

《数据库索引,到底是什么做的?》介绍了B+树,它是一种非常适合用来做数据库索引的数据结构:
(1)很适合磁盘存储,能够充分利用局部性原理,磁盘预读;
(2)很低的树高度,能够存储大量数据;
(3)索引本身占用的内存很小;
(4)能够很好的支持单点查询,范围查询,有序性查询;
数据库的索引分为主键索引(Primary Inkex)与普通索引(Secondary Index)。InnoDB和MyISAM是怎么利用B+树来实现这两类索引,其又有什么差异呢?这是今天要聊的内容。
一,MyISAM的索引
MyISAM的索引与行记录是分开存储的,叫做非聚集索引(UnClustered Index)。
其主键索引与普通索引没有本质差异:
- 有连续聚集的区域
单独存储行记录 - 主键索引的叶子节点,存储主键,与对应行记录的
指针 - 普通索引的叶子结点,存储索引列,与对应行记录的
指针
*画外音:MyISAM的表可以没有主键。*
主键索引与普通索引是两棵独立的索引B+树,通过索引列查找时,先定位到B+树的叶子节点,再通过指针定位到行记录。
举个例子,MyISAM:
t(id PK, name KEY, sex, flag);
表中有四条记录:
1, shenjian, m, A
3, zhangsan, m, A
5, lisi, m, A
9, wangwu, f, B
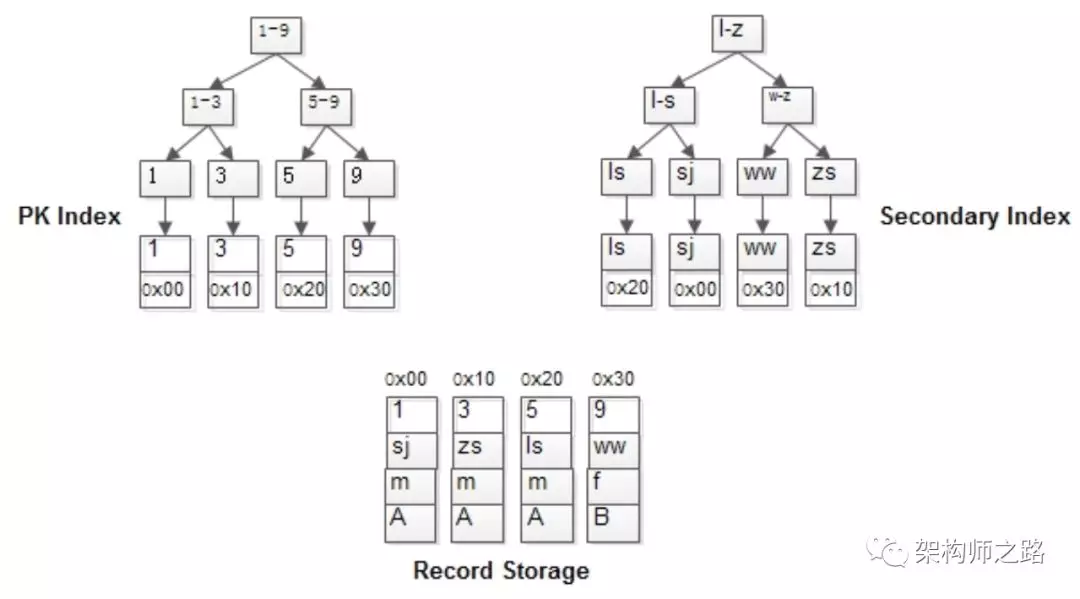
其B+树索引构造如上图:
- 行记录单独存储
- id为PK,有一棵id的索引树,叶子指向行记录
- name为KEY,有一棵name的索引树,叶子也指向行记录
二、InnoDB的索引
InnoDB的主键索引与行记录是存储在一起的,故叫做聚集索引(Clustered Index):
- 没有单独区域存储行记录
- 主键索引的叶子节点,
存储主键,与对应行记录(而不是指针)
画外音:因此,InnoDB的PK查询是非常快的。
因为这个特性,InnoDB的表必须要有聚集索引:
