

一、常用排序算法
一、直接插入排序 空间复杂度:O(1);时间复杂度:O(n) ~ O(n^2)
整个序列分为两部分,前面是已经排序好的,后面是等待排序的,每次取一个元素,放入前面合适的位置。
function sort(arr) {
var temp; //存放临时变量
for(var i = 1; i < arr.length; i ++ ) {
// 要插入的元素小于之前排序好的最后一个值
if(arr[i] < arr[i-1]) {
temp = arr[i];
arr[i] = arr[i-1];// 先移动最后一个
// 倒序处理,将temp放置入合适的位置
for(var j = i-2; j >= 0 && arr[j] > temp; j-- ) {
arr[j+1] = arr[j];
}
arr[j+1] = temp;
}
}
}
二、希尔排序 空间复杂度:O(1);时间复杂度:O(n) ~ O(n^2)
希尔排序是插入排序的一种。
设待排序元素序列有n个元素,首先取一个整数increment(小于n)作为间隔将全部元素分为increment个子序列,所有距离为increment的元素放在同一个子序列中,在每一个子序列中分别实行直接插入排序。然后缩小间隔increment,重复上述子序列划分和排序工作。直到最后取increment=1,将所有元素放在同一个子序列中排序为止。
// dis为距离增量
function sort(arr, dis) {
var temp; //存放临时变量
for(var i = dis; i < arr.length; i += dis ) {
// 要插入的元素小于之前排序好的最后一个值
if(arr[i] < arr[i-dis]) {
temp = arr[i];
arr[i] = arr[i-dis];// 先移动最后一个
// 倒序处理,将temp放置入合适的位置
for(var j = i-dis; j >= 0 && arr[j] > temp; j-=dis ) {
arr[j+dis] = arr[j];
}
arr[j+dis] = temp;
}
}
}
// [5, 4, 2, 1, 3, 6, 7, 9, 2, 0];
// dis取3,第一轮排序后
// [0, 4, 2, 1, 3, 6, 5, 9, 2, 7]
// t为要进行多少次子排序
function sheelSort(arr, t) {
var dis;
var len = arr.length; // 间隔默认数组长度
for(var i = 0; i < t; i++) {
// 每次取得不同的间隔
len = Math.floor(len / 3) + 1;
sort(arr, len);// 对不同的子序列进行直接插入排序,最后一次len为1,做最后的整理
}
}
希尔排序的性能较直接插入排序要好很多,因为经过几次子序列的排序之后,最后当间距为1的时候,此时序列几乎已经排好了,所以在最多项排列的时候可以很快的处理完毕。
三、快速排序 空间复杂度:O(nlogn);时间复杂度:O(nlogn) ~ O(n^2)
基本思想是选取一个记录作为枢轴,经过一趟排序,将整段序列分为两个部分,其中一部分的值都小于枢轴,另一部分都大于枢轴。然后继续对这两部分继续进行排序,从而使整个序列达到有序。
快速排序其实还有其他交换位置的方法,只是因为其他方法较我们下面使用的这中左右指针的方法效率要低一些,因此我们通常使用如下方式来交换位置。
function partion(arr, left, right) {
let base = arr[left]; //基准值,默认取数组第一个元素
while (left < right) {
while(left < right && arr[right] >= base) {
right --;
}
if(left < right) {
swap(arr, left, right);
}
while(left<right && arr[left] <= base) {
left ++;
}
if(left < right) {
swap(arr, left, right);
}
}
arr[left] = base;
return left;
}
// 快速排序
function quickSort(arr, left, right) {
let dp;
if(left < right) {
dp = partion(arr, left, right); // 第一步: 定位第一个基值,左侧的小,右侧的大
quickSort(arr, left, dp-1); // 第二步: 排序左侧的
quickSort(arr, dp+1, right); // 第三步: 排序右侧的
}
}
// 交换数组中的两个值
function swap(array, left, right) {
let rightValue = array[right]
array[right] = array[left]
array[left] = rightValue
}
var arr = [5, 4, 2, 1, 3, 6, 7, 9, 2, 0];
quickSort(arr, 0, arr.length-1);
console.log(arr);
四、简单选择排序 空间复杂度:O(1);时间复杂度:O(n) ~ O(n^2)
选择排序原理:每次从待排序的序列中找到最小的放在前面。O(n^2)
function sort(arr) {
for(var i = 0 ; i < arr.length; i++) {
var min = i;
// 从往后部分找出最小
for(var j = i+1 ; j< arr.length; j ++) {
if(arr[j] < arr[min]) {
min = j;
}
}
if(i != min) {
swap(arr, i, min);
}
}
}
// 交换数组中的两个值
function swap(array, left, right) {
let rightValue = array[right]
array[right] = array[left]
array[left] = rightValue
}
var arr = [5, 4, 2, 1, 3, 6, 7, 9, 2, 0];
sort(arr);
console.log(arr);
五、归并排序 空间复杂度: O(n) 时间复杂度:O(nlogn) ~ O(nlogn)
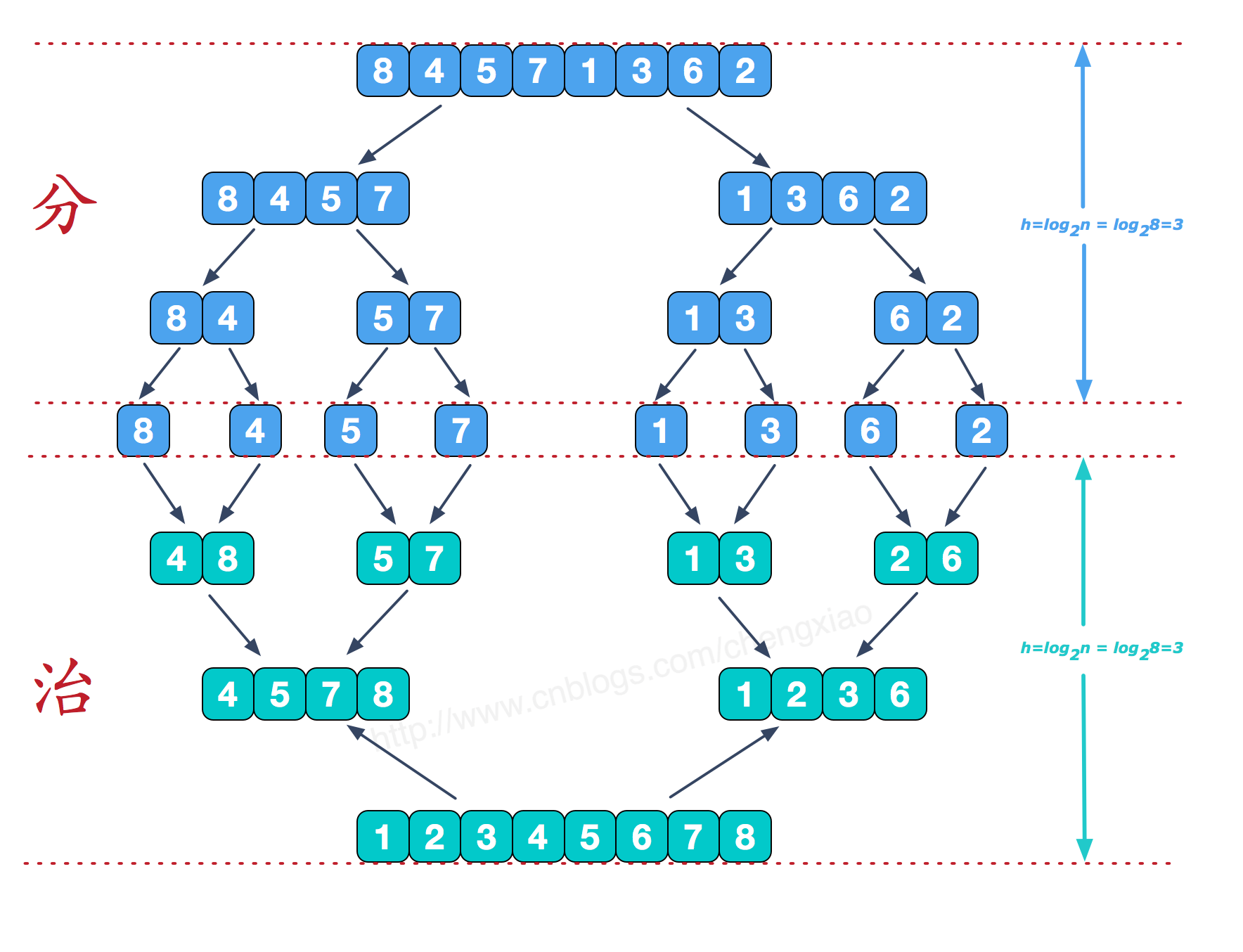
function merge(arr, L, mid, R) {
var temp = new Array(R - L + 1);
var i = 0;
var p1 = L;
var p2 = mid + 1;
// 比较左右两部分的元素,哪个小,把那个元素填入temp中
while(p1 <= mid && p2 <= R) {
temp[i++] = arr[p1] < arr[p2] ? arr[p1++] : arr[p2++];
}
// 上面的循环退出后,把剩余的元素依次填入到temp中
// 以下两个while只有一个会执行
while(p1 <= mid) {
temp[i++] = arr[p1++];
}
while(p2 <= R) {
temp[i++] = arr[p2++];
}
// 把最终的排序的结果复制给原数组
for(i = 0; i < temp.length; i++) {
arr[L + i] = temp[i];
}
}
function sort(arr, L, R) {
if(L == R) {
return;
}
var mid = parseInt(( R + L)/2);
sort(arr, L, mid);
sort(arr, mid + 1, R);
merge(arr, L, mid, R);
}
var arr = [5, 4, 2, 1, 3, 6, 7, 9, 2, 0];
