提供更好的体验。而全链路压测则相当于对服务进行一次体检,了解当前系统的状况
定义:基于线上环境和实际业务场景,通过模拟海量的用户请求,来对整个系统链路进行压力测试。
目的:
- 验证新功能的稳定性
- 验证峰值流量下服务的稳定性和伸缩性
- 对线上服务进行更准确的容量评估
- 找到系统瓶颈并且进行优化
压测极限标准
- load不超过 (机器核数* 0.6)
- 网卡流量不超过网卡容量的0.6,超过的话可能延迟比较大
- 请求超时不超过请求总量的十万分之一
- QPS不低于预估的85%,否则需要优化,或者给出合理的解释
压测方案
为模拟更真实的环境,压测机器与线上机器同等配置,仿照线上机器的部署情况部署。压测数据尽可能采用线上真实数据。
方案一
复用线上环境压测,在低峰期,比如凌晨3点钟,回放读请求,写请求无法压测,因为写请求会导致数据污染。
压测可以采用本地日常环境,或者采用线上环境:
-
日常环境:要求低,如果想要效果真实,可以构建与线上服务一模一样的配套设施,缺点是成本高
-
线上环境:完全采用线上环境,测量机器的抗压能力,流量逐渐的分配到越来越少的服务器上,观察10分钟以上,直到服务器处理的极限。
- 需要强大的压测平台
- 立体监控系统
- 服务治理平台
- 可参加各大公司的全链路压测系统,在文末参考中。
流量复用工具:TCPcopy
方案二
方案一很难对整个集群的进行压测,容易以偏概全,无法评估系统的真实性能。如果想做全链路压测:
-
尽可能构造真实数据
-
压测线上真实环境
-
核心技术
-
压测标识透传
- 跨线程:采用InheritableThreadLocal父线程ThreadLocal中的变量传递给子线程,保证了压测标识的传递
- 跨进程:存储在请求的Header中,做一些标识。
-
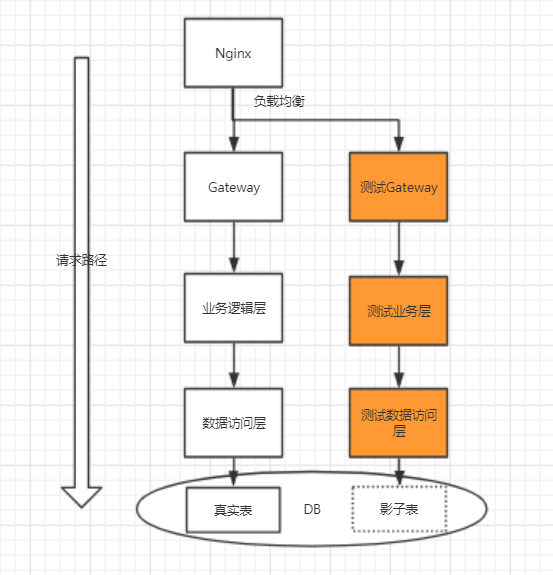
压测服务隔离,不能因为压测影响正常服务
- 根据业务需求在线上对整条链路创建一个压测分组,隔离出一批机器用于压测,在请求入口处,可以将请求进行分割
-
压测数据隔离,不影响真实数据
-
使用影子表进行数据隔离,线上使用同一个数据库,只是在写入数据的时候将数据写入到另外一张“影子表”中。
-
最后
附录中给了很多互联网大厂的真实案例,可以一起学习
