

以下内容由第四范式先荐团队编译,原文发布于Medium,作者Steeve Huang。转载内容仅用于学习交流,版权归原作者所有。
1.背景
在上一篇文章《想要了解推荐系统?看这里!(1)——协同过滤与奇异值分解》中,我们谈到了协同过滤(CF)与奇异值分解(SVD)如何用于构建推荐系统。随着神经网络的兴起,如何利用这种技术构建推荐系统也引起了很多人的关注。这篇博文将介绍Spotlight——由PyTorch支持的推荐系统框架。
2. Spotlight

Spotlight是一个很好实现的python框架,用于构建推荐系统。它包含两种主要类型的模型,分解模型和序列模型。
分解模型利用SVD背后的思想,将效用矩阵(记录用户和项目之间交互的矩阵)分解为用户和项目矩阵的两个潜在表征,并将它们反馈到网络中。
序列模型使用时间序列模型构建,例如长期短期记忆(LSTM)和一维卷积神经网络(CNN)。由于Spotlight的后端是PyTorch,请确保在使用PyTorch之前已安装了正确版本的PyTorch。
交互
在Spotlight中,效用矩阵被称为交互。要创建隐式交互,我们为每一用户-项目交互对分别指定ID。附加的评级信息则把隐式交互转换为显式交互。
分解模型
分解模型采用隐式或显式交互。接下来本文将对隐式交互进行简要说明。

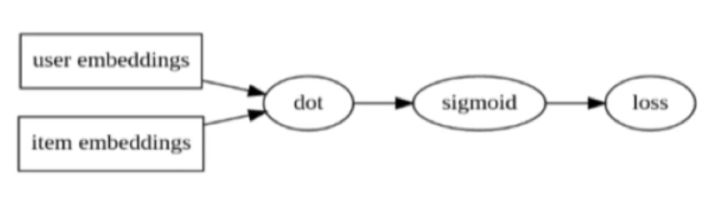
隐式交互的理念与SVD非常相似,用户和物品被映射到潜在空间,可以直接进行比较。一般来说,我们用两个嵌入层分别表示用户和项目。
目标是我们传入的交互(效用矩阵)。为了计算用户-项目对的得分情况,我们采用该用户和项目的潜在表征的点积,并将其传递给sigmoid激活函数。
通过计算真实交互的所有用户-项目对的损失,我们可以反向传播和优化嵌入层,结构如下图所示。
这种模型只需要几行代码就能在Spotlight中训练,它看起来与scikit-learn工具包非常相似:
顺序模型
顺序模型将推荐问题视为顺序预测问题。有了用户之前的交互行为数据,我们想要知道用户在下一个时间步中最可能喜欢的项目。
例如,假设用户A与[2,4,17,3,5]序列中的项目有了交互行为。接下来我们将进行以下扩展窗口预测。
[2] -> 4
[2, 4] -> 17
[2, 4, 17] -> 3
[2, 4, 17, 3] -> 5
左侧的数组存储用户之前的交互行为,而右侧的整数表示用户A接下来要与之发生交互的项目。
为了训练这样的模型,我们只需将原始交互对象转换为顺序交互对象。其余对象同理。
需要注意的是,为了确保每个序列具有相同的长度,Sequence函数会在长度不足的序列前边补零。

因此,为了确保该函数起作用,ID为0的项目应该更改为其他未被使用的任一ID号。
选择损失函数
在指定模型时,我们可以灵活地更改损失函数。具有不同损失函数的模型可能在性能上具有显著差异。接下来本文将简要介绍Spotlight中定义的两种主要类型的损失函数。
- 'pointwise':
与其他形式的损失函数相比,这是最简单的形式。由于样本的稀疏性(效用矩阵中存在多个0),把所有项目都考虑在内则会无法计算。因此,我们只考虑随机选择的一部分负样本(用户未与之交互的项目)和所有的正样本。
- 'bpr':
贝叶斯个性化排序(BPR)为每位用户提供每个项目的排序。BPR运用以下计算公式,以确保正样本的等级高于负样本的等级。
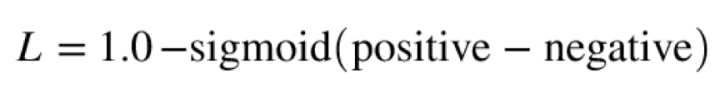
5.结论
本文讨论了如何用Spotlight构建推荐系统。这种方法既简单又灵活,能满足大部分需求。虽然对于大多数问题而言,序列模型优于分解模型,但是训练序列模型需要更长的时间。此外,如果数据之间没有明显的顺序相关性,那么应用序列模型用处不大。
相关阅读:
如欲了解更多,欢迎搜索并关注官方微博@先荐、微信公众号(ID:dsfsxj)。