sort(arr, 0, arr.length-1);
console.log(arr);
六、各排序算法的对比
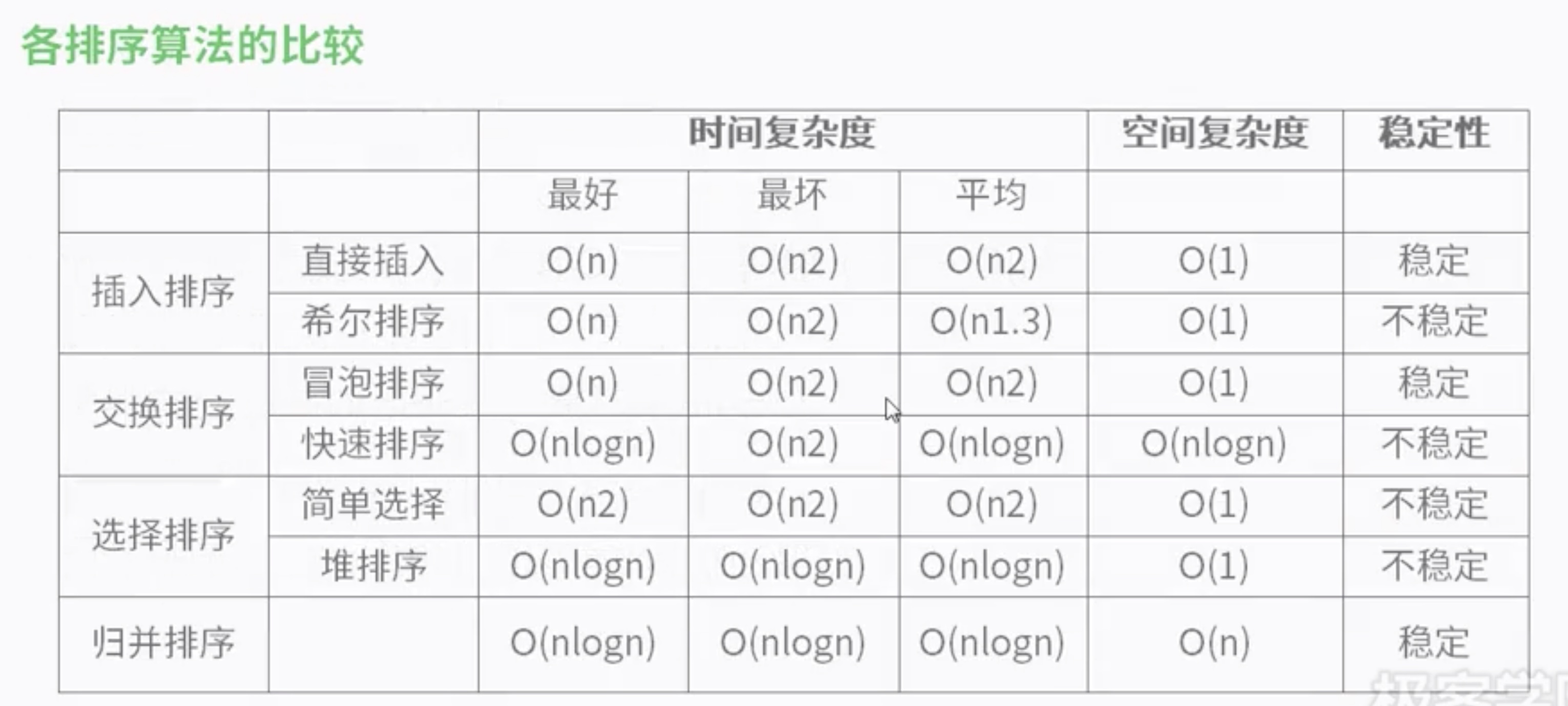
二、常用查找算法
1、二分查找/拆半查找
二分查找法作为一种常见的查找方法,将原本是线性时间提升到了对数时间范围,大大缩短了搜索时间,但是二分查找有两个前提条件:(1)序列必须是已经排好序的(2)序列必须支持随机访问
// v为待查找值
function find(arr, v) {
var low = 0;
var high = arr.length - 1;
var mid;
// 循环条件必须为low <= high
while(low <= high) {
mid = low + parseInt((high - low) / 2); // js除法后不是整数,所以需要转为整数
if(arr[mid] == v) {
return arr[mid]; // 函数结束条件
} else {
// 到左侧查找
if(arr[mid] > v) {
high = mid-1;
}
// 右侧查找
if(arr[mid] < v) {
low = mid + 1;
}
}
}
// 没找到返回-1
return -1;
}
var arr = [];
for(var i = 0; i < 1000; i ++) {
arr[i] = i;
}
console.log(find(arr, 25));
console.log(find(arr, 500));
console.log(find(arr, 28));
其中,有几个要注意的点:
循环的判定条件是:low <= high 为了防止数值溢出,mid = low + parseInt((high - low) / 2); 当 A[mid]不等于target时,high = mid - 1或low = mid + 1
由于二分查找的两个约束条件,因此二分查找使用并不多。
统计一个数字在排序数组中出现的次数
1、首先,遍历数组肯定就能知道某个数字的个数,此时的时间复杂度O(n)。
2、首先这里是排好序的数组,而且是查找问题,那么我们是不是可以使用二分查找呢,通过二分查找到一个目标,然后向两侧查找,然后就能找到所有的目标数,但是这样复杂度其实还是O(n)。
3、如果我们知道了第一个3和最后一个3出现的位置,那么其实也就知道了个数,那么我们能否在第一次使用二分查找之后,继续使用二分法,找到两端的3?当然可以,只是这样的二分查找就要跟上面的有点不一样了
4、总之:我们采用二分查找,找到第一个目标值和最后一个目标值,然后就能知道出现的个数了~
function getFirst(arr, length, k, start, end) {
if(start > end) {
return -1;
}
var mid = start + parseInt((end - start) / 2);
var midData = arr[mid];
if(midData == k ) {
if((mid > 0 && arr[mid - 1] != k) || midData == 0) {
return mid;
} else {
end = mid - 1;
}
} else {
if(midData > k) {
end = mid - 1;
}
if(midData < k ) {
start = mid + 1;
}
}
return getFirst(arr, length, k, start, end);
}
function getLast(arr, length, k, start, end) {
if(start > end)
return -1;
var mid = start + parseInt((end - start) / 2);
var midData = arr[mid];
if(midData == k) {
if((mid < length-1 && arr[mid + 1] != k) || midData == length-1) {
return mid;
} else {
start = mid + 1;
}
} else {
if(midData > k) {
end = mid - 1;
}
if(midData < k ) {
start = mid + 1;
}
}
return getLast(arr, length, k, start, end);
}
function getNumber(data, k) {
var num = 0;
var length = data.length;
var first = getFirst(data, length, k, 0, length - 1); // 获取第一次出现的位置
var last = getLast(data, length, k, 0, length - 1); // 获取最后一次出现的位置
if(first > -1 && last > -1)
num = last - first + 1;
console.log(num, first, last);
}
var arr = [1,2,2,3,4,4,4,4,5,6,8,9];
getNumber(arr, 4);
当我们遇到以排序,查找问题的时候,我们不妨想想二分查找,毕竟这个算法还是挺快的。
上面我们提到的是常规有序列表,但是还有一种特殊的有序列表,称为旋转有序列表。
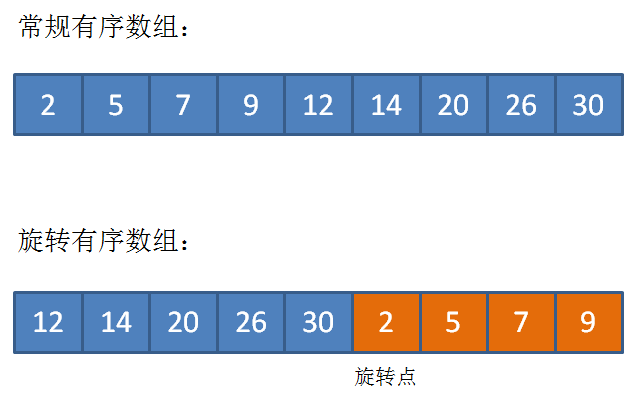
首先明确一个概念:旋转点。
旋转点是什么呢?我们这里规定,假设旋转有序数组恢复为普通有序数组,位于普通有序数组第一个位置的元素,就是旋转数组的旋转点。
直白地说,旋转点就是旋转数组中最小的元素
我们可以分为以下几种情况。
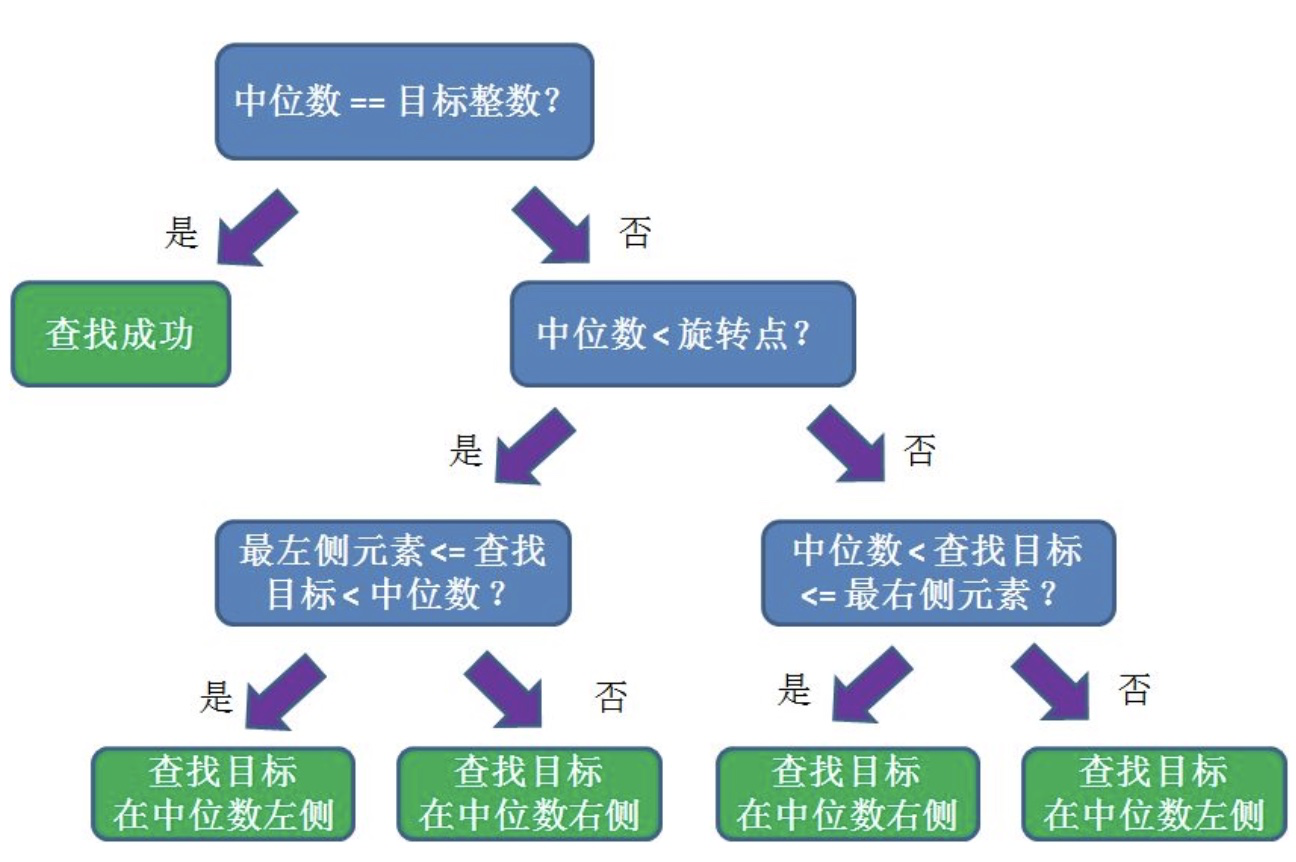
2、树的查找
一、二叉搜索树
相较于我们的二分查找,二叉搜索树的稳定性是其关键之处,虽然时间复杂度都可以达到O(logn).但是二叉搜索树在不稳定的情况下会降低性能,极端情况下会退化为O(n);但是二叉搜索树还是有其自身的优势的,比如插入、删除相对较快。
为了解决普通二叉搜索树的不平衡问题,出现了AVL树(平衡二叉树)和红黑树。他们都是二叉搜索树。
了解AVL树可以查看我的这篇文章:算法复习 我们接下来以红黑树为主:
二、红黑树
强烈推荐 —— 什么是红黑树? 红黑树就是一种自平衡的二叉查找树,说他平衡的意思是他不会变成“瘸子”,左腿特别长或者右腿特别长。除了符合二叉查找树的特性之外,还具体下列的特性:
1、我们的每个结点都标记了颜色(红或者黑)。
2、根结点是黑色的
3、所有NIL结点都是黑色的(叶子结点的两个空结点被称为是NIL结点)
4、如果结点是红色的,那么子结点必须是黑色的
5、对于树中的每一个结点,到任意一个NIL的路径中,黑色结点的个数都是一致
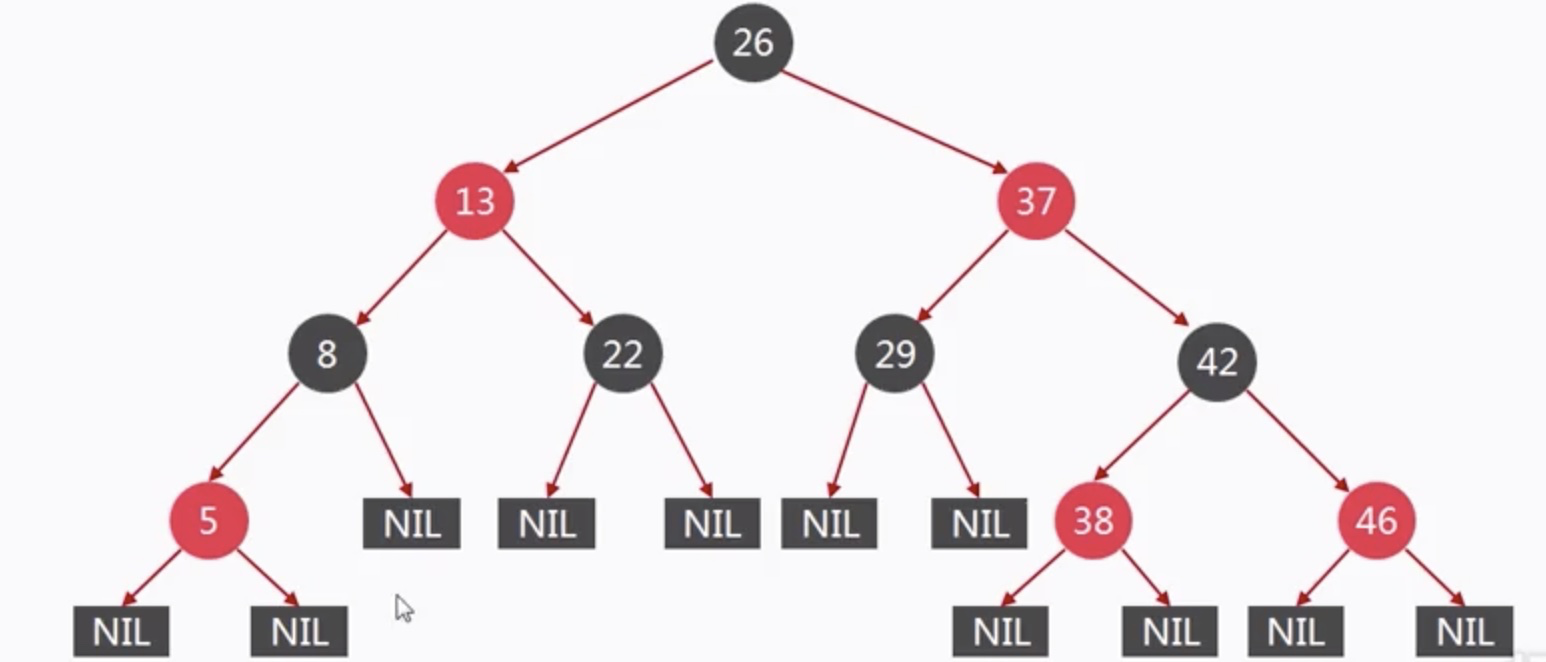
1、红黑树的最大高度为2log(n+1)
2、最大高度差不会超过一倍,即从根结点出发到NIL的最大距离不超过该树最小深度的两倍。
- 红黑树于AVL树的对比
1、二者的查找时间复杂度都是O(logn)
2、AVL树对平衡性要求较为严格,差值不能超过1,红黑树的要求较低一些,差值不能超一半,所以AVL树的高度相对较低一些
3、红黑树的很多操作都不需要进行旋转调节,而AVL树则经常需要旋转调节平衡
4、红黑树适合于数据变动比较频繁的场合,而AVL树则适合于相对于较为静态的场合
很多童鞋又会惊讶了,天啊这个条条框框也太多了吧。没错,正式因为这些规则,才能保证红黑树的自平衡。最长路径不超过最短路径的2倍。
下面我们来分析红黑树的插入操作
插入点不能为黑节点,应插入红节点。因为你插入黑节点将破坏性质5,所以每次插入的点都是红结点,但是若他的父节点也为红,那岂不是破坏了性质4?对啊,所以要做一些【“旋转”】和一些节点的【变色】!