(1)如果表定义了PK,则PK就是聚集索引;
(2)如果表没有定义PK,则第一个非空unique列是聚集索引;
(3)否则,InnoDB会创建一个隐藏的row-id作为聚集索引;
聚集索引,也只能够有一个,因为数据行在物理磁盘上只能有一份聚集存储。
InnoDB的普通索引可以有多个,它与聚集索引是不同的:
- 普通索引的叶子节点,
存储主键(也不是指针)
对于InnoDB表,这里的启示是:
(1)不建议使用较长的列做主键,例如char(64),因为所有的普通索引都会存储主键,会导致普通索引过于庞大;
(2)建议使用趋势递增的key做主键,由于数据行与索引一体,这样不至于插入记录时,有大量索引分裂,行记录移动;
仍是上面的例子,只是存储引擎换成InnoDB:
t(id PK, name KEY, sex, flag);
表中还是四条记录:
1, shenjian, m, A
3, zhangsan, m, A
5, lisi, m, A
9, wangwu, f, B
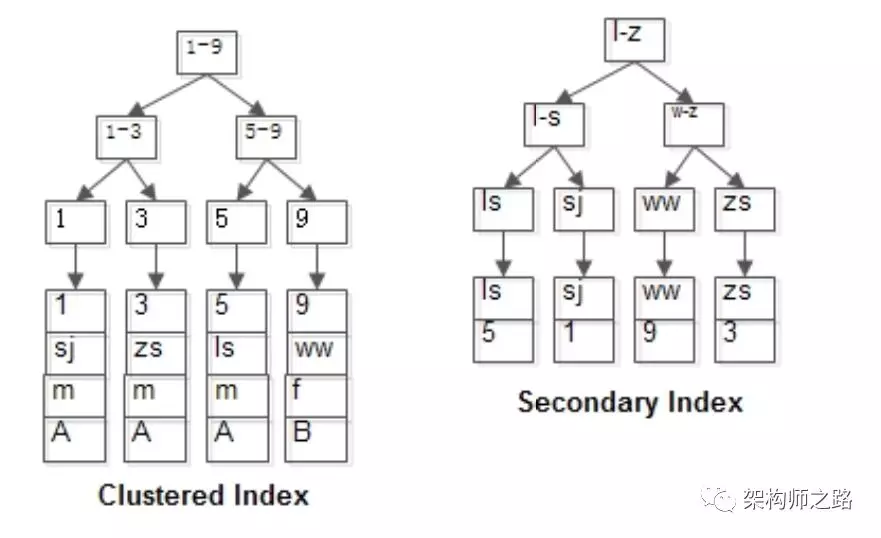
其B+树索引构造如上图:
- id为PK,行记录和id索引树存储在一起
- name为KEY,有一棵name的索引树,叶子存储id
当:
select * from t where name=‘lisi’;
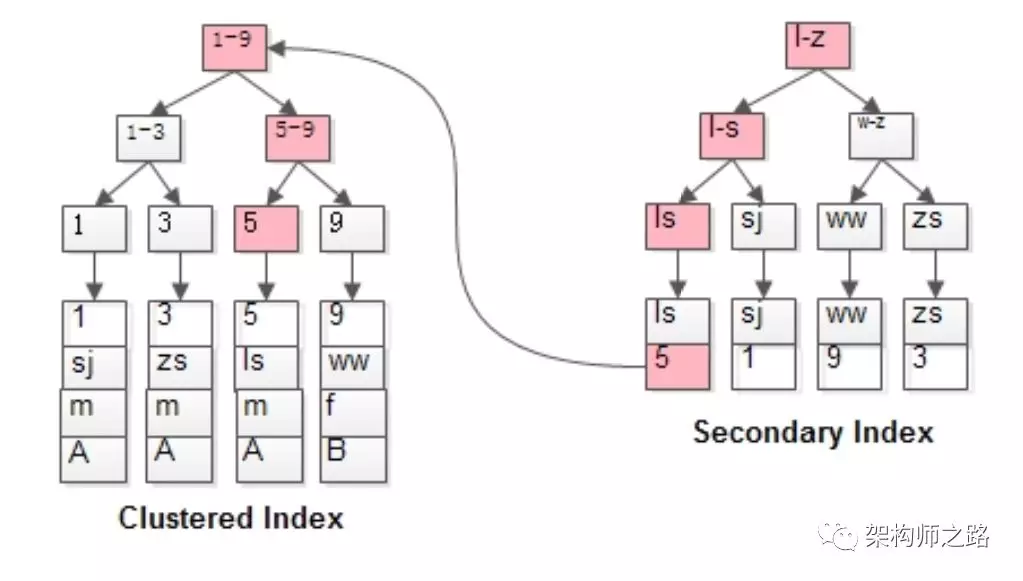
会先通过name辅助索引定位到B+树的叶子节点得到id=5,再通过聚集索引定位到行记录。
*画外音:所以,其实扫了2遍索引树。*
三,总结
MyISAM和InnoDB都使用B+树来实现索引:
- MyISAM的索引与数据
分开存储 - MyISAM的索引叶子
存储指针,主键索引与普通索引无太大区别 - InnoDB的聚集索引和
数据行统一存储 - InnoDB的聚集索引存储数据行本身,普通索引
存储主键 - InnoDB一定有且只有一个聚集索引
- InnoDB建议使用
趋势递增整数作为PK,而不宜使用较长的列作为PK

