

执行顺序
一般执行顺序很显然按照创建顺序执行,对大对数开发者来说并不陌生。
像是这样:
foo(); // 报错
var foo = function () {
console.log('foo1');
}
foo(); // foo1
var foo = function () {
console.log('foo2');
}
foo(); // foo2
然而有的时候会是这样:
foo(); // foo2
function foo() {
console.log('foo1');
}
foo(); // foo2
function foo() {
console.log('foo2');
}
foo(); // foo2
我们可以看到,作为函数调用的时候,会出现三个foo2。其实 JavaScript 引擎并非一行一行地分析和执行程序,在执行之前会对一些对结构进行分析执行。比如第一个例子中的变量提升,和第二个例子中的函数提升。
那么JS又是如何进行结构化的解析的呢?执行过程中又做了什么动作呢?
栈
栈又是什么?
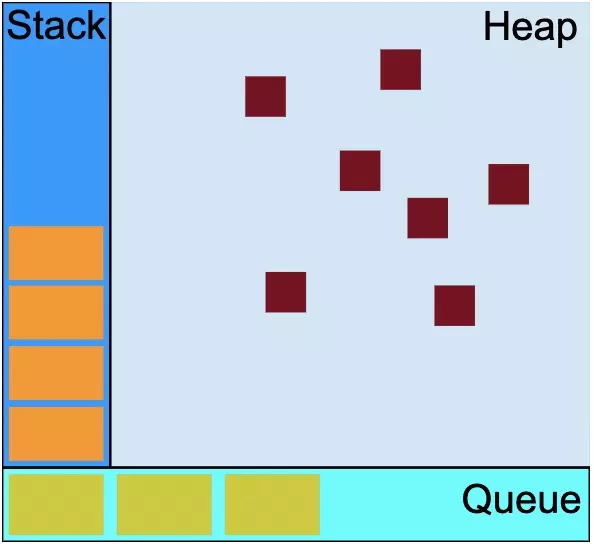
这张图分别展示了栈、堆和队列,其中栈就是我们所说的执行上下文栈;堆是用于存储复杂类型比如:对象,数组等等。队列就是异步队列,用于事件循环(event loop)的执行。
JS代码在引擎中是以代码片段的方式来分析执行的,而并非一行一行来分析执行。
简单的例子
//入栈过程
Stack.push("chris")
Stack.push("james")
Stack.push("kobe")
//出栈过程
Stack.pop() //["chirs","james"]
Strack.pop() //["chirs"]
Stack.pop() //[]
可以看出,栈是执行过程是一个先入后出的过程。
可执行代码
而这些代码片段的可执行代码无非为三种:全局代码(Global code)、函数代码(Function Code)、eval代码(Eval code)。
这些可执行代码在执行的时候又会创建一个一个的执行上下文(Execution context)。例如,当执行到一个
函数的时候,JS引擎会做一些“准备工作”,而这个“准备工作”,我们称其为执行上下文。
那么随着我们的执行上下文数量的增加,JS引擎又如何去管理这些执行上下文呢?这时便有了执行上下文栈。
执行上下文栈
问题来了,我们写的函数多了去了,如何管理创建的那么多执行上下文呢?
所以 JavaScript 引擎创建了执行上下文栈(Execution context stack,ECS)来管理执行上下文
为了模拟执行上下文栈的行为,让我们定义执行上下文栈是一个数组:
Stack= [];
试想当 JavaScript 开始要解释执行代码的时候,最先遇到的就是全局代码,所以初始化的时候首先就会向执
行上下文栈压入一个全局执行上下文,我们用 globalContext 表示它,并且只有当整个应用程序结束的时候,
Stack才会被清空,所以程序结束之前, Stack最底部永远有个 globalContext:
Stack = [
globalContext// 一开始只有全局上下文
];
一个简单的例子:
function fun3() {
console.log('fun3')
}
function fun2() {
fun3();
}
function fun1() {
fun2();
}
fun1();
每当一个函数执行,就会创建一个执行上下文,并且压入执行上下文栈,当函数执行完毕的时候,就会将函
数的执行上下文从栈中弹出。
// fun1()
Stack .push(<fun1> functionContext);
//[globalContext,<fun1> functionContext]
// fun1中有fun2,还要创建fun2的执行上下文
Stack .push(<fun2> functionCofuntext);
//[globalContext,<fun1> functionContext,<fun2> functionCofuntext],
// fun2还调用了fun3
Stack .push(<fun3> functionContext);
//[globalContext,<fun1> functionContext,<fun2> functionCofuntext,<fun3> functionContext]
// fun3执行完毕
Stack .pop();
//[globalContext,<fun1> functionContext,<fun2> functionCofuntext]
// fun2执行完毕
Stack .pop();
//[globalContext,<fun1> functionContext]
// fun1执行完毕
Stack .pop();
//[globalContext]
// javascript接着执行下面的代码,但是Stack 底层永远有个globalContext
一个复杂的例子:
var scope = "global scope";
function checkscope(){
var scope = "local scope";
function f(){
return scope;
}
return f();
}
checkscope();
var scope = "global scope";
function checkscope(){
var scope = "local scope";
function f(){
return scope;
}
return f;
}
checkscope()();
两段代码执行的结果一样,但是两段代码究竟有哪些不同呢?
答案就是执行上下文栈的变化不一样。
先模拟第一段代码:
Stack.push(<checkscope> functionContext);
Stack.push(<f> functionContext);
Stack.pop();
Stack.pop();
再模拟第二段代码:
Stack.push(<checkscope> functionContext);
Stack.pop();
Stack.push(<f> functionContext);
Stack.pop();
我们可以发现二三部分出栈和入栈是不同的。
总结
- JS代码在引擎中是以
一段一段的方式来分析执行的,而并非一行一行来分析执行 - 可执行代码分为三种:
全局代码(Global code)、函数代码(Function Code)、eval代码(Eval code),其中全局代码、函数代码比较常见,关于eval代码可参考JavaScript 为什么不推荐使用 eval? - 每遇到
函数执行的时候,就会创建一个执行上下文,执行上下文会进入执行上下文栈中 - 程序开始最先入栈和程序结束最后出栈的都是
全局执行上下文
JavaScript基础专题系列
JavaScript基础专题系列目录地址:
新手写作,如果有错误或者不严谨的地方,请大伙给予指正。如果这篇文章对你有所帮助或者有所启发,还请给一个赞,鼓励一下作者,在此谢过。