比如我们添加21元素进去。
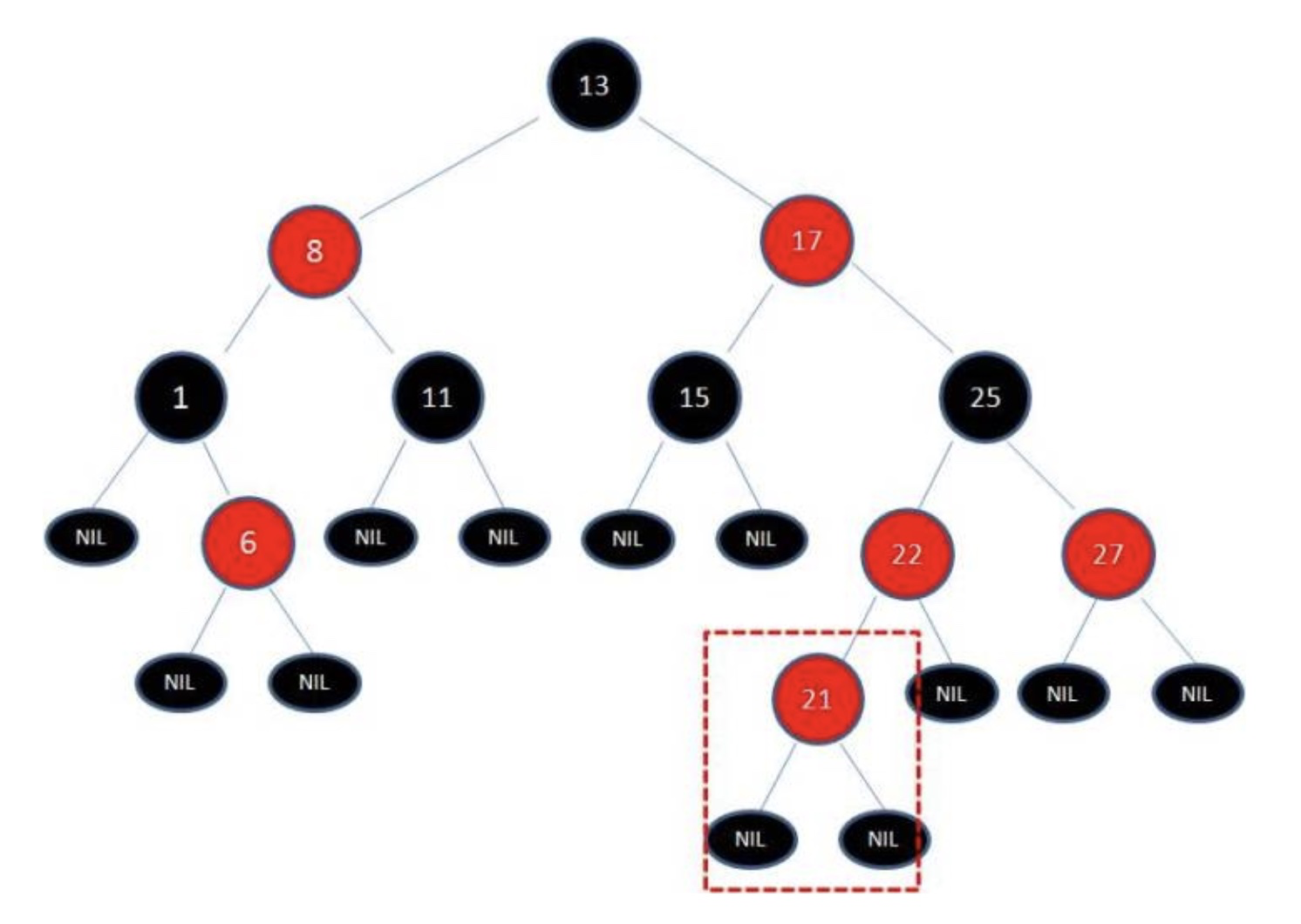
我们会发现此时已经破坏了红黑树原本的性质,此时我们就要做一些相应的旋转和变色处理了~
我们需要了解这里的旋转操作:
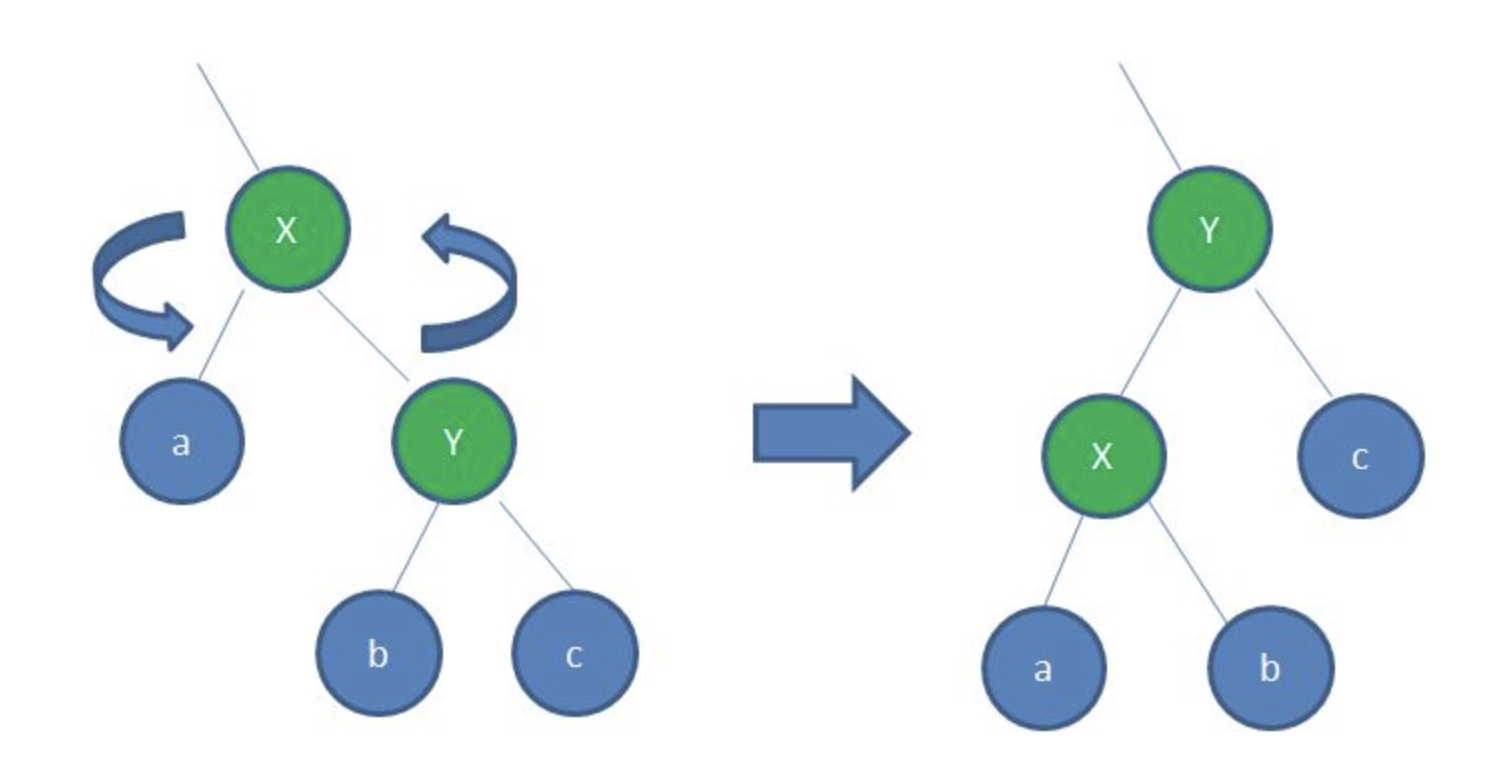
- 左旋转
逆时针旋转红黑树的两个节点,使得父节点被自己的右孩子取代,而自己成为自己的左孩子。说起来很怪异,大家看下图:
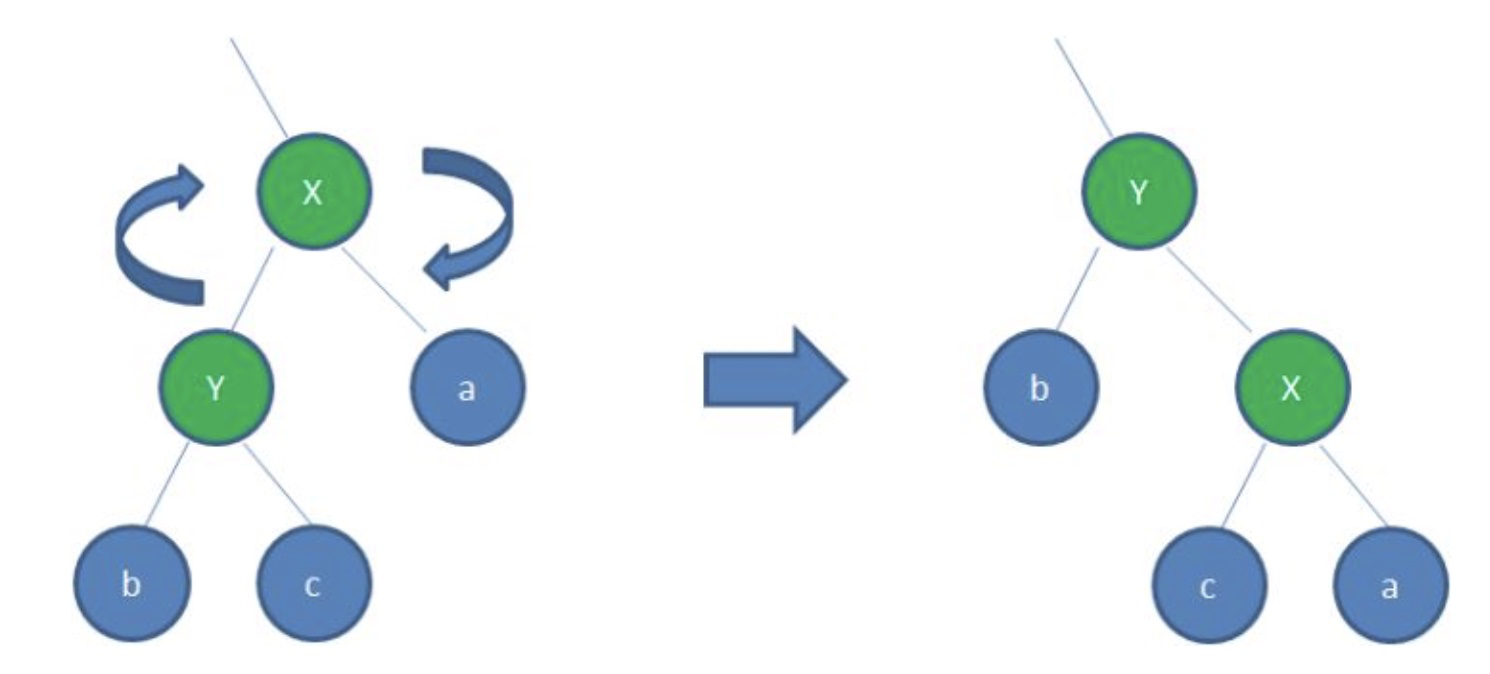
- 右旋转
顺时针旋转红黑树的两个节点,使得父节点被自己的左孩子取代,而自己成为自己的右孩子。大家看下图:

- 例子:
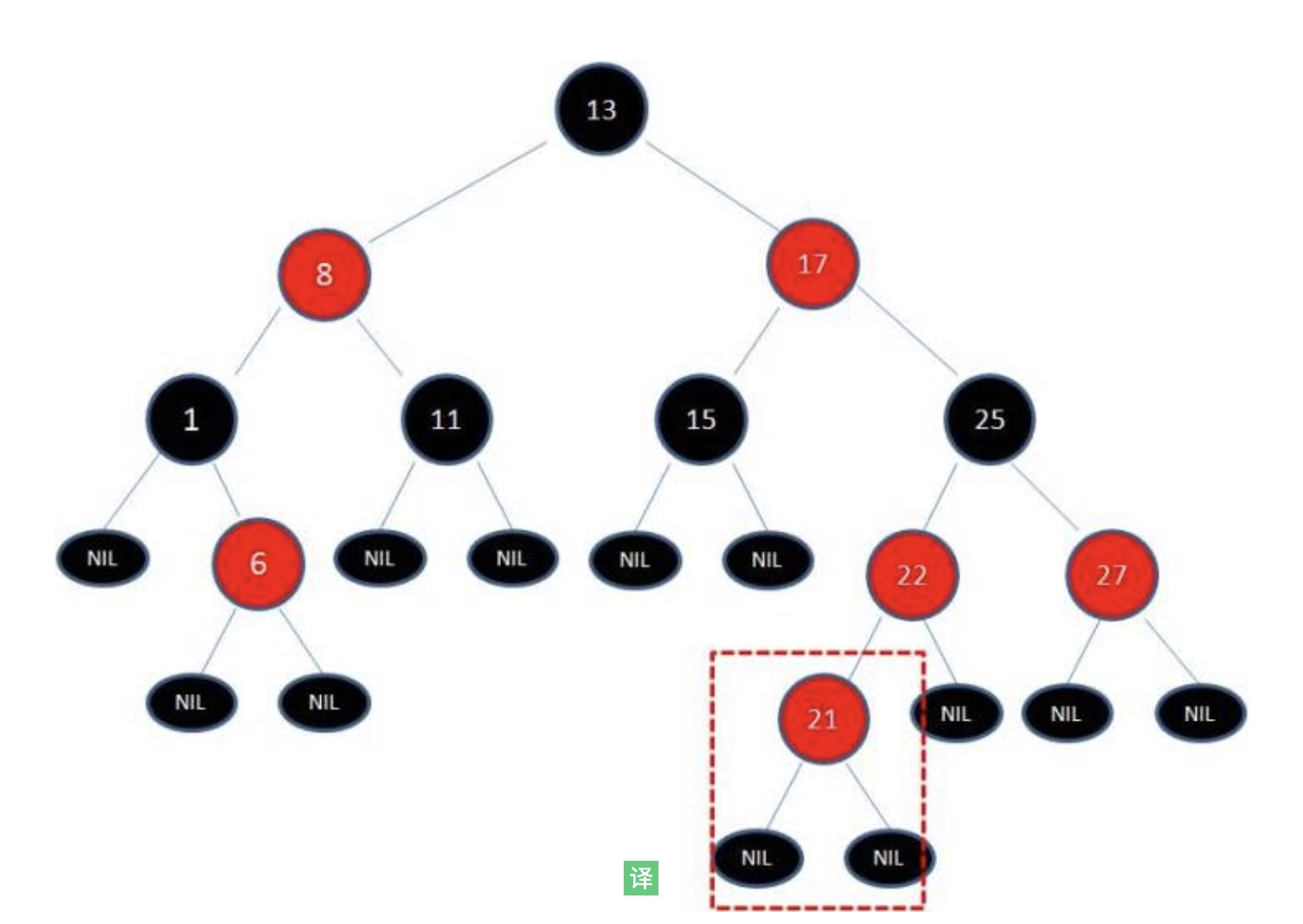
我们发现22和21颜色冲突,因此我们需要变色,同时我们把只看下面方框中的部分,将22变为黑色之后,很明显不符合第5性质了,因此我们需要把27也变为黑色。
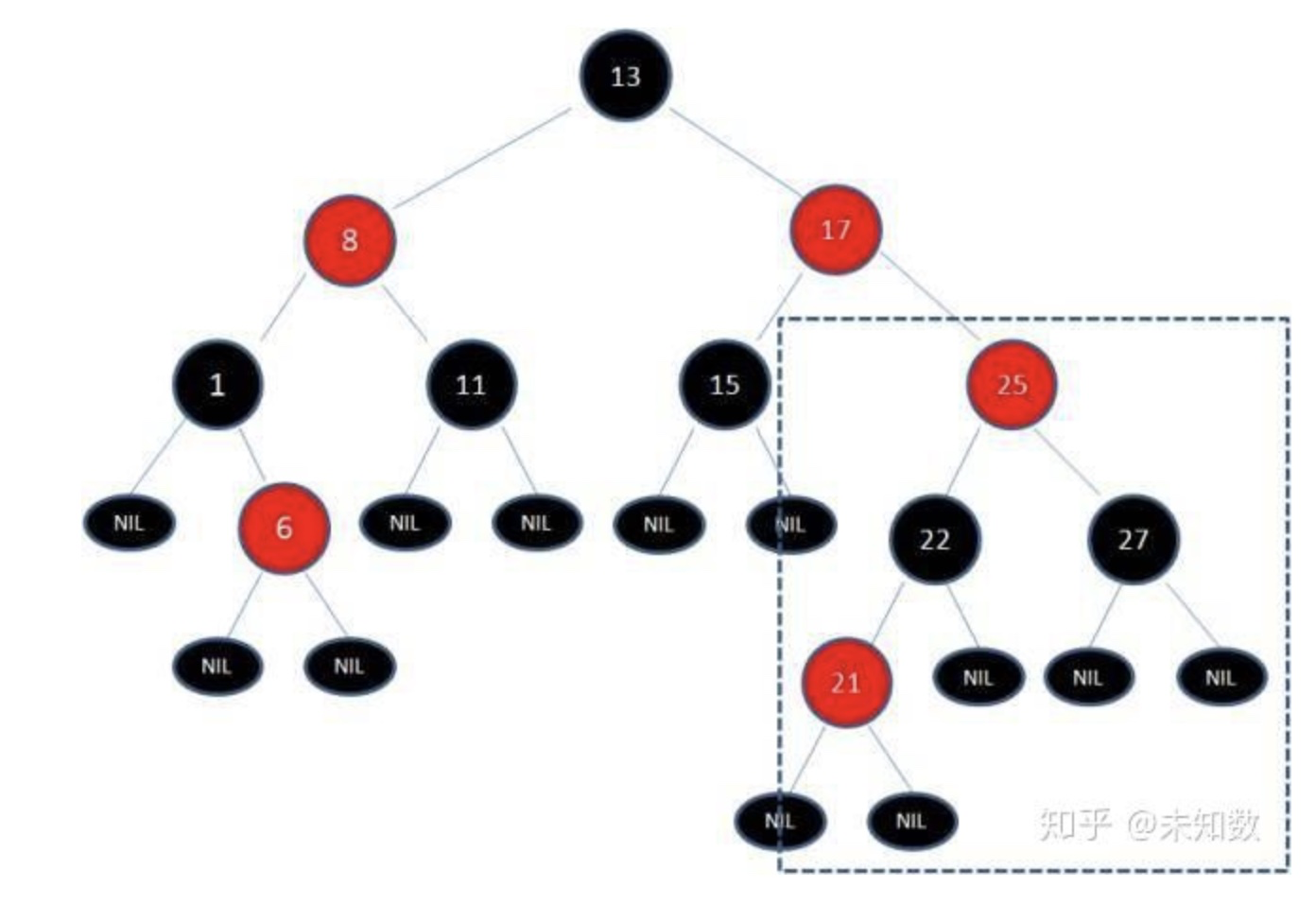
此时节点17和节点25是连续的两个红色节点,那么把节点17变成黑色节点?恐怕不合适。这样一来不但打破了规则4,而且根据规则2(根节点是黑色),也不可能把节点13变成红色节点。我们这时候需要旋转来解决了~~
我们把节点13看做X,把节点17看做Y,像刚才的示意图那样进行左旋转:
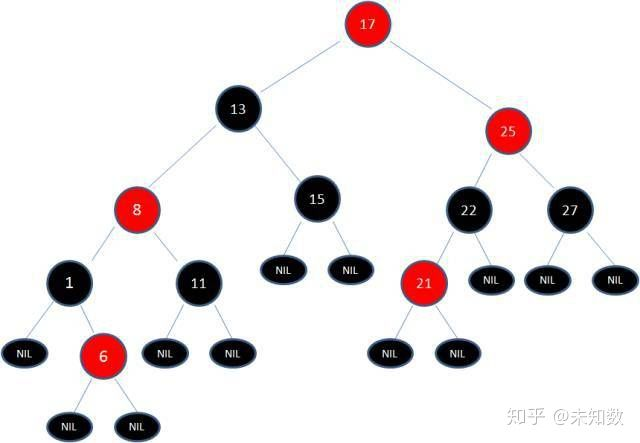
由于根节点必须是黑色节点,所以需要变色,变色结果如下:
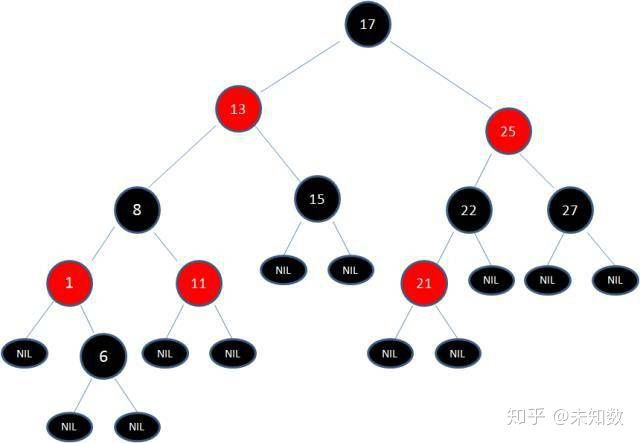
这样就结束了吗?并没有。因为其中两条路径(17 -> 8 -> 6 -> NIL)的黑色节点个数是4,其他路径的黑色节点个数是3,不符合规则5。
这时候我们需要把节点13看做X,节点8看做Y,像刚才的示意图那样进行右旋转:
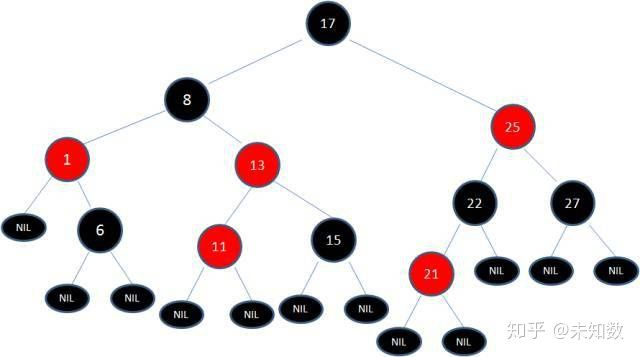
然后我们依据规则变色:
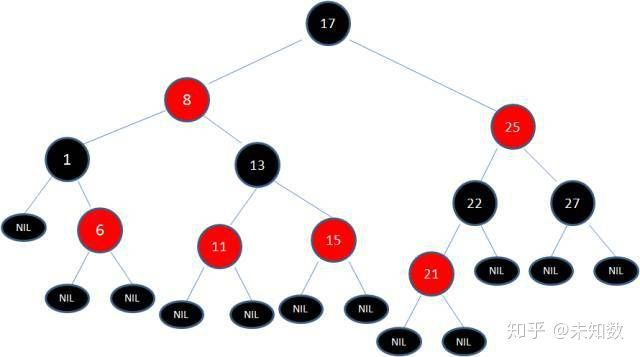
如此一来,我们的红黑树变得重新符合规则。这一个例子的调整过程比较复杂,经历了如下步骤:
变色 -> 左旋转 -> 变色 -> 右旋转 -> 变色
总结: 描述以下红黑树的插入过程:
1、第一步: 将红黑树当作一颗二叉查找树,将节点插入。
红黑树本身就是一颗二叉查找树,将节点插入后,该树仍然是一颗二叉查找树。也就意味着,树的键值仍然是有序的。那接下来,我们就来想方设法的旋转以及重新着色,使这颗树重新成为红黑树!
2、第二步:将插入的节点着色为"红色"。
为什么着色成红色,而不是黑色呢?为什么呢?在回答之前,我们需要重新温习一下红黑树的特性: (1) 每个节点或者是黑色,或者是红色。 (2) 根节点是黑色。 (3) 每个叶子节点是黑色。 [注意:这里叶子节点,是指为空的叶子节点!] (4) 如果一个节点是红色的,则它的子节点必须是黑色的。 (5) 从一个节点到该节点的子孙节点的所有路径上包含相同数目的黑节点。
将插入的节点着色为红色,不会违背"特性(5)"!少违背一条特性,就意味着我们需要处理的情况越少。接下来,就要努力的让这棵树满足其它性质即可;满足了的话,它就又是一颗红黑树了。o(∩∩)o...哈哈
3、第三步: 通过一系列的旋转或着色等操作,使之重新成为一颗红黑树。
对于"特性(4)",是有可能违背的! 那接下来,想办法使之"满足特性(4)",就可以将树重新构造成红黑树了。
4、具体描述如下:
// 新插入的点的三种不同情况:
父节点是根节点(root),把节点变成黑色
父节点是黑色节点,无需改变,插入后任是红黑树(性质还满足)
父节点是红色节点, 特殊处理[这种情况正是我们需要郑重考虑的~~]
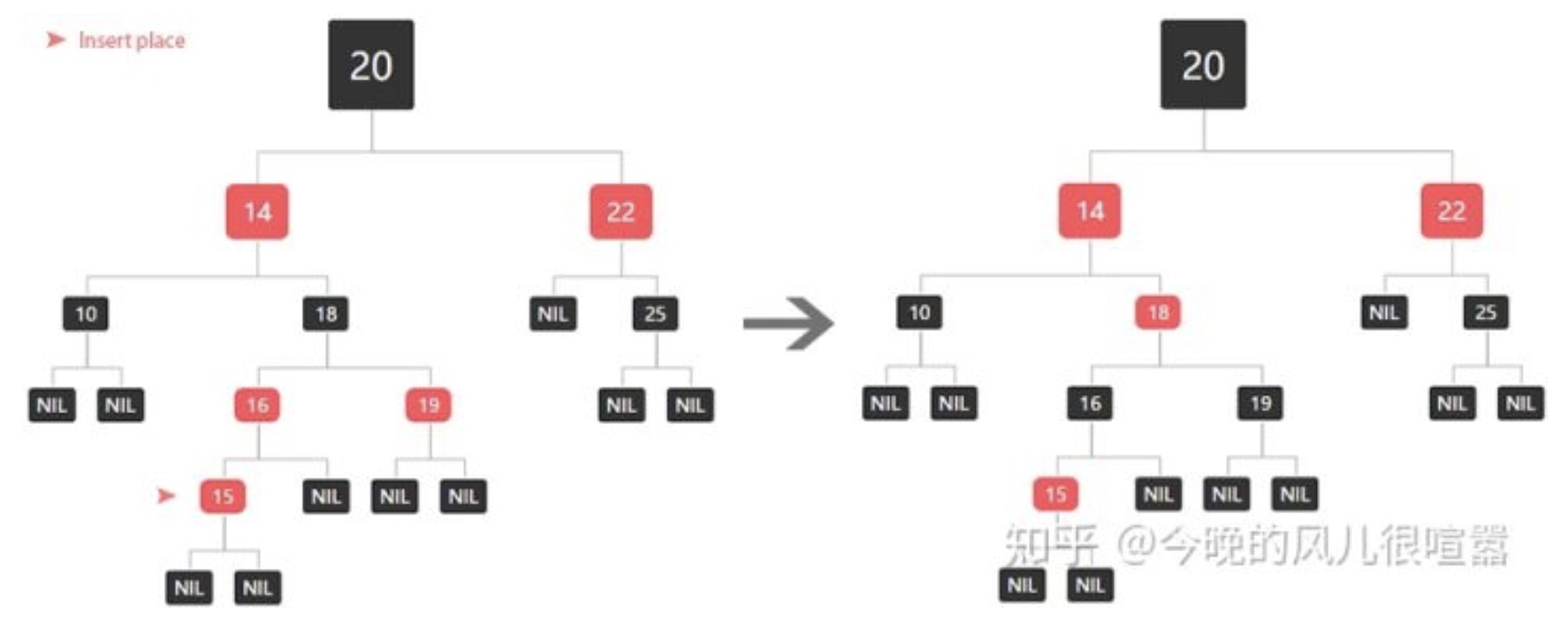
比如:我们新插入15
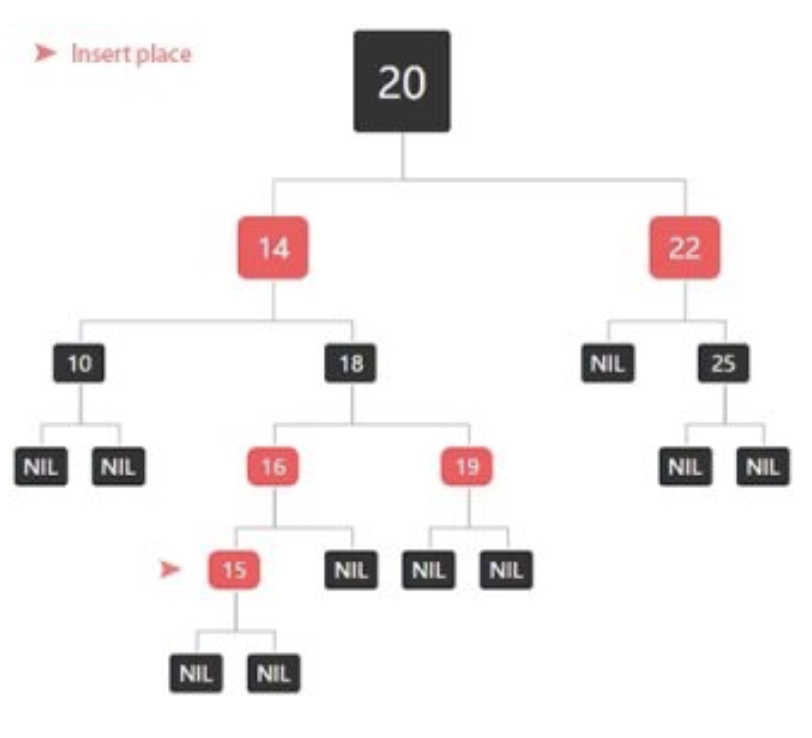
-
- 叔叔节点是红色
将当前父节点设为黑色
将叔叔节点设为黑色
将祖父节点设为红色,并且将祖父节点设置为新的当前节点,进行下一步分析
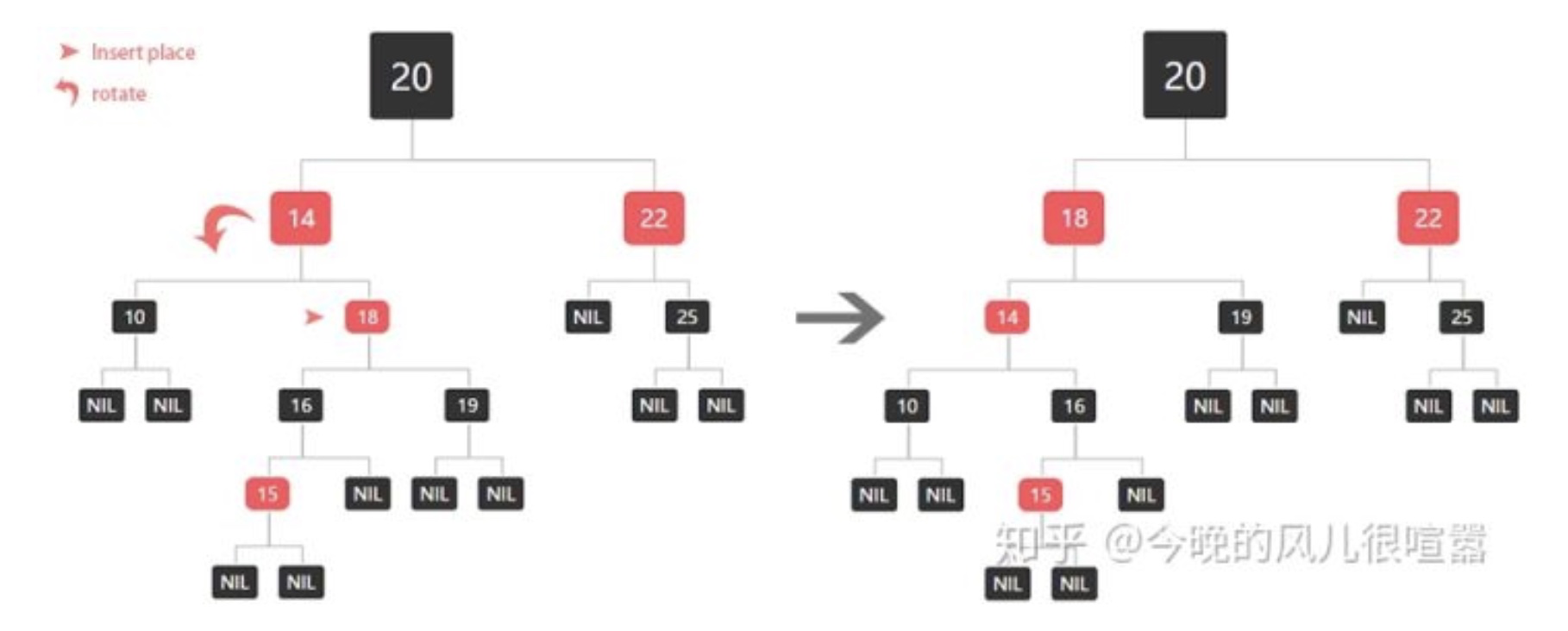
- 2、兄弟节点是黑色的,当前节点是右节点
将父节点作为新的当前节点
以新的当前节点为支点进行左旋
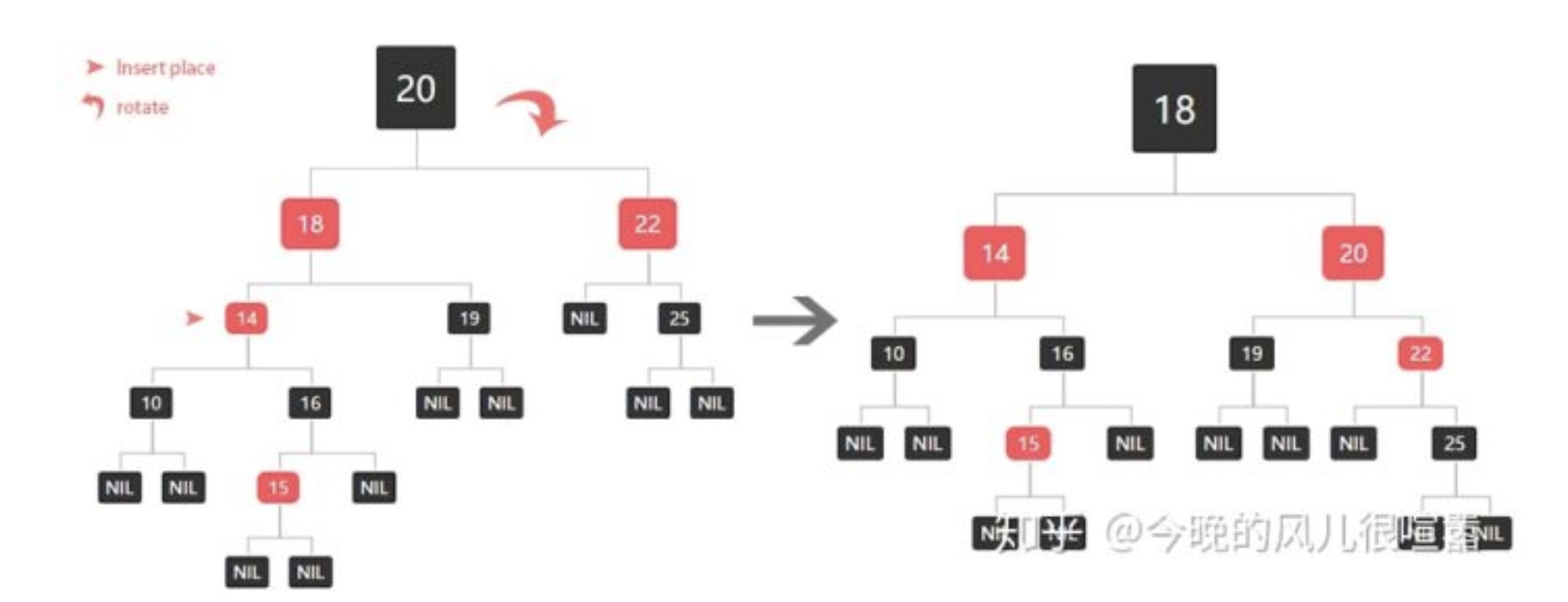
- 3、兄弟节点是黑色的,当且节点是左节点
将父节点设置为黑色
将祖父节点设置为红色
以祖父节点为支点进行右旋
三、字典树
字典树,又称为单词查找树,Tire树,是一种树形结构,它是一种哈希树的变种。
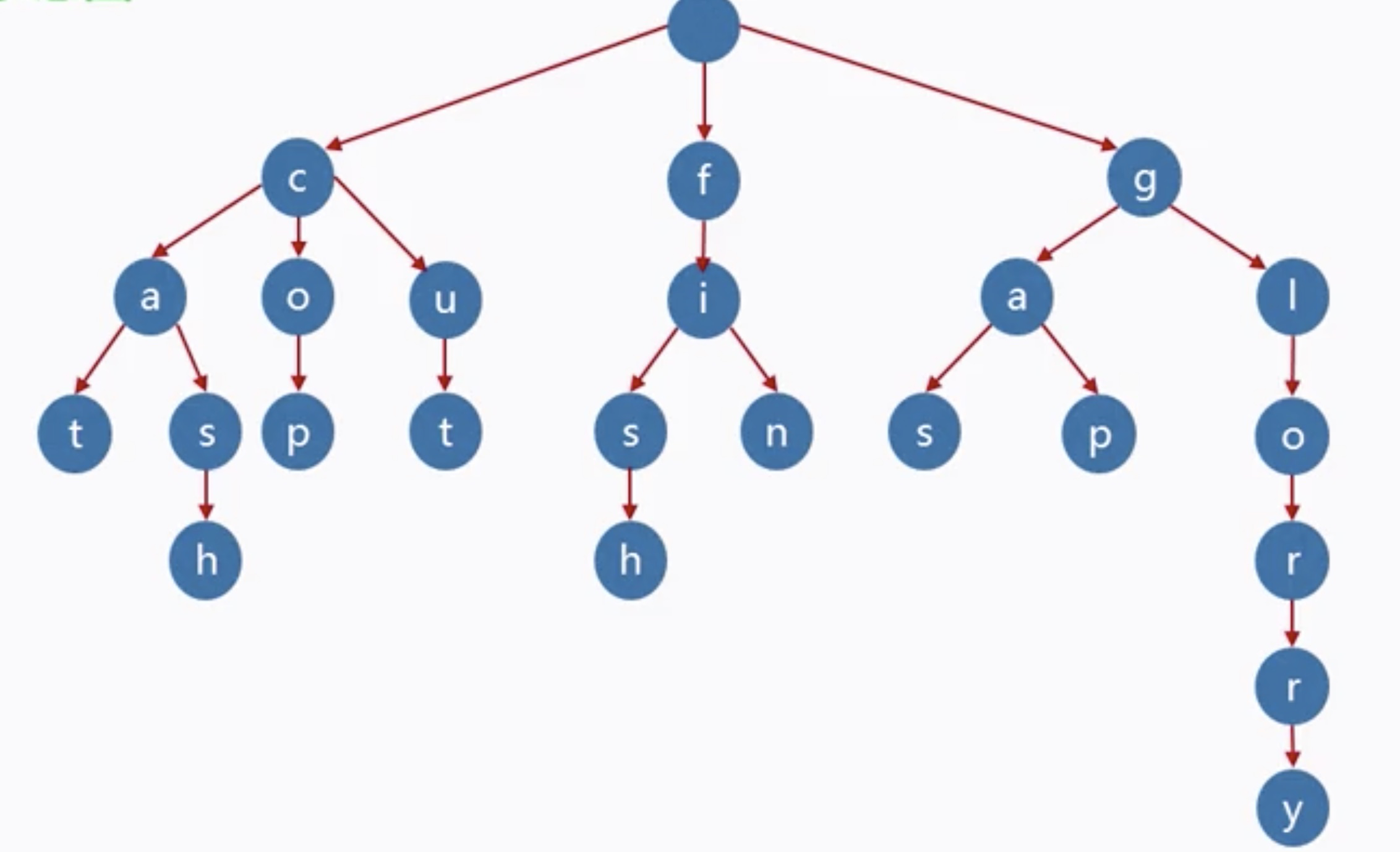
根节点不包含字符,除根节点外的每一个子节点都包含一个字符
从根节点到某一节点。路径上经过的字符连接起来,就是该节点对应的字符串
每个节点的所有子节点包含的字符都不相同
四、B-树
B-树是一个多叉平衡查找树,我们不能读成B减树。
强烈推荐——漫画:什么是B-树?一个m阶的B树具有如下几个特征:
每个结点最多有m个子结点。
1.根结点至少有两个子女。
2.每个中间节点都包含k-1个元素和k个孩子,其中 m/2 <= k <= m
3.每一个叶子节点都包含k-1个元素,其中 m/2 <= k <= m
4.所有的叶子结点都位于同一层。
5.每个节点中的元素从小到大排列,节点当中k-1个元素正好是k个孩子包含的元素的值域分划。
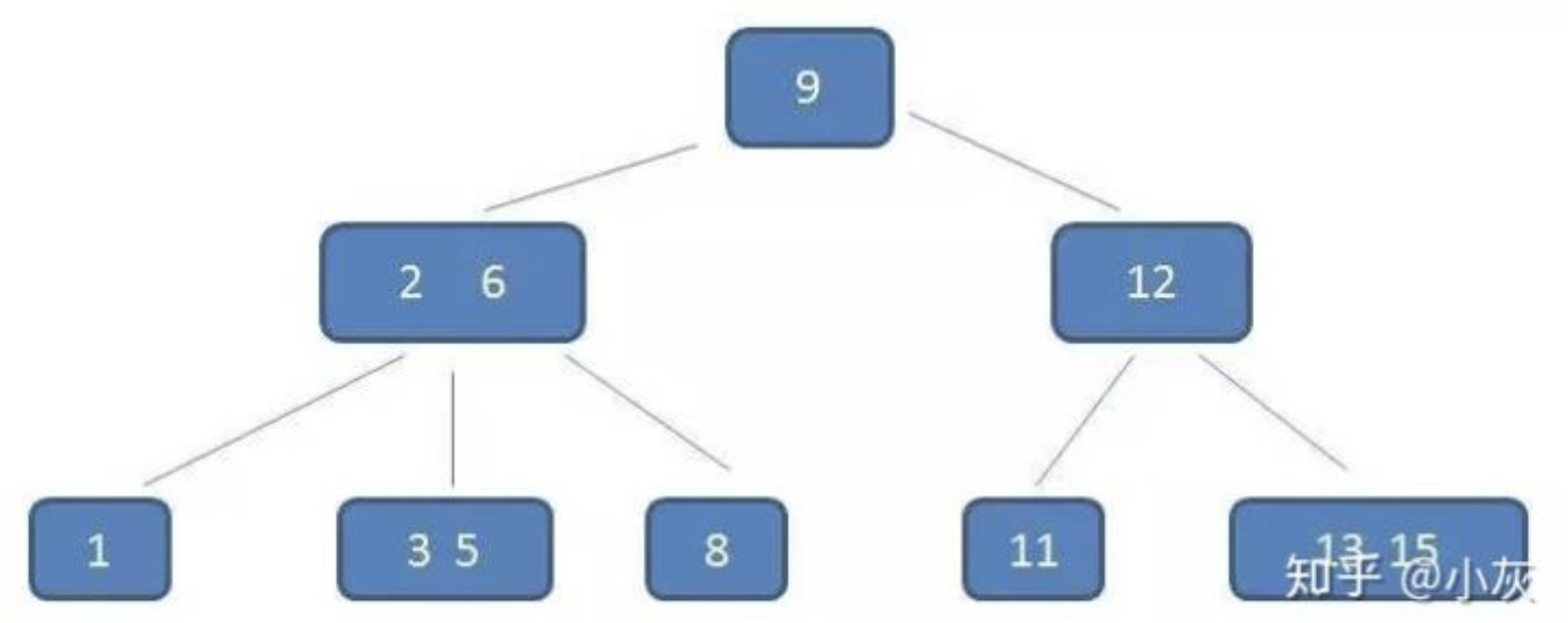
我们可以通过下图来理解以上几个性质:
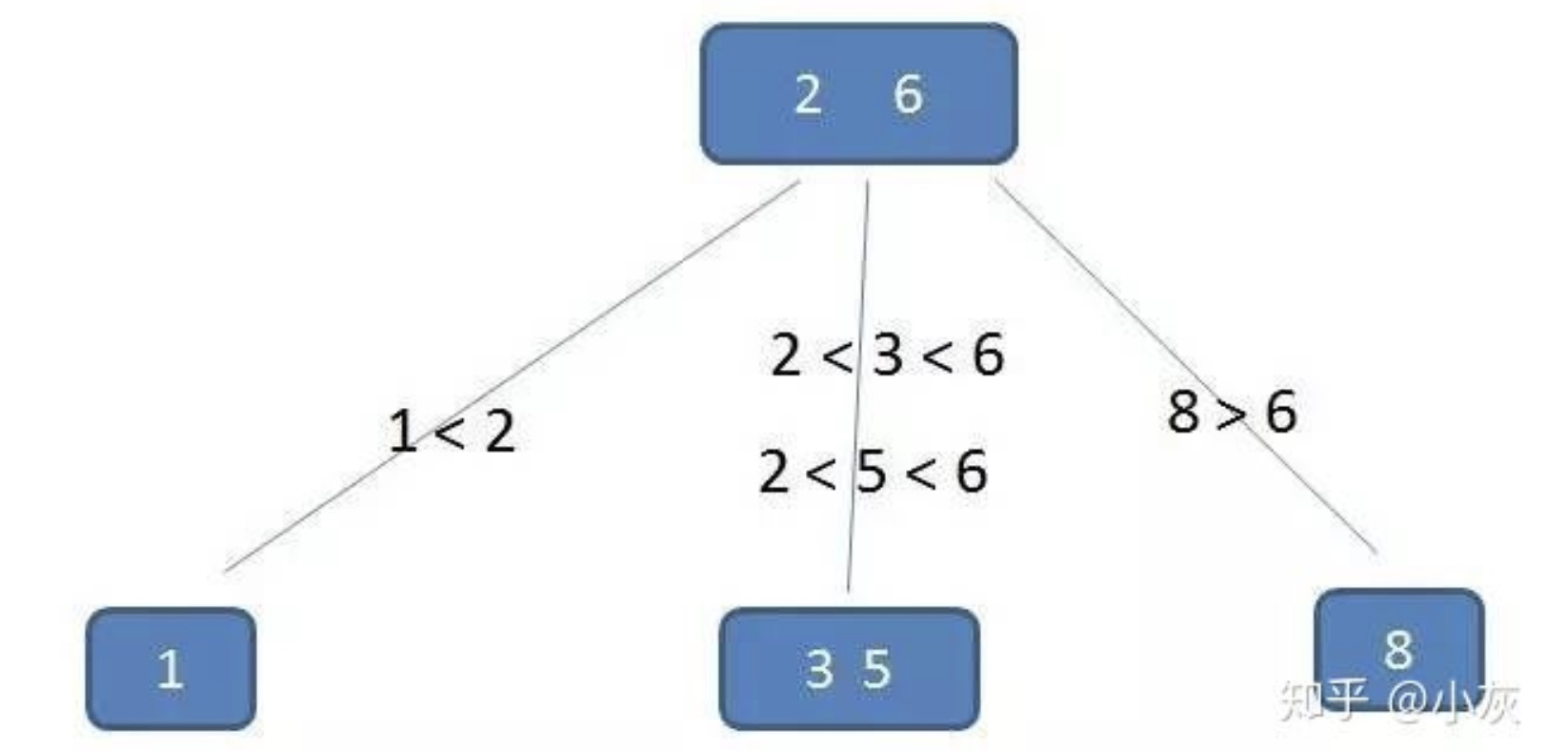
- 插入操作
插入操作涉及较多,我们先看典型的一个例子:
自顶向下查找4的节点位置,发现4应当插入到节点元素3,5之间。
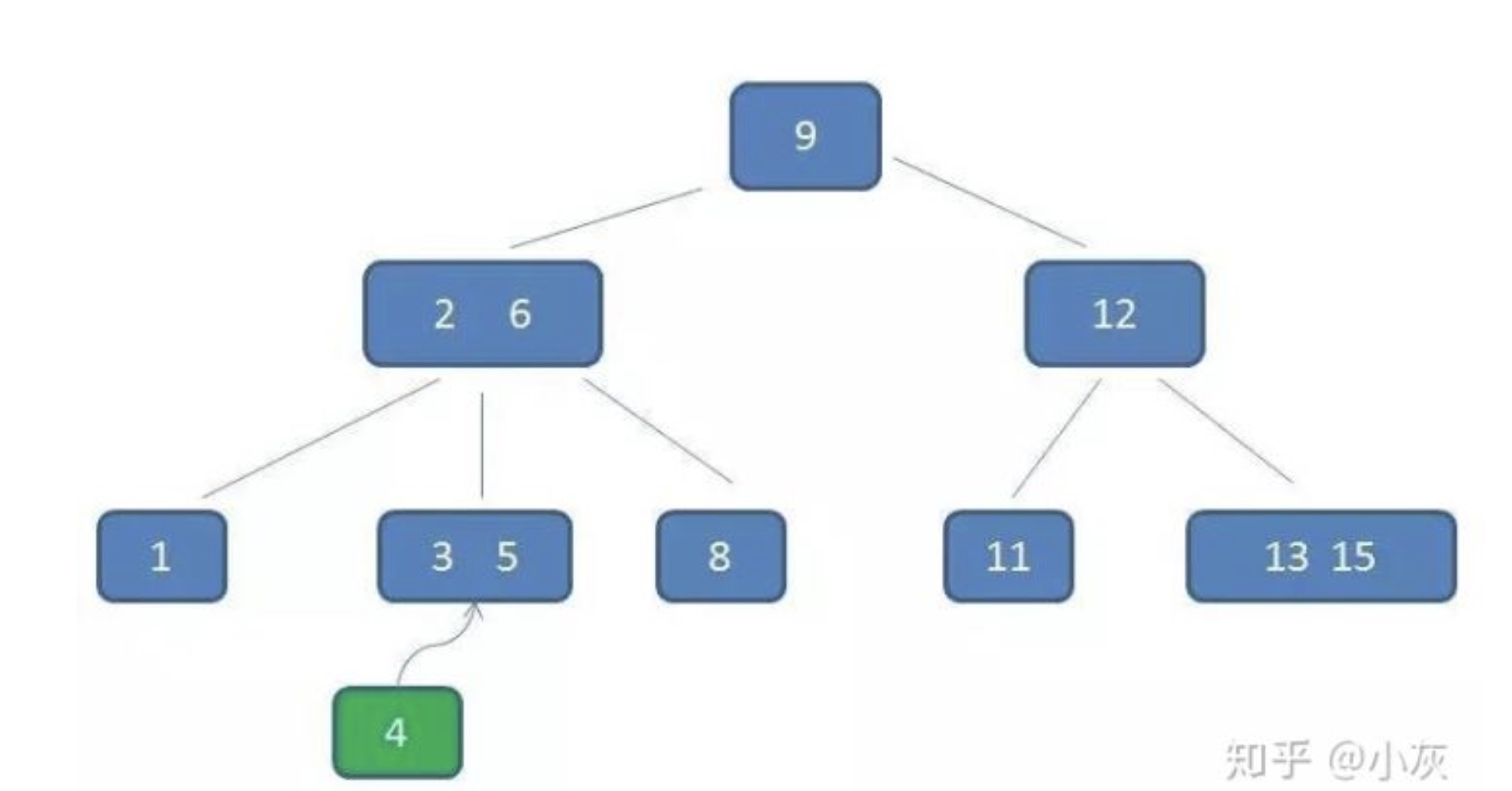
节点3,5已经是两元素节点,无法再增加。父亲节点 2, 6 也是两元素节点,也无法再增加。根节点9是单元素节点,可以升级为两元素节点。于是拆分节点3,5与节点2,6,让根节点9升级为两元素节点4,9。节点6独立为根节点的第二个孩子。
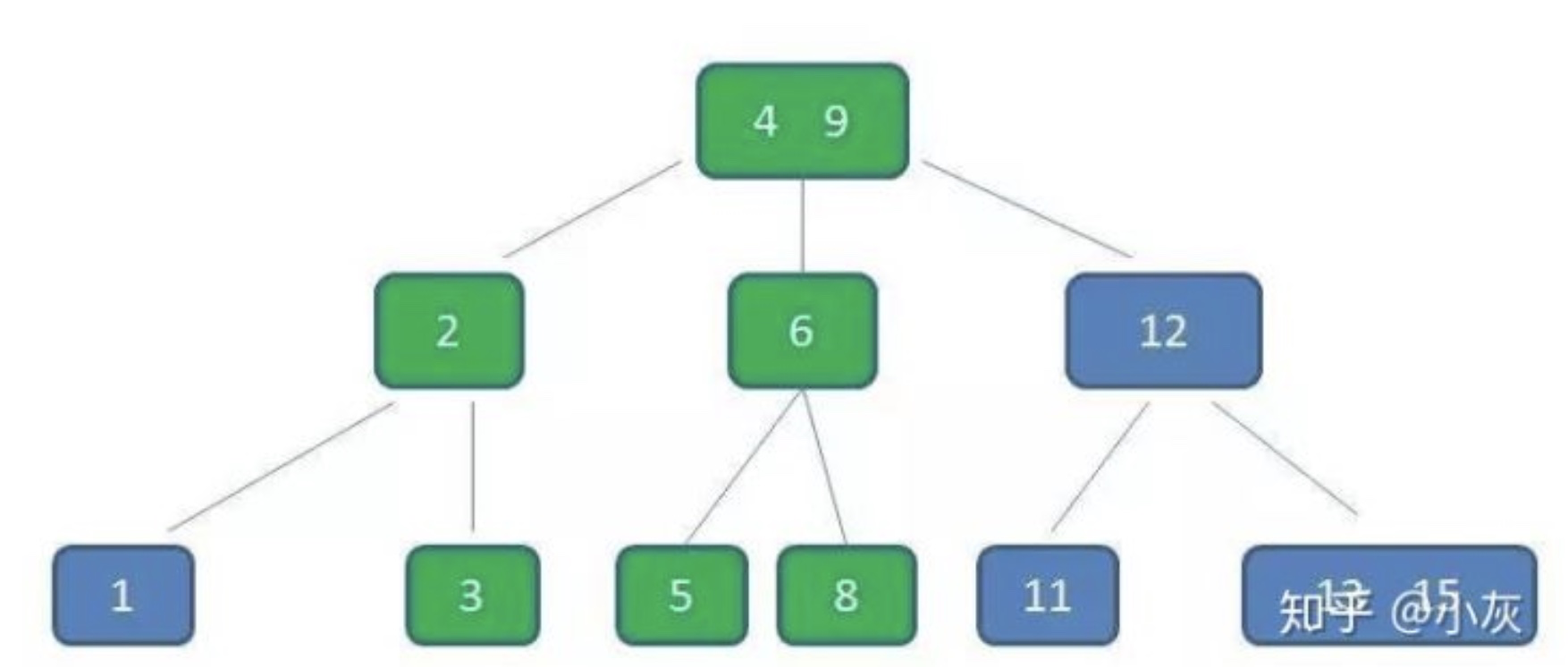
我们可以看出插入操作相当的繁琐,也正是因为如此,我们才能让B-树保持多路平衡,这也是B-树的一大优势(自平衡)。
- 删除操作
比如要删除结点11:
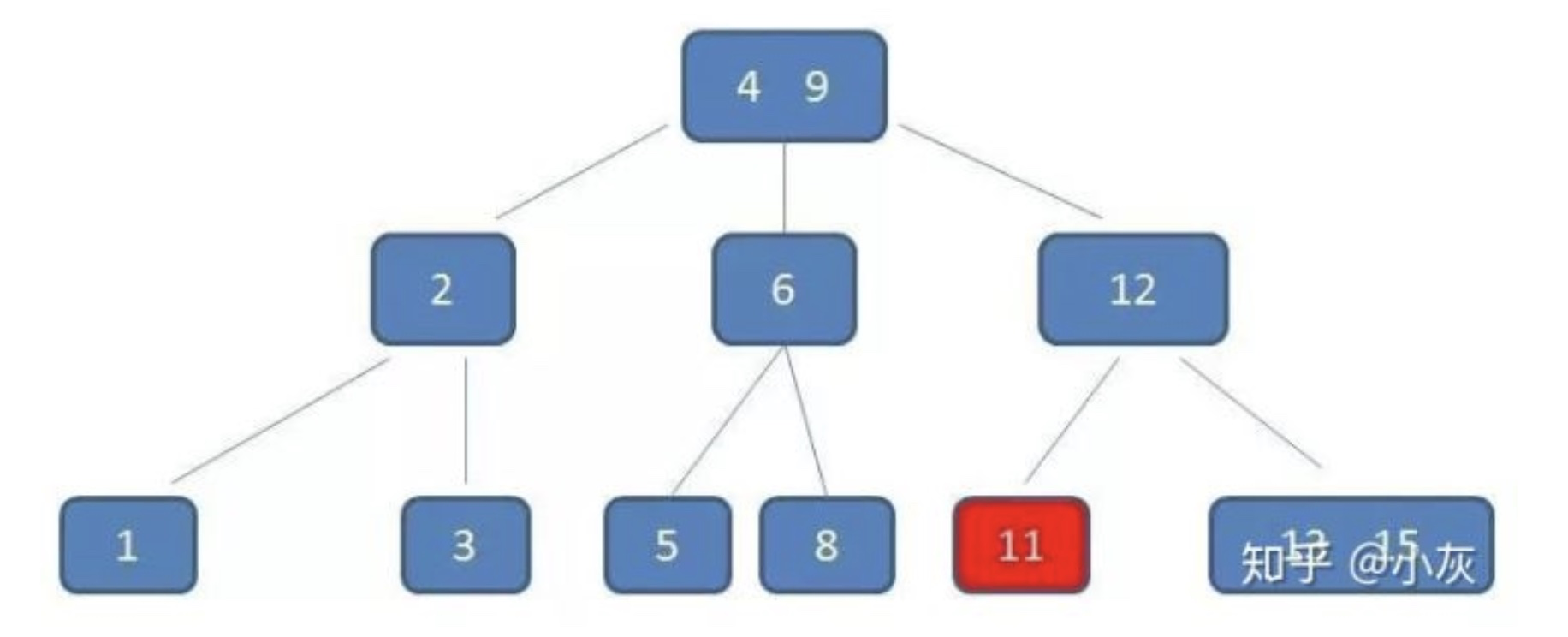
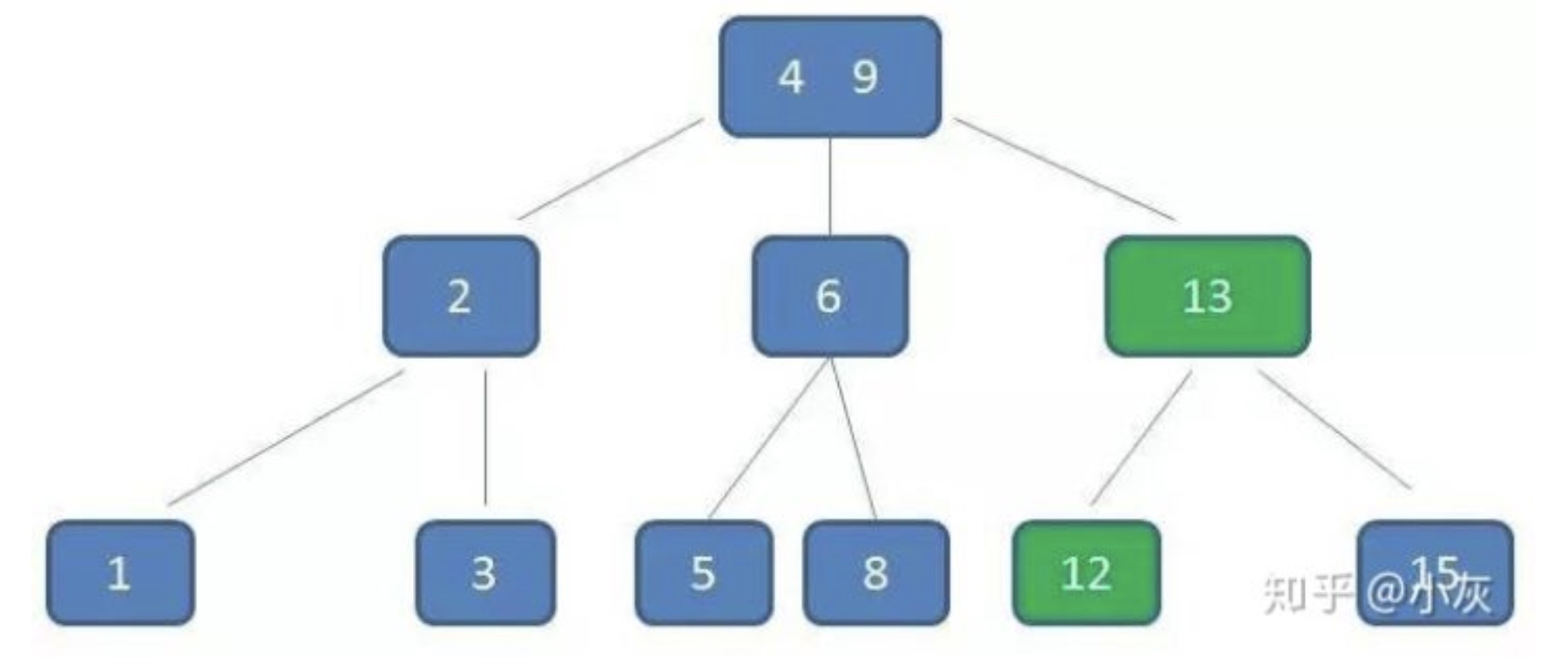
删除11后,节点12只有一个孩子,不符合B树规范。因此找出12,13,15三个节点的中位数13,取代节点12,而节点12自身下移成为第一个孩子。(
我们的数据库索引往往需要提供较快的查找速率,往往数据库索引一般很多,占据很大的空间,因此通常保存在磁盘上,当我们查找的时候就需要读入内存。二叉树查找的速度根树的高度有着很大的关系,因此我们就需要B-树这种矮胖型的树了,可以大大提高我们的查找速度。

优点:
进一步减少了树的高度
优化了查找时候磁盘的访问频率
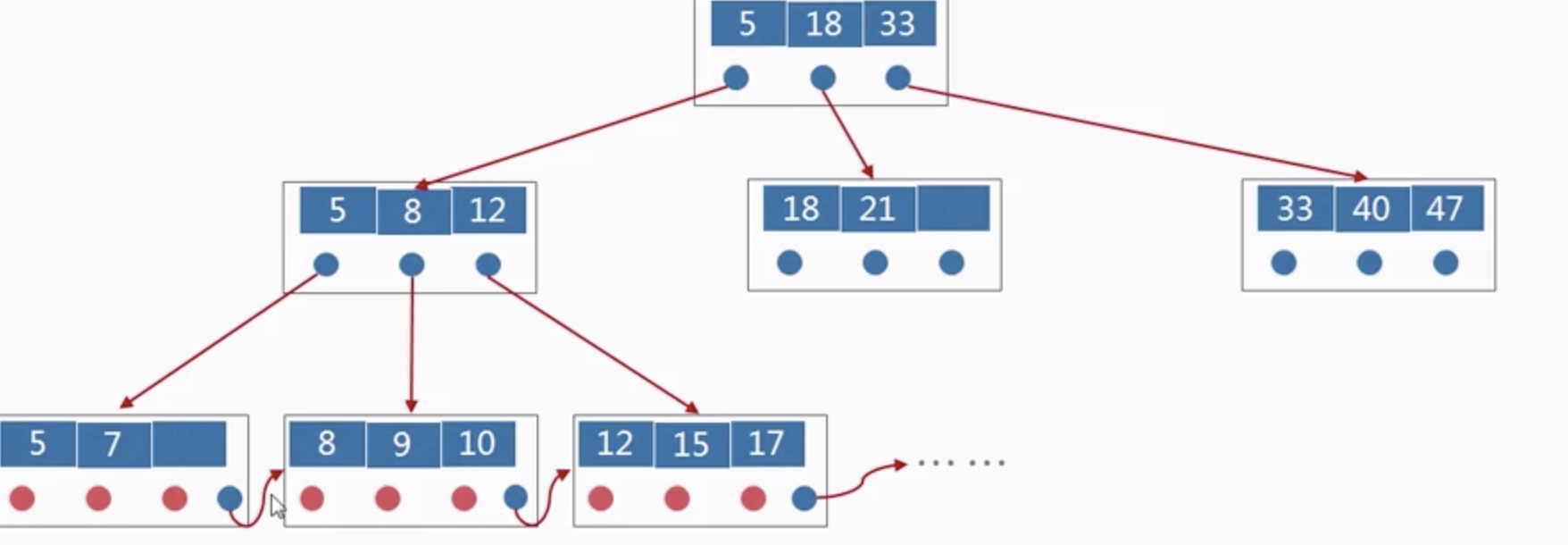
五、B+树
强烈推荐——漫画:什么是B+树?B+树是B-树的一种变体,比B-树有着更高的查询性能。
一个m阶的B+树具有如下几个特征:
1.有k个子树的中间节点包含有k个元素(B树中是k-1个元素),每个元素不保存数据,只用来索引,所有数据都保存在叶子节点。
2.所有的叶子结点中包含了全部元素的信息,及指向含这些元素记录的指针,且叶子结点本身依关键字的大小自小而大顺序链接。
3.所有的中间节点元素都同时存在于子节点,在子节点元素中是最大(或最小)元素。
通过以下几幅图可以让我们对B+树有一个初步的认识。
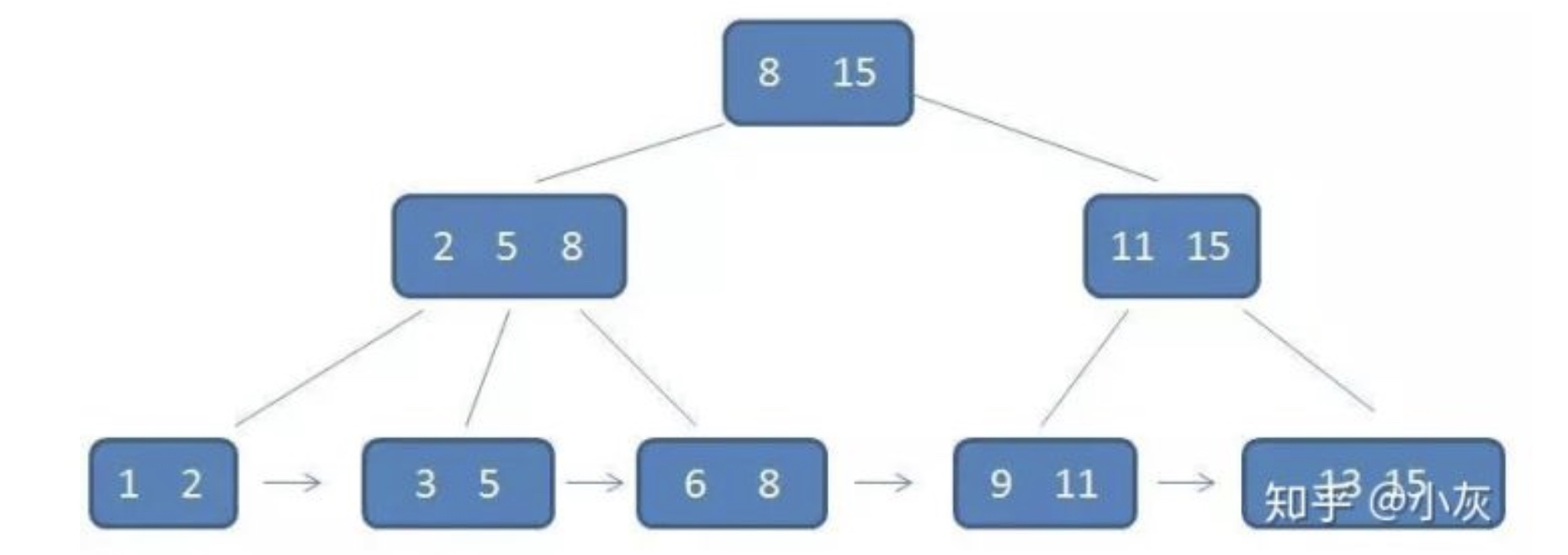
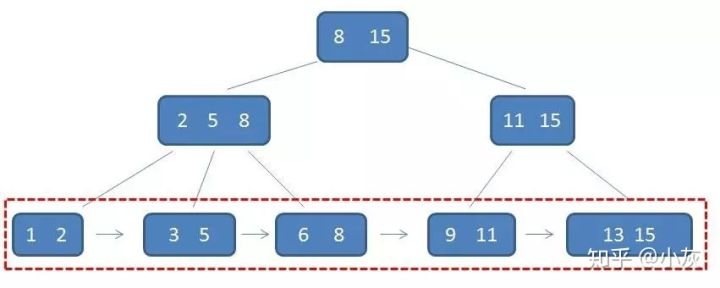
B+树比B-树更加的矮胖,因此查询次数更少。B+树的查找每次都会查找到叶子结点,因此稳定性也相对较高。
- 查找
相对于范围查找来说,B-树需要我们中序遍历整个树,选出所在某个范围内的元素。如果是B+树,我们只需要在最底层的链表上做查询即可。
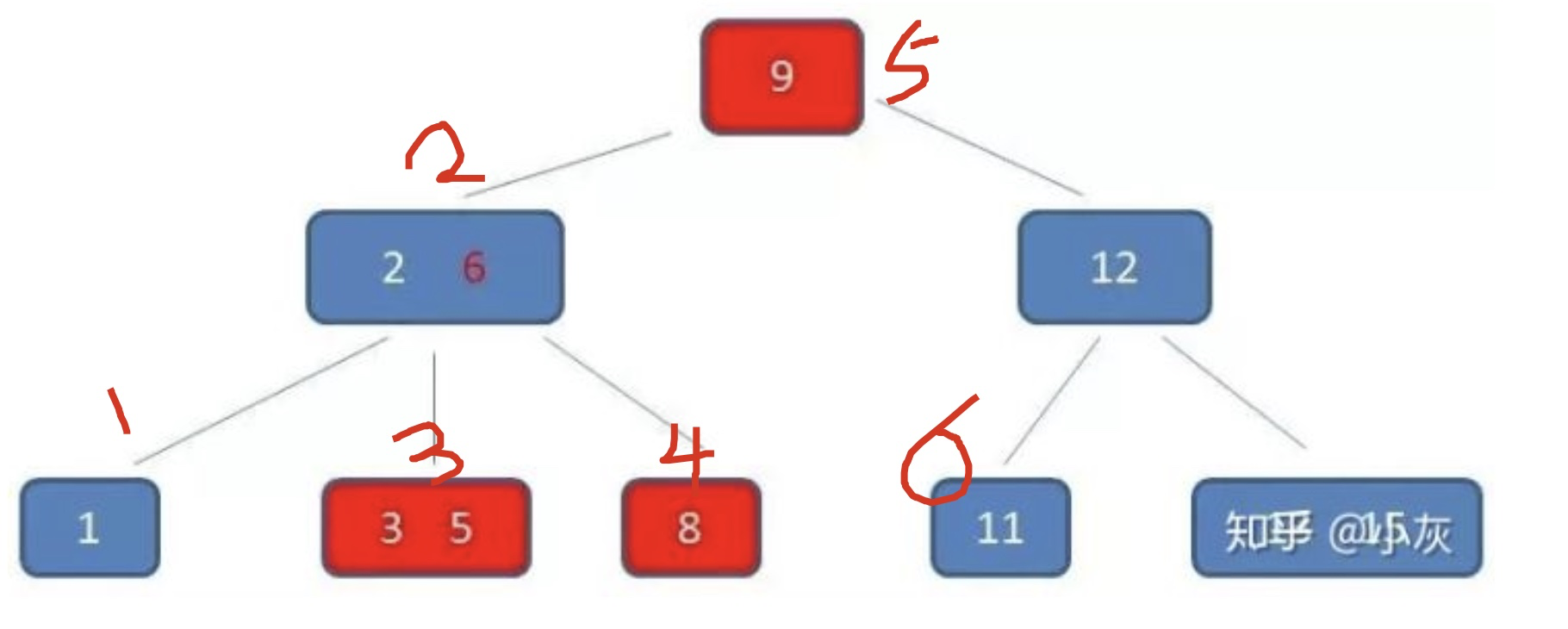
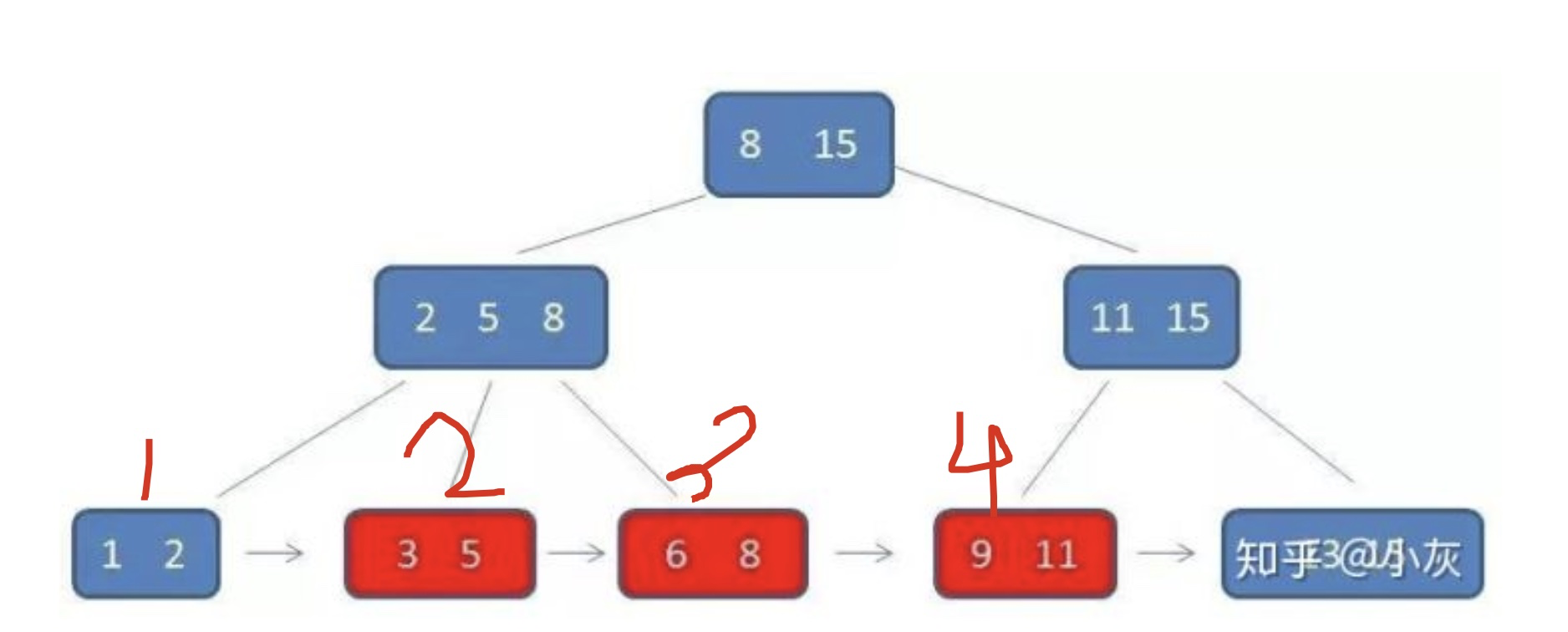
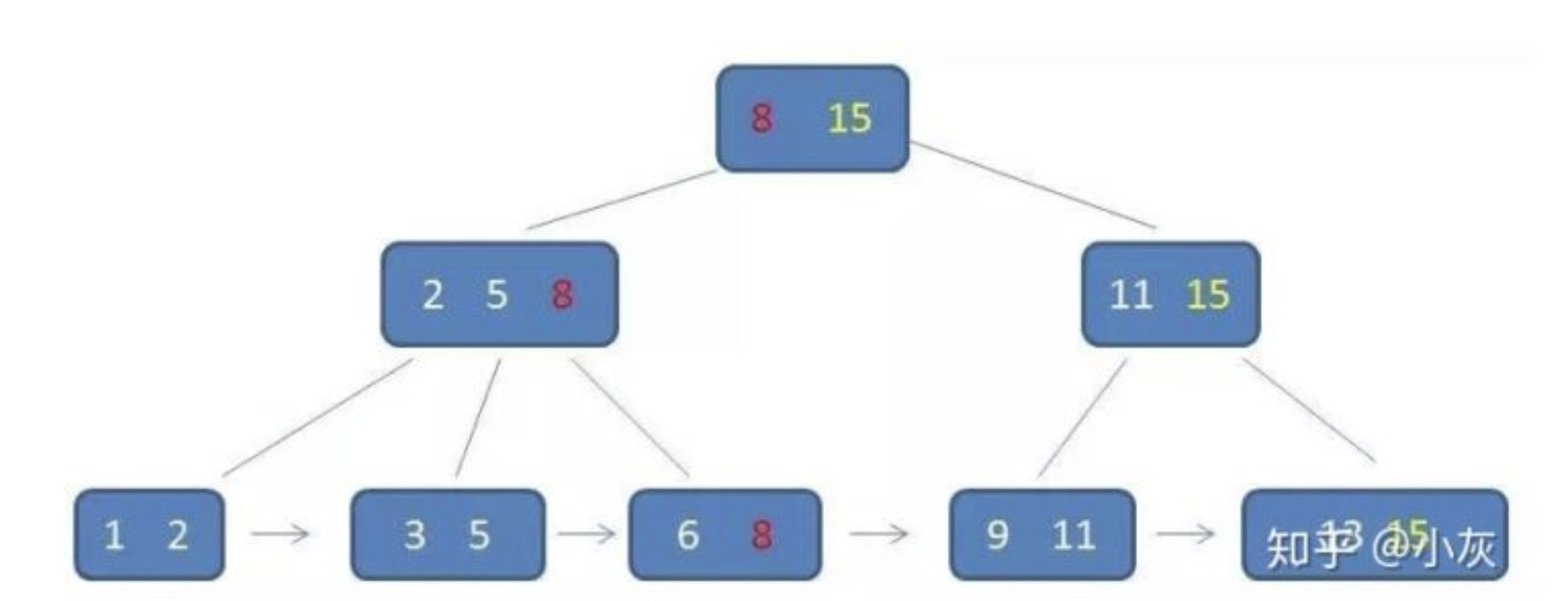
以下图为例,分析我们的查找过程~
比如我们的目标值小于5,根据根结点,我们可以知道不再范围内,如果大于第一个数小于第二个数,那么在第一个子树中找,依次类推。
